1 推薦演算法總體架構
1.1 推薦演算法意義
隨著互聯網近十年來的大力發展,用戶規模和內容規模均呈現迅猛發展,用戶側榷訓過億早已不是什么新鮮事,內容側由于UGC生產方式的普及,擁有幾十億內容庫的平臺也屢見不鮮,如何讓海量用戶在海量內容中找到自己喜歡的,以及如何讓海量內容被海量用戶精準消費,一直以來都是每個公司十分核心的問題,在這個背景下,搜索系統和推薦系統應運而生,搜索系統主要解決用戶尋找感興趣的內容,偏主動型消費,推薦系統則主要解決內容推送給合適用戶,偏被動型消費,二者一邊牽參考戶,一邊牽引內容,是實作用戶與內容匹配的中間媒介,推薦系統在每個公司都是十分核心的地位,其意義主要有
- 用戶側,為用戶及時精準的推送感興趣的個性化內容,并不斷發現和培養用戶的潛在興趣,滿足用戶消費需求,提升用戶體驗,從而提升用戶活躍度和留存,
- 內容側,作為流量分發平臺,對生產者(如UGC作者、電商賣家等)有正向反饋刺激能力,通過扶持有潛力的中小生產者,可以促進整體內容生態的繁榮發展
- 平臺側,推薦系統對內容分發的流量和效率都至關重要,通過提升用戶體驗,可提升用戶留存,從而提升榷訓,通過提升用戶轉化和流量效率,可提升電商平臺訂單量和內容平臺用戶人均時長等核心指標,通過提升用戶消費深度,可提升平臺整體流量,為商業化目標(如廣告)打下基礎,提升ARPU(每用戶平均收入)等核心指標,推薦系統與公司很多核心指標息息相關,有極大的牽引和推動作用,意義十分重要,
1.2 推薦演算法基本模塊
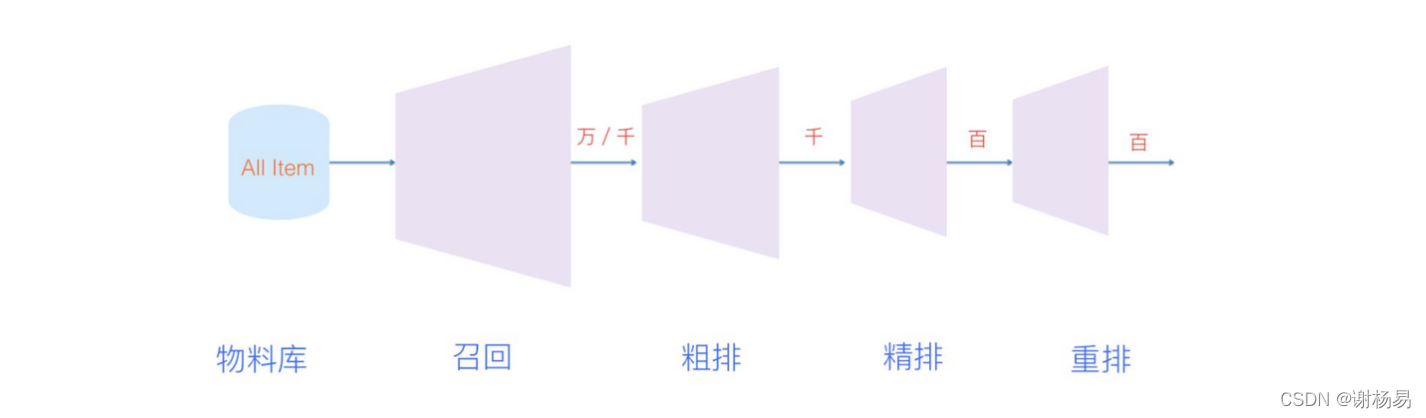
當前基于算力和存盤的考慮,還沒辦法實作整體端到端的推薦,一般來說推薦系統分為以下幾個主要模塊:
- 推薦池:一般會基于一些規則,從整體物料庫(可能會有幾十億甚至百億規模)中選擇一些item進入推薦池,再通過汰換規則定期進行更新,比如電商平臺可以基于近30天成交量、商品在所屬類目價格檔位等構建推薦池,短視頻平臺可以基于發布時間、近7天播放量等構建推薦池,推薦池一般定期離線構建好就可以了,
- 召回:從推薦池中選取幾千上萬的item,送給后續的排序模塊,由于召回面對的候選集十分大,且一般需要在線輸出,故召回模塊必須輕量快速低延遲,由于后續還有排序模塊作為保障,召回不需要十分準確,但不可遺漏(特別是搜索系統中的召回模塊),目前基本上采用多路召回解決范式,分為非個性化召回和個性化召回,個性化召回又有content-based、behavior-based、feature-based等多種方式,
