🌰 昨天我們學習完Table API后,今天我們繼續學SQL,Table API和SQL可以處理SQL語言撰寫的查詢陳述句,但是這些查詢需要嵌入用Java、Scala和python撰寫的程式中,
- hadoop專題: hadoop系列文章.
- spark專題: spark系列文章.
- flink專題: Flink系列文章.
🌱flink sql只需要具備 SQL 的基礎知識即可,不需要其他編程經驗,我的SQL 客戶端選擇的是docker安裝的Flink SQL Click,大家根據自己的需求安裝即可,
目錄
- 1. SQL客戶端
- 2. SQL陳述句
- 2.1 create
- 2.2 drop
- 2.3 alter
- 2.4 insert
- 2.5 show
- 3. Window Functions
- 3.1 滾動視窗 TUMBLE
- 3.2 滑動視窗 HOP
- 3.3 累計視窗 CUMULATE
- 4. 其他函式
- 5. 總結
- 6. 參考資料
1. SQL客戶端
SQL客戶端內置在Flink的版本中,大家只要啟動即可,我使用的是docker環境中配置的Flink SQL Click,讓我們測驗一下:
輸入’helloworld’ 看看輸出的結果,
SELECT ‘hello world’;
結果如下:說明運行成功!

2. SQL陳述句
2.1 create
CREATE 陳述句用于向當前或指定的 Catalog 中注冊表、視圖或函式,注冊后的表、視圖和函式可以在 SQL 查詢中使用,
CREATE TABLE [IF NOT EXISTS] [catalog_name.][db_name.]table_name
(
{ <physical_column_definition> | <metadata_column_definition> | <computed_column_definition> }[ , ...n]
[ <watermark_definition> ]
[ <table_constraint> ][ , ...n]
)
[COMMENT table_comment]
[PARTITIONED BY (partition_column_name1, partition_column_name2, ...)]
WITH (key1=val1, key2=val2, ...)
[ LIKE source_table [( <like_options> )] ]
-- 例如
CREATE TABLE Orders_with_watermark (
`user` BIGINT,
product STRING,
order_time TIMESTAMP(3),
WATERMARK FOR order_time AS order_time - INTERVAL '5' SECOND
) WITH (
'connector' = 'kafka',
'scan.startup.mode' = 'latest-offset'
);
2.2 drop
DROP 陳述句可用于洗掉指定的 catalog,也可用于從當前或指定的 Catalog 中洗掉一個已經注冊的表、視圖或函式,
--洗掉表
DROP TABLE [IF EXISTS] [catalog_name.][db_name.]table_name
--洗掉資料庫
DROP DATABASE [IF EXISTS] [catalog_name.]db_name [ (RESTRICT | CASCADE) ]
--洗掉視圖
DROP [TEMPORARY] VIEW [IF EXISTS] [catalog_name.][db_name.]view_name
--洗掉函式
DROP [TEMPORARY|TEMPORARY SYSTEM] FUNCTION [IF EXISTS] [catalog_name.][db_name.]function_name;
2.3 alter
ALTER 陳述句用于修改一個已經在 Catalog 中注冊的表、視圖或函式定義,
--修改表名
ALTER TABLE [catalog_name.][db_name.]table_name RENAME TO new_table_name
--設定或修改表屬性
ALTER TABLE [catalog_name.][db_name.]table_name SET (key1=val1, key2=val2, ...)
--修改視圖名
ALTER VIEW [catalog_name.][db_name.]view_name RENAME TO new_view_name
--在資料庫中設定一個或多個屬性,若個別屬性已經在資料庫中設定,將會使用新值覆寫舊值,
ALTER DATABASE [catalog_name.]db_name SET (key1=val1, key2=val2, ...)
2.4 insert
INSERT 陳述句用來向表中添加行(INTO是追加,OVERWRITE是覆寫)
-- 1. 插入別的表的資料
INSERT { INTO | OVERWRITE } [catalog_name.][db_name.]table_name [PARTITION part_spec] select_statement
-- 2. 將值插入表中
INSERT { INTO | OVERWRITE } [catalog_name.][db_name.]table_name VALUES [values_row , values_row ...]
