kafka
一、基礎架構
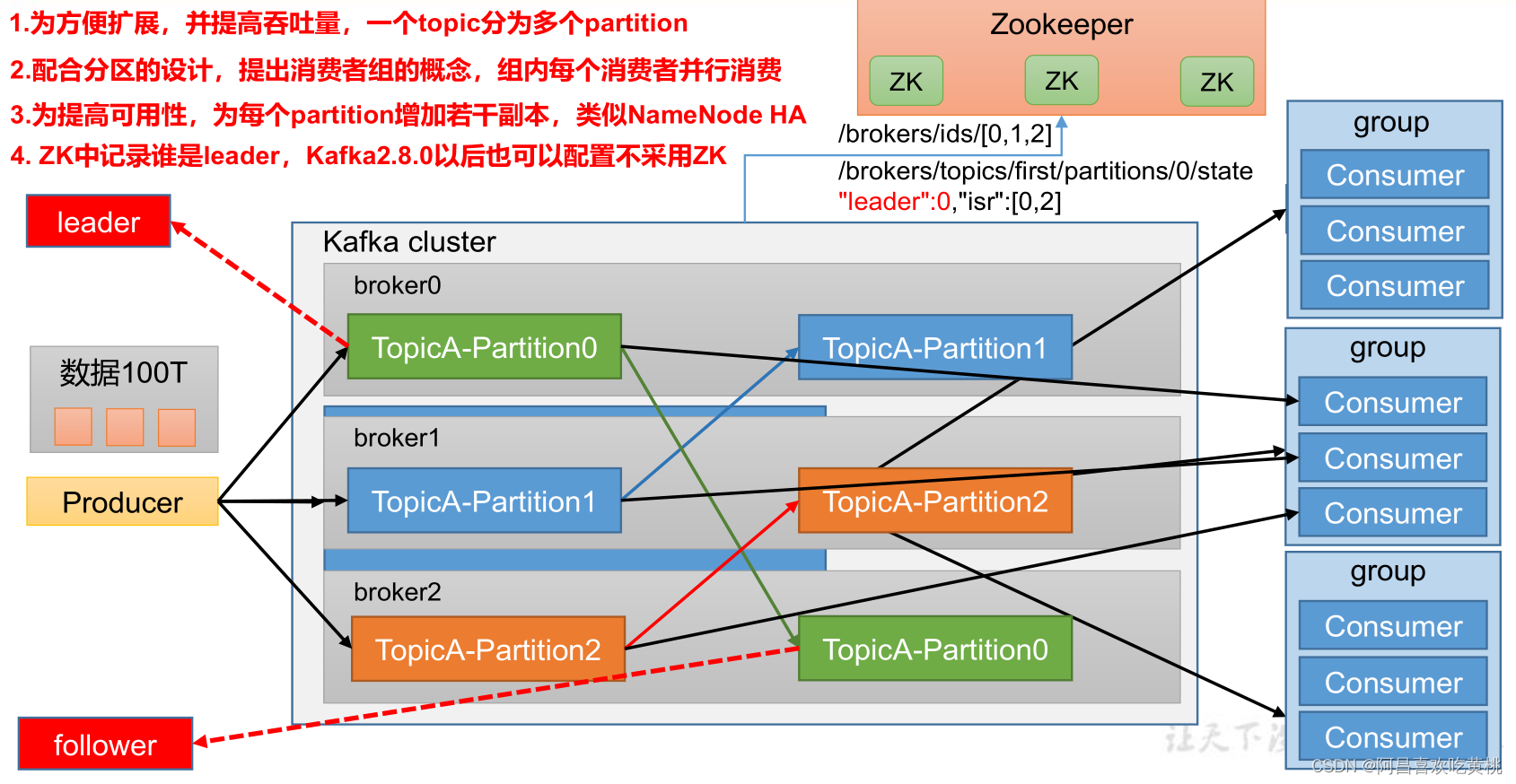

二、Kafka 快速入門
1、集群規劃

2、集群部署
下載地址
1 )解壓安裝包:
tar -zxvf kafka_2.12-3.0.0.tgz -C /opt/module/
2 )修改解壓后的檔案名稱:
mv kafka_2.12-3.0.0/ kafka
3 )進入到/opt/module/kafka 目錄,修改組態檔
cd config/
vim server.properties
輸入以下內容:


#broker 的全域唯一編號,不能重復,只能是數字,
broker.id=0
#處理網路請求的執行緒數量
num.network.threads=3
#用來處理磁盤 IO 的執行緒數量
num.io.threads=8
#發送套接字的緩沖區大小
socket.send.buffer.bytes=102400
#接收套接字的緩沖區大小
socket.receive.buffer.bytes=102400
#請求套接字的緩沖區大小
socket.request.max.bytes=104857600
#kafka 運行日志(資料)存放的路徑,路徑不需要提前創建,kafka 自動幫你創建,可以
配置多個磁盤路徑,路徑與路徑之間可以用","分隔
log.dirs=/opt/module/kafka/datas
#topic 在當前 broker 上的磁區個數
num.partitions=1
#用來恢復和清理 data 下資料的執行緒數量
num.recovery.threads.per.data.dir=1
# 每個 topic 創建時的副本數,默認時 1 個副本
offsets.topic.replication.factor=1
#segment 檔案保留的最長時間,超時將被洗掉
log.retention.hours=168
#每個 segment 檔案的大小,默認最大 1G
log.segment.bytes=1073741824
# 檢查過期資料的時間,默認 5 分鐘檢查一次是否資料過期
log.retention.check.interval.ms=300000
#配置連接 Zookeeper 集群地址(在 zk 根目錄下創建/kafka,方便管理)
zookeeper.connect=hadoop102:2181,hadoop103:2181,hadoop104:2181/kafka
3、集群 啟停腳本
在/home/atguigu/bin 目錄下創建檔案 kf.sh 腳本檔案
vim kf.sh
腳本如下:
#! /bin/bash
case $1 in
"start"){
for i in hadoop102 hadoop103 hadoop104
