本文已加入 🚀 Python AI 計劃,從一個Python小白到一個AI大神,你所需要的所有知識都在 這里 了,
在之前的文章中我們通過Xception演算法模型實作了狗、貓、雞、馬四種的動物的識別(新模型!實作動物識別),今天我們接著介紹MobileNetV2演算法,將資料集擴充到90個類別,即使用 90 個不同類別的動物圖片,每個類別分別含有60張圖片,一共 5400 張圖片進行識別,最后達到的準確率是86.2% ,代碼與資料我放在文末了,需要的自取,
我的環境:
- 語言環境:Python3.8
- 編譯器:Jupyter lab
- 深度學習環境:TensorFlow2.4.1
- 選自專欄:《深度學習100例》
我們的代碼流程圖如下所示:
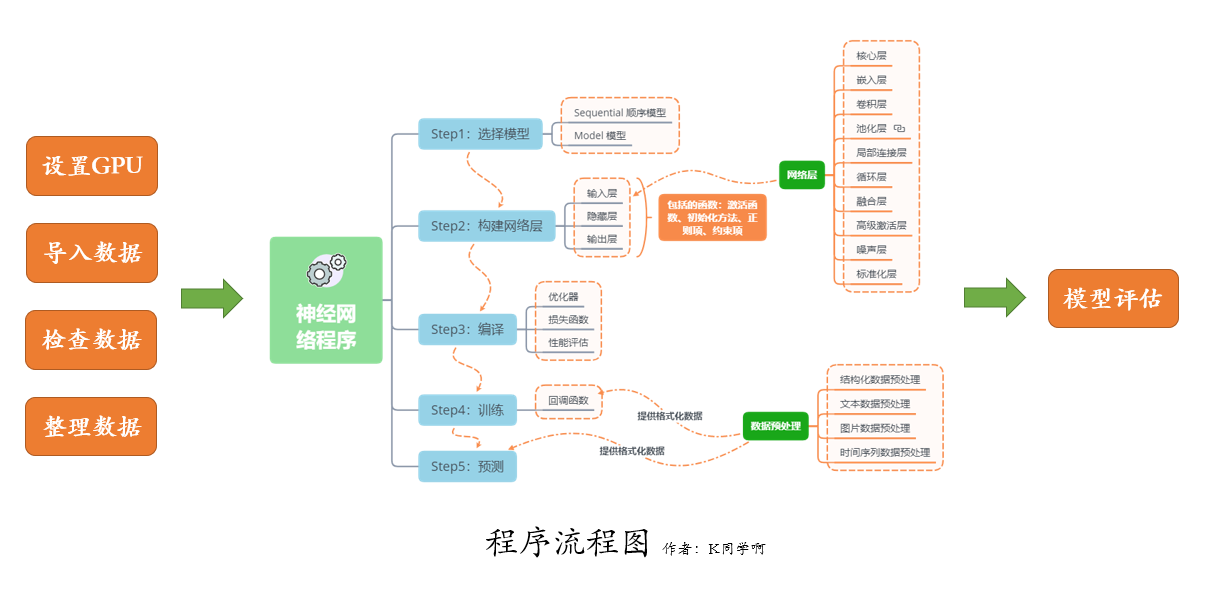
文章目錄
- 一、設定GPU
- 二、匯入資料
- 1. 查看資料
- 2. 加載資料
- 3. 配置資料集
- 4. 資料可視化
- 三、構建MobileNetV2遷移模型
- 四、編譯
- 五、訓練模型
- 六、評估模型
- 1. Accuracy與Loss圖
- 2. 混淆矩陣
- 3. 各項指標評估
一、設定GPU
import tensorflow as tf
gpus = tf.config.list_physical_devices("GPU")
if gpus:
gpu0 = gpus[0] #如果有多個GPU,僅使用第0個GPU
tf.config.experimental.set_memory_growth(gpu0, True) #設定GPU顯存用量按需使用
tf.config.set_visible_devices([gpu0],"GPU")
import matplotlib.pyplot as plt
import os,PIL,pathlib
import numpy as np
import pandas as pd
import warnings
from tensorflow import keras
warnings.filterwarnings("ignore")#忽略警告資訊
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用來正常顯示中文標簽
plt.rcParams['axes.unicode_minus'] = False # 用來正常顯示負號
二、匯入資料
1. 查看資料
import pathlib
data_dir = "./30-data/"
data_dir = pathlib.Path(data_dir)
image_count = len(list(data_dir.glob('*/*')))
print("圖片總數為:",image_count)
圖片總數為: 5400
# 統計每一個類別的數目
class_name = []
class_sum = []
for i in data_dir.glob('*'):
class_name.append(str(i).split("\\")[1])
class_sum.append(len(list(i.glob('*'))))
class_dict = {'class_name':class_name,'class_sum':class_sum}
class_df = pd.DataFrame(class_dict,columns=['class_name', 'class_sum'])
# 按照圖片數量進行降序排序
class_df = class_df.sort_values(by="class_sum" , ascending=False)
class_df.head()
| class_name | class_sum | |
|---|---|---|
| 0 | antelope | 60 |
| 67 | raccoon | 60 |
| 65 | porcupine | 60 |
| 64 | pigeon | 60 |
| 63 | pig | 60 |
在實驗開始時查看資料集分布情況,部分類別圖片數量過少時,需要及時補充資料,
2. 加載資料
batch_size = 16
img_height = 224
img_width = 224
"""
關于image_dataset_from_directory()的詳細介紹可以參考文章:https://mtyjkh.blog.csdn.net/article/details/117018789
通過該方法匯入資料時,會同時打亂資料
"""
train_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="training",
seed=12,
image_size=(img_height, img_width),
batch_size=batch_size)
