目錄
第5章 深度學習用于計算機視覺
5.1 卷積神經網路簡介
5.1.1 卷積運算
5.1.2 最大池化運算
5.2 在小型資料集上從頭開始訓練一個卷積神經網路
5.2.1 深度學習與小資料問題的相關性
5.2.2 下載資料
5.2.3 構建網路
5.2.4 資料預處理
5.2.5 使用資料增強
5.3 使用預訓練的卷積神經網路
5.3.1 特征提取
5.3.2 微調模型
5.3.3 小結
5.4 卷積神經網路的可視化
5.4.1 可視化中間激活
第5章 深度學習用于計算機視覺
本章將介紹卷積神經網路,也叫convnet,它是計算機視覺應用幾乎都在使用的一種深度學習模型,
5.1 卷積神經網路簡介
實體化一個小型的卷積神經網路:
from keras import layers
from keras import models
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activaition='relu'))重要的是,卷積神經網路接收形狀為(image_height, image_width, image_channels)的輸入張量(不包括批量維度),我們來看一下目前卷積神經網路的架構:
print(model.summary())Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 26, 26, 32) 320
max_pooling2d (MaxPooling2D (None, 13, 13, 32) 0
)
conv2d_1 (Conv2D) (None, 11, 11, 64) 18496
max_pooling2d_1 (MaxPooling (None, 5, 5, 64) 0
2D)
conv2d_2 (Conv2D) (None, 3, 3, 64) 36928
=================================================================
Total params: 55,744
Trainable params: 55,744
Non-trainable params: 0
_________________________________________________________________
None在卷積神經網路上添加分類器:
model.add(layers.Flatten())
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(10, activation='softmax'))
print(model.summary())
現在的網路架構如下:
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 26, 26, 32) 320
max_pooling2d (MaxPooling2D (None, 13, 13, 32) 0
)
conv2d_1 (Conv2D) (None, 11, 11, 64) 18496
max_pooling2d_1 (MaxPooling (None, 5, 5, 64) 0
2D)
conv2d_2 (Conv2D) (None, 3, 3, 64) 36928
flatten (Flatten) (None, 576) 0
dense (Dense) (None, 64) 36928
dense_1 (Dense) (None, 10) 650
=================================================================
Total params: 93,322
Trainable params: 93,322
Non-trainable params: 0
_________________________________________________________________
None
在MNIST影像上訓練卷積神經網路:
from keras.datasets import mnist
from keras.utils.np_utils import to_categorical
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
train_images = train_images.reshape((60000, 28, 28, 1))
train_images = train_images.astype('float32') / 255
test_images = test_images.reshape((10000, 28, 28, 1))
test_images = test_images.astype('float32') / 255
train_labels = to_categorical(train_labels)
test_labels = to_categorical(test_labels)
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
model.fit(train_images, train_labels, epochs=5, batch_size=64)完整代碼:
from keras.datasets import mnist
from keras.utils.np_utils import to_categorical
from keras import layers
from keras import models
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.Flatten())
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(10, activation='softmax'))
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
train_images = train_images.reshape((60000, 28, 28, 1))
train_images = train_images.astype('float32') / 255
test_images = test_images.reshape((10000, 28, 28, 1))
