本此博客也是本人的第一篇文章,有寫得不好的地方希望大家多多指點!
廢話不多說直接上干貨;本文主要講解幾個部分,(適合一些在讀的研究生啥也不會然后接到一些專案無從下手,如果是大佬的話就可以跳過了)先看看網路攝像頭的效果吧(在2060的電腦上運行 )
網路攝像頭
(1)yolov5的訓練
(2)yolov5的界面開發(Pyqt5)
(3)將整個專案打包成EXE
一.yolov5的訓練:
很多做深度學習的伙伴肯定有跑過一些網上的目標檢測開源專案,比如yolo系列,我跑過YOLOv4(VS編譯進行對于我這個小白來說比較麻煩),還是YOLOv5使用pycharm在pytorch的環境下進行訓練、測驗,之類的(此內容只針對小白);
先從搭建環境開始,首先你要去官網下載anaconda點擊此處進入下載教程,就當你已經下載好anaconda了,然后你要下載一個編譯器pycharm(簡單的來說就是你撰寫python代碼的一個APP),編譯器有了現在就要創建一個虛擬環境了(通過anaconda創建一個虛擬環境,在這個環境里面你可以下載很多庫模塊,比如python—opencv,torch,tensorflow,Pyqt之類的第三方庫你才能運行你的深度學習或者你的界面開發)
如果你是做深度學習的話肯定有一個不錯的GPU,我是下載的GPU版本的torch,所以都是以我自身的計算機能力下載相關配置:
# 創建(建議下載3.7我也不是很清楚)
conda create -n env_name python=x.x
#如果你要創建pytorch環境你可以如下操作(名字可以自己選擇)
conda create -n pytorch python=3.7
# 洗掉
conda remove -n env_name --all
創建完虛擬環境后你可以在你的anaconda目錄下面找到你創建的環境如下圖所示:
環境創好了、編譯器也下載好了,大家伙不要著急!馬上就要去下載YOLOv5的原始碼(這里面有一個巨大的坑困擾了我幾天后面會告訴大家)
直接去GitHub官網下載點擊此處下載YOLOV5原始碼
大家可以看到有很多不同的版本,就是在這里困擾了我很久,我自己下載的是V3.0版本的,但是有一個博主的界面設計使用的原始碼是V4.0,導致后面加載權重死活加載不出來,界面崩潰;所以大家做界面開發一定要用自己的或者跟博主的一樣,好了建議你下載V4.0因為我是4.0版本的如果出現什么問題還可以討論一下,
點擊右上角的Code,Download就可以了,然后解壓到自己的電腦如下:
好了!原始碼下載好了之后,開始安裝YOLOv5需要的庫,大家打開根目錄可以看到有一個requirements.txt如下:

開始安裝上面的一些庫,win+r輸入cmd進入終端激活你剛剛創建的環境(因為你以后要使用這個環境把所以的第三方庫下進去就完事了)
#激活環境(你自己的環境)
activate pytorch激活之后就會出現:
![]() 此時你已經進入了環境就可以下載了,
此時你已經進入了環境就可以下載了,
如果你要執行pip install -r requirements.txt,你需要進入原始碼根目錄在路徑輸入cmd如下:
進入終端后直接輸入:(torch,和torchvision先不下載)
pip install -r requirements.txt
#一般情況下都不會成功反正我是這樣的所以我是一個一個下載的
#這里忘了告訴大家pip下載是訪問外網進行下載所以速度非常慢,加入國內鏡像源下載如下:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple matplotlib>=3.2.2(默認下載最新版本)
就這樣一個一個的下載很笨的方法,gpu-torch官網上可以下載但是對于小白來說很容易失敗,或者根本下載不了非常慢,所以我把我的gpu-torch發給大家,

我的CUDA版本是11.1(至于cuda是什么我也不解釋了自己百度一下就知道了),我會把CUDA、CUDNN、torch,這一套都放在百度網盤:
鏈接:https://pan.baidu.com/s/15GASd44zuYZXDhrR-bnzbA
提取碼:7eit
CUDA的安裝大家可以看一下其他教程,cuda一定要安裝在C盤默認位置記住這個位置,
![]() 左圖是CUDNN這個很難下載在官網,大家直接在我的網盤里面下載完之后把幾個檔案夾里面的東西拷貝到CUDA的對應檔案夾即可,系統變數一般在安裝時會自動添加,這里你的CUDA就安裝成功了,
左圖是CUDNN這個很難下載在官網,大家直接在我的網盤里面下載完之后把幾個檔案夾里面的東西拷貝到CUDA的對應檔案夾即可,系統變數一般在安裝時會自動添加,這里你的CUDA就安裝成功了,
下一步安裝torch(這個東西在官網下載非常的慢所以用我的梯子)
大家把torch-1.8.0+cu111-cp37-cp37m-win_amd64.whl和另一個torchvision-0.9.0+cu111-cp37-cp37m-win_amd64.whl解壓到你剛剛創建的環境里面,解壓好之后在路徑輸入CMD進入終端,進入終端后:
pip install torch-1.8.0+cu111-cp37-cp37m-win_amd64.whl
pip install torchvision-0.9.0+cu111-cp37-cp37m-win_amd64.whl等待幾分鐘就會下載好,在你的:
這里面基本都是你以后下載的所以三方庫!可以測驗一下你的gpu-torch是否可以呼叫:
#進入你的環境
activate pytorch
#輸入
python
import torch
torch.cuda.is_available()
#如果輸出的結果是
Ture(表示你安裝成功了)如果沒什么大問題我們就可以直接進入pycharm運行yolov5代碼試一試!(一般都會有錯誤)
(大家也可以去其他地方下載合適的cuda和torch點擊此處)
廢話不多說讓我們進入pycharm吧, 雙擊它第一次會有一點慢稍微等待一下!