do
echo " --------啟動 $i Kafka-------"
ssh $i "/opt/module/kafka/bin/kafka-server-start.sh -daemon /opt/module/kafka/config/server.properties"
done
};;
"stop"){
for i in hadoop102 hadoop103 hadoop104
do
echo " --------停止 $i Kafka-------"
ssh $i "/opt/module/kafka/bin/kafka-server-stop.sh "
done
};;
esac
添加執行權限
chmod +x kf.sh
啟動集群命令
kf.sh start
停止集群命令
kf.sh stop

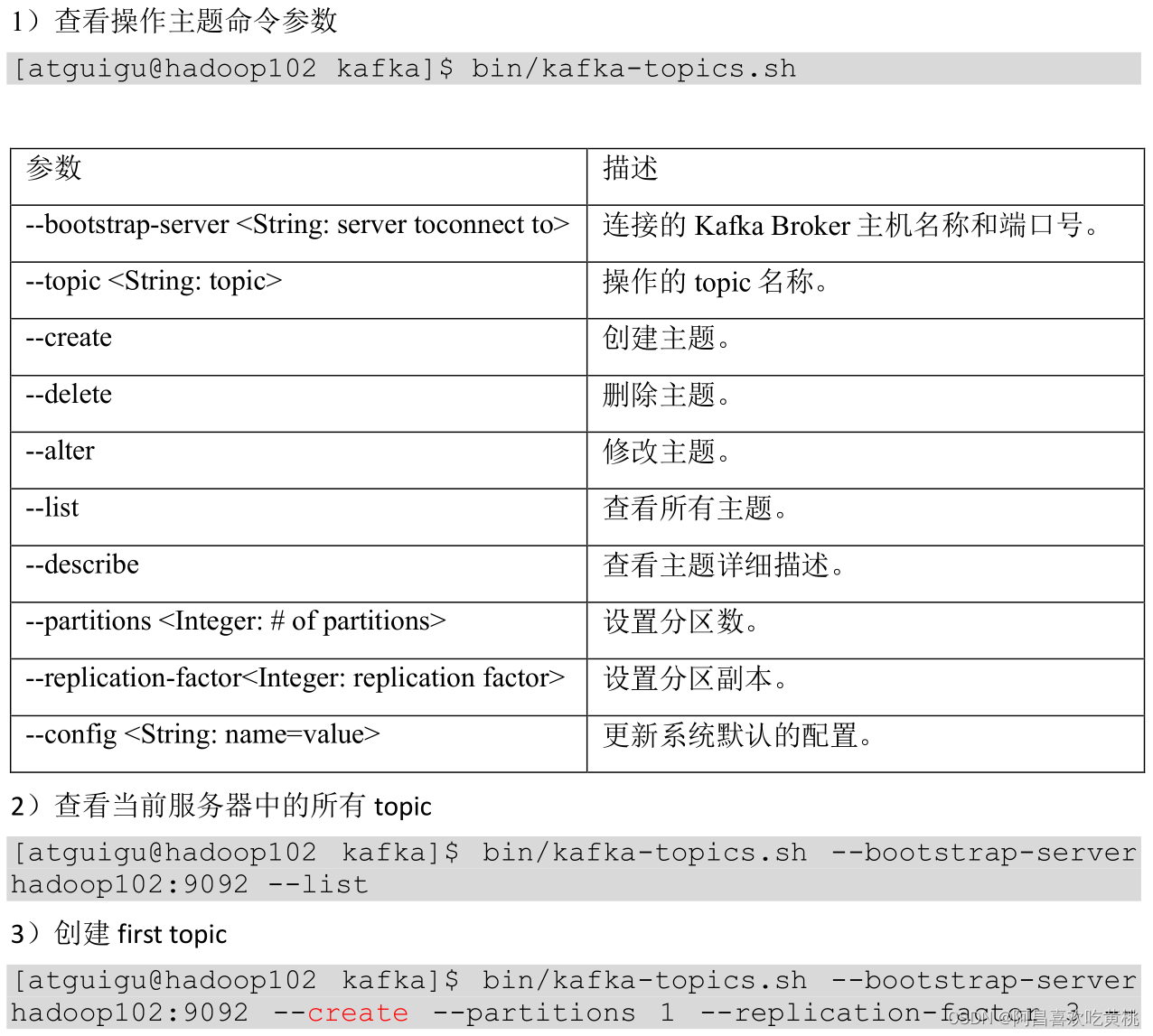
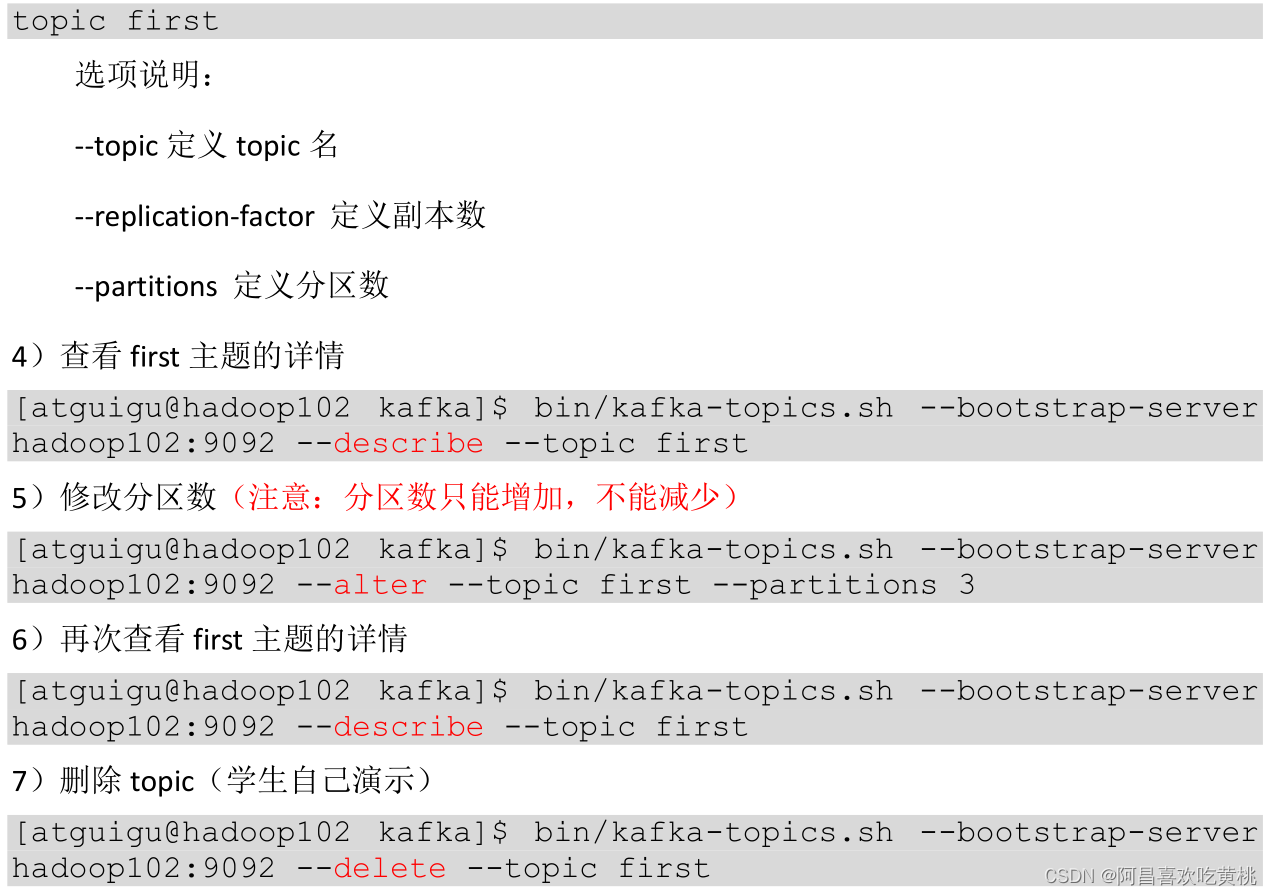
3、Kafka 命令列操作
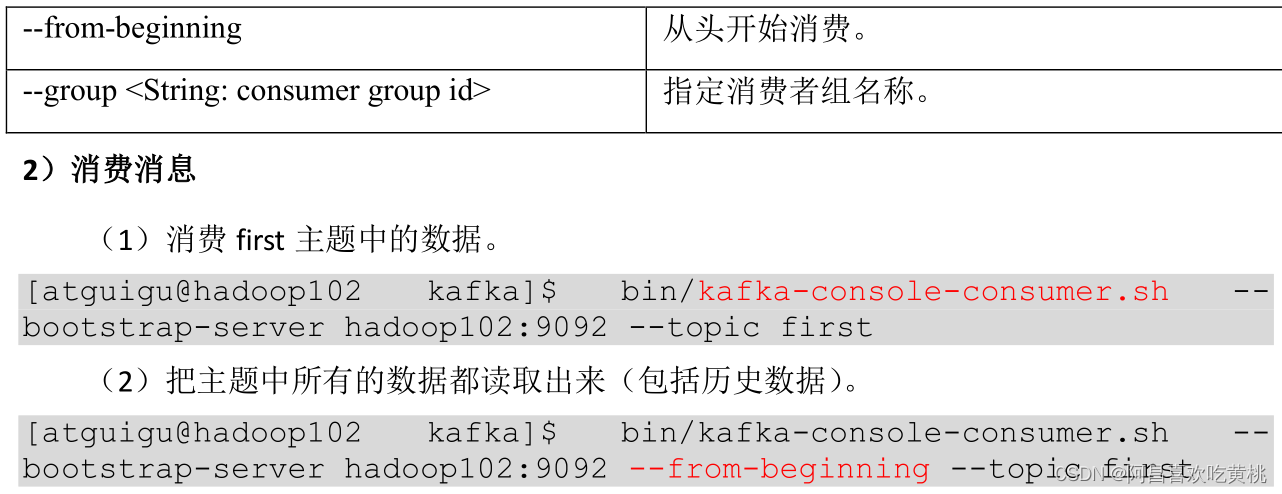
4、生產者命令 行操作

三、Kafka 生產者
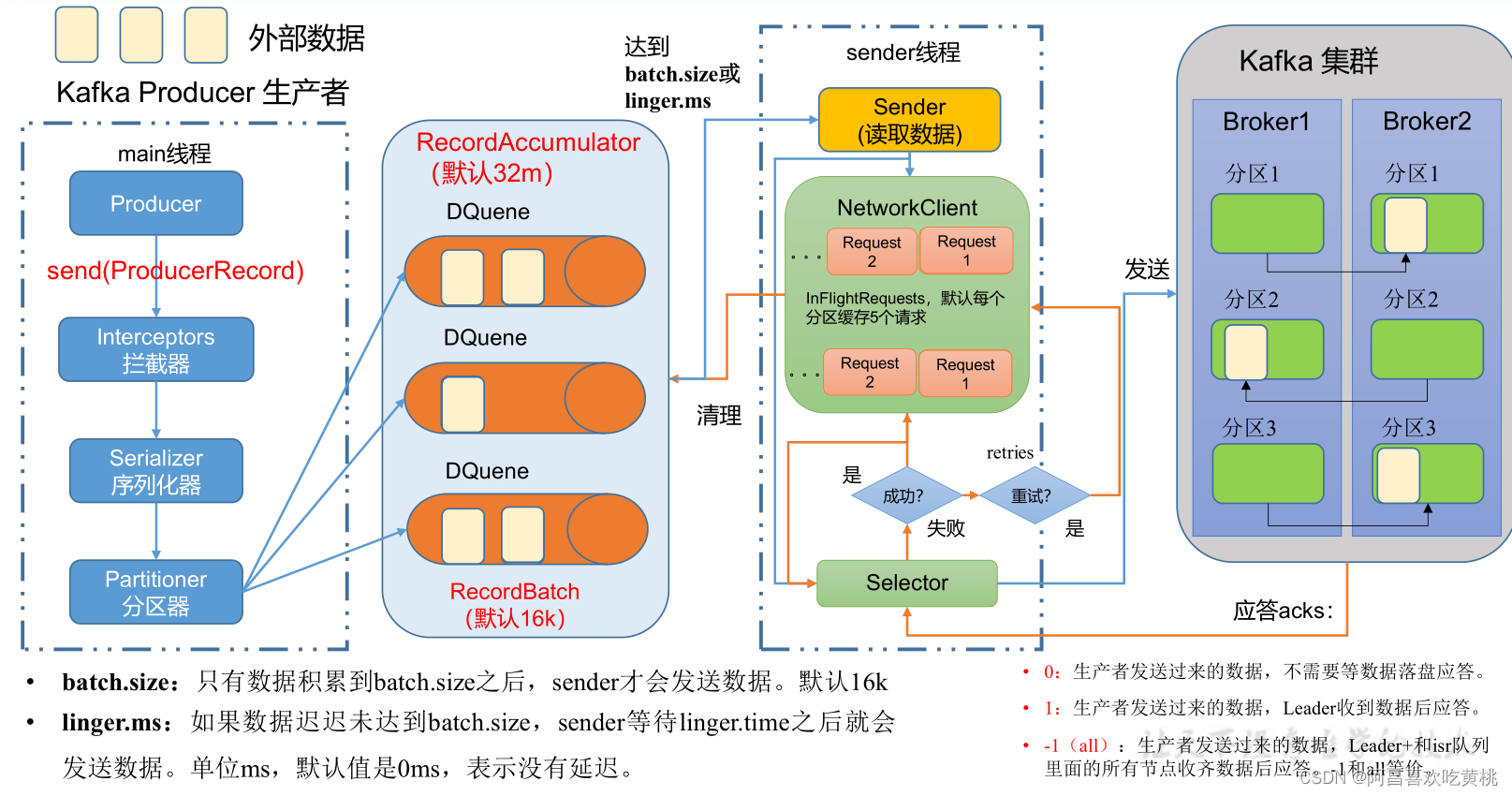
1、生產者 訊息發送流程
①發送原理
在訊息發送的程序中,涉及到了 兩個執行緒 ——main 執行緒和Sender 執行緒,
在 main 執行緒中創建了 一個 雙端列佇列 RecordAccumulator,
main執行緒將訊息發送給RecordAccumulator,Sender執行緒不斷從 RecordAccumulator 中拉取訊息發送到 Kafka Broker,
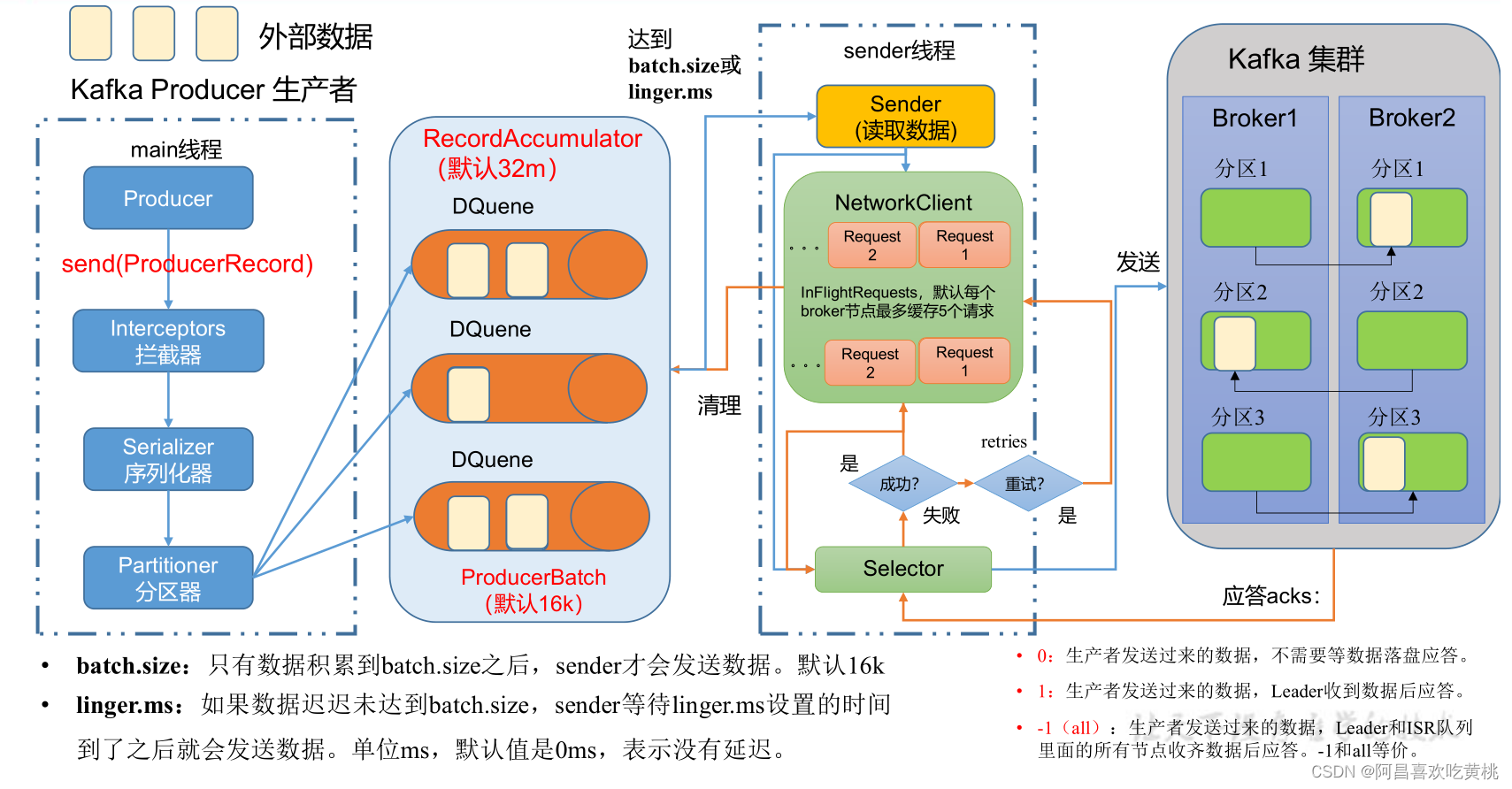
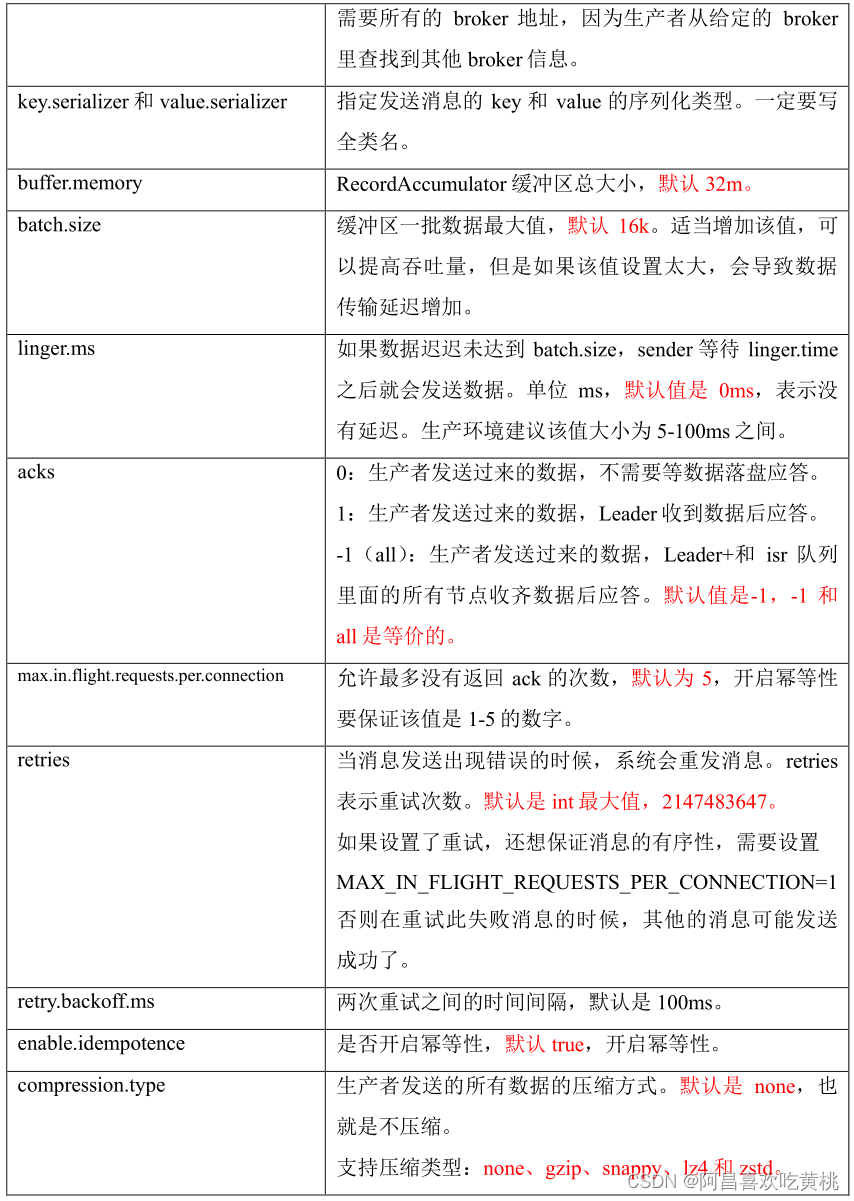
②生產者重要引數串列

2、異步送 發送 API
①普通異步發送
需求:創建 Kafka生產者,采用異步的方式發送到 Kafka Broker
匯入依賴
<dependencies>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.0.0</version>
</dependency>
</dependencies>
撰寫不帶回呼函式的 API代碼:
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
public class CustomProducer {
public static void main(String[] args) throws InterruptedException {