test_images = test_images.astype('float32') / 255
train_labels = to_categorical(train_labels)
test_labels = to_categorical(test_labels)
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
model.fit(train_images, train_labels, epochs=5, batch_size=64)
test_loss, test_acc = model.evaluate(test_images, test_labels)
print(test_acc)Epoch 1/5
938/938 [==============================] - 33s 24ms/step - loss: 0.1748 - accuracy: 0.9453
Epoch 2/5
938/938 [==============================] - 26s 28ms/step - loss: 0.0481 - accuracy: 0.9848
Epoch 3/5
938/938 [==============================] - 21s 22ms/step - loss: 0.0331 - accuracy: 0.9895
Epoch 4/5
938/938 [==============================] - 21s 22ms/step - loss: 0.0250 - accuracy: 0.9926
Epoch 5/5
938/938 [==============================] - 20s 22ms/step - loss: 0.0191 - accuracy: 0.9940
313/313 [==============================] - 4s 9ms/step - loss: 0.0348 - accuracy: 0.9898
0.9897999763488775.1.1 卷積運算
密集連接層和圈進層的根本區別在于,Dense層從輸入特征空間學到的是全域模式(比如對于MNIST數字,全域模式就是涉及所有像素的模式),而卷積層學到的是區域模式,對于影像來說,學到的就是在輸入影像的二維小視窗中發現的模式,
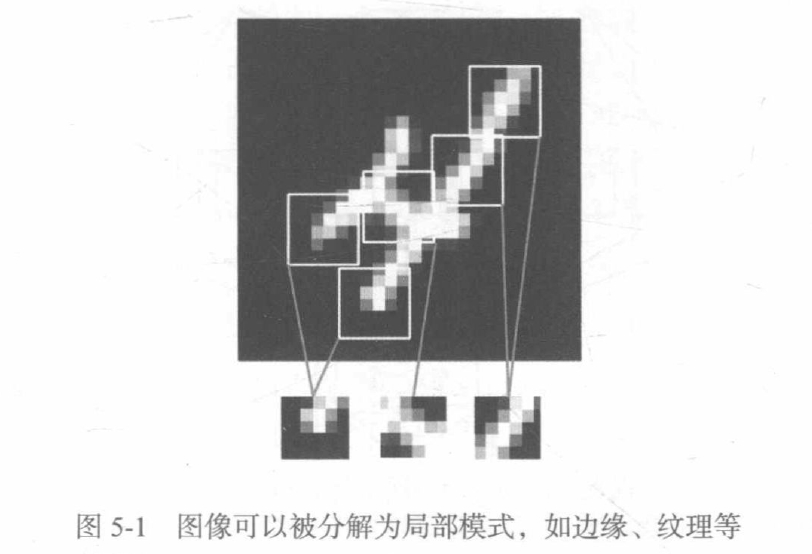
這個重要特性使卷積神經網路具有以下兩個有趣的性質:
1.卷積神經網路學到的模式具有平移不變性,卷積神經網路在影像右下角學到某個模式之后,它可以在任何地方識別這個模式,比如左上角,對于密集連接網路來說,如果模式出現在新的位置,它只能重新學習這個模式,這使得卷積神經網路在處理影像時可以高效利用資料(因為視覺世界從根本上具有平移不變性),它只需要更少的訓練樣本就可以學到具有泛化能力的資料表示,
2.卷積神經網路可以學到模式的空間層次結構,第一個卷積層將學習較小的區域模式(比如邊緣),第二個卷積層將學習由第一層特征組成的更大的模式,以此類推,這使得卷積神經網路可以有效地學習越來越復雜、越來越抽象的視覺概念(因為視覺世界從根本上具有空間層次結構),
對于包含兩個空間軸(高度和寬度)和一個深度軸(也叫通道軸)的3D張量,其卷積也叫特征圖,對于RGB影像,深度軸的維度大小等于3, 因為影像有3個顏色通道:紅色、綠色和藍色,對于黑白影像(比如MNIST數字影像),深度等于1(表示灰度等級),卷積運算從輸入特征圖中提取圖塊,并對所有這些圖塊應用相同的變換,生成輸出特征圖,該輸出特征圖仍是一個3D張量,具有寬度和高度,其深度可以任意取值,因為輸出深度是層的引數,深度軸的不同通道不再像RGB那樣代表特定顏色,而是代表過濾器,過濾器對輸入資料的某一方面進行編碼 ,
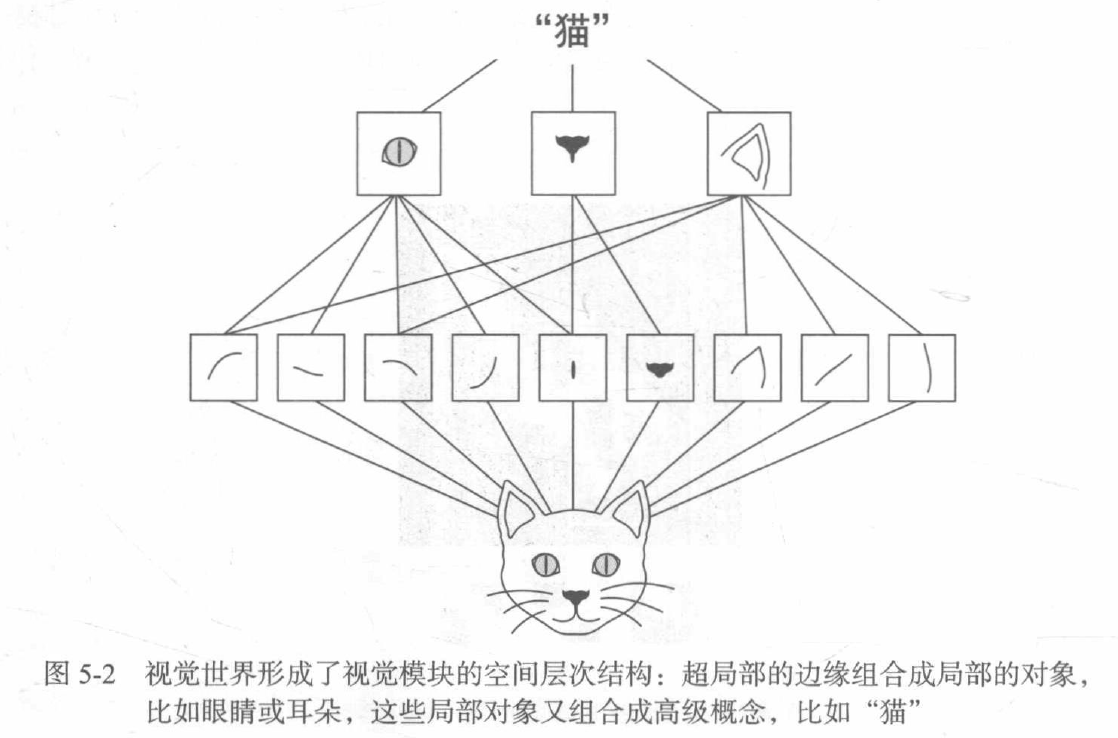
特征圖:深度軸的每個維度都是一個特征(或過濾器),而2D張量output[:, :, n]是這個過濾器在輸入上的回應的二維空間圖,
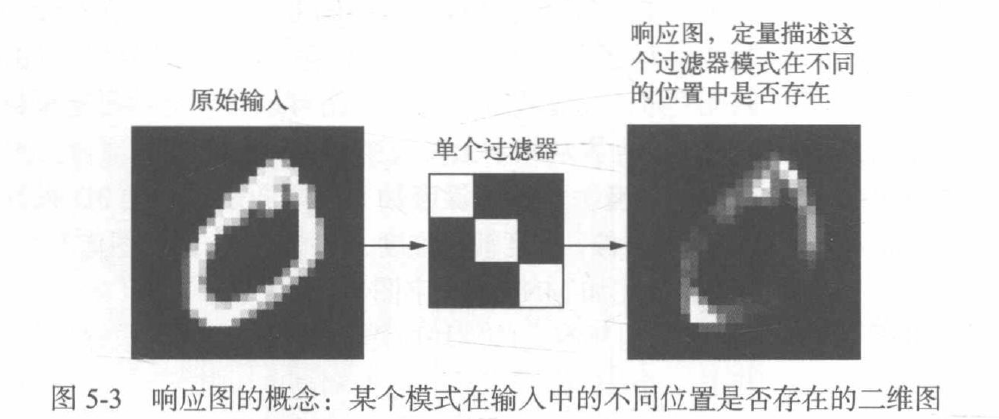
卷積由以下兩個關鍵引數所定義,
1.從輸入中提取的圖塊尺寸,
2.輸出特征圖的深度:卷積所計算的過濾器的數量,
卷積的作業原理:在3D輸入特征圖上滑動這些3x3或5x5的視窗,在每個可能的位置停止并提取周圍特征的3D圖塊[形狀為(window_height, window_width, input_depth)],然后每個3D圖塊與學到的同一個權重矩陣[叫作卷積核]做張量積,轉換成形狀為(output_depth,)的1D向量,然后對所有這些向量進行空間重組,使其轉換為形狀為(height, width, output_depth)的3D輸出特征圖,輸出特征圖中的每個空間位置都對應于輸入特征圖中的相同位置,
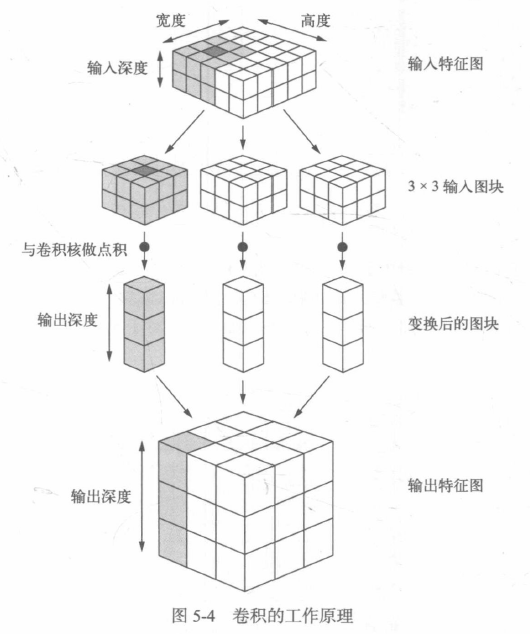
輸出的寬度和高度可能與輸入的寬度和高度不同,不同的原因可能有兩點:
(1)邊界效應,可以通過對輸入特征圖進行填充來抵消;
(2)使用了步幅,
1.理解邊界效應與填充
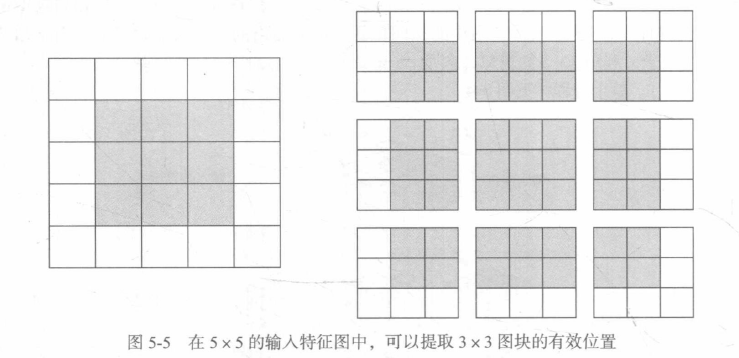
如果你希望輸出特征圖的空間維度與輸入相同,那么可以使用填充,填充是在輸入特征圖的每一邊添加適當資料的行和列,使得每個輸入方塊都能作為卷積視窗的中心,
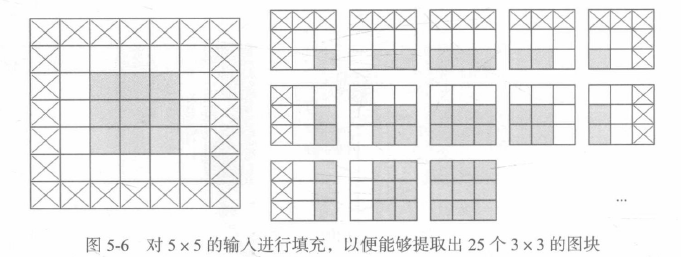
2.理解卷積步幅
影響輸出尺寸的另一個因素是步幅的概念,目前為止,對卷積的描述都假設卷積視窗的中心方塊都是相鄰的,但兩個連續視窗的距離是卷積的一個引數,叫作步幅,默認值為1,也可以使用步進卷積,即步幅大于1的卷積,
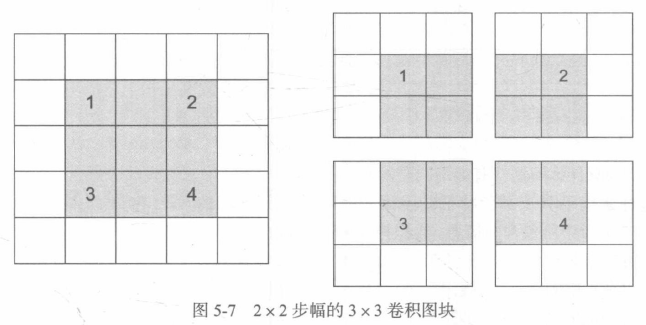
步幅為2意味著特征圖的寬度和高度都被做了2倍下采樣(除了邊界效應引起的變化),雖然步進卷積對某些型別的模型可能有用,但在實踐中很少使用,
為了對特征圖進行下采樣,我們不用步幅,而是通常使用最大池化運算,
5.1.2 最大池化運算
在卷積神經網路示例中,你可能注意到,在每個MaxPooling2D層之后,特征圖的尺寸都會減半,例如,在第一個MaxPooling2D層之前,特征圖的尺寸是26x26,但最大池化運算將其減半為13x13,這就是最大池化的作用:對特征圖進行下采樣,與步進卷積類似,
