Fast-r-cnn是Ross在2015年發表的一篇論文,其網路全稱為: Fast Region-based Convolutional Network method–用于目標檢測的基于區域的快速卷積網路演算法,

在于先前的網路R-CNN對比之下,其訓練速度要快9倍,檢測時間快出來213倍(R-CNN的檢測時間GPU作業下為47s一張圖片),同時在檢測精度上也作了進一步的提升,
一、任務簡介
在介紹中,作者提出目標檢測任務相比分類來說更為復雜和困難,首先計算機要處理眾多的候選目標區域(也就是proposals)、其次這些候選框只提供了檢測目標的大概位置,也就是說他所框中的物體可能并不是物體的全部,或者框內有很多不屬于物體的部分,這個時候還要對候選框進行位置修正,使其更加精確,
然后作者簡單介紹了一下R-CNN網路和SPPnet,將這兩個于Fast-RCNN網路經對比,來突出Fast-R-CNN的優勢所在,
1、更高的檢測質量
2、訓練使用了單價段演算法,損失函式使用多項損失
3、訓練可以更新所有網路層引數
4、快取特征不再需要磁盤存盤(在R-CNN網路中訓練一張圖片需要非常大的磁盤存盤空間)
二、網路整體架構
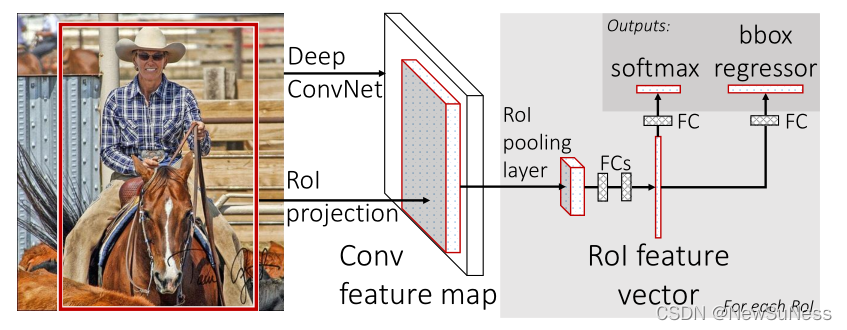
上圖就是原論文給出的網路整體架構,該網路將整張圖片作為輸入,然后經過卷積層和最大池化層得到特征圖,然后ROI池化層會從特征圖上提取到適合尺寸的物體候選特征向量、然后將提取到的特征向量送進去兩個全連接層后,將其作為同級輸出送入兩個全連接層,也就是圖片右上角的兩個FC(fully-connected layer),第一個鏈接softmax層輸出,第二個輸出四個真實的數字值來精細化對檢測物體框的位置,簡單點講就是一個輸出該框內的物體到除錯于哪一類,另外的一個輸出調整候選框的位置,讓候選框可以更加準確的框住被測目標,
1、ROI pooling層
該層使用最大池化層來將特征圖中感興趣的區域提取出來成固定HxW的尺寸特征圖,其尺寸H和W都是超引數,這一步人為決定該使用哪種大小的特征圖,也就是說原圖經過卷積和池化后變成了特征圖,然后ROI負責在特征圖中框選出來感興趣的區域,并使用池化操作將其變為固定尺寸的新特征圖, 每個特征圖都包含一個含四個引數的元組----(r, c, h, w), r,c表示ROI區域左上角的坐標,h表示ROI區域的高, w表示寬,
其實在這一步就可以看作是目標檢測的最終框的引數,左上角的點的坐標作為索引,然后指定長寬來形成一個矩形,
作者也提到了其實ROI層就相當于SPPnet里面的影像影像金字塔的特例,只不過其只含有一個層級而已,
2、網路模型
訓練網路的主體采用在ImageNet上的預訓練模型,然后在這上面進行修改,修改主要有三個程序:最后一個最大池化層被替換成ROIpooling層,這樣做的目的是使其與后面的全連接層引數匹配;網路最后的全連接層和softmax層被拆分為平行的一個全鏈接層和softmax層(對于上面圖片中的最后兩個層),其中softmax層具有K+1個類別,K為類別總數,多出來的一個為背景標簽;最后,該網路被修改為接受兩個資料作為輸入–用于訓練的圖片序列和圖片上的ROI區域,
3、精細修正檢測框
首先,作者說反向傳播訓練訓練所有網路引數是非常重要的,然后解釋了為什么SPPnet不能更新空間金字塔以后的權重引數—最根本的原因是在反向傳播時,當訓練樣本來自不同圖片時,SPP層的效率是非常低的,這個問題的來源是每個ROI都可能有很大的感受野,所以訓練時網路輸入會非常大,經常是整張圖片,