雙擊它第一次會有一點慢稍微等待一下!
點擊file-open打開專案點擊我們剛剛下載的YOLOv5原始碼的檔案:
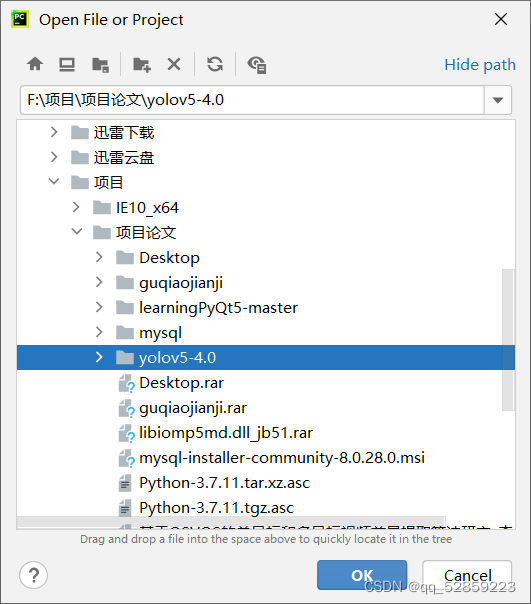
大家像這種都保存在英文路徑下,匯入我們剛剛的環境點擊file-setting-projict-python編譯器-點擊設定就進入到此界面,然后點擊conda-environment
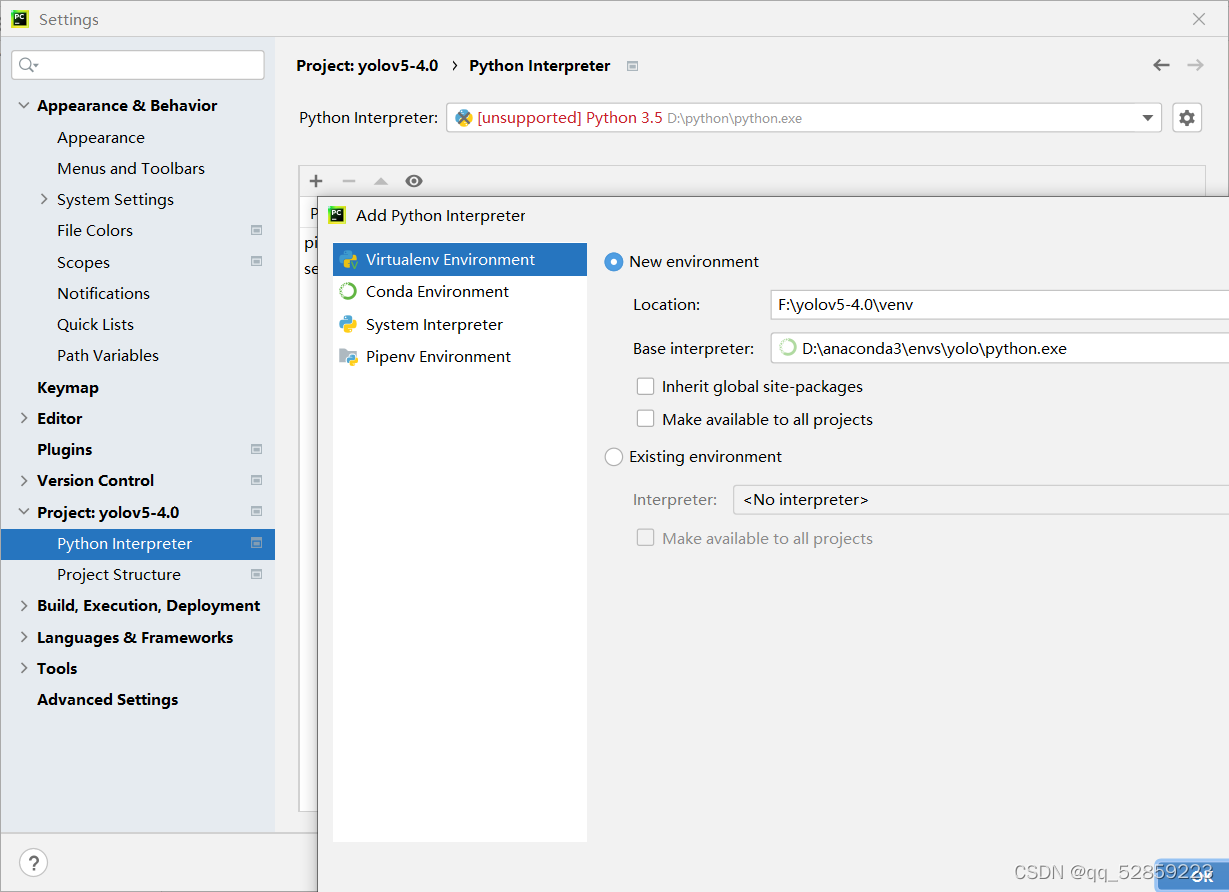
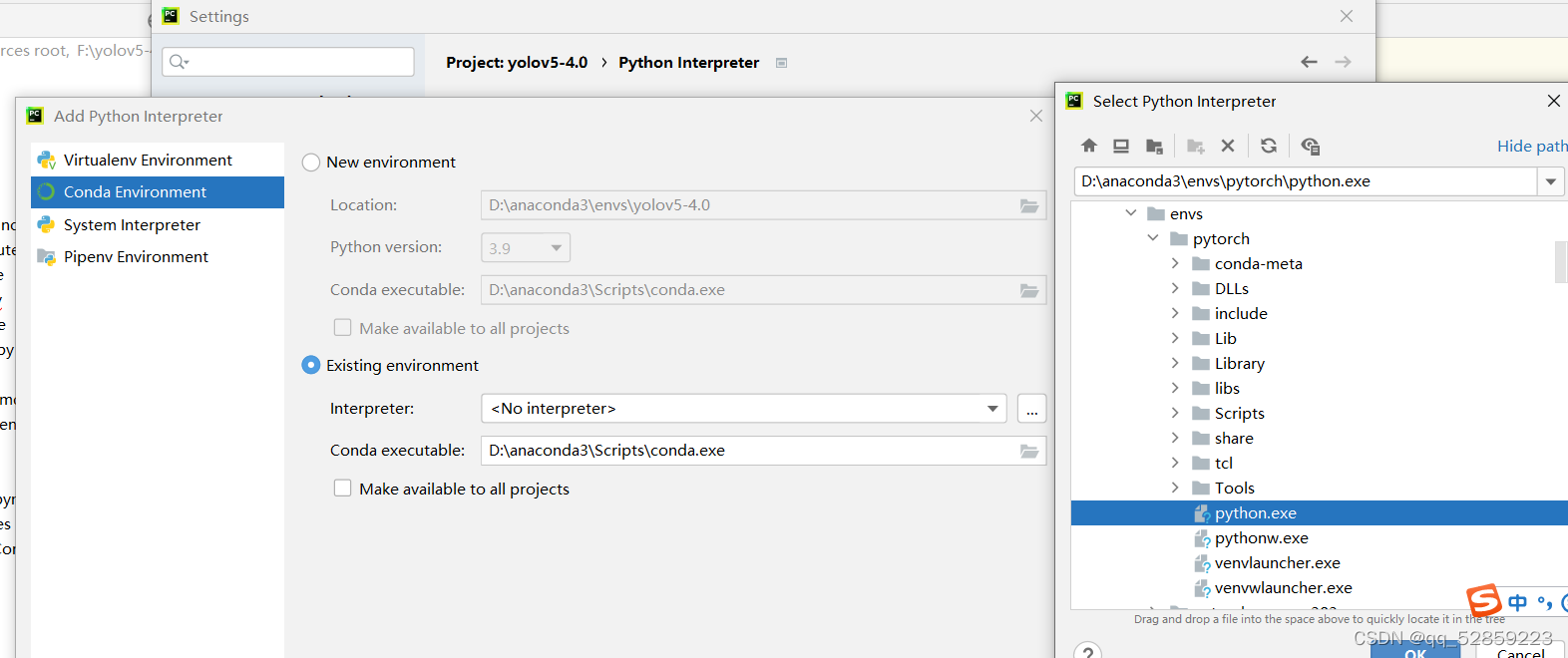
等待幾分鐘讓他配置環境,完成之后就可以進行測驗了,運行detect.py,設定device=0
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--weights', nargs='+', type=str, default='yolov5s.pt', help='model.pt path(s)')
parser.add_argument('--source', type=str, default='data/images', help='source') # file/folder, 0 for webcam
parser.add_argument('--img-size', type=int, default=640, help='inference size (pixels)')
parser.add_argument('--conf-thres', type=float, default=0.25, help='object confidence threshold')
parser.add_argument('--iou-thres', type=float, default=0.45, help='IOU threshold for NMS')
parser.add_argument('--device', default='0', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--view-img', action='store_true', help='display results')好的在意料之中:報錯了,沒有YOLOV5S.pt權重檔案,大家可以在網上下載V4.0的,

下載好你的權重檔案放在根目錄,如果沒有問題的話就像下面這樣:
恭喜你你已經入門了!(關于如何訓練自己的權重檔案網上有很多教程直接進入下一個板塊)
二.如何為YOLOv5設計界面
首先你要學習一下Pyqt5,算了反正看我的文章應該都不想看,先安裝三方庫吧:
pip install Pyqt5我給大家說一下最基本的可以用到的控制元件(如果你是真的想要學習必須自己進行設計,千萬不要搞別人的源代碼跑一下就完事了),
首先要搞清楚界面設計我們需要yolov5原始碼的哪一部分結合界面進行檢測;
我們需要兩部分一部分是模型引數加載:
def model_init(self):
# 模型相關引數配置
parser = argparse.ArgumentParser()#best1.pt效果最好
parser.add_argument('--weights', nargs='+', type=str, default='weights/best1.pt', help='model.pt path(s)')
parser.add_argument('--source', type=str, default='data/images', help='source') # file/folder, 0 for webcam
parser.add_argument('--img-size', type=int, default=640, help='inference size (pixels)')
parser.add_argument('--conf-thres', type=float, default=0.25, help='object confidence threshold')
parser.add_argument('--iou-thres', type=float, default=0.45, help='IOU threshold for NMS')
parser.add_argument('--device', default='0', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--view-img', action='store_true', help='display results')
parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')
parser.add_argument('--nosave', action='store_true', help='do not save images/videos')
parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --class 0, or --class 0 2 3')
parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')
parser.add_argument('--augment', action='store_true', help='augmented inference')
parser.add_argument('--update', action='store_true', help='update all models')
parser.add_argument('--project', default='runs/detect', help='save results to project/name')
parser.add_argument('--name', default='exp', help='save results to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
self.opt = parser.parse_args()
print(self.opt)
# 默認使用opt中的設定(權重等)來對模型進行初始化
source, weights, view_img, save_txt, imgsz = self.opt.source, self.opt.weights, self.opt.view_img, self.opt.save_txt, self.opt.img_size
# 若openfile_name_model不為空,則使用此權重進行初始化
if self.openfile_name_model:
weights = self.openfile_name_model
print("Using button choose model")
# self.device = select_device(self.opt.device)
self.device = torch.device('cuda:0')
self.half = self.device.type != 'cpu' # half precision only supported on CUDA
cudnn.benchmark = True
# Load model
self.model = attempt_load(weights, map_location=self.device) # load FP32 model
stride = int(self.model.stride.max()) # model stride
self.imgsz = check_img_size(imgsz, s=stride) # check img_size
if self.half:
self.model.half() # to FP16
# Get names and colors
self.names = self.model.module.names if hasattr(self.model, 'module') else self.model.names
self.colors = [[random.randint(0, 255) for _ in range(3)] for _ in self.names]
print("model initial done")這里大家可以看到我沒有使用self.opt.device,而是直接使用torch.device進行選擇GPU,因為大佬說使用上面的進行打包會不成功;
另一部分是檢測(包括圖片歸一化、模型加載、繪制):
def detect(self):
t0 = time.time()
img = torch.zeros((1, 3, imgsz, imgsz), device=device) # init img
_ = model(img.half() if half else img) if device.type != 'cpu' else None # run once
for path, img, im0s, vid_cap in dataset:
img = torch.from_numpy(img).to(device)
img = img.half() if half else img.float() # uint8 to fp16/32