Found 5400 files belonging to 90 classes.
Using 4320 files for training.
"""
關于image_dataset_from_directory()的詳細介紹可以參考文章:https://mtyjkh.blog.csdn.net/article/details/117018789
通過該方法匯入資料時,會同時打亂資料
"""
val_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="validation",
seed=12,
image_size=(img_height, img_width),
batch_size=batch_size)
Found 5400 files belonging to 90 classes.
Using 1080 files for validation.
class_names = train_ds.class_names
print("資料類別有:",class_names)
print("需要識別的動物一共有%d類"%len(class_names))
資料類別有: ['antelope', 'badger', 'bat', 'bear', 'bee', 'beetle', 'bison', 'boar', 'butterfly', 'cat', 'caterpillar', 'chimpanzee', 'cockroach', 'cow', 'coyote', 'crab', 'crow', 'deer', 'dog', 'dolphin', 'donkey', 'dragonfly', 'duck', 'eagle', 'elephant', 'flamingo', 'fly', 'fox', 'goat', 'goldfish', 'goose', 'gorilla', 'grasshopper', 'hamster', 'hare', 'hedgehog', 'hippopotamus', 'hornbill', 'horse', 'hummingbird', 'hyena', 'jellyfish', 'kangaroo', 'koala', 'ladybugs', 'leopard', 'lion', 'lizard', 'lobster', 'mosquito', 'moth', 'mouse', 'octopus', 'okapi', 'orangutan', 'otter', 'owl', 'ox', 'oyster', 'panda', 'parrot', 'pelecaniformes', 'penguin', 'pig', 'pigeon', 'porcupine', 'possum', 'raccoon', 'rat', 'reindeer', 'rhinoceros', 'sandpiper', 'seahorse', 'seal', 'shark', 'sheep', 'snake', 'sparrow', 'squid', 'squirrel', 'starfish', 'swan', 'tiger', 'turkey', 'turtle', 'whale', 'wolf', 'wombat', 'woodpecker', 'zebra']
需要識別的動物一共有90類
for image_batch, labels_batch in train_ds:
print(image_batch.shape)
print(labels_batch.shape)
break
(16, 224, 224, 3)
(16,)
3. 配置資料集
- shuffle() : 打亂資料,
- prefetch() : 預取資料,加速運行,其詳細介紹可以參考我前兩篇文章,里面都有講解,
- cache() : 將資料集快取到記憶體當中,加速運行
AUTOTUNE = tf.data.AUTOTUNE
def train_preprocessing(image,label):
return (image/255.0,label)
train_ds = (
train_ds.cache()
# .shuffle(2000)
.map(train_preprocessing) # 這里可以設定預處理函式
# .batch(batch_size) # 在image_dataset_from_directory處已經設定了batch_size
.prefetch(buffer_size=AUTOTUNE)
)
val_ds = (
val_ds.cache()
# .shuffle(2000)
.map(train_preprocessing) # 這里可以設定預處理函式
# .batch(batch_size) # 在image_dataset_from_directory處已經設定了batch_size
.prefetch(buffer_size=AUTOTUNE)
)
4. 資料可視化
