引言
本著“凡我不能創造的,我就不能理解”的思想,本系列文章會基于純Python以及NumPy從零創建自己的深度學習框架,該框架類似PyTorch能實作自動求導,
要深入理解深度學習,從零開始創建的經驗非常重要,從自己可以理解的角度出發,盡量不使用外部完備的框架前提下,實作我們想要的模型,本系列文章的宗旨就是通過這樣的程序,讓大家切實掌握深度學習底層實作,而不是僅做一個調包俠,
本系列文章首發于微信公眾號:JavaNLP
我們已經了解了前饋神經網路的基礎知識,本文就基于前饋網路來解決實際問題——IMDB電影評論分類,
imdb資料集
imdb資料集是英文電影評論資料集,包含50000條兩極分化的評論,資料集被分為25000條用于訓練和25000條用于測驗的評論,它們都包含50%的正面和50%的負面評論,
我們想要訓練一個前饋網路能學到輸入一段英文評論,判斷這段評論是正面(表揚、鼓勵)還是負面(狂噴)的,屬于一個二分類問題,
我們先來看下資料集,為了簡單,我們先用keras提供的封裝方法加載資料集,需要引入from keras.datasets import imdb,
def load_dataset():
# 保留訓練資料中前10000個最常出現的單詞,舍棄低頻單詞
(X_train, y_train), (X_test, y_test) = imdb.load_data(num_words=10000)
return Tensor(X_train), Tensor(X_test), Tensor(y_train), Tensor(y_test)
def indices_to_sentence(indices: Tensor):
# 單詞索引字典 word -> index
word_index = imdb.get_word_index()
# 逆單詞索引字典 index -> word
reverse_word_index = dict(
[(value, key) for (key, value) in word_index.items()])
# 將index串列轉換為word串列
#
# 0、1、2 是為“padding”(填充)、“start of sequence”(序
# 列開始)、“unknown”(未知詞)分別保留的索引
decoded_review = ' '.join(
[reverse_word_index.get(i - 3, '?') for i in indices.data])
return decoded_review
if __name__ == '__main__':
X_train, X_test, y_train, y_test = load_dataset()
print(indices_to_sentence(X_train[0]))
print(y_train[0])
這里加載了第一個樣本,將索引還原成句子,最后列印出該句子對應的標簽,
? this film was just brilliant casting location scenery story direction everyone's really suited the part they played and you could just imagine being there robert ? is an amazing actor and now the same being director ? father came from the same scottish island as myself so i loved the fact there was a real connection with this film the witty remarks throughout the film were great it was just brilliant so much that i bought the film as soon as it was released for ? and would recommend it to everyone to watch and the fly fishing was amazing really cried at the end it was so sad and you know what they say if you cry at a film it must have been good and this definitely was also ? to the two little boy's that played the ? of norman and paul they were just brilliant children are often left out of the ? list i think because the stars that play them all grown up are such a big profile for the whole film but these children are amazing and should be praised for what they have done don't you think the whole story was so lovely because it was true and was someone's life after all that was shared with us all
Tensor(1.0, requires_grad=False) # 對應的類別
很長的一段評論,該評論被標記為正面(1),
句子的處理
這是我們第一次接觸NLP相關任務,雖然我們人類能很容易地看懂文字,但是讓機器讀懂文字不是一件容易的事,
這里用了最簡單的方法,首先將句子拆分成一個個單詞,然后構造一個詞典來保存每個單詞和其對應的序號(imdb.get_word_index()),這里keras已經幫我們處理好了,
