目錄
0. 相關文章鏈接
1. 編譯Hudi原始碼
1.1. Maven安裝
1.2. 下載并編譯hudi
2. 安裝HDFS
3. 安裝Spark
4. 在spark-shell中運行hudi程式
主要介紹的Apache原生的Hudi、HDFS、Spark等的集成使用
0. 相關文章鏈接
大資料基礎知識點 文章匯總
1. 編譯Hudi原始碼
雖然對hudi的下載編譯在博主的另一篇博文里有介紹,但這里是系統的介紹Hudi的體驗使用,所以在介紹一遍,
1.1. Maven安裝
將maven的安裝包上傳到centos7服務器上,并解壓,然后配置系統環境變數即可,詳情可以查看博主的另一篇博文:Maven的下載安裝和使用_yang_shibiao的博客-CSDN博客
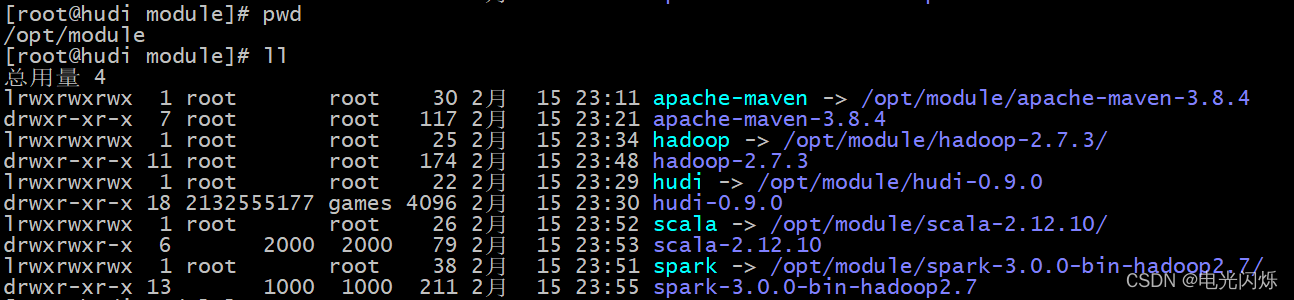
配置好軟連接,完成之后如下圖所示:
修改maven中的本地倉庫和鏡像,如下所示:
<localRepository>/opt/module/apache-maven/repository</localRepository>
<mirrors>
<!-- mirror
| Specifies a repository mirror site to use instead of a given repository. The repository that
| this mirror serves has an ID that matches the mirrorOf element of this mirror. IDs are used
| for inheritance and direct lookup purposes, and must be unique across the set of mirrors.
|
<mirror>
<id>mirrorId</id>
<mirrorOf>repositoryId</mirrorOf>
<name>Human Readable Name for this Mirror.</name>
<url>http://my.repository.com/repo/path</url>
</mirror>
-->
<mirror>
<id>aliyunCentralMaven</id>
<name>aliyun central maven</name>
<url>https://maven.aliyun.com/repository/central/</url>
<mirrorOf>central</mirrorOf>
</mirror>
<mirror>
<id>centralMaven</id>
<name>central maven</name>
<url>http://mvnrepository.com/</url>
