一、性能基礎
什么是性能測驗--->本質?
基于協議來模擬用戶發送的請求(業務模擬),對服務器形成一定負載,
關注點:時間性能、空間性能
與界面無關
性能測驗分類
-
性能測驗(狹義)
性能測驗方法是通過模擬生產環境運行的業務壓力量和使用場景組合,測驗系統性能是否滿足生產性能要求,通俗地講,這種方法就是要在特定的運行條件下來驗證系統能力狀態,
-
負載測驗
通過在被測系統上進行不斷加壓,直到性能指標達到極限,例如“回應時間”超過了預定指標或都某種資源已經達到了飽和狀態,
-
壓力測驗(強度測驗)
壓力測驗方法,測驗系統在一定飽和狀態下,例如cpu、記憶體在飽和使用情況下,系統能夠處理的會話能力,及系統是否會出現錯誤,
-
并發測驗
并發測驗方法通過模擬用戶并發的訪問,測驗多用戶并發訪問同一應用、同一模塊或資料記錄時,是否死鎖或其他性能問題,
-
配置測驗
配置測驗方法通過對被測系統軟\硬體環境調整,了解各種不同對系統性能影響程度,找到系統各項資源最優分配原則,
-
可靠性測驗
在給系統加載一定業務壓力情況下,使系統運行一定時間,來檢測系統是否穩定,
常見的性能測驗指標
-
用戶數
并發用戶數在同一時間向服務器發送請求的用戶數量
與每秒的并發請求數不同,一定要確認需求的目的是并發用戶數還是并發請求數 -
吞吐量(Throughput)
說明:單位時間內處理客戶端請求數量,直接體現軟體系統性能承載能力,
通常情況下,吞吐量用"請求數/秒"或"頁面數/秒"來衡量,
提示:
1.從業務角度看,吞吐量可以用"業務數/小時"、"訪問人數/天"、"業務數/天","業務訪問量/天"去衡量,
2.從網路角度看,還可以用"位元組數/天"、"位元組數/小時"等來衡量網路流量,
3.每秒事務數(TPS)、每秒查詢數(QPS)都歸屬吞吐量,區別是TPS\QPS描述服務器具體性能處理的能力,
-
并發數
說明:并發測驗的用戶數
擴展:
并發用戶數:某一物理時刻同時向系統發送請求的用戶數,
在線用戶數:某段時間內訪問系統的用戶數,這些用戶不一定都是同時向系統來提交請求,
系統用戶數:系統注冊的總用戶資料,
-
回應時間
說明:用戶從客戶端發起一個請求開始,到客戶端接收到從服務器端回傳結果整個程序中所消耗的時間,
-
點擊數
說明:衡量web服務器處理能力的重要指標,
提示:
1.點擊數并不是大家認為的訪問一個頁面就是1個點擊數,點擊數是頁面中包含的元素(如:圖片、鏈接等)向web服務器發出請求數數量,
2.通常會用每秒點擊次數(Hits per Second)指標來衡量web服務器的處理能力,
注意:
只有web專案才有指標,
-
資源利用率
說明:指系統各種資源的使用情況,使用率=已使用的資源/全部的資源x100%
常見的資源使用率指標:
CPU,不超過80%
記憶體,不超過80%
磁盤,不高于90%
網路,不超過80%
如果資源利用率太小,也是造成資源浪費
-
錯誤率
說明:指系統各個資源的使用情況,一般使用"資源的使用量/總的資源可用量x100%"生成資源利用率的資料,
提示:通常,沒有什么特殊需求的話
1.不同系統對錯誤率要求不同,但一般不超過千分之五---(根據實際專案而定萬分之五等等),
2.穩定性較好的系統,其錯誤率應該是由超時引起的---超時率,
-
TPS(Transactions Per Second)
說明:每秒的事務數(單位時間內系統處理客戶端請求事務次數)
計算:tps=并發數/平均回應時間
事務:業務站在代碼角度的統稱,可以理解為一段或多段代碼,
提示:TPS歸屬吞吐量
-
QPS(Query Per Second)
說明:每秒查詢數(衡量web服務器處理能力的一個重要指標)
應用:控制服務器每秒處理指定請求數(如:控制服務器達到每秒60qps,服務器的性能各項性能指標是否正常),
二、性能測驗流程
流程圖
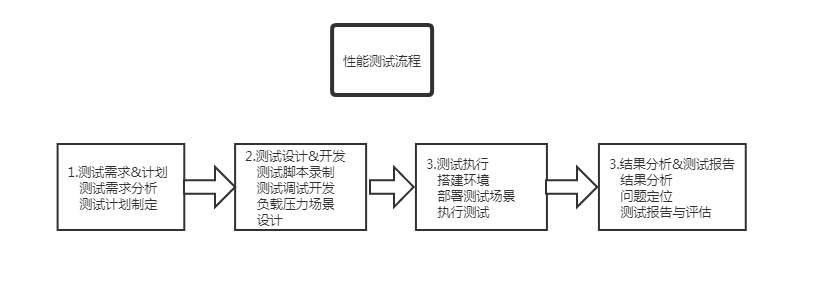
需求分析
-
測驗物件
-
常用的
-
核心的,重要的
-
資料量、并發量
-
例子:
注冊、登錄、搜索、添加購物車、下訂單、支付
-
-
確定性能指標
-
吞吐量、TPS
服務器每秒處理的請求數量 -
回應時間
從瀏覽器發出請求,服務器處理,到收到回應所需要的處理時間
-
用戶數
-
資源利用率
-
例子:
例子一:要求每天完成交易額2億,求每秒鐘最大交易數? 客單價:200-500,以300計算 采用28定律換算得出,以24小時計算 2/8原則:80%的用戶請求,集中在20%的熱點資料上,或時間段 計算公式:(200000000/300*0.8)/(24/0.2)/3600s=30.86個/s例子二:每天8小時系統支付500萬用戶訪問 1.500萬在8小時內完成,500萬/8*3600,一般不采用,除非系統負載比較平穩/平均 2.先分析流量分布,再根據2/8定律估算每秒請求 80%的用戶數:500*0.8=400w 20%的時間內:8*0.2=1.6h 計算得出服務器需要支持694次/s--->500*0.8/(8*0.2)/3600s 每小時的平均負載*4(估算,不建議此計算) -
-
測驗場景
-
單一場景
登錄
注冊
搜索
添加購物車
下單、支付
-
混合場景
用戶使用場景
系統使用場景
-
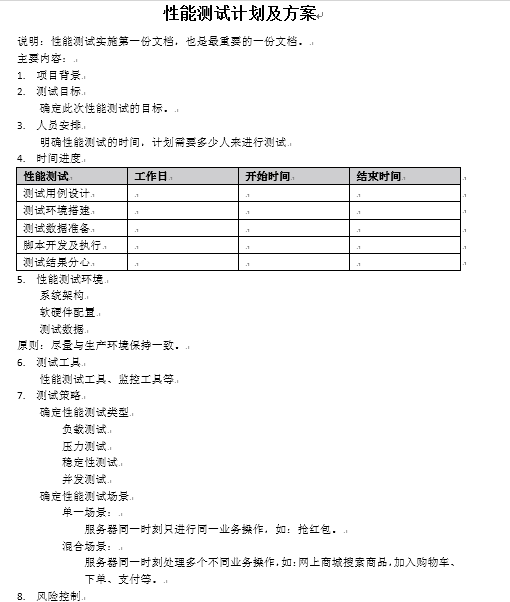
測驗計劃
-
測驗目標
-
測驗人員組織
-
壓測進度安排
-
壓力機
- 配置
- 要求
- 數量
-
風險
測驗方案
-
測驗工具