最大池化是從輸入特征圖中提取視窗,并輸出每個通道的最大值,它使用硬編碼的max張量運算對區域圖塊進行變換,而不是使用學到的線性變換,最大池化與卷積的最大不同之處在于,最大池化通常使用2x2的視窗和步幅2,其目的是將特征圖下采樣2倍,與此相對的是,卷積通常使用3x3視窗和步幅1,
from keras import layers
from keras import models
model_no_max_pool = models.Sequential()
model_no_max_pool.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)))
model_no_max_pool.add(layers.Conv2D(64, (3, 3), activation='relu'))
model_no_max_pool.add(layers.Conv2D(64, (3, 3), activation='relu'))
print(model_no_max_pool.summary())Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 26, 26, 32) 320
conv2d_1 (Conv2D) (None, 24, 24, 64) 18496
conv2d_2 (Conv2D) (None, 22, 22, 64) 36928
=================================================================
Total params: 55,744
Trainable params: 55,744
Non-trainable params: 0
_________________________________________________________________
None
這種架構有如下兩點問題:
1.這種架構不利于學習特征的空間層級結構,
2.最后一層的特征圖對每個樣本共有22x22x64=30976個元素,這太多了,如果你將其展平并在上面添加一個大小為512的Dense層,那一層將會有1580萬個引數,這對于這樣一個小模型來說太多了,會導致嚴重的過擬合,
簡而言之,使用下采樣的原因,一是減少需要處理的特征圖的元素個數,二是通過讓連續的卷積層的觀察視窗越來越大(即視窗覆寫原始輸入的比例越來越大),從而引入空間過濾器的層級結構,
最大池化不是實作這種下采樣的唯一方法,還可以在前一個卷積層中使用步幅來實作,此外,還可以使用平均池化來代替最大池化,其方法是將每個區域輸入圖塊變換為取該圖塊各通道的平均值,而不是最大值,但最大池化的效果往往比這些替代方法更好,
簡而言之,原因在于特征中往往編碼了某種模式或概念在特征圖的不同位置是否存在(因此得名特征圖),而觀察不同特征的最大值而不是平均值能夠給出更多的資訊,因此,最合理的子采樣策略是首先生成密集的特征圖(通過步進卷積)或對輸入圖塊取平均,因為后兩種方法可能導致錯過或淡化特征是否存在的資訊,
5.2 在小型資料集上從頭開始訓練一個卷積神經網路
5.2.1 深度學習與小資料問題的相關性
深度學習的一個基本特性就是能夠獨立地在訓練資料中找到有趣的特征,無須人為的特征工程,而這只有擁有大量訓練樣本時才能實作,對于輸入樣本的維度非常高(比如影像)的問題尤其如此,
由于卷積神經網路學到的是區域的、平移不變的特征,它對于感知問題可以高效地利用資料,雖然資料相對較少,但在非常小的影像資料集上從頭開始訓練一個卷積神經網路,仍然可以得到不錯的結果,而且無須任何自定義的特征工程,
此外,深度學習模型本質上具有高度的可復用性,比如,已有一個在大規模資料集上訓練的影像分類模型或語音轉文本模型,你只需做很小的修改就能將其復用與完全不同的問題,特別是在計算機視覺領域,許多預訓練的模型(通常都是在ImageNet資料集上訓練得到的)現在都可以公開下載,并可以用于在資料很少的情況下構建強大的視覺模型,
5.2.2 下載資料
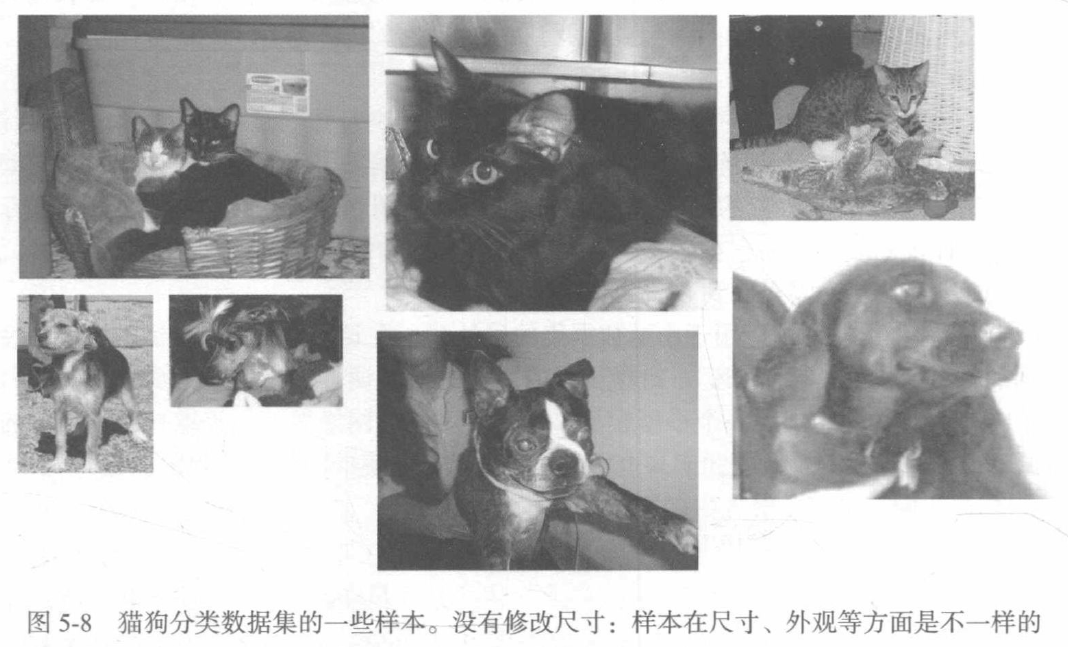
將影像復制到訓練、驗證和測驗的目錄:
import os
import shutil
original_dataset_dir = r'E:\train\train'
base_dir = r'E:\train\cats_and_dogs_small'
os.mkdir(base_dir)
train_dir = os.path.join(base_dir, 'train')
os.mkdir(train_dir)
validation_dir = os.path.join(base_dir, 'validation')
os.mkdir(validation_dir)
test_dir = os.path.join(base_dir, 'test')
os.mkdir(test_dir)
train_cats_dir = os.path.join(train_dir, 'cats')
os.mkdir(train_cats_dir)
train_dogs_dir = os.path.join(train_dir, 'dogs')
os.mkdir(train_dogs_dir)
validation_cats_dir = os.path.join(validation_dir, 'cats')
os.mkdir(validation_cats_dir)
validation_dogs_dir = os.path.join(validation_dir, 'dogs')
os.mkdir(validation_dogs_dir)
test_cats_dir = os.path.join(test_dir, 'cats')
os.mkdir(test_cats_dir)
test_dogs_dir = os.path.join(test_dir, 'dogs')
os.mkdir(test_dogs_dir)
fnames = ['cat.{}.jpg'.format(i) for i in range(1000)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(train_cats_dir, fname)
shutil.copyfile(src, dst)