// 1. 創建 kafka 生產者的配置物件
Properties properties = new Properties();
// 2. 給 kafka 配置物件添加配置資訊:bootstrap.servers
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,
"hadoop102:9092");
// key,value 序列化(必須):key.serializer,value.serializer
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer");
// 3. 創建 kafka 生產者物件
KafkaProducer<String, String> kafkaProducer = new
KafkaProducer<String, String>(properties);
// 4. 呼叫 send 方法,發送訊息
for (int i = 0; i < 5; i++) {
kafkaProducer.send(new
ProducerRecord<>("first","atguigu " + i));
}
// 5. 關閉資源
kafkaProducer.close();
}
}
②帶回呼函式的 異步發送
回呼函式會在 producer 收到 ack 時呼叫,為異步呼叫,該方法有兩個引數,分別是元
資料資訊(RecordMetadata)和例外資訊(Exception)
如果 Exception 為 null,說明訊息發送成功,如果 Exception 不為 null,說明訊息發送失敗,
注意:訊息發送失敗會自動重試,不需要我們在回呼函式中手動重試,
import org.apache.kafka.clients.producer.*;
import java.util.Properties;
public class CustomProducerCallback {
public static void main(String[] args) throws InterruptedException {
// 1. 創建 kafka 生產者的配置物件
Properties properties = new Properties();
// 2. 給 kafka 配置物件添加配置資訊
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,
"hadoop102:9092");
// key,value 序列化(必須):key.serializer,value.serializer