loadrunner
jmeter
-
測驗環境
資料庫
服務器
架構設計
有條件的情況下盡量和生產環境一致
-
測驗策略
單一場景
混合場景 -
監控工具
- Linux
nmon
rpc
jvisualVm
Spotlight - windows
Spotlight
perfmon.exe
- Linux
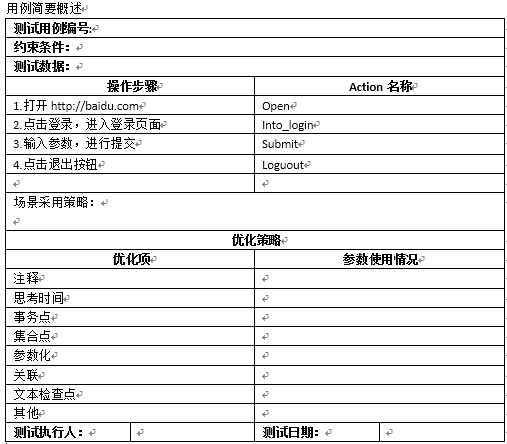
用例設計
-
測驗腳本
基于腳本的用例 -
場景設計
基于場景的用例
測驗執行
-
腳本撰寫
-
場景監控設計
業務設計-
場景搭建
說明:測驗場景設計重要的原則就是依據測驗用例,把用例設計場景進行展現出來,
提示: 1.虛擬用戶數量及啟動虛擬用戶方式 2.場景相關的設定(如:集合點) 3.腳本是否有依賴關系(如:登錄與注冊)
-
-
運行場景
說明:運行腳本就是運行場景
1.負載的測驗機不能夠運行設定的虛擬用戶數 2.沒有"預熱"程序 3.沒有模擬用戶的真實環境 4.性能用例運行次數過少 -
監控場景
-
測驗報告
定位分析問題
- 后端
- 代碼
- 軟體(服務)
資料庫
應用服務器 - 硬體
- 前端
- 網路
測驗定位問題順序:硬體問題--->網路問題--->應用服務器、資料庫服務器配置問題--->源代碼、資料庫腳本--->系統架構問題
性能調優
性能測驗人員經過對測驗結果的對比,發現系統性能的瓶頸,
提示:
1.調優人員:以開發為主導,資料庫管理員、系統管理員、網路管理員、性能測驗分析人員配合進行性能問題的調優
2.驗證:性能測驗驗證通常需要很多輪;每輪回歸時需要對所有的測驗指標進行全方位的對比
系統調優由易到難的順序:
- 硬體問題
- 網路問題
- 應用服務器、資料庫服務器配置問題
- 源代碼、資料庫腳本
- 系統架構問題
測驗報告
-
對整體性能測驗階段的回顧(覆寫需求、測驗不同階段的進度和產物、性能測驗結果的分析)--->技術角度
-
對整體性能測驗階段風險的管理--->管理的角度
-
對專案性能測驗結果的總結(是否通過,經驗、教訓)
三、工具介紹及選型
LoadRunner
- 工業化的性能測驗工具,能支持大量用戶,提供詳細的報表來提供測驗分析的數量
- 支持的協議多
- 使用C語言來撰寫的
優點
1.支持用戶量大(以萬為單位)
2.提供精確的報表
3.支持ip欺騙
缺點
1.收費
2.體積大
3.無法定制
Jmeter
jmeter是Apache組織基于java開發的一款性能測驗軟體,多協議(HTTP/HTTPS、JDBC、JAVA...等等)
優點
1.開源免費
2.體積小
3.有豐富的第三方插件
缺點
1.不支持ip欺騙
2.報表的精度比LR要差
LoadRunner與Jmeter之間該如何選擇?