<mirrorOf>central</mirrorOf>
</mirror>
</mirrors>修改環境變數:
export MAVEN_HOME=/opt/module/apache-maven
export PATH=$MAVEN_HOME/bin:$PATHsource環境變數,然后查看maven版本如下所示:

1.2. 下載并編譯hudi
- 到Apache 軟體歸檔目錄下載Hudi 0.8原始碼包:http://archive.apache.org/dist/hudi/0.9.0/
- 編譯Hudi原始碼步驟
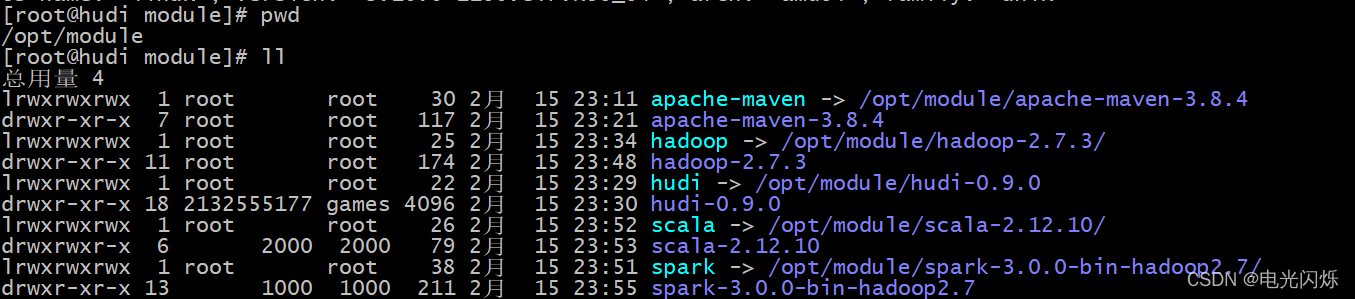
- 上傳原始碼包到 /opt/module 目錄,并解壓配置軟連接:
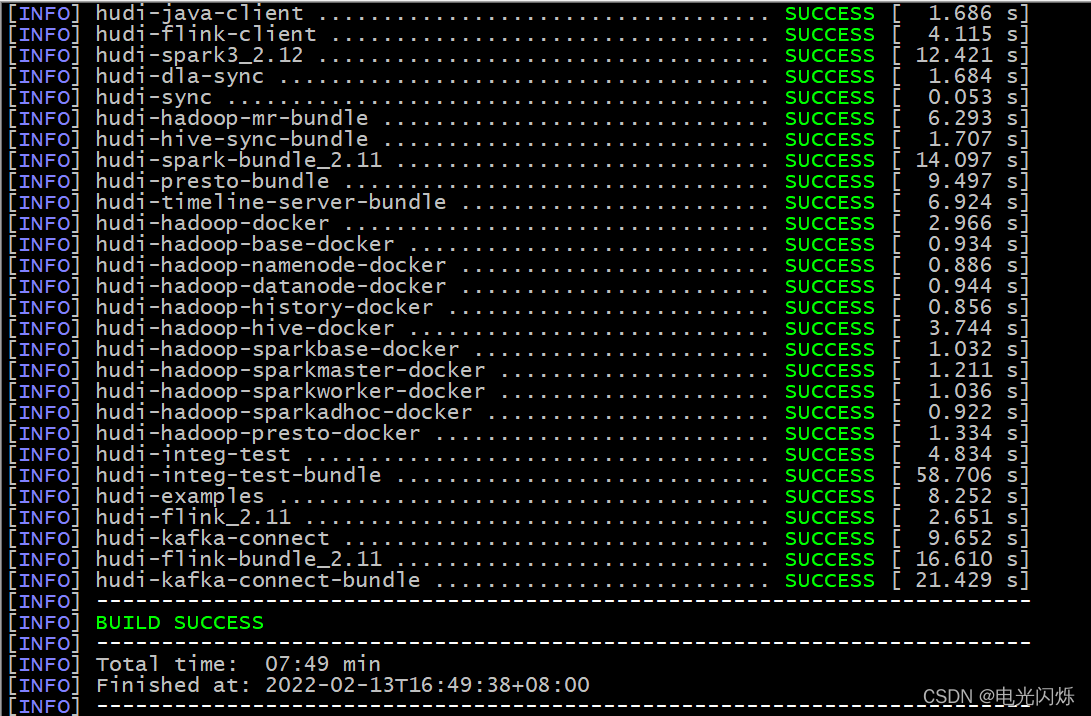
- 執行 mvn clean install -DskipTests -Dscala-2.12 -Dspark3 命令進行編譯,成功后如下圖所示:
- 編譯完成以后,進入$HUDI_HOME/hudi-cli目錄,運行hudi-cli腳本,如果可以運行,說明編譯成功,如下圖所示:
2. 安裝HDFS
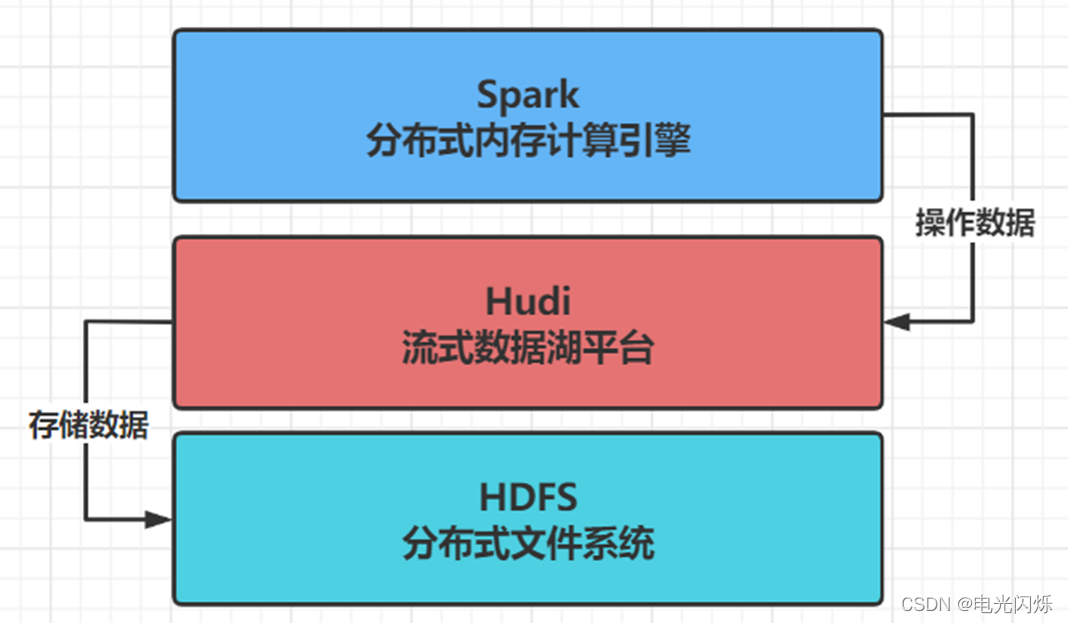
- step1:Hudi 流式資料湖平臺,協助管理資料,借助HDFS檔案系統存盤資料,使用Spark操作資料
- step2:下載 hadoop-2.7.3 安裝包,上傳服務器,解壓,并配置軟連接,如下圖所示:
- step3:配置環境變數(在Hadoop中,bin和sbin目錄下的腳本、etc/hadoop下的組態檔,有很多配置項都會使用到HADOOP_*這些環境變數,如果僅僅是配置了HADOOP_HOME,這些腳本會從HADOOP_HOME下通過追加相應的目錄結構來確定COMMON、HDFS和YARN的類別庫路徑,)

# 在 /etc/profile 檔案下添加如下配置
export HADOOP_HOME=/opt/module/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin- step4:配置hadoop-env.sh
# 在該 HADOOP_HOME/etc/hadoop/hadoop-evn.sh 下修改添加如下配置
export JAVA_HOME=/usr/java/jdk1.8.0_181
export HADOOP_HOME=/opt/module/hadoop- step5:配置core-site.xml,配置Hadoop Common模塊公共屬性,修改HADOOP_HOME/etc/hadoop/core-site.xml檔案為如下所示,并根據配置創建對應的臨時資料目錄,創建命令:mkdir -p /opt/module/hadoop/datas/tmp