img /= 255.0 # 0 - 255 to 0.0 - 1.0
if img.ndimension() == 3:
img = img.unsqueeze(0)
# Inference
t1 = time_synchronized()
pred = model(img, augment=opt.augment)[0]
# Apply NMS
pred = non_max_suppression(pred, opt.conf_thres, opt.iou_thres, classes=opt.classes, agnostic=opt.agnostic_nms)
t2 = time_synchronized()
# Apply Classifier
if classify:
pred = apply_classifier(pred, modelc, img, im0s)
# Process detections
for i, det in enumerate(pred): # detections per image
if webcam: # batch_size >= 1
p, s, im0, frame = path[i], '%g: ' % i, im0s[i].copy(), dataset.count
else:
p, s, im0, frame = path, '', im0s, getattr(dataset, 'frame', 0)
p = Path(p) # to Path
save_path = str(save_dir / p.name) # img.jpg
txt_path = str(save_dir / 'labels' / p.stem) + ('' if dataset.mode == 'image' else f'_{frame}') # img.txt
s += '%gx%g ' % img.shape[2:] # print string
gn = torch.tensor(im0.shape)[[1, 0, 1, 0]] # normalization gain whwh
if len(det):
# Rescale boxes from img_size to im0 size
det[:, :4] = scale_coords(img.shape[2:], det[:, :4], im0.shape).round()
# Print results
for c in det[:, -1].unique():
n = (det[:, -1] == c).sum() # detections per class
s += f'{n} {names[int(c)]}s, ' # add to string
# Write results
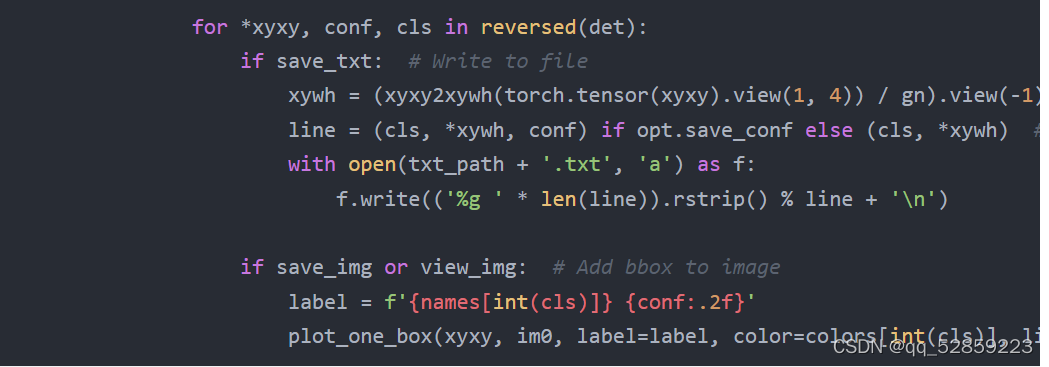
for *xyxy, conf, cls in reversed(det):
if save_txt: # Write to file
xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # normalized xywh
line = (cls, *xywh, conf) if opt.save_conf else (cls, *xywh) # label format
with open(txt_path + '.txt', 'a') as f:
f.write(('%g ' * len(line)).rstrip() % line + '\n')
if save_img or view_img: # Add bbox to image
label = f'{names[int(cls)]} {conf:.2f}'
plot_one_box(xyxy, im0, label=label, color=colors[int(cls)], line_thickness=3)
有了這兩個部分就可以進行檢測了,但是要找到檢測的結果圖片,對檢測后的圖片進行顯示;
這里是對檢測到的物體進行繪制,所以你需要想辦法將圖片傳入此函式進行檢測,檢測完之后再進行傳出來顯示,比如:
def detect(self,image)
pass
def show_video(self)
這里的image可以是攝像頭,圖片,視頻,網路攝像頭
比如使用opencv
num = 0
self.cap = cv2.VideoCapture(camera_num)
image = self.cap.read()
a = self.detect(image)
對這里的image進行處理顯示檢測完之后可以通過pyqt界面進行顯示,
重點來了!