- 粗排:獲取召回模塊結果,從中選擇上千item送給精排模塊,粗排可以理解為精排前的一輪過濾機制,減輕精排模塊的壓力,粗排介于召回和精排之間,要同時兼顧精準性和低延遲,一般模型也不能過于復雜
- 精排:獲取粗排模塊的結果,對候選集進行打分和排序,精排需要在最大時延允許的情況下,保證打分的精準性,是整個系統中至關重要的一個模塊,也是最復雜,研究最多的一個模塊,精排系統構建一般需要涉及樣本、特征、模型三部分,
- 重排:獲取精排的排序結果,基于運營策略、多樣性、context背景關系等,重新進行一個微調,比如三八節對美妝類目商品提權,類目打散、同圖打散、同賣家打散等保證用戶體驗措施,重排中規則比較多,但目前也有不少基于模型來提升重排效果的方案,
- 混排:多個業務線都想在Feeds流中獲取曝光,則需要對它們的結果進行混排,比如推薦流中插入廣告、視頻流中插入圖文和banner等,可以基于規則策略(如廣告定坑)和強化學習來實作,
推薦系統包含模塊很多,論文也是層出不窮,相對來說還是十分復雜的,我們掌握推薦系統演算法最重要的還是要梳理清楚整個演算法架構和大圖,知道每個模塊是怎么做的,有哪些局限性和待解決問題,可以通過什么手段優化等,并通過演算法架構大圖將各個模塊聯系起來,融會貫通,從而不至于深陷某個細節,不能自拔,看論文的時候也應該先了解它是為了解決什么問題,之前已經有哪些解決方案,再去了解它怎么解決的,以及相比其他方案有什么改進和優化點,本文主要講解推薦演算法架構大圖,幫助讀者掌握全域,起到提綱挈領作用,
2 召回
2.1 多路召回
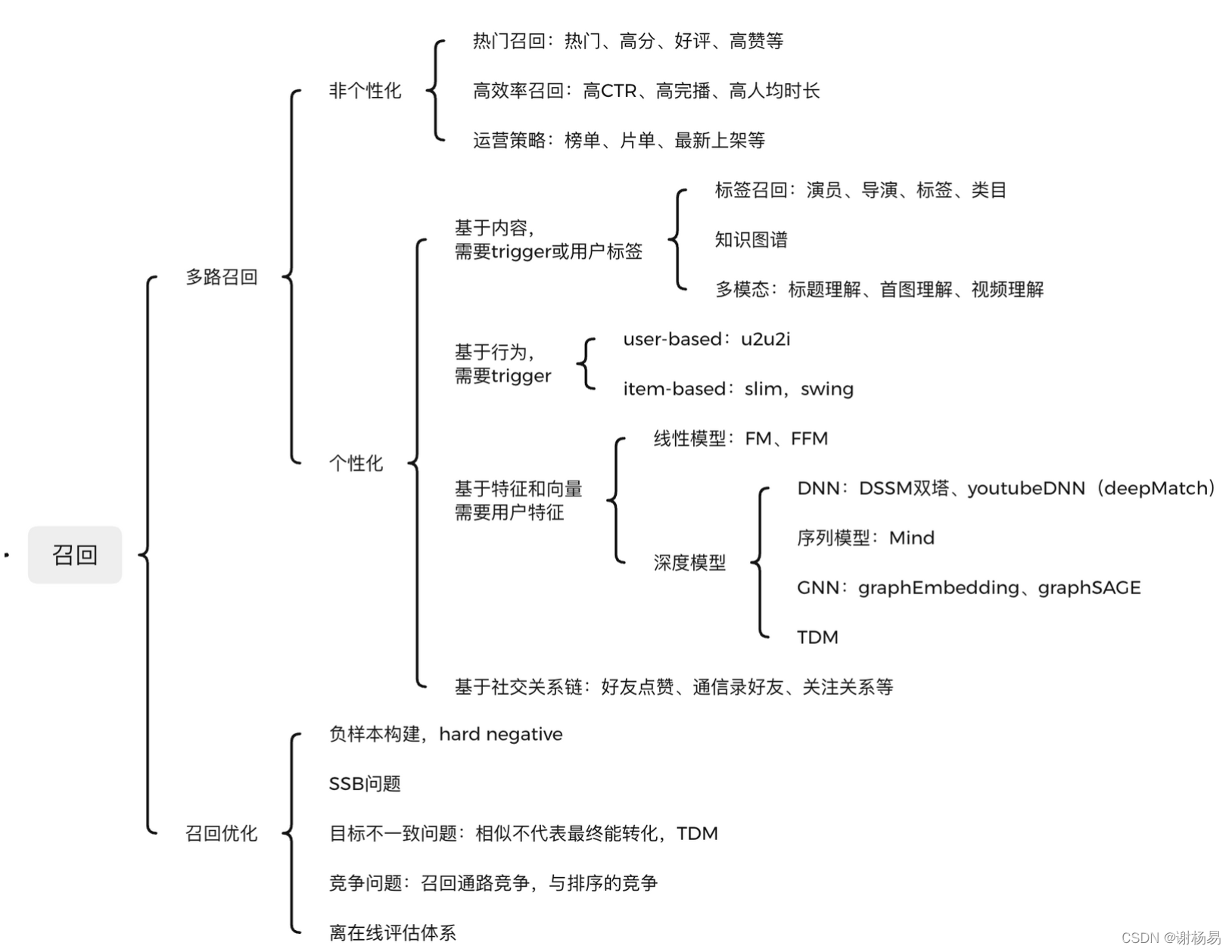
召回模塊面對幾百上千萬的推薦池物料規模,候選集十分龐大,由于后續有排序模塊作為保障,故不需要十分準確,但必須保證不要遺漏和低延遲,目前主要通過多路召回來實作,一方面各路可以并行計算,另一方面取長補短,召回通路主要有
- 非個性化召回:與用戶無關,非個性化,可以離線構建好,主要有
- 熱門召回:比如近7天播放vv比較高的短視頻,可以結合CTR和時間衰減做平滑,并過濾掉人均時長偏低的疑似騙點擊item,還可以選擇用戶點贊多、好評多的item等,這部分主要基于規則實作即可,由于熱門item容易導致馬太效應,如果熱門召回占整體通路比例過大,可以考慮做一定打壓,
- 高效率召回:比如高CTR、高完播率、高人均時長的短視頻,這類item效率較高,但可能上架不久,歷史播放vv不多,好評也需要時間積累,有可能不在熱門召回內,
- 運營策略召回:例如運營構建的各個類目的榜單、片單,最新上架item等,
- 個性化召回:與用戶相關,千人千面,根據構建方式主要有
-