plt.figure(figsize=(10, 8)) # 圖形的寬為10高為5
plt.suptitle("資料展示")
for images, labels in train_ds.take(1):
for i in range(15):
plt.subplot(4, 5, i + 1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
# 顯示圖片
plt.imshow(images[i])
# 顯示標簽
plt.xlabel(class_names[labels[i]-1])
plt.show()

三、構建MobileNetV2遷移模型
from tensorflow.keras import layers, models, Input
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Dense, Flatten, Dropout,BatchNormalization,Activation
# 加載預訓練模型
base_model = tf.keras.applications.mobilenet_v2.MobileNetV2(weights='imagenet',
include_top=False,
input_shape=(img_width,img_height,3),
pooling='max')
for layer in base_model.layers:
layer.trainable = True
X = base_model.output
"""
注意到原模型(MobileNetV2)會發生過擬合現象,這里加上一個Dropout層
加上后,過擬合現象得到了明顯的改善,
大家可以試著通過調整代碼,觀察一下注釋Dropout層與不注釋之間的差別
"""
X = Dropout(0.6)(X)
output = Dense(len(class_names), activation='softmax')(X)
model = Model(inputs=base_model.input, outputs=output)
# model.summary()
四、編譯
optimizer = tf.keras.optimizers.Adam(lr=1e-4)
model.compile(optimizer=optimizer,
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
五、訓練模型
from tensorflow.keras.callbacks import ModelCheckpoint, Callback, EarlyStopping, ReduceLROnPlateau, LearningRateScheduler
NO_EPOCHS = 20
PATIENCE = 5
VERBOSE = 1
# 設定動態學習率
annealer = LearningRateScheduler(lambda x: 1e-4 * 0.98 ** x)
# 設定早停
earlystopper = EarlyStopping(monitor='loss', patience=PATIENCE, verbose=VERBOSE)
#
checkpointer = ModelCheckpoint('best_model.h5',
monitor='val_accuracy',
verbose=VERBOSE,
save_best_only=True,
save_weights_only=True)
train_model = model.fit(train_ds,
epochs=NO_EPOCHS,
verbose=1,
validation_data=val_ds,
callbacks=[annealer, earlystopper, checkpointer])
Epoch 1/20
270/270 [==============================] - 24s 65ms/step - loss: 9.6472 - accuracy: 0.0667 - val_loss: 6.1488 - val_accuracy: 0.1407racy - ETA: 13s - loss: 16.8260 - ac - ETA: 5s - loss: 11.5347
Epoch 00001: val_accuracy improved from -inf to 0.14074, saving model to best_model.h5
Epoch 2/20
270/270 [==============================] - 16s 58ms/step - loss: 3.1554 - accuracy: 0.3285 - val_loss: 2.4029 - val_accuracy: 0.4852
..........