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
StringSerializer.class.getName());
// 3. 創建 kafka 生產者物件
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<String, String>(properties);
// 4. 呼叫 send 方法,發送訊息
for (int i = 0; i < 5; i++) {
// 添加回呼
kafkaProducer.send(new ProducerRecord<>("first","atguigu " + i), new Callback() {
// 該方法在 Producer 收到 ack 時呼叫,為異步呼叫
@Override
public void onCompletion(RecordMetadata metadata,Exception exception) {
if (exception == null) {
// 沒有例外,輸出資訊到控制臺
System.out.println(" 主 題 : " +
metadata.topic() + "->" + "磁區:" + metadata.partition());
} else {
// 出現例外列印
exception.printStackTrace();
}
}
});
// 延遲一會會看到資料發往不同磁區
Thread.sleep(2);
}
// 5. 關閉資源
kafkaProducer.close();
}
}
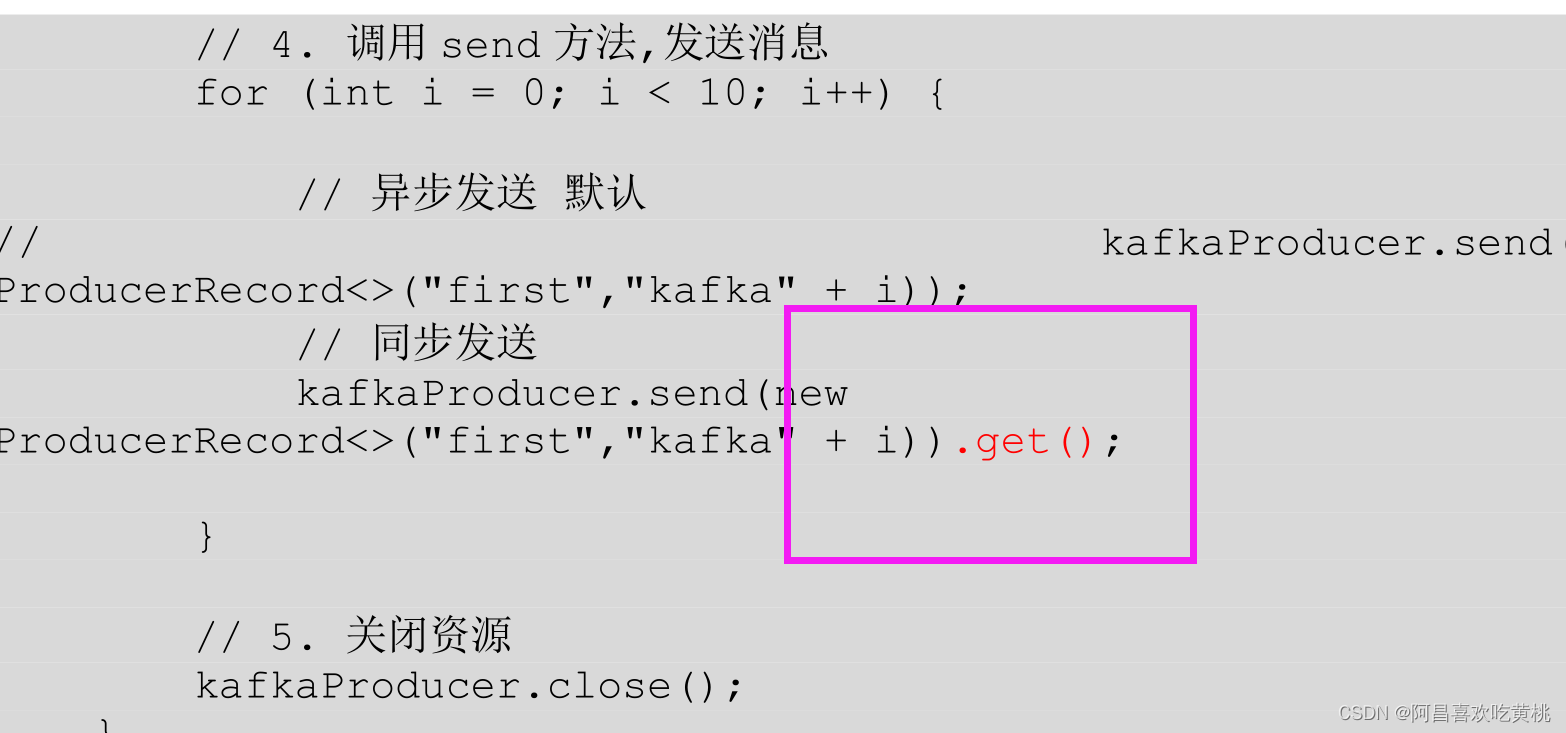
③同步發送 API
只需在異步發送的基礎上,再呼叫一下 get()方法即可,
四、生產者磁區
1、磁區好處
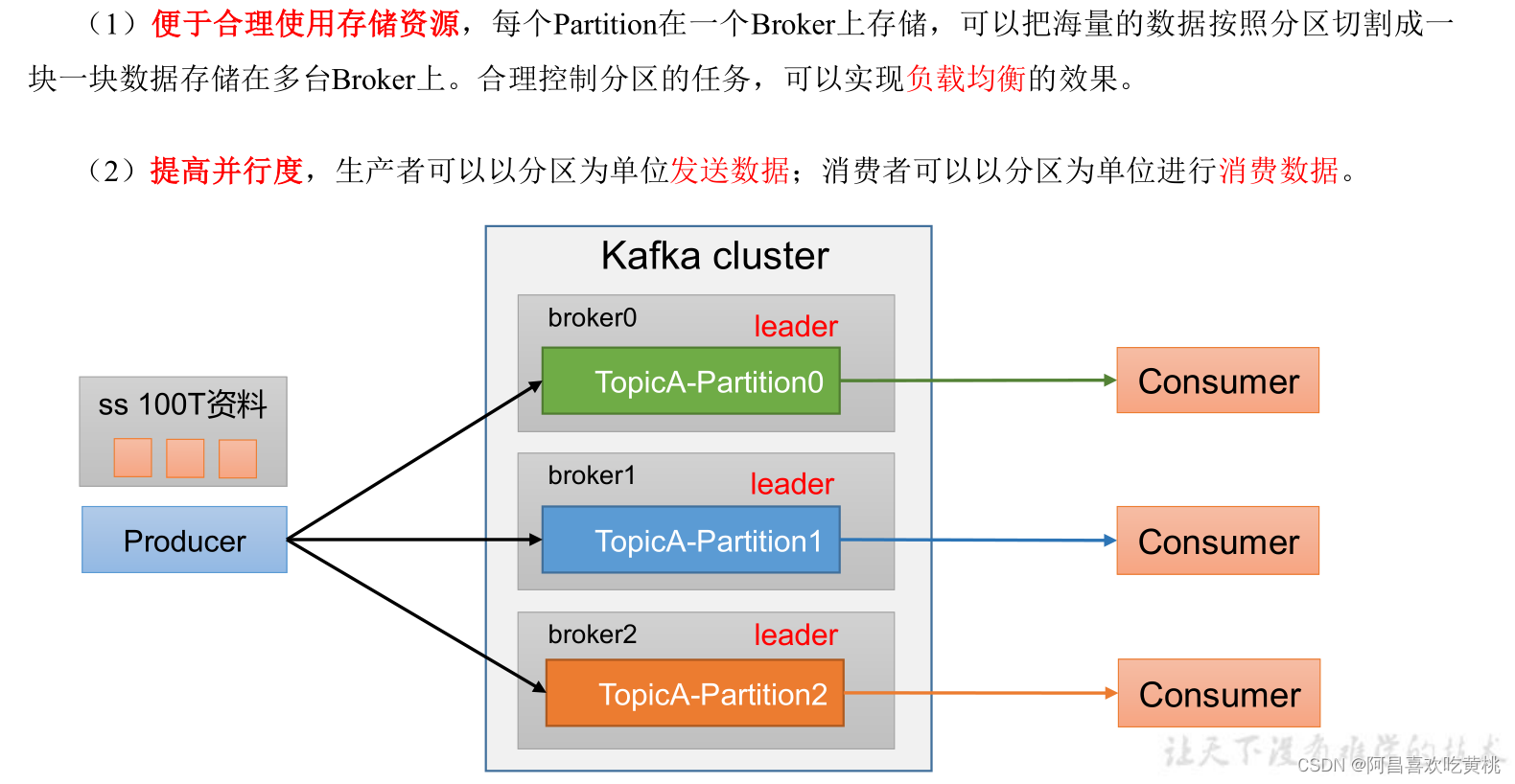
2、生產者發送訊息的磁區策略
①默認的磁區器 DefaultPartitioner
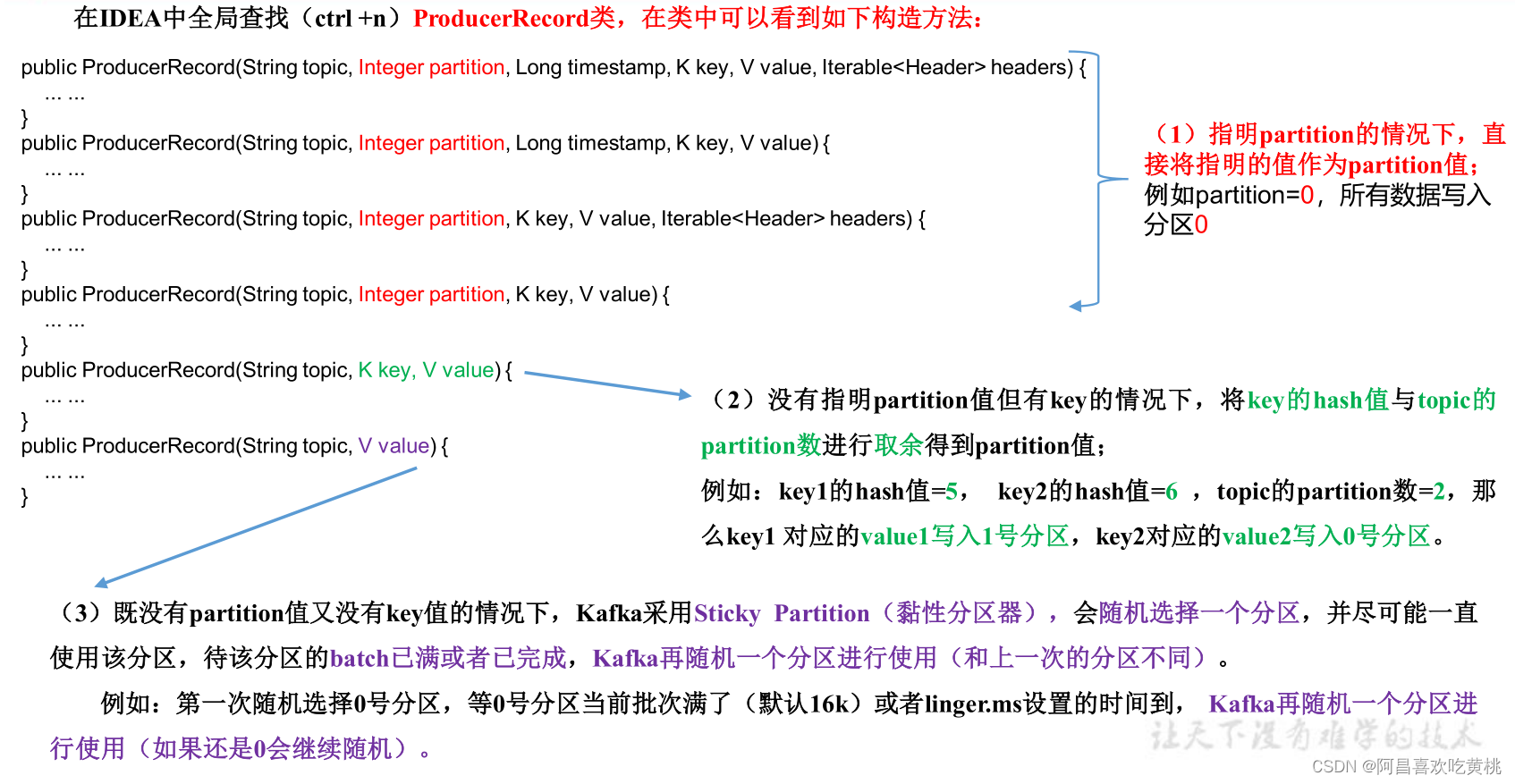
②自定義磁區器
實作步驟:
- (1)定義類實作 Partitioner 介面,
- (2)重寫 partition()方法,
import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.common.Cluster;
import java.util.Map;
/**
* 1. 實作介面 Partitioner
* 2. 實作 3 個方法:partition,close,configure
* 3. 撰寫 partition 方法,回傳磁區號
*/