content-based:基于內容,可以通過用戶標簽,比如新注冊時填寫的喜歡的導演、演員、類目等資訊,也可以通過用戶歷史行為作為trigger,來選取與之內容相似的item,主要有
- 標簽召回:比如演員、導演、item標簽tag、類目等,
- 知識圖譜
- 多模態:比如標題語意相似的item,首圖相似的item,視頻理解相似的item等
一般先離線構建好倒排索引,在線使用時通過用戶標簽或者歷史行為item作為trigger,取出對應候選即可,基于內容來構建倒排索引,不需要item有豐富的行為,對冷啟item比較友好,
-
behavior-based:基于行為,主要是userCF和itemCF兩種,都是通過行為來找相似,需要user或者item有比較豐富的行為,userCF先找到與user行為相似的user,選取他們行為序列中的item作為候選,itemCF則找到每個item被行為相似的其他item,構建倒排索引,構建方式主要有CF和MF兩大類,MF又稱model-based CF,就不具體展開了,
-
feature-based:基于特征,比如user的年齡、性別、機型、地理位置、行為序列等,item的上架時間、視頻時長、歷史統計資訊等,基于特征的召回構建方式,資訊利用比較充分,效果一般也比較好,對冷啟也比較友好,是最近幾年來的研究重點,又主要分為
- 線性模型:比如FM、FFM等,就不具體展開了
- 深度模型:比如基于DNN的DSSM雙塔、youtubeDNN(又叫deepMatch),基于用戶序列的Mind,基于GNN的graphSAGE等,
線上使用時,可以有兩種方式:
- 向量檢索:通過生成的user embedding,采用近鄰搜索,尋找與之相似的item embedding,從而找到具體item,檢索方式有哈希分桶、HNSW等多種方法
- i2i倒排索引:通過item embedding,找到與本item相似的其他item,離線構建i2i索引,線上使用時,通過用戶歷史行為中的item作為trigger,從倒排索引中找到候選集
-
social-network:通過好友點贊、關注關系、通信錄關系等,找到社交鏈上的其他人,然后通過他們來召回item,原則就是好友喜歡的item,大概率也會喜歡,物以類聚人以群分嘛,
-
2.2 召回優化
多路召回的各通路主要就是這些,那召回中主要有哪些問題呢,個人認為主要有
-
負樣本構建問題:召回是樣本的藝術,排序是特征的藝術,這句話說的很對,召回正樣本可以選擇曝光點擊的樣本,但負樣本怎么選呢?選擇曝光未點擊的樣本嗎,肯定不行