然后保存每個句子的時候,我們只需要保留句子中所有單詞對應的序號串列即可,得到序號串列相當于將句子進行了數字化,只有數字化之后,計算機才能處理,
每個樣本都是單詞序列串列,因此我們需要將它們還原成句子,人類才能看得懂,
但是我們不能將整數序列直接輸入神經網路,我們需要將串列轉換為向量,我們這里對序列串列使用ont-hot編碼,比如序列[3,5]會被轉換為10000維的向量,只有索引3和5的元素是1,相當于標記了哪些單詞出現在序列中,這是一個簡單的句子向量化方法,
這里我們把每個句子轉換成一個10000維的向量,這里的10000是我們設的最常見的單詞數,包括填充詞、序列開始詞和未知詞,每個句子都會有一個序列開始詞,表示這是一個句子的開始單詞;未知詞是來處理不常見單詞的,比如你不在這10000個常見單詞里面的詞;填充詞用于填充句子;
def vectorize_sequences(sequences, dimension=10000):
# 默認生成一個[句子長度,維度數]的向量
results = np.zeros((len(sequences), dimension), dtype='uint8')
for i, sequence in enumerate(sequences):
# 將第i個序列中,對應單詞序號處的位置置為1
results[i, sequence] = 1
return results
X_train = vectorize_sequences(X_train)
print(X_train[0])
[0 1 1 ... 0 0 0]
處理好句子之后,我們就可以將資料輸入到神經網路中,
構建前饋神經網路
輸入資料是向量,而標簽是標量(1或0),這和我們之前使用邏輯回歸構建的模型一樣,不過這次我們采用神經網路的方式,
我們使用前面介紹的單隱藏層前饋網路來處理這個問題,看一下效果如何,
首先設計我們的單隱藏層網路:
class Feedforward(nn.Module):
'''
簡單單隱藏層前饋網路,用于分類問題
'''
def __init__(self, input_size, hidden_size, output_size):
'''
:param input_size: 輸入維度
:param hidden_size: 隱藏層大小
:param output_size: 分類個數
'''
self.net = nn.Sequential(
nn.Linear(input_size, hidden_size), # 隱藏層,將輸入轉換為隱藏向量
nn.ReLU(), # 激活函式
nn.Linear(hidden_size, output_size) # 輸出層,將隱藏向量轉換為輸出
)
def forward(self, x: Tensor) -> Tensor:
return self.net(x)
實作這種順序網路很簡單,就像堆疊石頭一樣,一層一層往上堆疊即可,

由于我們將使用之前介紹的BCELoss,因此最終的輸出只是logits即可,不需要是經過Sigmoid的概率,
訓練模型
由于我們的資料量足夠大,我們可以從訓練集中保留一部分資料作為驗證集,以監控訓練的效果,
# 保留驗證集
# X_train有25000條資料,我們保留10000條作為驗證集
X_val = X_train[:10000]
X_train = X_train[10000:]
y_val = y_train[:10000]
y_train = y_train[10000:]
下面我們構造模型,并準備優化器和損失器,由于我們加了批處理,這里計算總損失,而不是均值,
model = Feedforward(10000, 128, 1) # 輸入大小10000,隱藏層大小128,輸出只有一個,代表判斷為正例的概率
optimizer = SGD(model.parameters(), lr=0.001)
# 先計算sum
loss = BCELoss(reduction="sum")
同時由于資料量較大,我們需要進行批處理,將訓練集和驗證集分成每批大小為512的批資料,訓練20輪,
epochs = 20
batch_size = 512 # 批大小
train_losses, val_losses = [], []
train_accuracies, val_accuracies = [], []
# 由于資料過多,需要拆分成批次
X_train_batches, y_train_batches = make_batches(X_train, y_train,batch_size=batch_size)
X_val_batches, y_val_batches = make_batches(X_val, y_val, batch_size=batch_size)
for epoch in range(epochs):
train_loss, train_accuracy = compute_loss_and_accury(X_train_batches, y_train_batches, model, loss, len(X_train), optimizer)
train_losses.append(train_loss)
train_accuracies.append(train_accuracy)
with no_grad():
val_loss, val_accuracy = compute_loss_and_accury(X_val_batches, y_val_batches, model, loss, len(X_val))
val_losses.append(val_loss)
val_accuracies.append(val_accuracy)
print(f"Epoch:{epoch}, Train Loss: {train_loss:.4f}, Accuracy: {train_accuracy:.2f}% | "