很多小伙伴想要使用網路攝像頭進行專案的開發,需要考慮實時的問題,很多作者都沒有考慮這個問題,所以我想告訴大家的是要想做專案開發,很多大佬都說python多執行緒是假的(偽執行緒),但是親測多執行緒可以解決這個網路攝像頭延遲問題,如果不使用多執行緒界面會卡死,因為網路攝像頭下載到緩沖區的速度大于你的讀取速度或者處理速度,他就會非常卡;打個比方:
使用opencv的videocapture進行抓取攝像頭是沒20ms讀取一幀到緩沖區,在通過cap.read()從緩沖區讀取圖片進行處理需要10ms,但是你讀取到圖片后你還需要進行檢測和顯示耗時假如在100ms,所以你從讀取到一張圖片到顯示在你的界面上需要110ms,但是此時你的緩沖區已經存盤了5,6張圖片了,所以你要解決這個問題,(跳幀和多執行緒可以解決延遲問題)
另一個困惑大家的問題就是如何檢測到目標進行報警的功能,在網上我是沒有搜到相關的代碼,所以這一部分是自己寫一個吧
def play_music(self)
winsound.PlaySound('選擇你要播放的WAV音頻',winsound.SND_ASYNC)
time.sleep(休眠時間以s計數,我設定的是0.5)有了報警函式,當檢測到物體呼叫此函式進行報警,但是這樣會有延遲出現,所以這里又要用到多執行緒(cpu已經開始爆炸了)
此時網路攝像頭延遲問題、報警問題有一定的解決,但是你會發現你的顯存不夠用,因為你啟動多執行緒進行檢測,假如隔5幀進行圖片的抓取進行處理并啟動檢測的多執行緒,多執行緒里面會有一個呼叫GPU的操作,在GPU上進行操作它會使用顯存如下:
pred = model(img, augment=opt.augment)[0]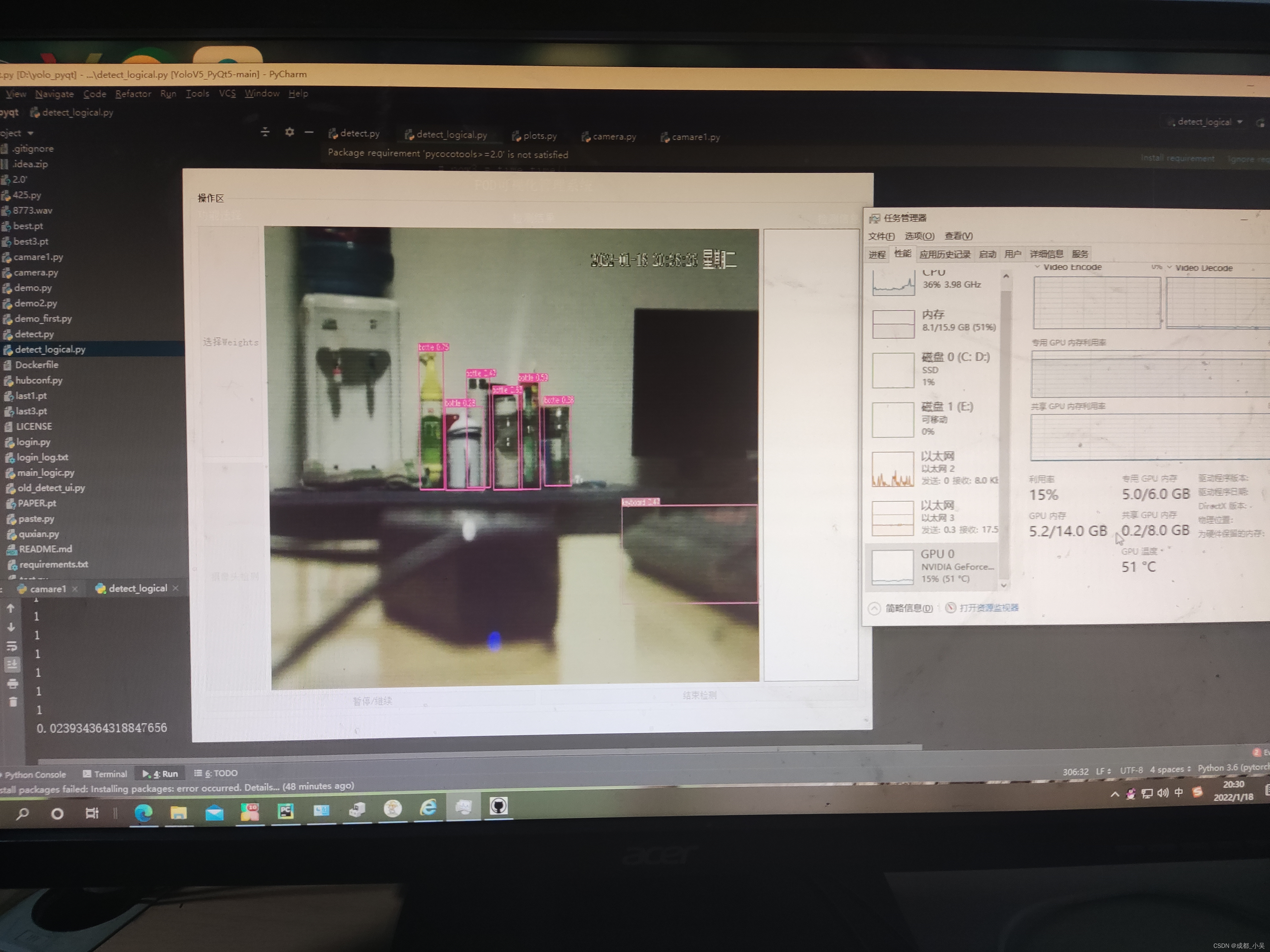
大家可以看到6G的顯存已經占了5G,所以看到這里很多大佬已經開始嘲諷我的編程技術了哈哈!