fnames = ['cat.{}.jpg'.format(i) for i in range(1000, 1500)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(validation_cats_dir, fname)
shutil.copyfile(src, dst)
fnames = ['cat.{}.jpg'.format(i) for i in range(1500, 2000)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(test_cats_dir, fname)
shutil.copyfile(src, dst)
fnames = ['dog.{}.jpg'.format(i) for i in range(1000)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(train_dogs_dir, fname)
shutil.copyfile(src, dst)
fnames = ['dog.{}.jpg'.format(i) for i in range(1000, 1500)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(validation_dogs_dir, fname)
shutil.copyfile(src, dst)
fnames = ['dog.{}.jpg'.format(i) for i in range(1500, 2000)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(test_dogs_dir, fname)
shutil.copyfile(src, dst)
print('total training cat image:', len(os.listdir(train_cats_dir)))
print('total training dog images:', len(os.listdir(train_dogs_dir)))
print('total validation cat images:', len(os.listdir(validation_cats_dir)))
print('total validation dog images:', len(os.listdir(validation_dogs_dir)))
print('total test cat images:', len(os.listdir(test_cats_dir)))
print('total test cat images:', len(os.listdir(test_dogs_dir)))total training cat image: 1000
total training dog image: 1000
total validation cat image: 500
total validation dog image: 500
total test cat image: 500
total test dog image: 500所以我們的確有2000張訓練影像、1000張驗證影像和1000張測驗影像,每個分組中兩個類別的樣本數相同,這是一個平衡的二分類問題,分類精度可作為衡量成功的指標,
5.2.3 構建網路
你面對的是一個二分類問題,所以網路最后一層是使用sigmoid激活的單一單元(大小為1的Dense層),這個單元將對某個類別的概率進行編碼,
將貓狗分類的小型卷積神經網路實體化:
from keras import layers
from keras import models
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(150, 150, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
print(model.summary())配置模型用于訓練:
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=1e-4),
metrics=['acc'])
5.2.4 資料預處理
現在,資料以JPEG檔案的形式形式保存在硬碟中,所以資料預處理步驟大致如下:
(1)讀取影像檔案;
(2)將JPEG檔案解碼為RGB像素網格;
(3)將這些像素網路轉換為浮點數張量;
(4)將像素值(0~255范圍內)縮放到[0, 1]區間(神經網路喜歡處理較小的輸入值),
使用ImageDataGenerator從目錄中讀取影像:
from keras.preprocessing.image import ImageDataGenerator
train_datagen = ImageDataGenerator(rescale=1./255)
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
train_dir,
target_size=(150, 150),
batch_size=20,
class_mode='binary')
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size=(150, 150),
batch_size=20,
class_mode='binary'
)
利用批量生成器擬合模型:
history = model.fit_generator(
train_generator,
steps_per_epoch=100,
epochs=30,
validation_data=validation_generator,
validation_steps=50
)保存模型:
model.save('cats_and_dogs_small_1.h5')繪制訓練程序中的損失曲線和精度曲線:
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()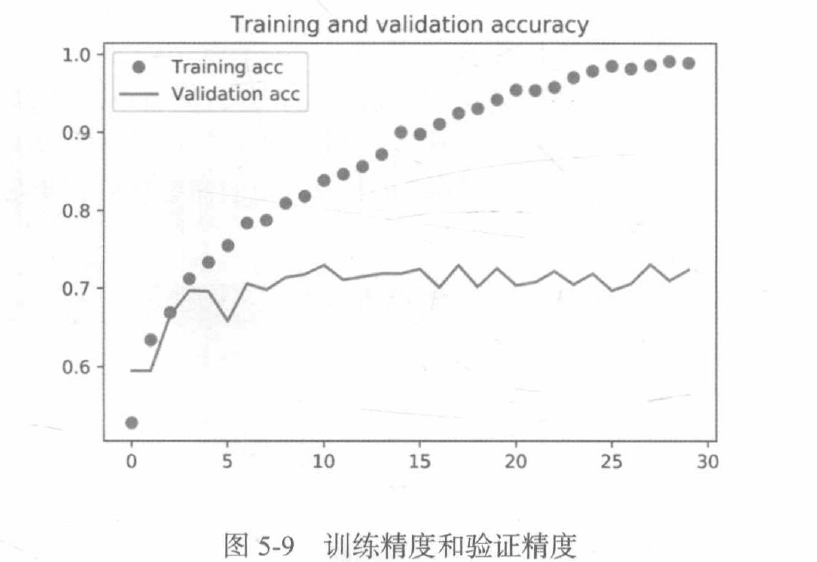
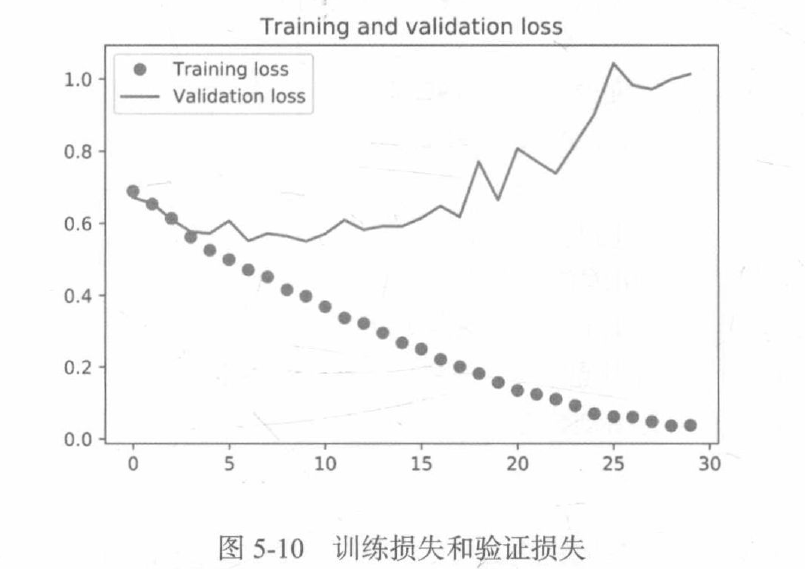
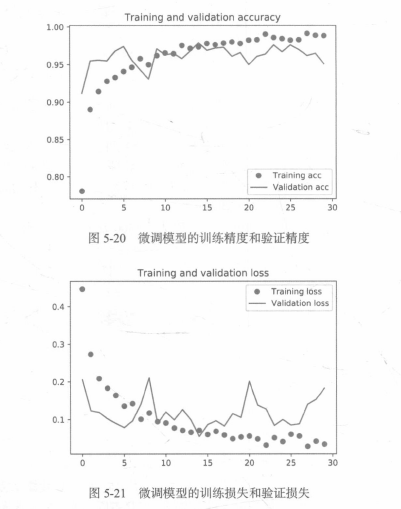
從這些影像中都能看出過擬合的特征,訓練精度隨著時間線性增加,直到接近100%,而驗證精度則停留在70%~72%,驗證損失僅在5輪后就達到最小值,然后保持不變,而訓練損失則一直線性下降,直到接近于0,因為訓練樣本相對較少(2000個),所以過擬合是你最關心的問題,