-- 追加行到該靜態磁區中 (date='2019-8-30', country='China')
INSERT INTO country_page_view PARTITION (date='2019-8-30', country='China')
SELECT user, cnt FROM page_view_source;
-- 追加行到磁區 (date, country) 中,其中 date 是靜態磁區 '2019-8-30';country 是動態磁區,其值由每一行動態決定
INSERT INTO country_page_view PARTITION (date='2019-8-30')
SELECT user, cnt, country FROM page_view_source;
-- 覆寫行到靜態磁區 (date='2019-8-30', country='China')
INSERT OVERWRITE country_page_view PARTITION (date='2019-8-30', country='China')
SELECT user, cnt FROM page_view_source;
-- 覆寫行到磁區 (date, country) 中,其中 date 是靜態磁區 '2019-8-30';country 是動態磁區,其值由每一行動態決定
INSERT OVERWRITE country_page_view PARTITION (date='2019-8-30')
SELECT user, cnt, country FROM page_view_source;
2.5 show
show用于列出所有的catalog、database、function等
-- 列出catalog
SHOW CATALOGS;
-- 列出資料庫
SHOW DATABASES;
--列出表
SHOW TABLES;
-- 列出視圖
SHOW VIEWS;
--列出函式
SHOW FUNCTIONS;
-- 列出所有激活的 module
SHOW MODULES;
3. Window Functions
這里的Window Functions不是指我們sql中的視窗函式,是指處理流資料中特有的窗口操作,
3.1 滾動視窗 TUMBLE
TUMBLE函式把行分配到有固定間隔時間且不重疊的視窗上,滾動視窗在批處理和流處理可以定義在事件時間上,但只有流處理可以定義在處理時間上,