三.界面打包
大家可以去關注一下迷途小書童點擊關注,網上有很多使用pyinstaller進行打包的教程,但是并沒有針對深度學習的一些打包程序,這個程序真的會出現很多問題!大家可以直接進入原博主官網https://xugaoxiang.com/2021/10/13/yolov5-to-exe/
Python 專案打包是很多新手經常會問的問題,之前也有文章介紹過如何使用 pyinstaller 來打包生成可執行檔案,只不過打包程序是基于命令列的,本文介紹的這個工具,auto-py-to-exe,它是 pyinstaller 的 GUI 版本,對新手更加友好,點點滑鼠就可以輕松搞定,那么,快開始吧,
進入根目錄找到exe檔案:
打開之后腳本位置就是你要打包的主程式,他會打包你所包括的其他檔案
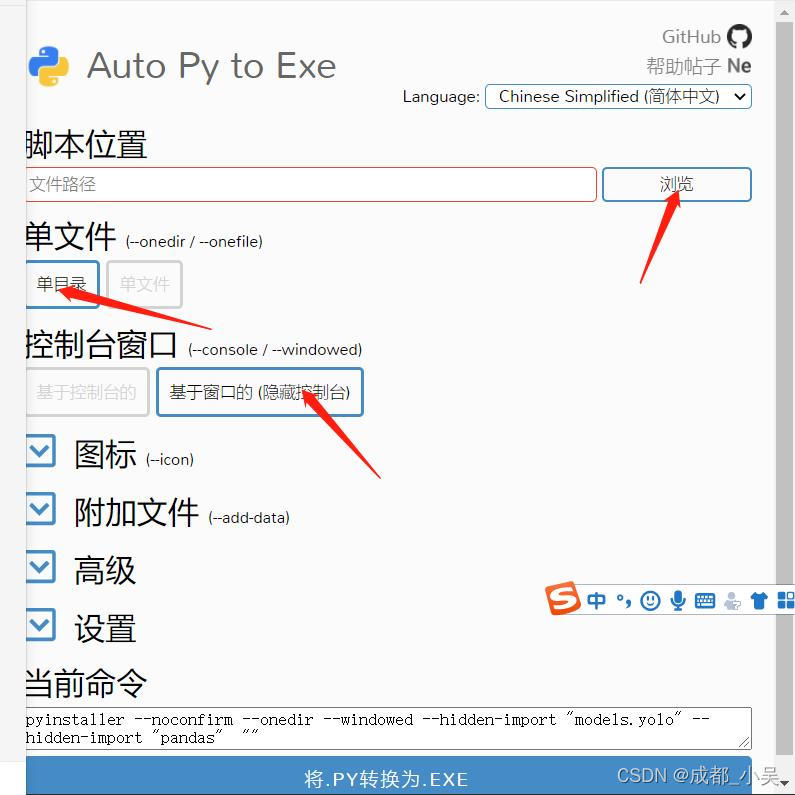
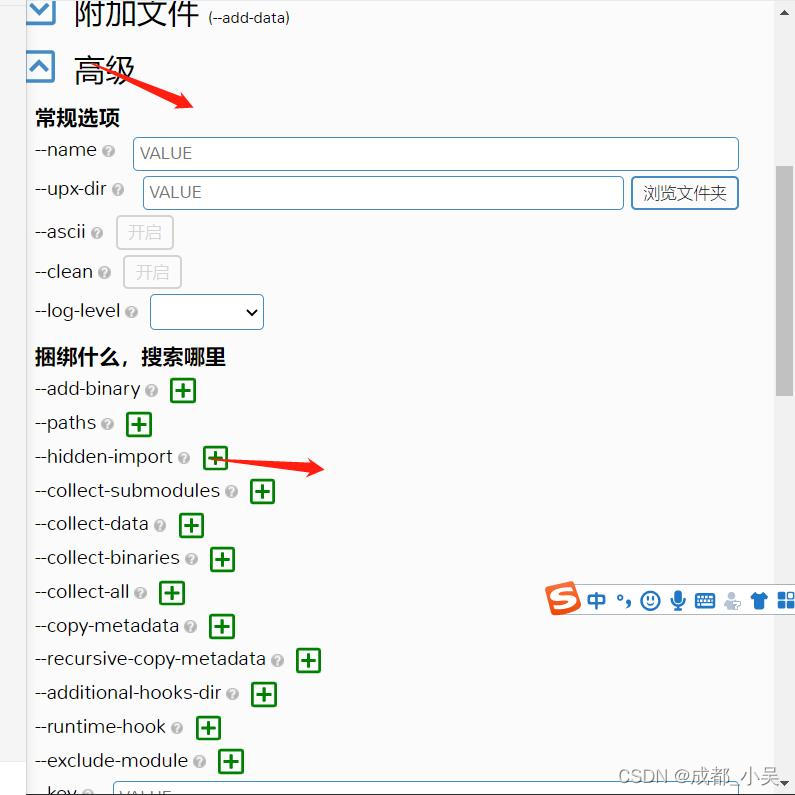
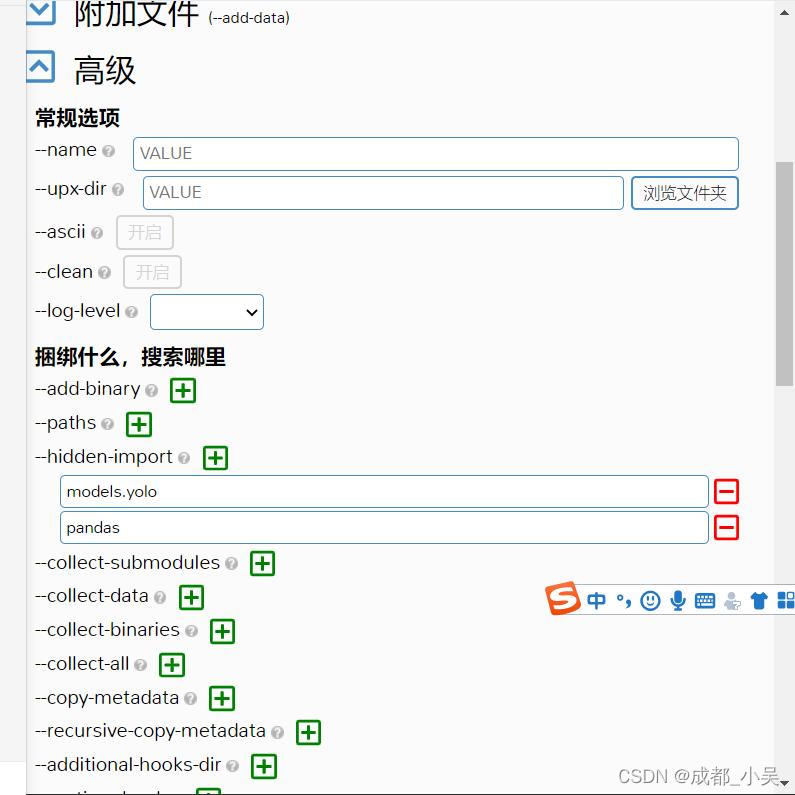
這里的pandas一般都會出錯,所以我們在之前直接添加,
選擇你的輸出路徑
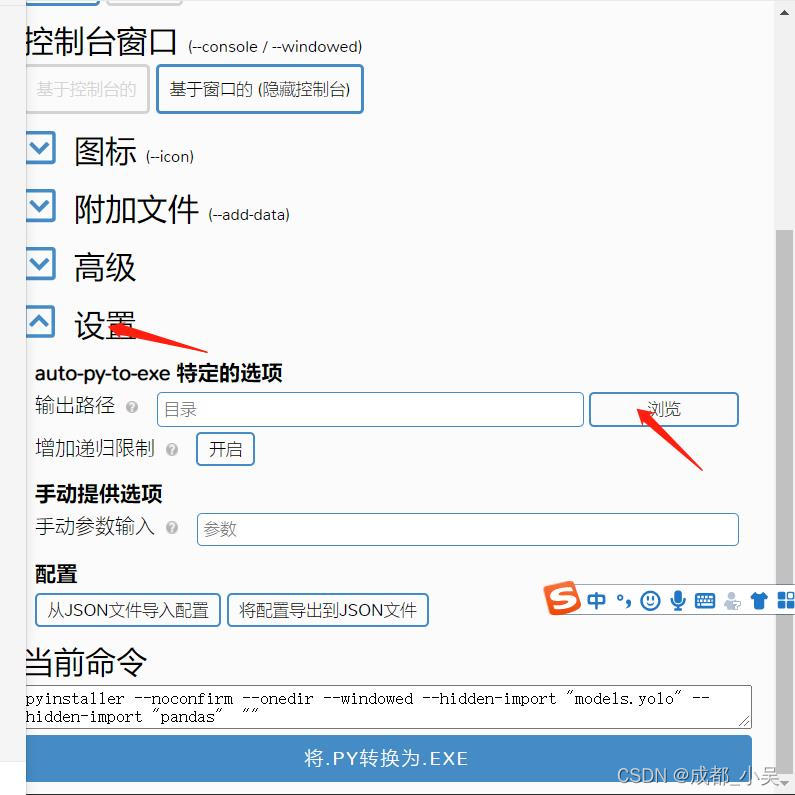
耐心等待幾分鐘,錯誤就出現了!
SystemExit: Unable to find "d:\anaconda3\envs\pytorch\Library\bin\libiomp5md.dll" when adding binary類似這種問題什么找不到啊,你就直接去這個路徑下面搜索一下,如果不存在就去你的回收站是不是把他刪了,要不然就去下載,
assert mpl_data_dir, "Failed to determine matplotlib's data directory!"
AssertionError: Failed to determine matplotlib's data directory!這個問題大家可能也會遇到,有的大佬說先把matplotlib卸載了再打包,這樣確實不會影響自己的打包,但是你打包出來的EXE無法運行,所以最好的解決辦法就是,先卸載掉這個,更新自己的PIP,再重新下載:
#首先進入自己的環境
pip uninstall matplotlib
python -m pip install --upgrade pip
#更新完之后
pip install matplotlib像這樣HOOK的問題:
PyInstaller.exceptions.ImportErrorWhenRunningHook: Failed to import module __PyInstaller_hooks_18_pandas_io_formats_style required by hook for module d:\anaconda3\envs\pytorch\lib\site-packages\PyInstaller\hooks\hook-pandas.io.formats.style.py.1.卸載和重新安裝pyinstaller
pip uninstall pyinstaller
pip install pyinstaller
2.報錯肯能是由于環境中安裝了過時的 IPython 引起的,我們可以嘗試將其更新到更新的版本,
#進入你的環境
pip install --upgrade IPython
這兩個應該就可以解決打包的問題了!