- 優選選擇Jmeter
- Jmeter能解決用Jmeter,Jmeter解決不了的用LoadRunner
四、Jmeter工具使用
檔案目錄介紹
1.1 bin目錄
存放可執行檔案和組態檔
jmeter.bat:windows的啟動檔案
jmeter.log:日志檔案
jmeter.sh:linux的啟動檔案
jmeter-properties:系統組態檔
jmeter-server.bat:windows分布式測驗要用到的服務器配置
jmeter-server:linux分布式測驗要用到的服務器配置
1.2 docs目錄
docs:是Jmeter的api檔案,可打開api/index.html頁面來查看
1.3 printable_docs目錄
printable_docs的usermanual子目錄下的內容是Jmeter的用戶手冊檔案,
usermanual下component_reference.html是最常用到的核心元件幫助檔案,
提示:printable_docs的demos子目錄下有些常用Jmeter腳本案例,可以參考,
1.4 lib目錄
該目錄用來存放Jmeter依賴的jar包和用戶擴展所依賴的jar包,
基礎配置
漢化設定
-
臨時修改:
? options--->language--->choose language--->Chinese
-
永久修改:
-
打開jmeter.properties
-
修改language=zh_CN
-
重啟jmeter
-
主題修改
選項--->主題--->選擇對應的主題,重啟jmeter
基本操作
- 啟動jmeter
- 添加執行緒組
- 添加http請求的取樣器,并配置
- 添加查詢結果樹的監聽器
- 點擊"啟動"運行jmeter,并查看結果
基本元件
執行緒組:模擬用戶的,
配置元件:進行測驗環境和測驗資料初始化--->比如自動化腳本中setup
前置處理器:對要發送請求進行預處理--->比如自動化腳本中引數化
取樣器:往服務器發送請求--->比如自動化腳本中發請求的代碼
后置處理器:對收到服務器的回應進行資料提取--->比如自動化腳本中獲取回應中特定欄位陳述句
斷言:將收到回應結果又預期結果做對比--->比如自動化腳本中斷言
監聽器:查看測驗腳本運行后結果和日志--->比如自動化腳本中測驗報告
定時器:等待一段時間--->比如自動化腳本中sleep
測驗片段:封裝基本功能,不單獨執行,需要通過腳本的呼叫才能執行--->比如自動化腳本中封裝函式
作用域
核心:根據測驗計劃中的樹形結構的父子節點來確定的
原則:
- 取樣器是沒有作用域的,
- 邏輯控制器:只對其子節點下的所有元件有效,
- 其他的元件,
- 如果其父節點是取樣器,則只對父節點取樣器有效,
- 如果其父節點不是取樣器,對父節點下所有子節點及節點中子節點有效,
元件的執行順序
順序:配置元件--->前置處理器--->定時器--->取樣器--->后置處理器--->斷言--->監聽器
注意:
- 配置元件、前置處理器、后置處理器都需要依賴取樣器才能運行
- 在同一個作用域下,相同型別元件執行順序是從上到下來按順序執行
Jemter重要的三個組件
執行緒組
作用:通過配置執行緒組中的執行緒數來模擬用戶,執行緒數就是用戶數,執行緒組是用戶組
特點:
- 模擬多用戶
- 取樣器和邏輯控制器必須在執行緒組下使用
- 一個測驗計劃下可以添加多個執行緒組,可以并行或串行執行
- 并行:默認情況下執行緒組為并行執行
- 串行:在測驗計劃下勾上"獨立運行每個執行緒組"
執行緒組的分類:
- setup執行緒組:擁有測驗前預處理操作,在所有執行緒組中最先執行
- 普通執行緒組:來執行業務測驗腳本
- teardown執行緒組:用來測驗后的后置處理(資料、恢復環境)的操作,在所有的執行緒組中最后執行
執行緒組的屬性
執行緒數:模擬虛擬用戶數
Ramp-up時間:虛擬用戶啟動所需要的時間