Epoch 00019: val_accuracy did not improve from 0.84167
Epoch 20/20
270/270 [==============================] - 16s 57ms/step - loss: 0.0514 - accuracy: 0.9843 - val_loss: 0.7325 - val_accuracy: 0.8250
Epoch 00020: val_accuracy did not improve from 0.84167
六、評估模型
1. Accuracy與Loss圖
acc = train_model.history['accuracy']
val_acc = train_model.history['val_accuracy']
loss = train_model.history['loss']
val_loss = train_model.history['val_loss']
epochs_range = range(len(acc))
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
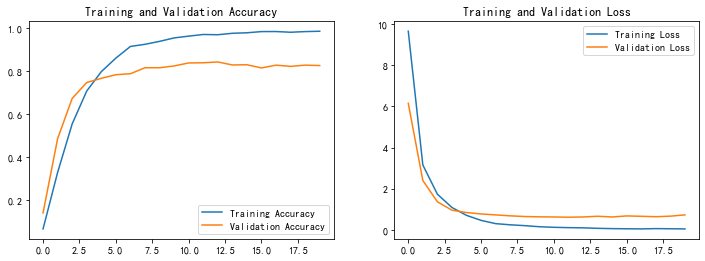
加入Dropout層后過擬合現象得到了緩解,沒有那么明顯了,
2. 混淆矩陣
from sklearn.metrics import confusion_matrix
import seaborn as sns
import pandas as pd
# 定義一個繪制混淆矩陣圖的函式
def plot_cm(labels, predictions):
# 生成混淆矩陣
conf_numpy = confusion_matrix(labels, predictions)
# 將矩陣轉化為 DataFrame
conf_df = pd.DataFrame(conf_numpy, index=class_names ,columns=class_names)
plt.figure(figsize=(8,7))
sns.heatmap(conf_df, annot=True, fmt="d", cmap="BuPu")
plt.title('混淆矩陣',fontsize=15)
plt.ylabel('真實值',fontsize=14)
plt.xlabel('預測值',fontsize=14)
val_pre = []
val_label = []
for images, labels in val_ds:#這里可以取部分驗證資料(.take(1))生成混淆矩陣
for image, label in zip(images, labels):
# 需要給圖片增加一個維度
img_array = tf.expand_dims(image, 0)
# 使用模型預測圖片中的人物
prediction = model.predict(img_array)
val_pre.append(class_names[np.argmax(prediction)])
val_label.append(class_names[label])
plot_cm(val_label, val_pre)
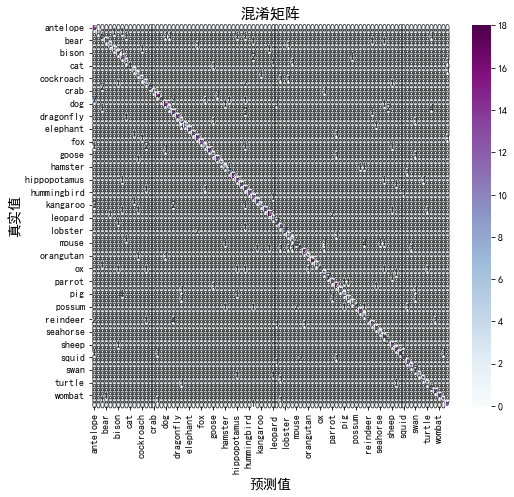
90個類別做成混淆矩陣,基本就看不出東西了,這里放上混淆矩陣的代碼主要是方便大家切換成其他資料集時使用,
3. 各項指標評估
from sklearn import metrics
def test_accuracy_report(model):
print(metrics.classification_report(val_label, val_pre, target_names=class_names))
score = model.evaluate(val_ds, verbose=0)
print('Loss function: %s, accuracy:' % score[0], score[1])
test_accuracy_report(model)
precision recall f1-score support
antelope 0.52 1.00 0.68 15
badger 1.00 0.83 0.91 12
bat 0.55 0.50 0.52 12
...此處省略若干...
zebra 0.80 0.92 0.86 13
accuracy 0.82 1080
macro avg 0.85 0.83 0.83 1080
weighted avg 0.85 0.82 0.82 1080
Loss function: 0.7324997782707214, accuracy: 0.824999988079071
📍 本文的資料與代碼:傳送門
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/430258.html
標籤:AI
上一篇:【數字信號處理】線性時不變系統 LTI ( 判斷某個系統是否是 “ 非時變 “ 系統 | 案例一 | 先變換后移位 | 先移位后變換 )