打包這種大型的EXE我建議還是單目錄進行打包,方便解決問題,
然后你就會得到一個像這樣的一個目錄:
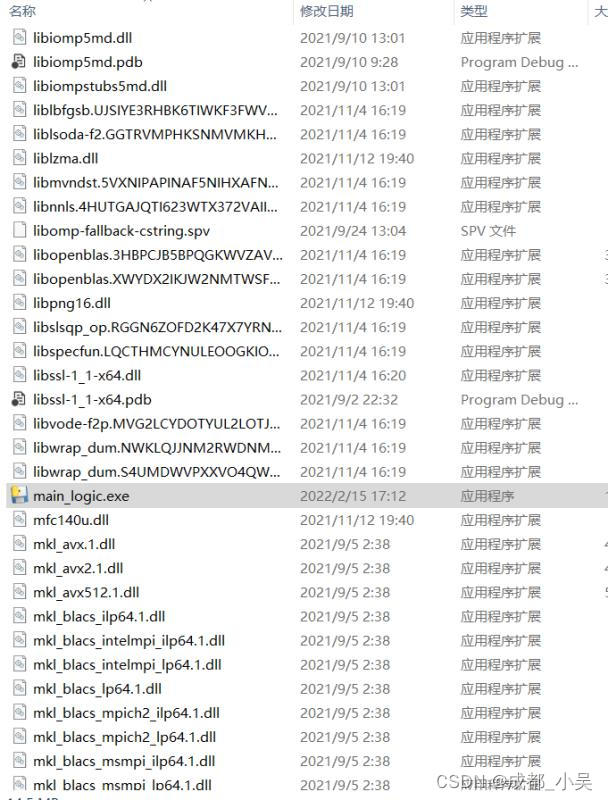
你已經迫不及待的點擊它了,反應非常的慢,你會發現你還是運行不起來還是會報錯:
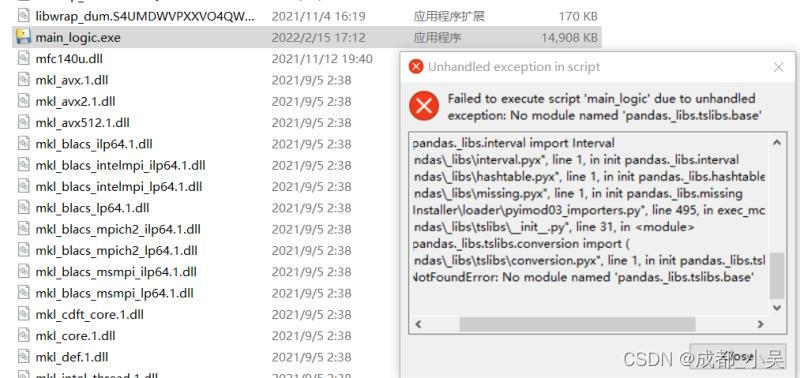
很痛苦在網上瘋狂的百度搜索,后來發現:你的打包pandas目錄里面和你的本機pandas少了一個檔案如下:
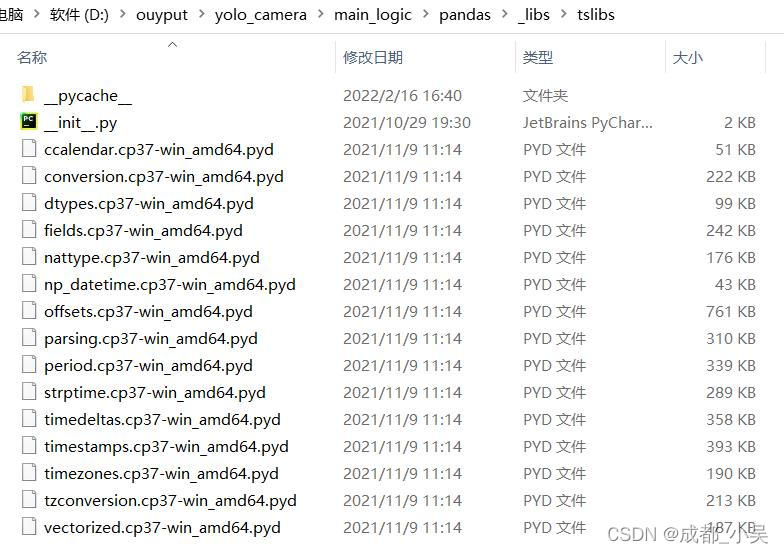
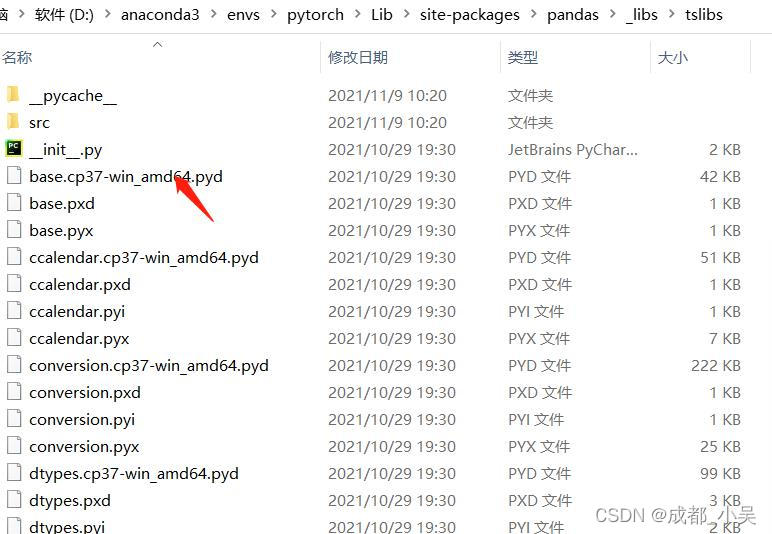
大家可以看到少了一個這個檔案,所以把他復制到你的打包檔案里面就可以了;讓我們運行一下試試,果然可以運行了,

到這里你以為就結束了?還是太年輕了,你會發現你點擊登錄卡死在登錄界面,這又是為什么呢?因為你要匯入你的賬號和密碼登錄表,這個原因我找了很久不知道為什么,如下的一個檔案:
OK,匯入到你的根目錄他就可以跳轉到你的主界面了,你可以拿著你的攝像機出去檢測了,
四.總結
這個專案大約做了兩三個月吧,對于菜鳥級別的我慢慢成長才是關鍵,如果大家有什么好的意見或者咨詢一些問題的話可以加入QQ群:135163517,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/427493.html
標籤:AI
上一篇:清華姚班陳丹琦等27位華人學者獲獎,斯隆獎2022年獲獎名單頒布
下一篇:2022年美賽思路題解