5.2.5 使用資料增強
過擬合的原因是學習樣本太少,導致無法訓練出能夠泛化到新資料的模型,如果擁有無限的資料,那么模型能夠觀察到資料分布的所有內容,這樣就永遠不會過擬合,資料增強是從現有的訓練樣本中生成更多的訓練資料,其方法是利用多種能夠生成可信影像的隨機變換來增加樣本,其目標是,模型在訓練時不會兩次查看完全相同的影像,這讓模型能夠觀察到資料的更多內容,從而具有更好的泛化能力,
利用ImageDataGenerator來設定資料增強:
datagen = ImageDataGenerator(
rotation_range=40,
width_shift_range=0.2,
heigth_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest'
)

顯示幾個隨機增強后的訓練影像:
# 顯示幾個隨機增強后的訓練影像
fnames = [os.path.join(train_cats_dir, fname) for fname in os.listdir(train_cats_dir)]
img_path = fnames[3] # 選擇一張影像進行增強
img = image.load_img(img_path, target_size=(150, 150)) # 讀取影像并調整大小
x = image.img_to_array(img) # 將其轉換為形狀(150,150,3)的Numpy陣列
x = x.reshape((1,) + x.shape) # 將其形狀改變為(1,150,150,3)
i = 0
for batch in datagen.flow(x, batch_size=1):
plt.figure(i)
imgplot = plt.imshow(image.array_to_img(batch[0]))
i += 1
if i % 4 == 0:
break
plt.show()
如果使用這種資料增強來訓練一個新網路,那么網路將不會兩次看到同樣的輸入,但網路看到的輸入仍然是高度相關的,因為這些輸入都來自于少量的原始影像,你無法生成新資訊,而只能混合現有資訊,因此,這種方法可能不足以完全消除過擬合,為了進一步降低過擬合,還需要向模型中添加一個Dropout層,添加到密集連接分類器之前,
定義一個包含dropout的新卷積神經網路:
# 定義一個包含dropout的新卷積神經網路
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(150, 150, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dropout(0.5))
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(1, activtion='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer=optimizers.RMSprop(lr=1e-4), metircs=['acc'])利用資料增強生成器訓練卷積神經網路:
# 利用資料增強生成訓練卷積神經網路
train_datagen = ImageDataGenerator(
rescale=1./255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
)
test_datagen = ImageDataGenerator(rescale=1./255) # 注意,不能增強驗證資料
train_generator = train_datagen.flow_from_directory(
train_dir, # 目標目錄
target_size=(150, 150), # 將所有影像的大小調整為150x150
batch_size=32,
class_mode='binary' # 因為使用了binary_crossentropy損失,所以需要用二進制標簽
)
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size=(150, 150),
batch_size=32,
class_mode='binary'
)
history = model.fit(
train_generator,
steps_per_epoch=100,
epochs=100,
validation_data=validation_generator,
validation_steps=50
)
保存模型:
# 保存模型
model.save('cats_and_dogs_small_2.h5')我們再次繪制結果:
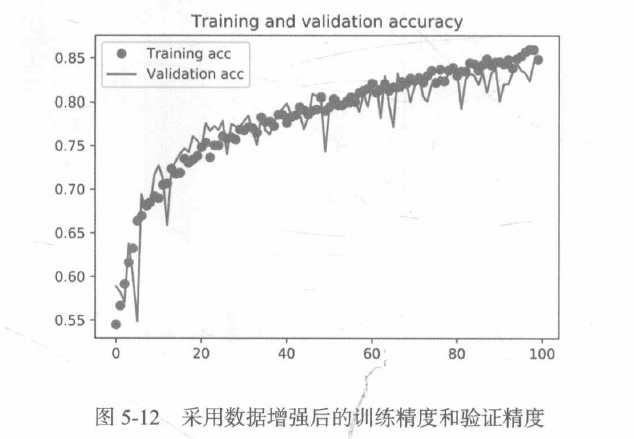
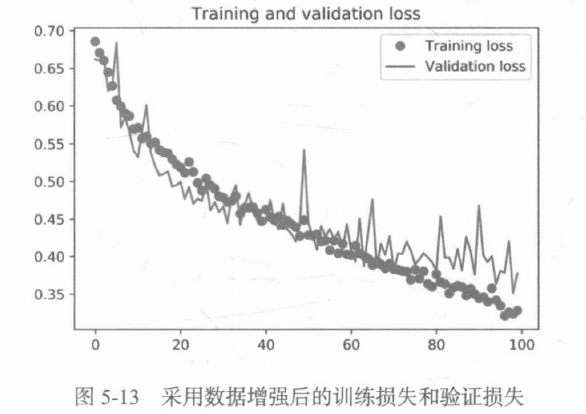
通過進一步使用正則化方法以及調節網路引數(比如每個卷積層的過濾器個數或網路中的層數),你可以得到更高的精度,但只靠從頭開始訓練自己的卷積神經網路,再想提高精度就十分困難,因為可用的資料太少,想要在這個問題上進一步提高精度,下一步需要使用預訓練的模型,
5.3 使用預訓練的卷積神經網路
想要將深度學習應用于小型影像資料集,一種常用且非常高效的方法是使用預訓練網路,預訓練網路是一個保存好的網路,之前已在大型資料集(通常是大規模影像分類任務) 上訓練好,如果這個原始資料集足夠大且足夠通用,那么預訓練網路學到的特征的空間層次結構可以有效地作為視覺世界的通用模型,因此這些特征可用于各種不同的計算機視覺問題,即使這些新問題涉及的類別和原始任務完全不同,
使用預訓練網路有兩種方法:特征提取和微調模型,
5.3.1 特征提取
特征提取是使用之前網路學到的表示來從新樣本中提取出有趣的特征,然后將這些特征輸入一個新的分類器,從頭開始訓練,
用于影像分類的卷積神經網路包含兩部分:首先是一系列池化層和卷積層,最后是一個密集連接分類器,第一部分叫作模型的卷積基,對于卷積神經網路而言,特征提取就是取出之前訓練好的網路的卷積基,在上面運行新資料,然后在輸出上面訓練的一個新的分類器,
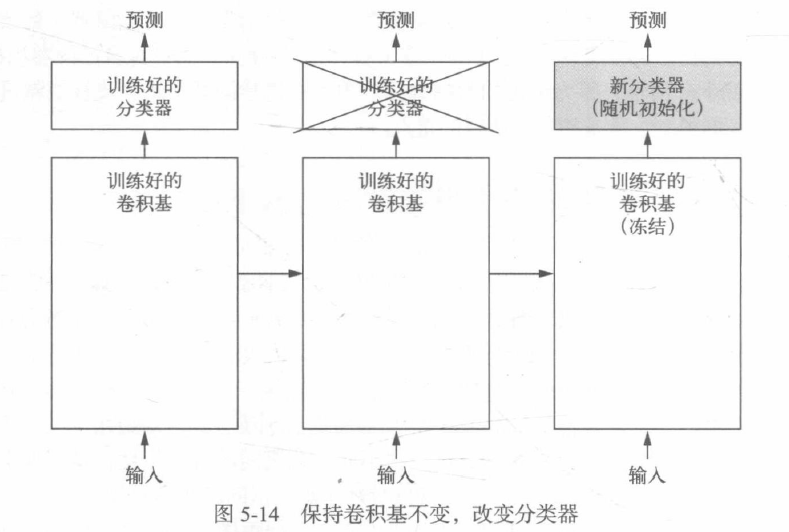