public class MyPartitioner implements Partitioner {
/**
* 回傳資訊對應的磁區
* @param topic 主題
* @param key 訊息的 key
* @param keyBytes 訊息的 key 序列化后的位元組陣列
* @param value 訊息的 value
* @param valueBytes 訊息的 value 序列化后的位元組陣列
* @param cluster 集群元資料可以查看磁區資訊
* @return
*/
@Override
public int partition(String topic, Object key, byte[]
keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
// 獲取訊息
String msgValue = value.toString();
// 創建 partition
int partition;
// 判斷訊息是否包含 atguigu
if (msgValue.contains("atguigu")){
partition = 0;
}else {
partition = 1;
}
// 回傳磁區號
return partition;
}
// 關閉資源
@Override
public void close() {
}
// 配置方法
@Override
public void configure(Map<String, ?> configs) {
}
}
使用磁區器的方法,在生產者的配置中添加磁區器引數,
import org.apache.kafka.clients.producer.*;
import java.util.Properties;
public class CustomProducerCallbackPartitions {
public static void main(String[] args) throws InterruptedException {
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102
:9092");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
StringSerializer.class.getName());
// 添加自定義磁區器
properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG,"com.atgui
gu.kafka.producer.MyPartitioner");
KafkaProducer<String, String> kafkaProducer = new