回圈次數:
- 配置指定次數:控制腳本運行執行的次數
- 配置回圈永遠
- 需要調度器配置使用
- 運行時間:腳本執行的時間
- 延遲啟動時間:腳本等待特定的時間才能開始運行
http請求
http協議:可以填寫為HTTP或者HTTPS,默認不填寫為HTTP協議
http主機名/ip:如:http://baidu.com 80
埠:可以填寫為任意值,默認不填寫時為80埠
請求發方法:HTTP協議所有支持的所有方法
? 路徑:目錄+引數
? 編碼格式:默認IOS國際標準,推薦使用utf-8
查看結果樹
取樣器結果:統計請求相關的資訊
請求:HTTP請求的請求頭和請求體的詳情資訊
回應:HTTP回應的回應頭和回應體的詳情資訊
jmeter回應中出現亂碼時:
- 修改jmeter.properties檔案中,sampleresult.default.encoding=utf-8
- 重啟jmeter
Jmeter引數化常用方式
用戶定義的變數
- 方式1:
添加:執行緒組--->配置元件--->用戶自定義變數
配置:引數名+引數值
使用:在HTTP請求的取樣器中參考定義變數,$(引數名)
- 方式2:
配置:在測驗計劃中去配置用戶定義變數
使用:在HTTP請求的取樣器中參考定義變數,$(引數名)
應用場景:當大量腳本中的引數值需要修改時候,直接修改用戶定義變數中值會更方便
用戶引數
添加:執行緒組--->前置處理器--->用戶引數
配置:
- 引數:添加變數
- 引數值:添加用戶--->針對每個用戶配置不同的引數值
使用:在HTTP請求的取樣器中參考定義的變數,$(引數名)
應用場景:可以針對不同的用戶獲取到不同的引數值
CSV Data Set Config
添加:執行緒組--->配置元件--->CSV資料檔案設定
撰寫CSV資料檔案(.csv作為后綴):
- 多個引數寫為多列,其中用逗號分隔
- 多組引數值,則使用多行來設定
配置:
- 路徑
- 檔案編碼:UTF-8
- 變數名稱:從CSV資料檔案中讀取的資料需要保存變數名,有多個變數時用逗號分隔
- 是否忽略首行:是否從CSV檔案第一行中開始讀取
- 分隔符:要求與CSV資料檔案中多列的分隔符一致
- 遇到檔案結束符是否再次回圈:默認TRUE
- 遇到檔案結束符是否停止執行緒:當前一個引數為FALSE,該引數有效,一般設定為TRUE
函式
counter:
- TRUE:每個用戶使用獨立計數器
- FALSE:所有的用戶使用全域計數器
參考:在取樣器中使用$(__counter(FALSE,))來參考對應值
建議大家使用函式方式
Jmeter斷言
作用:讓腳本自動化執行程序中,能夠自動判定執行結果是否符合要求時候,需要添加斷言
回應斷言
添加:執行緒組--->HTTP請求--->斷言--->回應斷言
配置:
- 測驗欄位:需要檢查的欄位
- 模式匹配規則:需要使用什么規則來進行檢查
- 測驗模式:需要校驗的值
Json斷言
適用于回傳的HTTP回應為JSON格式
添加:執行緒組--->HTTP請求--->斷言--->JSON斷言
配置:
- JSON PATH:$.weatherinfo.city
- 勾選"Addltonal assert value"
- 在expected value里填寫期望值
斷言持續時間:
適用于性能測驗時,檢查HTTP請求的回應時間是否超過預期值
添加:執行緒組--->HTTP請求--->斷言--->斷言持續時間
配置:預期時間
Jmeter關聯(提取器、資料庫、邏輯控制器等)
當多個請求之間有依賴關系,后一個請求的引數需要使用前一個請求的回應資料時,需要用到關聯,
分類:
- 正則運算式提取器
- xpath提取器
- Json提取器
提取器
正則提取器
添加:執行緒組--->HTTP請求--->后置處理器--->正則運算式提取器
配置:
- 要檢查的回應欄位:默認主體
- 參考名稱:匹配后的資料要存盤的變數名