于是作者提出了一種更為有效的訓練方式,即訓練時采用特征共享,具體的做法就是從N張圖片中挑選出來R/N個ROI區域,然后在前向傳播與反向傳播時,同一張圖片的ROI區域共享計算和記憶體(無需重復存盤了),
三、損失函式
損失函式在網路訓練中非常重要,因為他為計算機提供了一個依靠指標,來使得計算機可以通過迭代調整引數來獲取我們想要的輸出結果,
在Fast-R-CNN中,損失函式由兩項組成:
L
(
p
,
u
,
t
u
,
v
)
=
L
c
l
s
(
p
,
u
)
+
λ
[
u
≥
1
]
L
l
o
c
(
t
u
,
v
)
L(p, u, t^u, v)=L_{cls}(p,u)+λ[u≥1]L_{loc}(t^u,v)
L(p,u,tu,v)=Lcls?(p,u)+λ[u≥1]Lloc?(tu,v)
其中第一項是預測類別與真實類別的交叉熵損失,多分類中其公式原型為為:
H
=
?
∑
i
o
i
?
l
o
g
(
o
i
)
H=-\sum_{i}^{}o_i^*log(o_i)
H=?i∑?oi??log(oi?)
但是由于真是標簽采用one-hot編碼,因此除了當下類別為1,其余類別標簽均為0.此時的交叉熵也就變成了論文中:
L
c
l
s
=
?
l
o
g
(
p
u
)
L_{cls}=-log(p_u)
Lcls?=?log(pu?)
pu表示softmax輸出當前類別的概率分數,
第二項為邊界框回歸損失函式,論文也說了t^u表示預測的一組邊界框位置引數,u表示真實的邊界框位置引數,其都包含一個含四個引數的元組–(x, y, h, w),
其中:
L
l
o
c
(
t
u
,
v
)
=
∑
i
∈
{
x
,
y
,
w
,
h
}
s
m
o
o
t
h
L
1
(
t
i
u
?
v
i
)
L_{loc}(t^u,v)=\sum_{i\in\{x,y,w,h\}}smooth_{{L_1}}(t_i^u-v_i)
Lloc?(tu,v)=i∈{x,y,w,h}∑?smoothL1??(tiu??vi?)
s
m
o
o
t
h
L
1
(
x
)
=
=
{
0.5
x
2
,
if |x| < 1
∣
x
∣
?
0.5
,
otherwise
smooth_{{L_1}}(x)== \begin{cases} 0.5x^2,& \text{if |x| < 1} \\ |x|-0.5, & \text{otherwise} \end{cases}
smoothL1??(x)=={0.5x2,∣x∣?0.5,?if |x| < 1otherwise?
λ是一個平衡系數,u是當下框內物體的標簽,當u≥1時取值1,否則取值0.這里的意思也就是當下的框內物體的確是屬于被檢測物體時,λ等于1.否則λ等于0,此時這項的計算值將被丟棄,論文中作者闡述:對于只有背景圖的ROI區域來說,λ等于0.此時這項計算值將被忽略,
最后再梳理一遍Fast-R-CNN的演算法流程:
首先將整張圖片作為輸入,通過卷積層和池化層獲得特征圖
使用ROI pooling層獲取ROIs
傳入網路主體架構中,然后其輸出將送去兩個平行分支,先經過全連接層,然后一個通過softmax層輸出分類,另外一個通過reg獲得候選框的精細修正,
使用的損失函式由兩部分組成
優化器使用分層采樣的小批量隨機梯度下降法 (stochastic gradient descent (SGD) mini batches)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/429283.html
標籤:AI