KafkaProducer<>(properties);
for (int i = 0; i < 5; i++) {
kafkaProducer.send(new ProducerRecord<>("first",
"atguigu " + i), new Callback() {
@Override
public void onCompletion(RecordMetadata metadata,
Exception e) {
if (e == null){
System.out.println(" 主 題 : " +
metadata.topic() + "->" + "磁區:" + metadata.partition()
);
}else {
e.printStackTrace();
}
}
});
}
kafkaProducer.close();
}
}
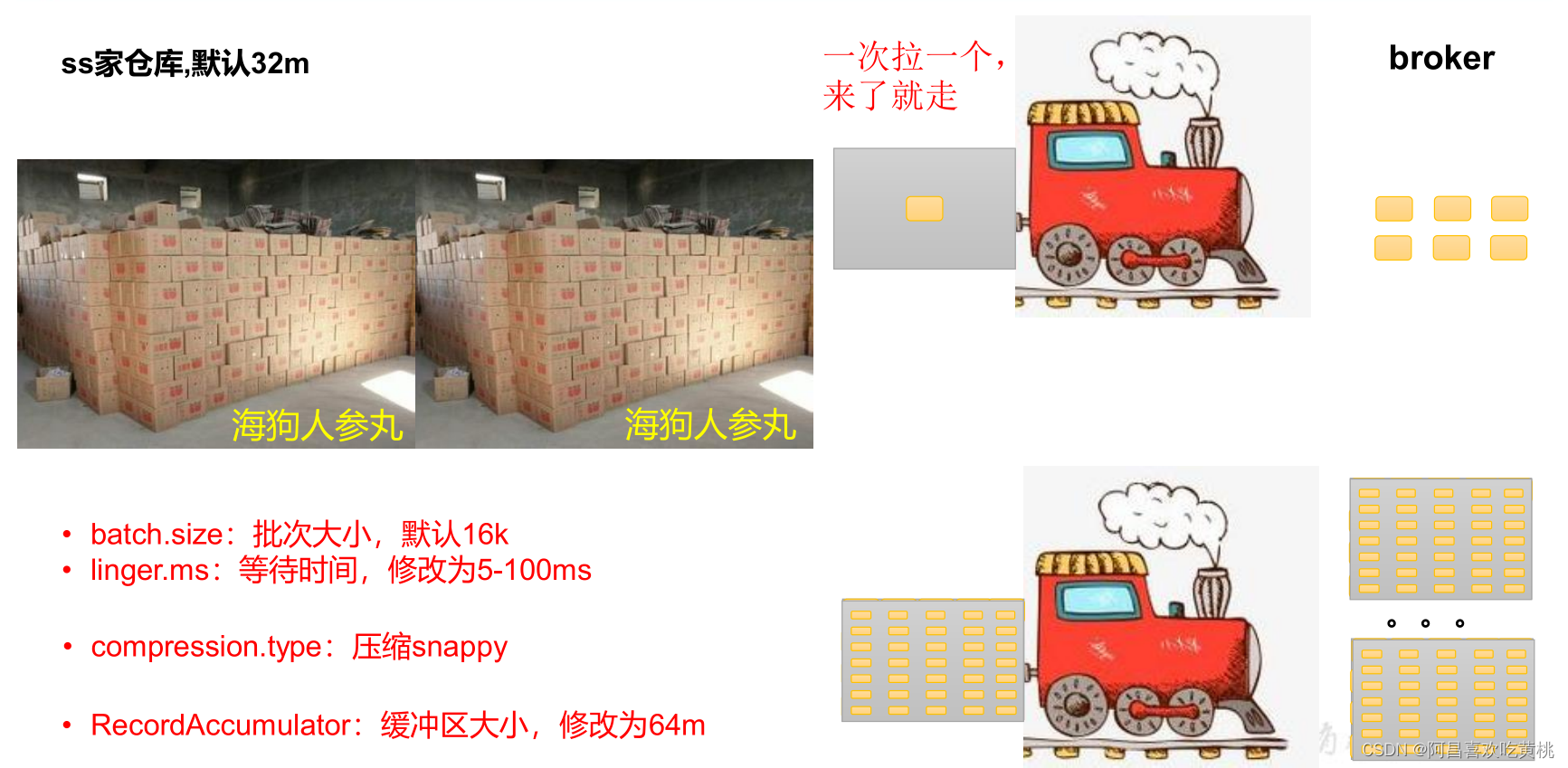
五、生產者 如何提高吞吐量
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
public class CustomProducerParameters {
public static void main(String[] args) throwsInterruptedException {
// 1. 創建 kafka 生產者的配置物件
Properties properties = new Properties();
// 2. 給 kafka 配置物件添加配置資訊:bootstrap.servers
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,
"hadoop102:9092");
// key,value 序列化(必須):key.serializer,value.serializer
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer");
// batch.size:批次大小,默認 16K
properties.put(ProducerConfig.BATCH_SIZE_CONFIG, 16384);
// linger.ms:等待時間,默認 0
properties.put(ProducerConfig.LINGER_MS_CONFIG, 1);
// RecordAccumulator:緩沖區大小,默認 32M:buffer.memory
properties.put(ProducerConfig.BUFFER_MEMORY_CONFIG,
33554432);