- 正則運算式:
<p>(.*?)</p>,"()"里是要保存的資料 - 模板:$1$
- 資料1代表上面正則運算式中第幾個()
- 匹配數字:0代表隨機值、1代表第一個結果,-1代表所有結果
- 預設值:當沒有匹配上時將該值保存到變數里
xpath提取器
添加:執行緒組--->HTTP請求--->后置處理器--->xpath提取器
配置:
- 參考名稱:匹配后的資料要存盤的變數名
- xpath path:xpath匹配規則
- 匹配數字:0代表隨機值、1代表第一個結果,-1代表所有結果
- 預設值:當沒有匹配上時將該值保存到變數里
json提取器
添加:執行緒組--->HTTP請求--->后置處理器--->json提取器
配置:
- 參考名稱:匹配后的資料要存盤的變數名
- json path:json路徑,$.weatherinfo.city
參考:直接參考變數名即可
資料庫
連接準備:
- 打開資料庫,確定資料庫的表及對應的欄位
- 加載mysql的jdbc驅動
- 方法一:將jdbc驅動通過測驗計劃,瀏覽的方式添加
- 方式二:將jdbc驅動jar包放入到lib\ext目錄下,并重啟jmeter
- 配置jdbc connection configuration
- created pool name:給連接池命名,用于后續參考
- 資料庫URL:jdbc:mysql://127.0.0.1:3306/test
- 用戶名
- 密碼
直連資料庫使用:
- 添加JDBC Request:取樣器下添加
- 配置:
- 配置連接池名稱
- 配置SQL陳述句
- 配置保存的變數名
- 如果SQL陳述句回傳了多個引數,輸入相同個數的變數名來保存
- HTTP斷言中,就可以參考變數來進行判斷
邏輯控制器
控制元件的執行順序
if控制器
添加:執行緒組--->邏輯控制器--->if控制器
配置:
- 使用JS預發:"${name}"=="baidu"
- 使用jmeter函式的方式:${__jexl3("${name}"=="baidu",)}
- 推薦使用函式的方式
回圈控制器
指定HTTP請求執行特定的次數
添加:執行緒組--->邏輯控制器--->回圈控制器
配置:次數
回圈控制器中的回圈次數配置m與執行緒組中的回圈次數n配置對比:
- 關系:如果同時配置,回圈控制器下HTTP請求實際執行的次數應該是n*m
- 區別:這兩個回圈次數作用域不同
ForEach控制器
與用戶定義的變數或正則運算式提取器配合使用,回圈讀取回傳的變數值,執行一次或多次,
-
與用戶定義的變數配合
添加:執行緒組--->邏輯控制器--->ForEach控制器
配置:
-
用戶定義的變數
- 變數名:固定前綴+連續數字
-
ForEach控制器
- 變數前綴:用戶定義的變數中配置的固定前綴
- 起始數字:連續數字的最小值-1
- 結束數字:連續數字的最大值
- 輸出變數名稱:依次讀取變數值后存盤到引數中,共HTTP請求來參考
-
HTTP請求:
- 參考輸出的變數名稱
-
-
與正則運算式配合使用
- 先通過正則運算式提取器,提取出請求中所有滿足條件資料
- 添加ForEach控制器,并配置提取所有滿足條件的資料,并保存為變數
- 在其子節點下,添加HTTP請求并參考變數,可回圈讀取正則運算式里匹配的所有資料
定時器
同步定時器
需要進行大量用戶的并發測驗時,為了讓用戶能真正同時執行,添加"同步定時器"使其阻塞執行緒,直到執行緒達到了預先設定數值,才開始進行取樣器操作,
配置:
-
并發數:同時達到多少用戶才開始發請求
-
超時時間:
- 必須配置:否則當虛擬用戶數無法被并發數整除時,會導致有部分用戶掛起無法執行
- 配置不能太短:必須比并發數加載時間要長,否則無法達到并發數的要求,資料就會被釋放掉
常數吞吐量定時器
用于性能測驗中模擬用戶產生業務壓力,通過給定QPS來對服務器發送固定頻率要求,
添加:執行緒組--->HTTP取樣器--->常數吞吐量定時器
