文章目錄
- 1.邏輯回歸簡介
- 2.最大熵模型簡介
- 3.常用評價指標
- 3.1混淆矩陣
- 3.2準確率
- 3.3精確率&召回率
- 3.4PR曲線
- 3.5ROC曲線與AUC
- 3.5.1ROC曲線
- 3.5.2AUC
- 4.基于邏輯回歸實作乳腺癌預測
??邏輯回歸模型是一種常用的回歸或分類模型,可以視為是廣義線性模型的特例,

1.邏輯回歸簡介
??關于線性回歸,線性回歸是最基本的回歸分析方法線性回歸研究的是自變數與因變數之間的線性關系,對于傳統的線性回歸而言,其基本假設是假設y與x直接呈線性關系,如果x與y不是線性關系,則使用線性回歸模型會得到較大的誤差,
為了解決這個問題,需要尋找一個函式g(y),使g(y)與x之間是線性關系,(即g(y)與y之間不是線性關系,從y到g(y)經歷了非線性變換),這種間接進行對x進行估計的回歸,即稱為廣義線性回歸,
2.最大熵模型簡介
??在資訊論中,熵可以度量隨機變數的不確定性,當隨機變數呈均勻分布時,熵值最大,在一個有序的系統中,有著較小的熵值;而在一個無序的系統中存在著較大的熵值,
??在機器學習中,有最大熵原理:描述一個概率分布時,在滿足所有約束條件的情況下,熵最大的模型是最好的,
對于離散隨機變數x,假設其有M個取值,記$\displaystyle p_i=P(x=i),則其熵定義為:
- H ( P ) = ? ∑ i = 1 M p i ln ? p i \displaystyle H(P)=- \sum_{i=1}^Mp_i\ln{p_i} H(P)=?i=1∑M?pi?lnpi?
對于連續變數x,假設其概率分布密度為f(x),則其熵定義為:
- H ( f ) = ∫ f ( x ) ln ? f ( x ) d x \displaystyle H(f)=\int f(x)\ln{f(x)}dx H(f)=∫f(x)lnf(x)dx
經過公式推導,最大熵模型與邏輯回歸模型之間是完全等價的,
(這里不談及公式推導的程序,)
3.常用評價指標
3.1混淆矩陣
對二分類問題:
| 真實值 | 預測值0 | 預測值1 |
|---|---|---|
| 0 | True Negative(TN) | False Negative(FP) |
| 1 | False Negative(FN) | True Positive(TP) |
其中,True/False表示判斷結果正誤,Positive/Negative表示預測值是正標簽還是負標簽,
| 指標 | 簡寫 | 描述 |
|---|---|---|
| 真陰率 | TN | 預測成負樣本實際是負樣本的個數 |
| 假陽率 | FP | 預測成正樣本實際是負樣本的個數 |
| 假陰率 | FN | 預測成負樣本實際是正樣本的個數 |
| 真陽率 | TP | 預測成正樣本實際是正樣本的個數 |
對于多分類問題,則遷移為:
| TN | 預測結果不是該標簽,真實標簽不是該標簽的個數 |
| FP | 預測結果是該標簽,真實標簽不是該標簽的個數 |
| FN | 預測結果不是該標簽,真實標簽是該標簽的個數 |
| TP | 預測結是該標簽,真實標簽是該標簽的個數 |
很多評價指標都是建立在混淆矩陣之上的,
3.2準確率
即預測正確的結果占總樣本的百分比,
A c c u r a c y = T P + T N T P + T N + F P + F N \displaystyle Accuracy =\frac{TP+TN}{TP+TN+FP+FN} Accuracy=TP+TN+FP+FNTP+TN?
3.3精確率&召回率
精確率,也稱查準率
P
r
e
c
i
s
i
o
n
=
T
P
T
P
+
F
P
\displaystyle Precision=\frac{TP}{TP+FP}
Precision=TP+FPTP?
可以描述為 預測結果是該標簽的樣例中,實際是該標簽的所占比,
召回率,也稱查全率
R e c a l l = T P T P + T N \displaystyle Recall=\frac{TP}{TP+TN} Recall=TP+TNTP?
可以描述為 實際是該標簽的樣例中,預測結果是該標簽的所占比,
3.4PR曲線
分類模型對每個樣本點都會輸出一個置信度,
通過設定置信度的閾值,就可以完成分類,
不同的置信度對應著不同的精確率 和 召回率
一般來說,置信度閾值較低時,大量樣本被預測為正例,所以召回率較高,精確率較低;
置信度閾值較高時,大量樣本被預測為負例,所以召回率較低,而精確率較高,
PR曲線就是以精確率為縱坐標,以召回率為橫坐標做出的曲線,
3.5ROC曲線與AUC
3.5.1ROC曲線
對于二分類分類器,
為了衡量分類器的分類能力,ROC曲線進行了表征:
ROC曲線的橫軸為假陽率(False Positive Rate, FPR)
-
F
P
R
=
F
P
T
N
+
F
P
\displaystyle FPR=\frac{FP}{TN+FP}
FPR=TN+FPFP?