卷積基學到的表示可能更加通用,因此更適合重復使用,卷積神經網路的特征圖表示通用概念在影像中是否存在,無論面對什么樣的計算機視覺問題,這種特征圖都可能很有用,但是,分類器學到的表示必然是針對于模型訓練的類別,其中僅包含某個類別出現在整張影像中的概率資訊,此外,密集連接層的表示不再包含物體在輸入影像中的位置資訊,密集連接層舍棄了空間的概念,而物體位置資訊仍然由卷積特征圖所描述,如果物體位置對于問題很重要,那么密集連接層的特征在很大程度上是無用的,
某個卷積層提取的表示的通用性(以及可復用性)取決于該層在模型中的深度,模型中更靠近底部的層提取的是區域的、高度通用的特征圖(比如視覺邊緣、顏色和紋理),而更靠近頂部的層提取的是更加抽象的概念(比如“貓耳朵”或“狗眼睛”) ,因此,如果你的新資料集與原始模型訓練的資料集有很大差異,那么最好只使用模型的前幾層來做特征提取,而不是使用整個卷積基,
將VGG16卷積基實體化:
from keras.applications.vgg16 import VGG16
conv_base = VGG16(weights='imagenet',
include_top=False,
input_shape=(150, 150, 3))print(conv_base.summary())Model: "vgg16"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 150, 150, 3)] 0
block1_conv1 (Conv2D) (None, 150, 150, 64) 1792
block1_conv2 (Conv2D) (None, 150, 150, 64) 36928
block1_pool (MaxPooling2D) (None, 75, 75, 64) 0
block2_conv1 (Conv2D) (None, 75, 75, 128) 73856
block2_conv2 (Conv2D) (None, 75, 75, 128) 147584
block2_pool (MaxPooling2D) (None, 37, 37, 128) 0
block3_conv1 (Conv2D) (None, 37, 37, 256) 295168
block3_conv2 (Conv2D) (None, 37, 37, 256) 590080
block3_conv3 (Conv2D) (None, 37, 37, 256) 590080
block3_pool (MaxPooling2D) (None, 18, 18, 256) 0
block4_conv1 (Conv2D) (None, 18, 18, 512) 1180160
block4_conv2 (Conv2D) (None, 18, 18, 512) 2359808
block4_conv3 (Conv2D) (None, 18, 18, 512) 2359808
block4_pool (MaxPooling2D) (None, 9, 9, 512) 0
block5_conv1 (Conv2D) (None, 9, 9, 512) 2359808
block5_conv2 (Conv2D) (None, 9, 9, 512) 2359808
block5_conv3 (Conv2D) (None, 9, 9, 512) 2359808
block5_pool (MaxPooling2D) (None, 4, 4, 512) 0
=================================================================
Total params: 14,714,688
Trainable params: 14,714,688
Non-trainable params: 0
_________________________________________________________________
None
最后的特征圖形狀為(4, 4, 512),我們將在這個特征上添加一個密集連接分類器,下一步有兩種方法可供選擇:
(1)在你的資料集上運行卷積基,將輸出保存成硬碟中的Numpy陣列,然后用這個資料作為輸入,輸入到獨立的密集連接分類其中,
(2)在頂部添加Dense層來擴展已有模型,并在輸入資料上端到端地運行整個模型,
1.不使用資料增強的快速特征提取
# 使用預訓練的卷積基提取特征
import os
import numpy as np
from keras.preprocessing.image import ImageDataGenerator
from keras.applications.vgg16 import VGG16
# 將VGG16卷積實體化
conv_base = VGG16(weights='imagenet',
include_top=False,
input_shape=(150, 150, 3))
base_dir = r'E:\train'
train_dir = os.path.join(base_dir, 'train')
validation_dir = os.path.join(base_dir, 'validation')
test_dir = os.path.join(base_dir, 'test')
datagen = ImageDataGenerator(rescale=1./255)
batch_size = 20
def extract_features(directory, sample_count):
features = np.zeros(shape=(sample_count, 4, 4, 512))
labels = np.zeros(shape=sample_count)
generator = datagen.flow_from_diretory(
directory,
target_size=(150, 150),
batch_size=batch_size,
class_mode='binary'
)
i = 0
for inputs_batch, labels_batch in generator:
features_batch = conv_base.predict(inputs_batch)
features[i * batch_size : (i + 1) * batch_size] = features_batch
labels[i * batch_size : (i + 1) * batch_size] = labels_batch