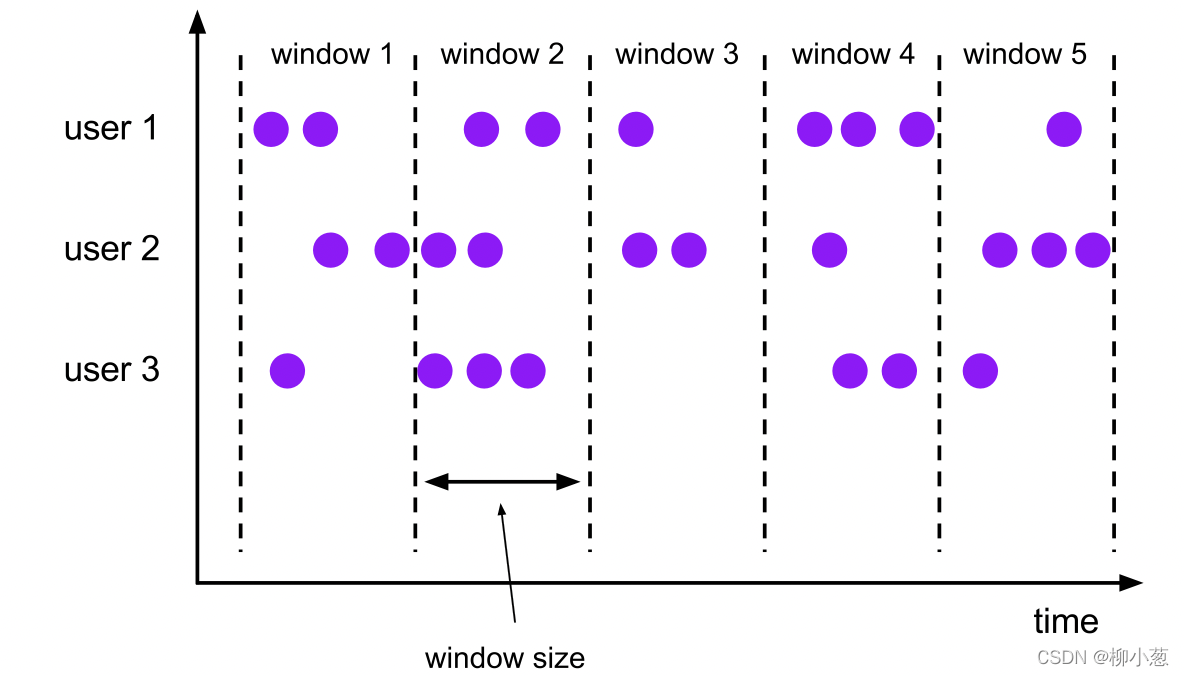
--1. TUMBLE函式的引數
TUMBLE(TABLE data, DESCRIPTOR(timecol), size [, offset ])
-- TABLE:代表資料源
-- DESCRIPTOR(timecol):指時間列
-- size:指視窗大小
-- offset:可增加其他引數,會有特別的意義
-- 2.實體
SELECT window_start, window_end, SUM(price)
FROM TABLE(
TUMBLE(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '10' MINUTES))
GROUP BY window_start, window_end;
3.2 滑動視窗 HOP
滑動視窗在批處理和流處理中可以定義在事件時間上,但只有流處理可以定義在處理時間上,(資料會有重復)
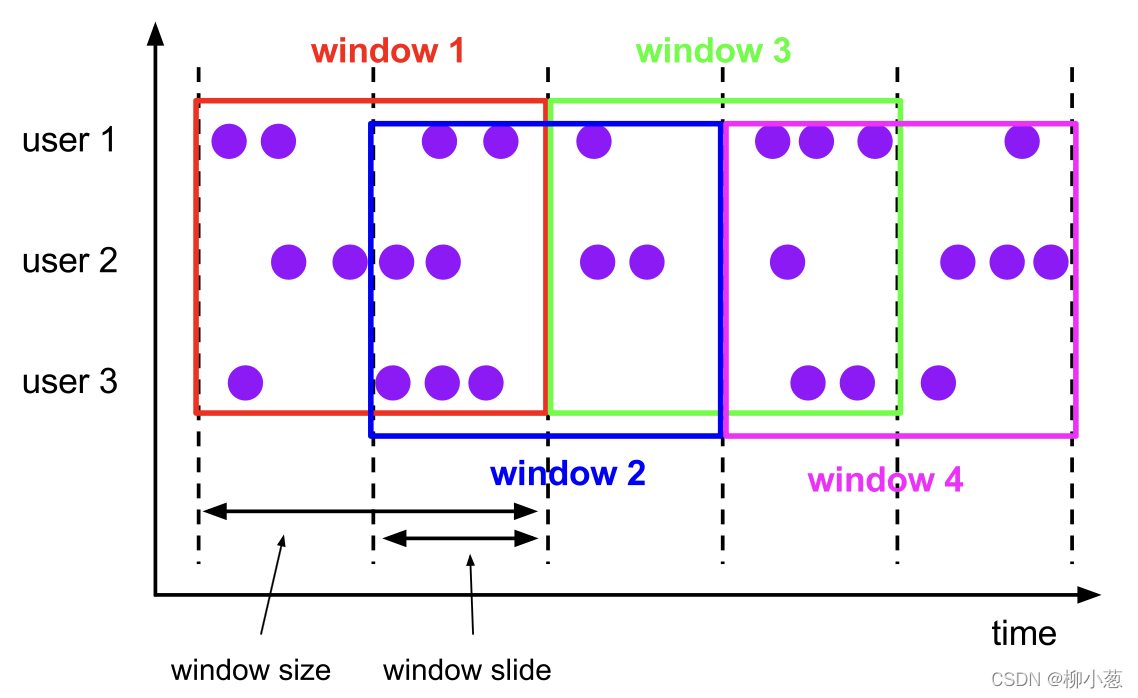
-- 1. HOP函式的引數
HOP(TABLE data, DESCRIPTOR(timecol), slide, size [, offset ])
-- TABLE:代表資料源
-- DESCRIPTOR(timecol):指時間列
-- slide:指視窗滑動的大小
-- size:指視窗大小
-- offset:可增加其他引數,會有特別的意義
-- 2.實體
SELECT window_start, window_end, SUM(price)
FROM TABLE(
CUMULATE(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '2' MINUTES, INTERVAL '10' MINUTES))
GROUP BY window_start, window_end;
3.3 累計視窗 CUMULATE
累計視窗是指在固定視窗內,每隔一段時間觸發操作,類似于滾動視窗內定時進行累計操作,
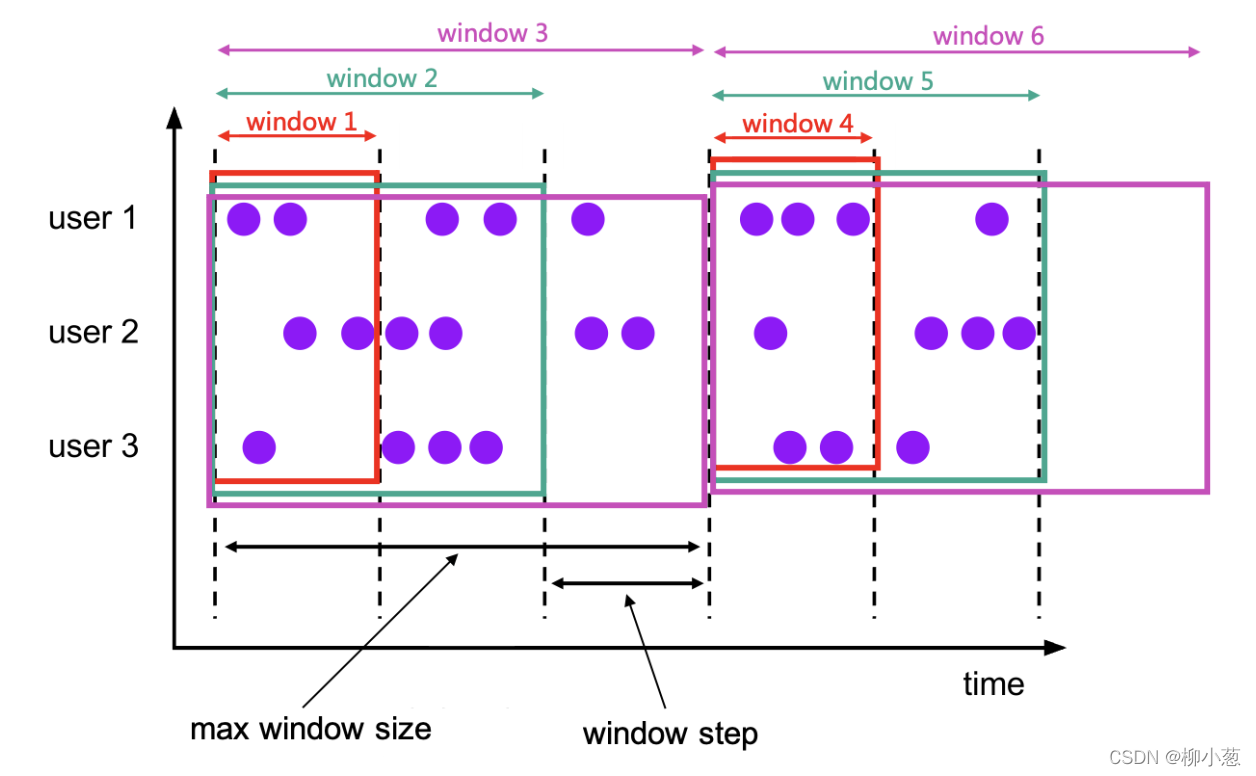
--1. 累計視窗的引數
CUMULATE(TABLE data, DESCRIPTOR(timecol), step, size)
--data: 和時間有關的資料源
--timecol: 時間列,資料的哪些時間屬性列應該映射到滾動視窗,