配置:吞吐量的值QPS*60
分布式
原理:
- 分布式測驗時分為一臺控制機和多臺代理機
- 控制機負責發布測驗任務給代理機
- 代理機接收任務并向服務器發送請求,并接收服務器回傳的回應,然后將測驗結果回傳給控制機
- 由控制機對測驗結果資料進行匯總統計
分布式相關注意事項:
- 所有的測驗機防火墻都已經關閉
- 所有的測驗機及服務器在同一個網路內
- 所有的測驗機的jmeter版本和JDK版本完全相同
- 關閉jmeter里的RMI SSL開關
分布式配置
配置
- 代理機
- server_port:不重復,如果使用多個機器做代理機,可不用配置
- 關閉RMI SSL
- 控制機
- remote_server:所有代理機的IP+port,有多個代理機時要使用逗號分隔
- 關閉RMI SSL
運行
- 代理機
- jmeter-server.bat運行
- 控制機:
- jmeter.bat運行
- 控制代理機執行腳本,運行--->遠程啟動所有
性能測驗常用術語解釋
性能測驗,有些專業術語,為了方便大家的理解,這里用通俗易懂的語言來解釋下,若有不準地方,謝謝糾正,
并發:tps
執行緒數:跑道中參加賽跑的人數
迭代:每人跑多少圈
回圈:一次迭代里面,回圈跑其中的一條腳本,就是重復來回跑其中一條跑道
引數值:發請求時用的資料
引數化:這是一種策略,上面有介紹到它的具體用法
思考時間:模擬用戶等待時間
關聯:下一個請求入參依賴上一個請求中的某個回傳值
檢查點:判斷請求的是否成功,一般只有查詢請求才會加檢查點,也就是斷言
集合點:等待所有用戶,同一時刻去發起請求,主要應用場景是購物中的秒殺
事務:一般把被測驗中某個或者某幾個請求一起定義成一個事務,是人為的測驗定義,可以是整個下單流程,也可以是下單中的一個請求
負載:服務器的繁忙程度,如果一個服務器,每次可以同時處理8個請求,如果請求數量大,后面請求就排隊,排隊請求越多,服務器負載就越高
平均回應時間(art):每個事務處理時間,從發送請求到接收到的回應
tps:每秒處理事務數
每秒點擊率(數):每秒處理請求數,而不是用戶每秒發送請求數
性能學習路線:
jmeter→java基礎→beanshell→架構知識→linux分析調優→各種中間件等定位調優
性能測驗,從0到實戰(包含熱門主流技術docker、k8s、skywalking、全鏈路、微服務、性能調優等)
熱門實戰性能測驗:https://www.cnblogs.com/upstudy/p/15916266.html
============================= 提升自己 ==========================微信公眾號獲取更多干貨:

> > > 咨詢交流、進群,請加微信,備注來意:sanshu1318 (←點擊獲取二維碼)
> > > 【自動化測驗實戰】python+requests+Pytest+Excel+Allure,測驗都在學的熱門技術:
https://www.cnblogs.com/upstudy/p/15901359.html
> > > 【熱門測驗技術,建議收藏備用】專案實戰、簡歷、筆試題、面試題、職業規劃:
https://www.cnblogs.com/upstudy/p/15901367.html
> > > 學習路線+測驗實用干貨精選匯總:
https://www.cnblogs.com/upstudy/p/15859768.html
> > > 宣告:如有侵權,請聯系洗掉,
============================= 升職加薪 ==========================
更多干貨,正在擠時間不斷更新中,敬請關注+期待,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/429269.html
標籤:其他
上一篇:XXE外部物體注入漏洞總結