目錄
0. 相關文章鏈接
1. Hudi 誕生
2. 發展歷史
3. 各版本新特性
4. 新架構:湖倉一體
0. 相關文章鏈接
大資料基礎知識點 文章匯總
1. Hudi 誕生
- Apache Hudi由Uber開發并開源,該專案在2016年開始開發,并于2017年開源,2019年1月進入 Apache 范訓器,且2020年6月稱為Apache 頂級專案,目前最新版本:0.9.0版本,
- Hudi 一開始支持Spark進行資料攝入(批量Batch和流式Streaming),從0.7.0版本開始,逐漸與Flink整合,主要在于Flink SQL 整合,還支持Flink SQL CDC,
2. 發展歷史
- 2015 年:發表了增量處理的核心思想/原則(O'reilly 文章)
- 2016 年:由 Uber 創建并為所有資料庫/關鍵業務提供支持
- 2017 年:由 Uber 開源,并支撐 100PB 資料湖
- 2018 年:吸引大量使用者,并因云計算普及
- 2019 年:成為 ASF 范訓專案,并增加更多平臺組件
- 2020 年:畢業成為 Apache 頂級專案,社區、下載量、采用率增長超過 10 倍
- 2021 年:支持 Uber 500PB 資料湖,SQL DML、Flink 集成、索引、元服務器、快取,
3. 各版本新特性
Hudi 0.5.x 版本時
Apache 頂級專案,支持Spark、Hive、Presto分析引擎
主要以Spark為主,將資料批量和流式寫入Hudi中
Hudi 0.6 版本開始
逐漸添加新特性和功能
Hudi 0.7.0 版本開始
由于Flink 計算引擎成熟穩定,尤其Flink 1.12版本發布
社區開始支持Flink 計算引擎,提供工具類方式
Hudi 0.8.0 版本,支持Flink SQL Client 操作Hudi 表資料
資料入湖
資料查詢
使用SQL方式
Hudi 0.9.0 版本,重構與Flink集成,更好與Flink使用
支持CDC方式,將資料流式入湖,使用Hudi進行管理
流式查詢Hudi表資料,僅僅撰寫SQL即可
Hudi 0.10.0 版本,支持更多資料源
比如支持MySQL資料源
支持Kafka 資料源4. 新架構:湖倉一體
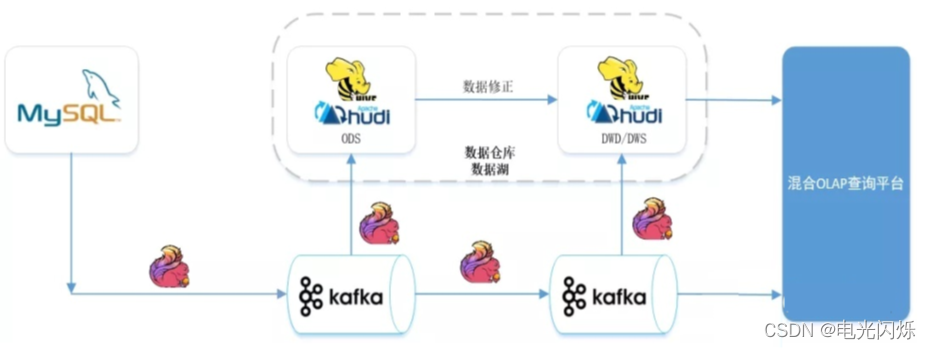
- Hudi 對于Flink友好支持以后,可以使用Flink + Hudi構建實時湖倉一體架構,資料的時效性可以到分鐘級,能很好的滿足業務準實時數倉的需求,
- 通過湖倉一體、流批一體,準實時場景下做到了:資料同源、同計算引擎、同存盤、同計算口徑,
注:Hudi系列博文為通過對Hudi官網學習記錄所寫,其中有加入個人理解,如有不足,請各位讀者諒解???
注:其他相關文章鏈接由此進(包括Hudi在內的各大資料相關博文) -> 大資料基礎知識點 文章匯總
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/430280.html
標籤:其他