i += 1
if i * batch_size >= sample_count:
break
if i * batch_size >= sample_count:
break
return features, labels
train_features, train_labels = extract_features(train_dir, 2000)
validation_features, validation_labels = extract_features(validation_dir, 1000)
test_features, test_labels = extract_features(test_dir, 1000)
# 將提取的特征形狀展平為(samples, 8192)
train_features = np.reshape(train_features, (2000, 4 * 4 * 512))
validation_features = np.reshape(validation_features, (1000, 4 * 4 * 512))
test_features = np.reshape(test_features, (1000, 4 * 4 * 512))定義并訓練密集連接分類器:
from keras import models
from keras import layers
from tensorflow import optimizers
model = models.Sequential()
model.add(layers.Dense(256, activation='relu', input_dim=4 * 4 * 512))
model.add(layers.Dropout(0.5))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(optimizer=optimizers.RMSprop(lr=2e-5),
loss='binary_crossentropy',
metircs=['acc'])
history = model.fit(train_features, train_labels,
epochs=30,
batch_size=20,
validation_data=(validation_features, validation_labels))繪制結果:
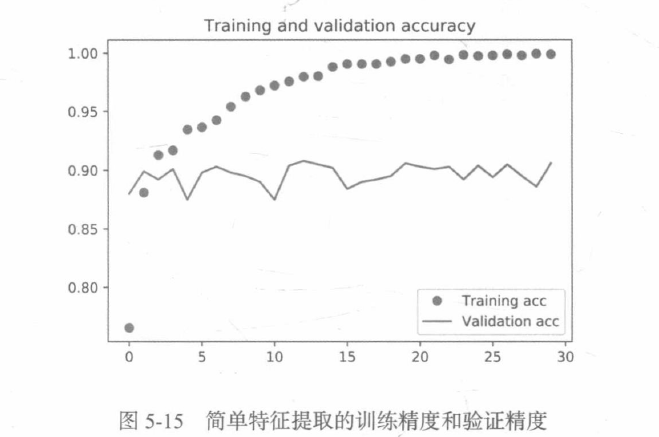
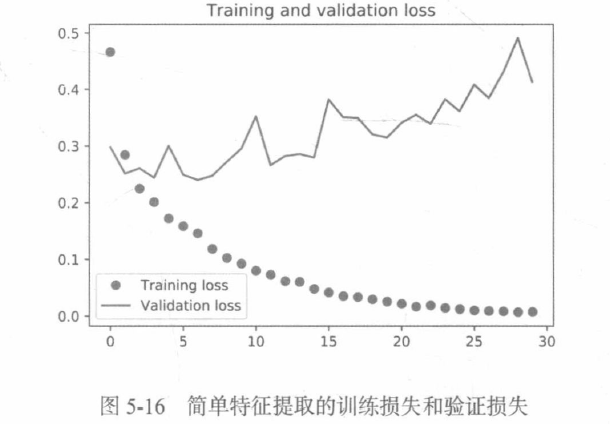
我們的驗證精度達到了約90%,比從頭開始訓練的小型模型效果要好得多,從圖中也可以看出,雖然dropout比率相當大,但模型幾乎從一開始就過擬合,這是因為本方法沒有使用資料增強,而資料增強對防止小型影像資料集的過擬合非常重要,
2.使用資料增強的特征提取
擴展conv_base模型,然后在輸入資料上端到端地運行模型,模型的行為和層類似,所以你可以向Sequential模型中添加一個模型(比如conv_base),就像添加一個層一樣,
在卷積基上添加一個密集連接分類器:
from keras import models
from keras import layers
from keras.applications.vgg16 import VGG16
conv_base = VGG16(weights='imagenet',
include_top=False,
input_shape=(150, 150, 3))
model = models.Sequential()
model.add(conv_base)
model.add(layers.Flatten())
model.add(layers.Dense(256, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
print(model.summary())Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
vgg16 (Functional) (None, 4, 4, 512) 14714688
flatten (Flatten) (None, 8192) 0
dense (Dense) (None, 256) 2097408
dense_1 (Dense) (None, 1) 257
=================================================================
Total params: 16,812,353
Trainable params: 16,812,353
Non-trainable params: 0
_________________________________________________________________
None
在編譯和訓練模型之前,一定要“凍結”卷積基,凍結一個或多個層是指在訓練程序中保持其權重不變,如果不這么做,那么卷積基之前學到的表示將會在訓練程序中被修改,因為其上添加的Dense層是隨機初始化的,所以非常大的權重更新將會在網路中傳播,對之前學到的表示造成很大破壞,
print('This is the number of trainable weights before freezing the conv base:', len(model.trainable_weights))
conv_base.trainable = False
print('This is the number of trainable weights after freezing the conv base:', len(model.trainable_weights))This is the number of trainable weights before freezing the conv base: 30
This is the number of trainable weights after freezing the conv base: 4
利用凍結的卷積基端到端地訓練模型:
train_generator = train_datagen.flow_from_directory(
train_dir,
target_size=(150, 150),
batch_size=20,
class_mode='binary'
)