描述:實際標簽為負樣本的樣本中,預測為正樣本的比例,
ROC曲線的縱軸為真陽率(True Positive Rate, TPR)
-
T
P
R
=
T
P
T
P
+
F
N
\displaystyle TPR=\frac{TP}{TP+FN}
TPR=TP+FNTP?
描述:實際標簽是正樣本的樣本中,預測為正樣本的比例,
通過這兩句描述,不看看出,我們更想要的是y軸較大,x軸較小的情況,
- (0, 0)假陽率和真陽率都為0,即分類器全部預測為負樣本,
- (0, 1)假陽率為0,真陽率為1,即全部完美預測正確,
- (1, 0)假陽率為1,真陽率為0,即全部完美預測錯誤,
- (1, 1)假陽率和真陽率都為1,即分類器全部預測為正樣本,
ROC曲線的橫走坐標都在[0, 1]之間,面積不大于1,
- 當TPR=FPR為一條斜對角線時,表示預測為正樣本的結果一般是對的,一般是錯的,此為隨機分類器的預測效果,
- 當ROC曲線在對角線以下,表示該分類器效果差于隨機分類器,
- 當ROC曲線在對角線以上,表示該分類器效果好于隨機分類器,我們希望ROC曲線盡可能地位于斜對角線以上,接近左上角(0,1)位置,
3.5.2AUC
AUC(Area Under Curve),即ROC曲線下與坐標軸圍成的面積,根據以上表述,可知,
AUC越大,分類器分類效果就越好,
- AUC = 1,表示 是完美分類器,采用這個預測模型時,不管設定什么閾值都能得出完美預測,完美分類器一般不存在,
- 0.5 < AUC < 1,效果好于隨機分類器,對于這個分類器,如果設定合適的閾值,則可以有預測價值,
- AUC = 0.5,相當于隨機分類器,
- AUC < 0.5,差于隨機分類器,(所以可以用于反向預測)
4.基于邏輯回歸實作乳腺癌預測
以內置的乳腺癌資料集為例,實作邏輯回歸:
from sklearn.datasets import load_breast_cancer
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import recall_score
from sklearn.metrics import precision_score
from sklearn.metrics import classification_report
from sklearn.metrics import accuracy_score
# 獲取資料
cancer = load_breast_cancer()
# 分割資料
X_train, X_test, y_train, y_test = train_test_split(cancer.data, cancer.target, test_size=0.2)
# 創建估計器(實體化邏輯回歸模型)
model = LogisticRegression()
# 訓練
model.fit(X_train, y_train)
# 回傳給定測驗資料下的準確率(即預測正確的結果占總樣本的百分比)
# 訓練集準確率
train_score = model.score(X_train, y_train)
# 測驗集準確率
test_score = model.score(X_test, y_test)
print('train score:{train_score:.6f};test score:{test_score:.6f}'.format(train_score=train_score, test_score=test_score))
# 再對X_test進行預測
y_pred = model.predict(X_test)
# 準確率
accuracy_score_value = accuracy_score(y_test, y_pred)
# 精確率
precision_score_value = precision_score(y_test, y_pred)
# 召回率
recall_score_value = recall_score(y_test, y_pred)
# 輸出報告模型評估報告
classification_report_value = classification_report(y_test, y_pred)
print("準確率:", accuracy_score_value)
print("精確率:", precision_score_value)
print("召回率:", recall_score_value)
print(classification_report_value)
程式輸出結果
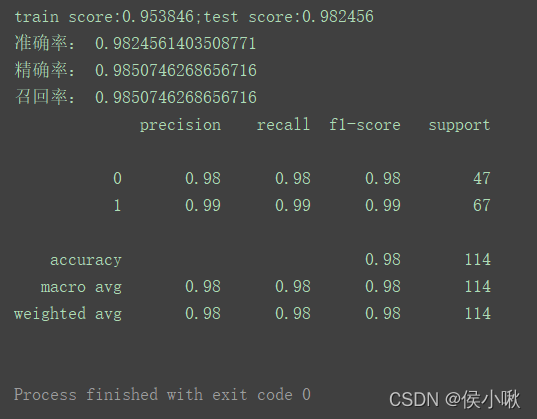
其中,輸出準確率,可以使用model物件的score方法,傳入引數是特征資料和對應的真實標簽,
也可以使用sklearn.metrics的accuracy_score方法,傳入引數為真實標簽和預測的標簽,
參考:
<Python機器學習實戰 呂云翔>
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/427479.html
標籤:AI
上一篇:2022美賽A題思路分享
下一篇:R語言撰寫用戶自定義腳本檔案(script)、在windows cmd中執行R語言批量任務操作(Batch Processing),并將處理結果保存到本地指定目錄檔案中