// compression.type:壓縮,默認 none,可配置值 gzip、snappy、lz4 和 zstd
properties.put(ProducerConfig.COMPRESSION_TYPE_CONFIG,"snappy");
// 3. 創建 kafka 生產者物件
KafkaProducer<String, String> kafkaProducer = new
KafkaProducer<String, String>(properties);
// 4. 呼叫 send 方法,發送訊息
for (int i = 0; i < 5; i++) {
kafkaProducer.send(new
ProducerRecord<>("first","atguigu " + i));
}
// 5. 關閉資源
kafkaProducer.close();
}
}
六、資料可靠性
回顧發送流程:
ack 應答原理:
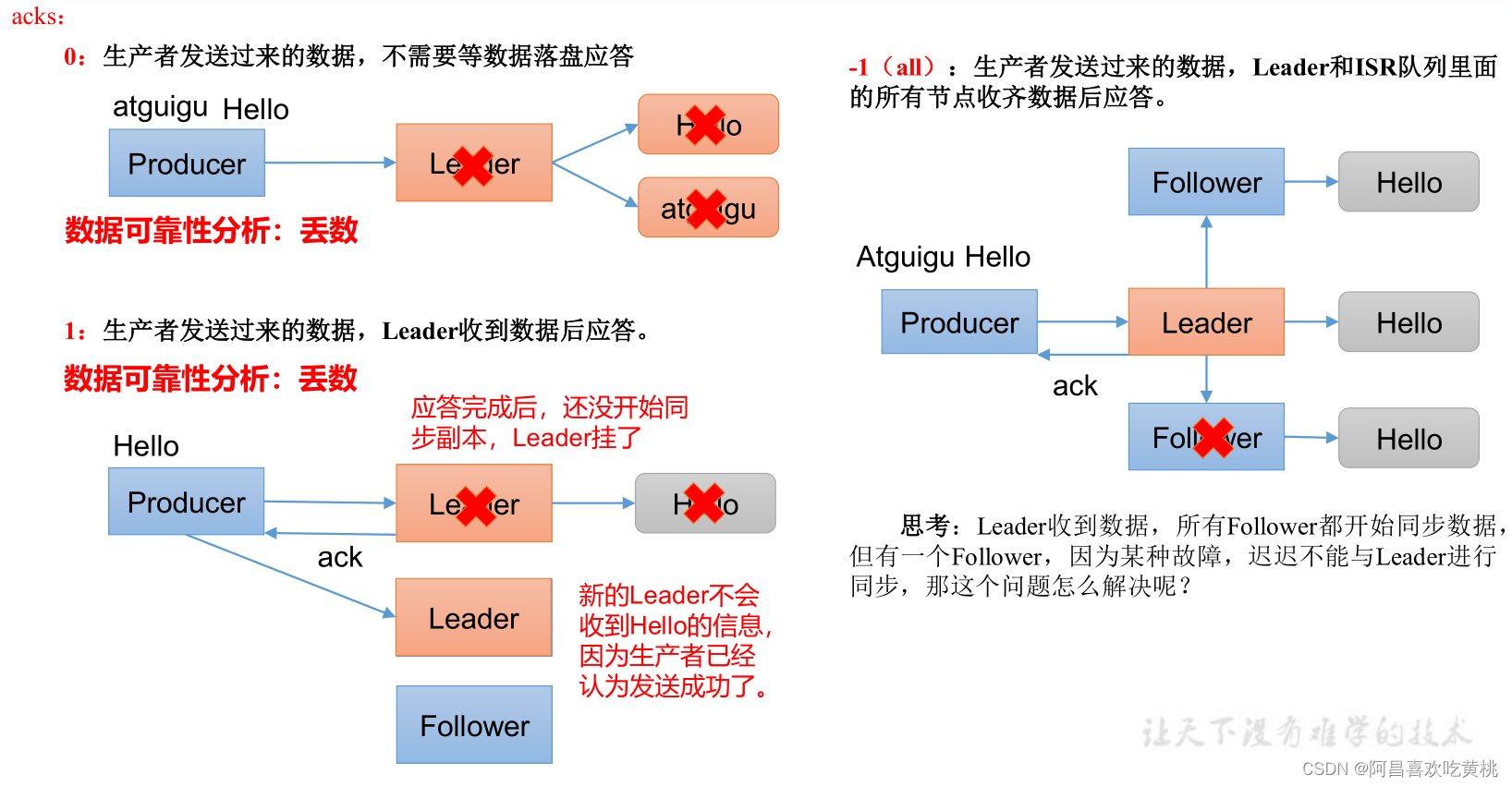
ACK應答級別:
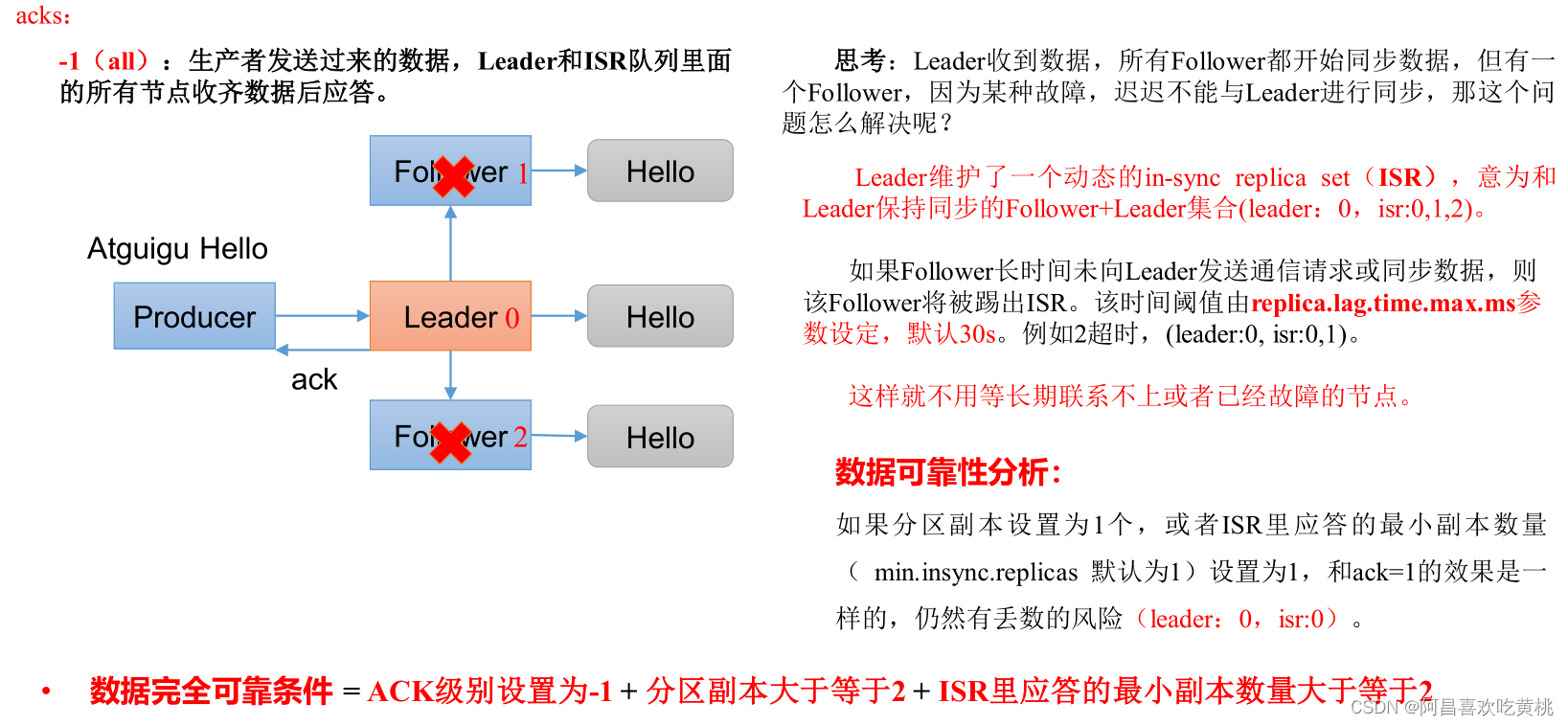
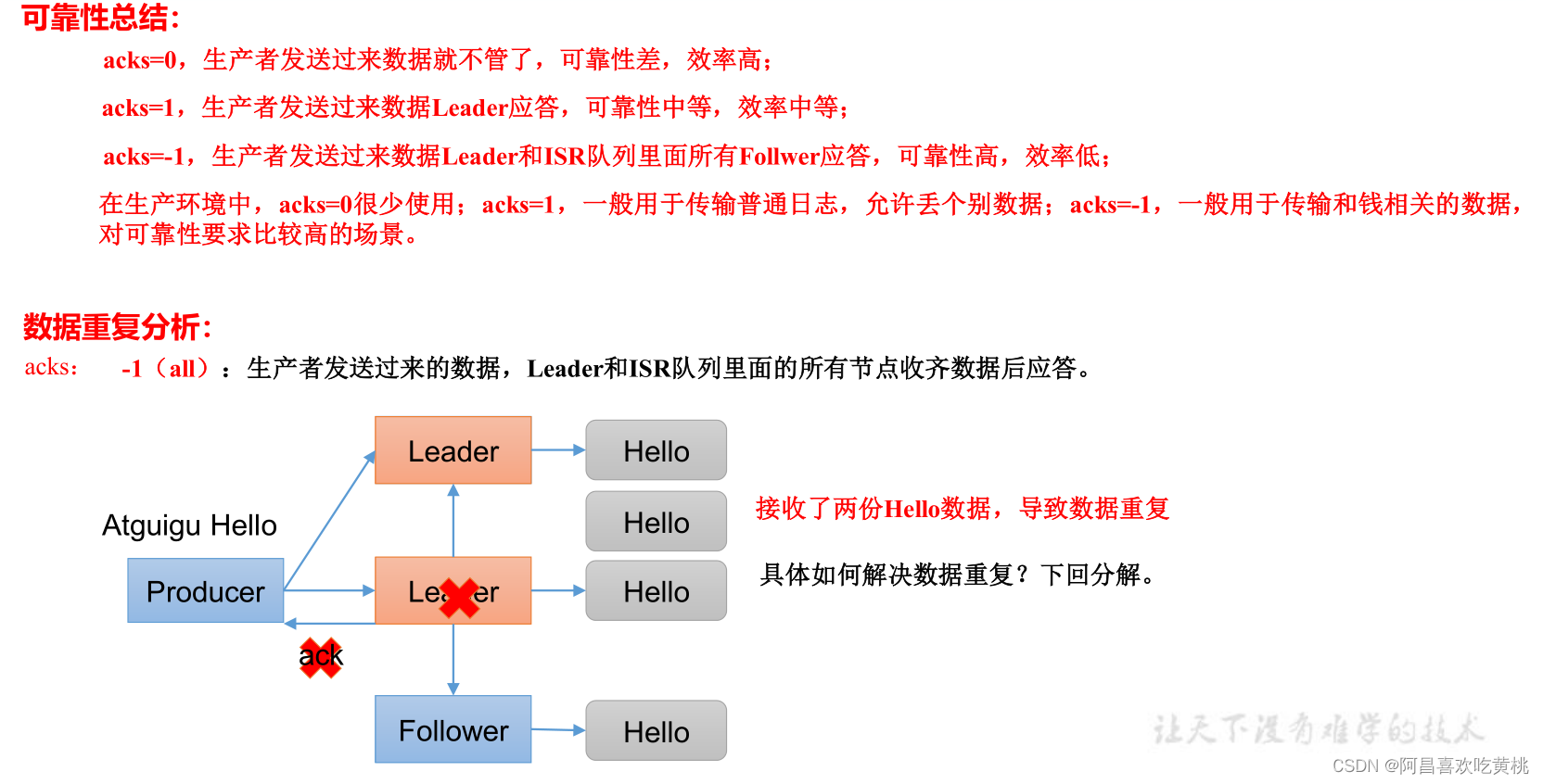
在配置properties中指定使用對應的ack級別

七、資料去重
1、資料傳遞語意

2、冪等性
①冪等性原理
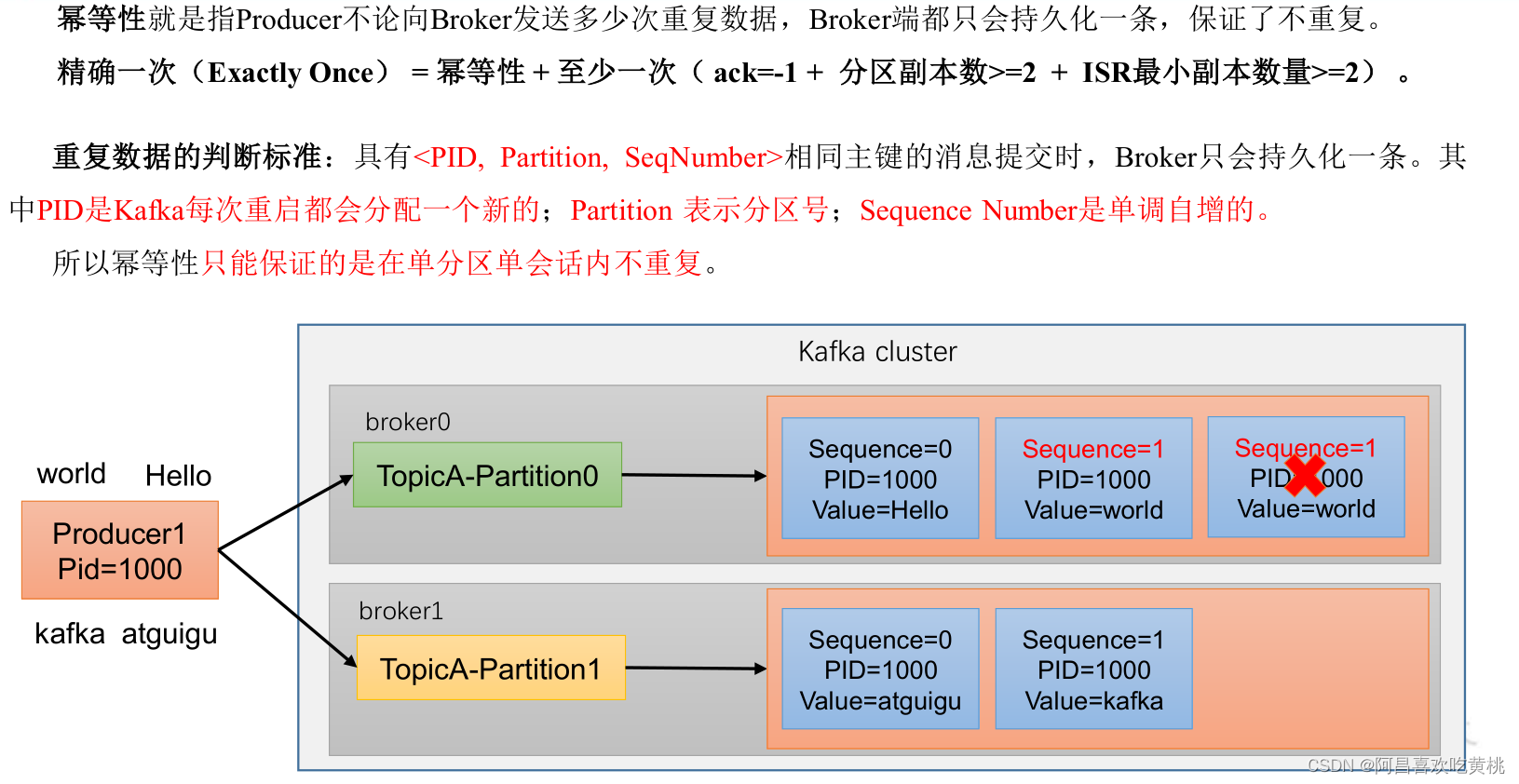
②如何使用冪等性
開啟引數 enable.idempotence 默認為 true,false關閉,
3、生產者事務
①Kafka事務原理
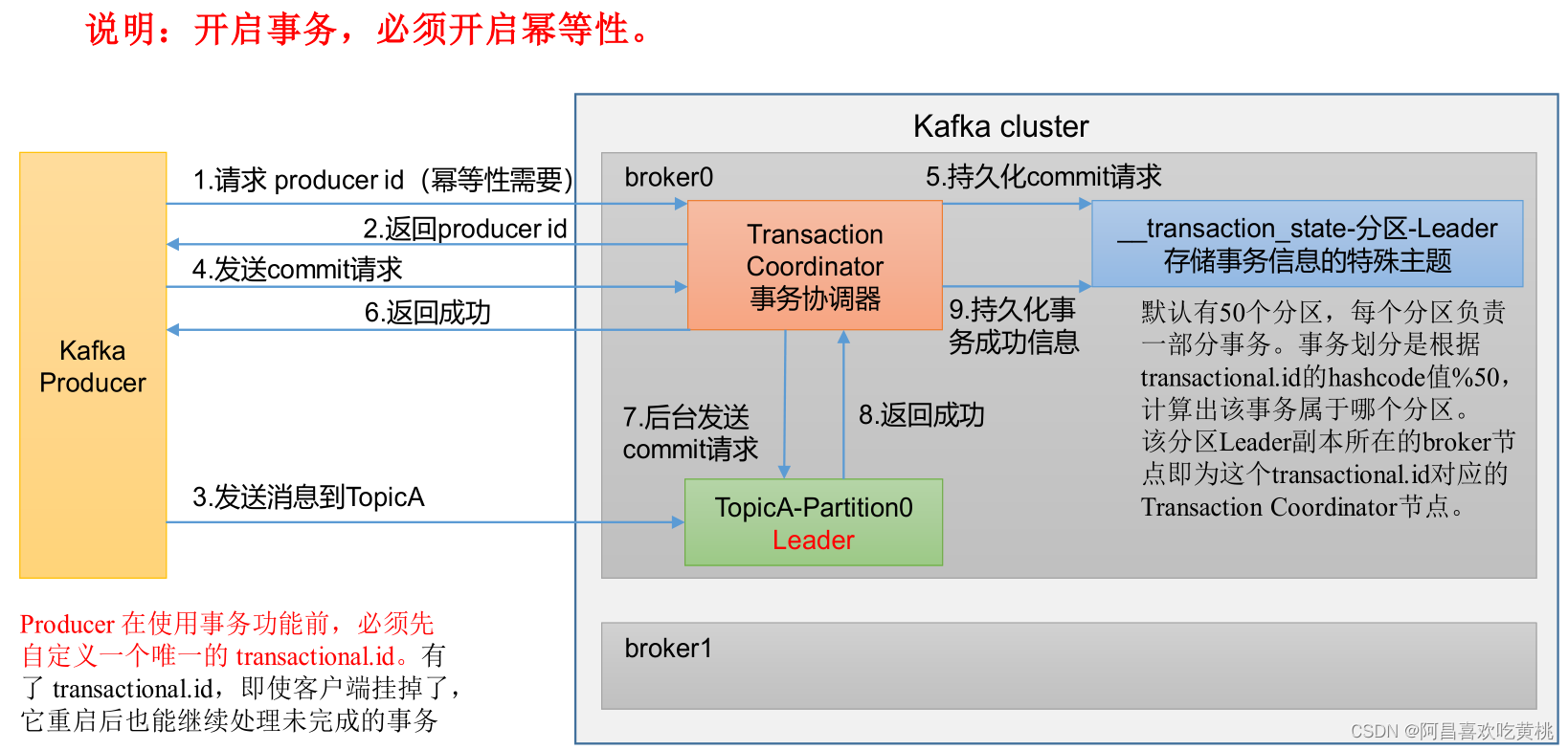
②Kafka的事務一共有如下 5個 API
// 1 初始化事務
void initTransactions();
// 2 開啟事務
void beginTransaction() throws ProducerFencedException;
// 3 在事務內提交已經消費的偏移量(主要用于消費者)
void sendOffsetsToTransaction(Map<TopicPartition, OffsetAndMetadata> offsets, String consumerGroupId) throws ProducerFencedException;
// 4 提交事務
void commitTransaction() throws ProducerFencedException;
// 5 放棄事務(類似于回滾事務的操作)
void abortTransaction() throws ProducerFencedException;
③單個 Producer,使用事務保證訊息的僅一次發送