--step: 是指定順序累積視窗結束之間增加的視窗大小的持續時間,
--size: 是指定累積視窗最大寬度的持續時間,size 必須是 step 的整數倍,
-- offset:可增加其他引數,會有特別的意義
-- 實體
SELECT window_start, window_end, SUM(price)
FROM TABLE(
CUMULATE(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '2' MINUTES, INTERVAL '10' MINUTES))
GROUP BY window_start, window_end;
4. 其他函式
處理上述這些,剩下還有的操作都是和我們的SQL語法差不多,就不再闡述:
- 視窗聚合函式:group by、…
- 分組聚合函式:count、having、count(distinct xxx)、…
- over聚合函式:over(partition by xxx order by xxx)、…
- 內外連接函式:join、left join 、outer join、…
- limit 函式
- TOP-N函式: rank()、dense_rank()、row_number()
對以上內容感興趣的小伙伴可以參考如下鏈接:
- SQL教程: SQL專題-各部分函式講解.
5. 總結
今天學習的sql,和往常不一樣的地方在于,以往的sql都是處理的是批資料,而今天學習的flink sql可以處理流資料,流資料隨著時間的變化而變化,flink sql可以對流資料進行類似表一樣的處理,可以實作大部分DataStream API和DataSet API的功能,
😂還有就是,flink sql中的視窗函式和我們傳統的視窗函式不一樣,按理來說,我們正常的視窗函式應該叫over聚合函式,
6. 參考資料
《Flink入門與實戰》
《PyDocs》(pyflink官方檔案)
《Kafka權威指南》
《Apache Flink 必知必會》
《Apache Flink 零基礎入門》
《Flink 基礎教程》
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/428574.html
標籤:其他
上一篇:R語言使用head函式獲取dataframe的頭部資料、使用tail函式獲取dataframe的尾部資料、使用引數n指定獲取的個數