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size=(150, 150),
batch_size=20,
class_mode='binary'
)
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=2e-5),
metrics=['acc'])
history = model.fit_generator(
train_generator,
steps_per_epoch=100,
epochs=30,
validation_data=validation_generator,
validation_steps=50
)
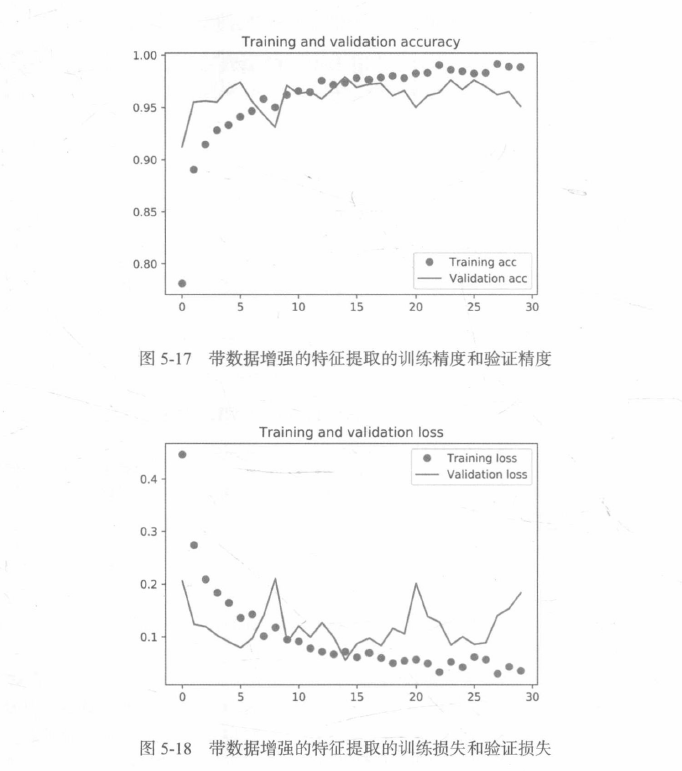
5.3.2 微調模型
另一種廣泛使用的模型復用方法是模型微調,與特征提取互為補充,對于用于特征提取的凍結的模型基,微調是指將其頂部的幾層“解凍”,并將這解凍的幾層和新增加的部分聯合訓練,之所以叫作微調,是因為它只是略微調整了所復用模型中更加抽象的表示,以便讓這些表示與手頭的問題更加相關,
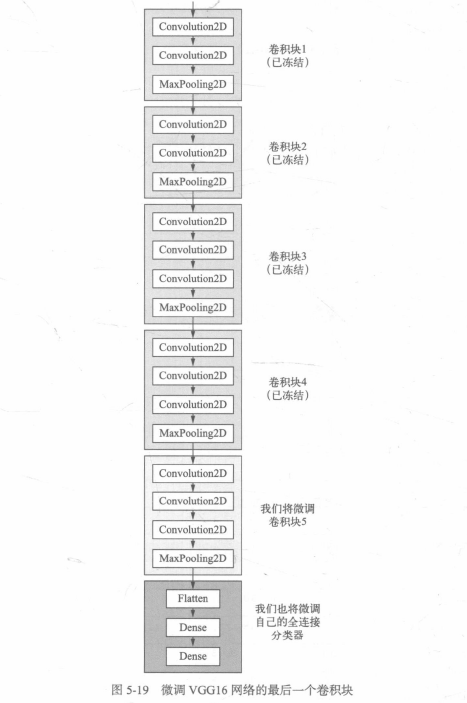
微調網路的步驟如下:
(1)在已經訓練好的基網路上添加自定義網路;
(2)凍結基網路;
(3)訓練所添加的部分;
(4)解凍基網路的一些層;
(5)聯合訓練解凍的這些層和添加的部分,
卷積基中更靠底部的層編碼的是更加通用的可復用特征,而更靠頂部的層編碼的是更專業化的特征,微調這些更專業化的特征更加有用,因為它們需要在你的新問題上改變用途,微調更靠底部的層,得到的回報會更少,
訓練的引數越多,過擬合的風險越大,卷積基有1500萬個引數,所以在你的小型資料集上訓練這么多引數是有風險的,
凍結直到某一層的所有層:
# 凍結直到某一層的所有層
conv_base.trainable = True
set_trainable = False
for layer in conv_base.layers:
if layer.name == 'block5_conv1':
set_trainable = True
if set_trainable:
layer.trainable = True
else:
layer.trainable = False
# 微調模型
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=1e-5),
metrics=['acc'])
history = model.fit_generator(
train_generator,
steps_per_epoch=100,
epochs=100,
validation_data=validation_generator,
validation_steps=50
)
使曲線變得平滑:
# 使曲線變得平滑
def smooth_curve(points, factor=0.8):
smoothed_points = []
for point in points:
if smoothed_points:
previous = smoothed_points[-1]
smoothed_points.append(previous * factor + point * (1 - factor))
else:
smoothed_points.append(point)
return smoothed_points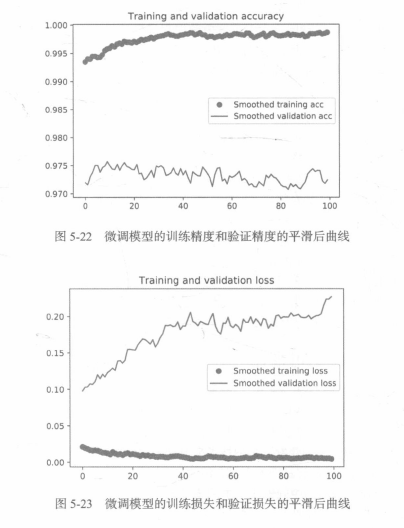
test_generator = test_datagen.flow_from_directory(
test_dir,
target_size=(150, 150),
batch_size=20,
class_mode='binary'
)
test_loss, test_acc = model.evaluate_generator(test_generator, steps=50)
print('test acc:', test_acc)5.3.3 小結
1.卷積神經網路是用于計算機視覺任務的最佳機器學習模型,即使在非常小的資料集上也可以從頭開始訓練一個卷積神經網路,而且得到的結果還不錯,
2.在小型資料集上的主要問題是過擬合,在處理影像資料時,資料增強是一種降低過擬合的強大方法;
3.利用特征提取,可以很容易將現有的卷積神經網路復用于新的資料集,對于小型影像資料集,這是一種很有價值的方法;
4.作為特征提取的補充,你還可以使用微調,將現有模型之前學到的一些資料表示應用于新問題,這種方法可以進一步提高模型性能,
5.4 卷積神經網路的可視化
人們常說,深度學習模型是“黑盒”, 即模型學到的表示很難用人類可以理解的方式來提取和呈現,雖然對于某些型別的深度學習模型來說,這種說法部分正確,但對卷積神經網路來說絕不是這樣,卷積神經網路學到的表示非常適合可視化,很大程度上是因為它們是視覺概念的表示,
三種最容易理解也最有用的對這些表示進行可視化和解釋的方法:
1.可視化卷積神經網路的中間輸出(中間激活);
2.可視化卷積神經網路的過濾器;
3.可視化影像中類激活的熱力圖,
5.4.1 可視化中間激活
可視化中間激活,是指對于給定輸入,展示網路中各個卷積層和池化層輸出的特征圖(層的輸出通常被稱為該層的激活,即激活函式的輸出),這讓我們可以看到輸入如何被分解為網路學到的不同過濾器,
(這一章的代碼實作遇到了一些問題,暫且跳過這一章,先進入下一章的學習)
有木有大佬能夠幫忙解答一下如下問題:
使用如下代碼匯入optimizers
from keras import optimizers運行后顯示:
AttributeError: module 'keras.optimizers' has no attribute 'RMSprop'將匯入方式改成如下:
from tensorflow import optimizers則又顯示:
AttributeError: module 'tensorflow.compat.v2.__internal__.distribute' has no attribute 'strategy_supports_no_merge_call'
請問如何解決?
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/430263.html
標籤:AI
上一篇:狀態機游戲AI設計