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
public class CustomProducerTransactions {
public static void main(String[] args) throws InterruptedException {
// 1. 創建 kafka 生產者的配置物件
Properties properties = new Properties();
// 2. 給 kafka 配置物件添加配置資訊
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,
"hadoop102:9092");
// key,value 序列化
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
StringSerializer.class.getName());
// 設定事務 id(必須),事務 id 任意起名
properties.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG,
"transaction_id_0");
// 3. 創建 kafka 生產者物件
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<String, String>(properties);
// 初始化事務
kafkaProducer.initTransactions();
// 開啟事務
kafkaProducer.beginTransaction();
try {
// 4. 呼叫 send 方法,發送訊息
for (int i = 0; i < 5; i++) {
// 發送訊息
kafkaProducer.send(new ProducerRecord<>("first",
"atguigu " + i));
}
// int i = 1 / 0;
// 提交事務
kafkaProducer.commitTransaction();
} catch (Exception e) {
// 終止事務
kafkaProducer.abortTransaction();
} finally {
// 5. 關閉資源
kafkaProducer.close();
}
}
}
八、資料有序
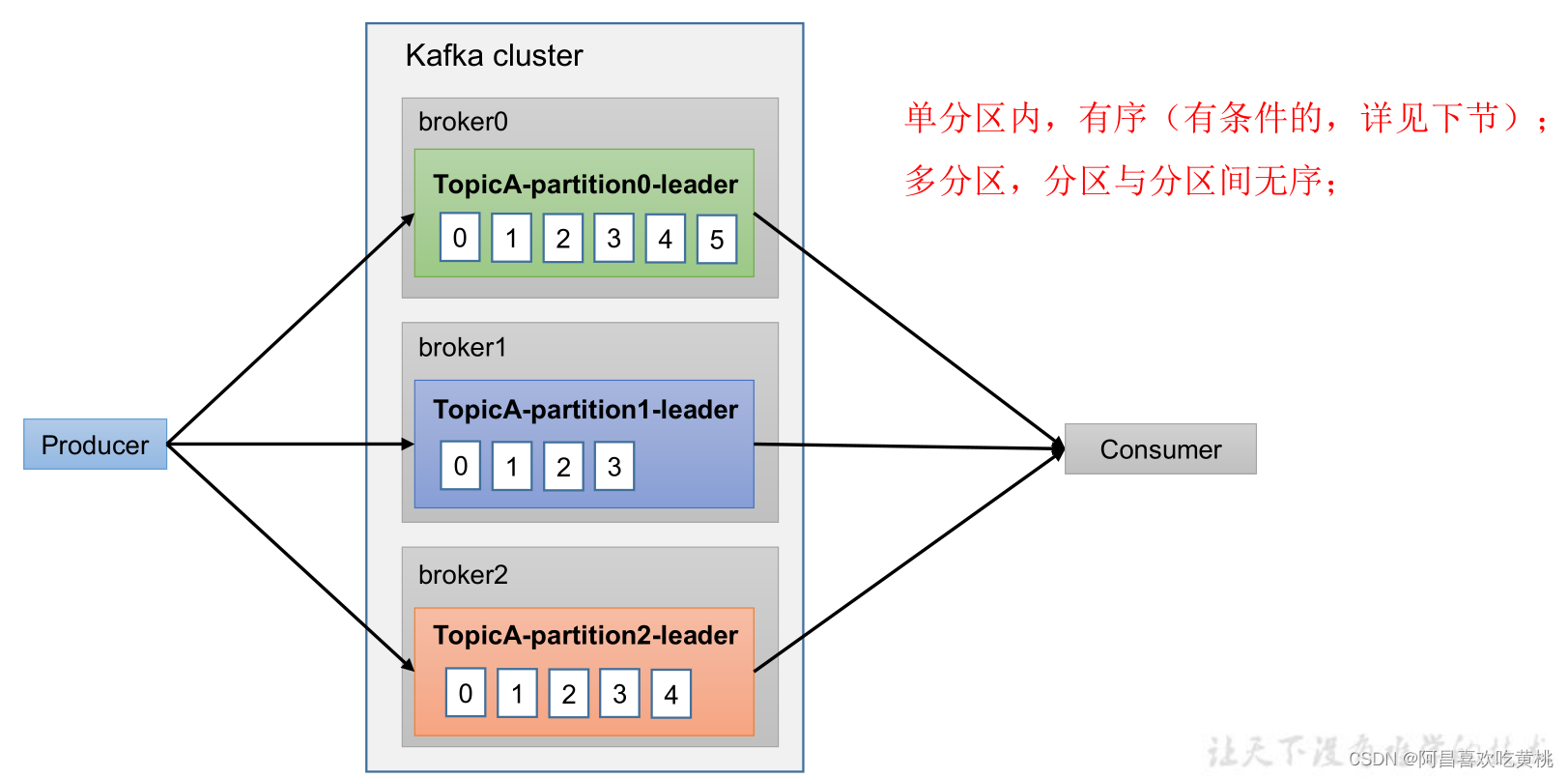
九、資料亂序

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/430273.html
標籤:其他