- 曝光未點擊樣本,能從已有召回、粗排、精排模塊中競爭出來,說明其item質量和相關性都還是不錯的,作為召回負樣本肯定不合適
- SSB問題,召回面向的全體推薦池,但能得到曝光的item只是其中很小的子集,這樣構建負樣本會導致十分嚴重的SSB(sample selection bias)問題,使得模型嚴重偏離實際
基于這個問題,我們可以在推薦池中隨機選擇item作為負樣本,但又會有一個問題,隨機選擇的item,相對于正樣本來說,一般很容易區分,所以需要有hard negative sample來刺激和提升召回模型效果,構建hard negative sample,是目前召回研究中比較多的一個方向,主要有:
- 借助精排模型:比如選取精排打分處于中間位置的item,如排名100~500左右的item,它們不是很靠前,可以看做負樣本,也不是吊車尾,與正樣本有一定相關性,區分起來有一定難度,
- 業務規則:比如選擇同類目、同價格檔位等規則的item,可以參考Airbnb論文的做法,
- 主動學習:召回結果進行人工審核,bad case作為負樣本
一般會將hard negative與easy negative,按照一定比例,比如1: 100,同時作為召回負樣本,
-
SSB問題:召回面向的是全體推薦池,item數量巨大,故需要做一定的負采樣,有比較大的SSB樣本選擇偏差問題,故需要讓選擇出來的負樣本,盡可能的能代表全體推薦池,從而提升模型泛化能力,主要問題仍然是負采樣,特別是hard negative sample的問題,
-
目標不一致問題:目前的召回目標仍然是找相似,不論是基于內容的,還是基于行為和特征的,但精排和最終實際業務指標仍然看的是轉化,相似不代表就能得到很好的轉化,比如極端情況,全部召回與用戶最近播放相似的短視頻,顯然最終整體的轉化是不高的,
-
競爭問題:各召回通路最侄訓做merge去重,各通道之間重復度過高則沒有意義,特別是新增召回通路,需要對歷史通路有較好的補充增益作用,各召回通路之間存在一定的重疊和競爭問題,同時,召回通路的候選item,不一定能在精排中競爭透出,特別是歷史召回少的item,由于其曝光樣本很少,精排中打分不高,所以不一定能透出,召回和精排的相愛相殺,還需要通過全鏈路優化來緩解,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/429286.html
標籤:AI
上一篇:用Python實作BP神經網路識別MNIST手寫數字資料集(帶GUI)
下一篇:[半監督學習] Deep Co-Training for Semi-Supervised Image Recognition