f" Validation Loss:{val_loss:.4f} , Accuracy:{val_accuracy:.2f}%")
訓練程序中的列印如下:
Epoch:1, Training Loss: 0.6335, Accuracy: 60.20% | Validation Loss:0.6429 , Accuracy:49.55%
Epoch:2, Training Loss: 0.6333, Accuracy: 66.75% | Validation Loss:0.5527 , Accuracy:76.28%
Epoch:3, Training Loss: 0.5587, Accuracy: 75.22% | Validation Loss:0.4782 , Accuracy:82.10%
Epoch:4, Training Loss: 0.4891, Accuracy: 77.11% | Validation Loss:0.3758 , Accuracy:84.26%
Epoch:5, Training Loss: 0.5085, Accuracy: 75.09% | Validation Loss:0.3763 , Accuracy:83.28%
Epoch:6, Training Loss: 0.3887, Accuracy: 82.52% | Validation Loss:0.3544 , Accuracy:84.76%
Epoch:7, Training Loss: 0.3628, Accuracy: 83.79% | Validation Loss:0.3584 , Accuracy:85.17%
Epoch:8, Training Loss: 0.3451, Accuracy: 84.71% | Validation Loss:0.3532 , Accuracy:83.87%
Epoch:9, Training Loss: 0.3201, Accuracy: 85.83% | Validation Loss:0.3433 , Accuracy:84.42%
Epoch:10, Training Loss: 0.3311, Accuracy: 84.93% | Validation Loss:0.3058 , Accuracy:87.20%
Epoch:11, Training Loss: 0.2989, Accuracy: 87.04% | Validation Loss:0.3484 , Accuracy:83.60%
Epoch:12, Training Loss: 0.2685, Accuracy: 88.61% | Validation Loss:0.2958 , Accuracy:87.65%
Epoch:13, Training Loss: 0.2640, Accuracy: 88.35% | Validation Loss:0.2957 , Accuracy:87.72%
Epoch:14, Training Loss: 0.2887, Accuracy: 87.17% | Validation Loss:0.3808 , Accuracy:82.40%
Epoch:15, Training Loss: 0.3235, Accuracy: 85.68% | Validation Loss:0.2926 , Accuracy:87.75%
Epoch:16, Training Loss: 0.2650, Accuracy: 88.68% | Validation Loss:0.3038 , Accuracy:86.86%
Epoch:17, Training Loss: 0.2448, Accuracy: 89.58% | Validation Loss:0.2906 , Accuracy:87.94%
Epoch:18, Training Loss: 0.2273, Accuracy: 90.34% | Validation Loss:0.2915 , Accuracy:88.05%
Epoch:19, Training Loss: 0.1913, Accuracy: 91.97% | Validation Loss:0.2889 , Accuracy:88.33%
Epoch:20, Training Loss: 0.2069, Accuracy: 91.22% | Validation Loss:0.2894 , Accuracy:88.07%
光看列印不夠直觀,我們可以繪制訓練損失和驗證損失:
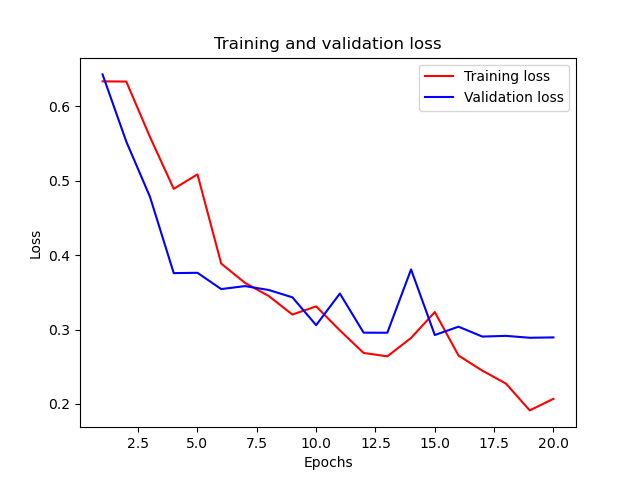
還可以繪制訓練和驗證準確率的變化曲線:
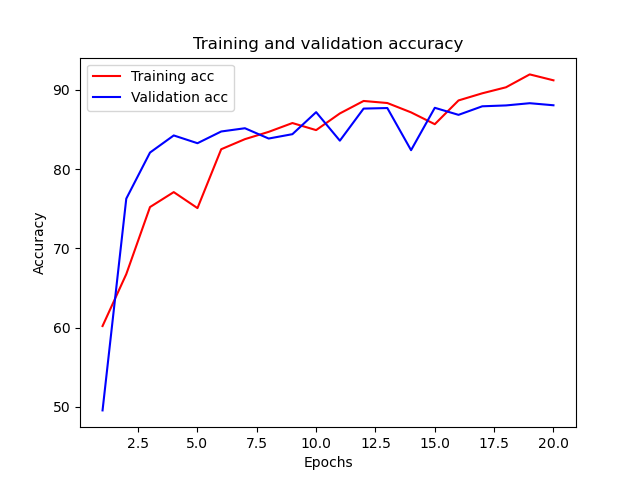
看起來模型還不錯,但是真正怎么樣還需要測驗之后才知道,我們現在來預測沒有看過的25000條記錄:
# 最后在測驗集上測驗
with no_grad():
X_test, y_test = Tensor(X_test), Tensor(y_test)
outputs = model(X_test)
correct = np.sum(sigmoid(outputs).numpy().round() == y_test.numpy())
accuracy = 100 * correct / len(y_test)
print(f"Test Accuracy:{accuracy}")
Test Accuracy:88.004
嗯,我們直接純手寫實作的前饋網路模型和Keras的前饋模型表現差不多1,還可以!
完整代碼
完整代碼筆者上傳到了程式員最大交友網站上去了,地址: 👉 https://github.com/nlp-greyfoss/metagrad
References
Python深度學習 ??
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/429770.html
標籤:AI