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hudi:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop/datas/tmp</value>
</property>
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
</configuration>
- step6:配置 HADOOP_HOME/etc/hadoop/hdfs-site.xml檔案,配置HDFS分布式檔案系統相關屬性,并創建對應的資料目錄,命令:mkdir -p /opt/module/hadoop/datas/dfs/nn , mkdir -p /opt/module/hadoop/datas/dfs/dn
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/module/hadoop/datas/dfs/nn</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/module/hadoop/datas/dfs/dn</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<property>
<name>dfs.datanode.data.dir.perm</name>
<value>750</value>
</property>
</configuration>
- step7:配置HADOOP_HOME/etc/hadoop/slaves,在該配置中添加上配置的域名即可
hudi- step8:格式化HDFS,在第一次啟動HDFS之前,需要先格式HDFS檔案系統,執行如下命令即可
hdfs namenode -format- step9:配置啟動停止腳本,用來啟動或停止HDFS集群
vim hdfs-start.sh
hadoop-daemon.sh start namenode
hadoop-daemon.sh start datanode
================================================
hdfs-stop.sh
hadoop-daemon.sh stop datanode
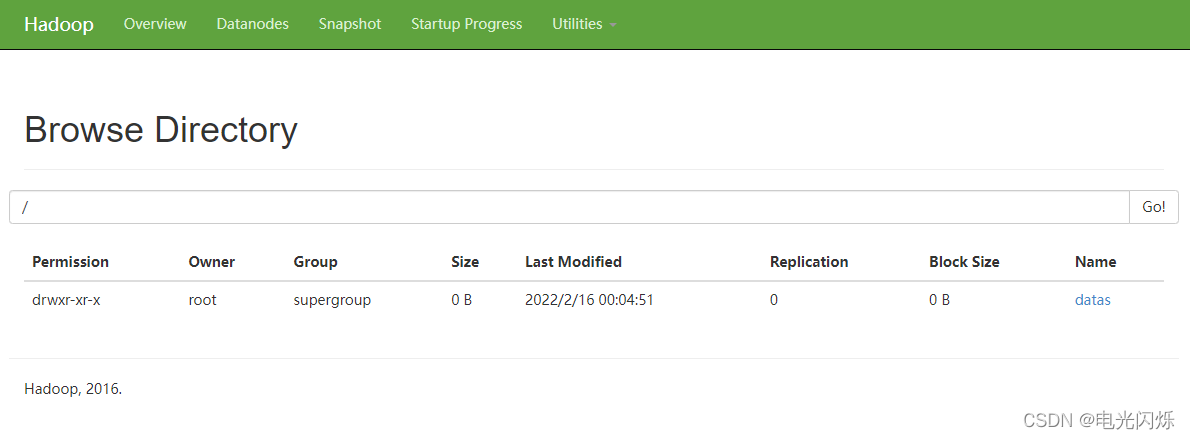
hadoop-daemon.sh stop namenode- step10:查看HDFS的web ui(http://hudi:50070/explorer.html#),如下圖所示:
- step11:HDFS 分布式檔案系統安裝,存盤資料
3. 安裝Spark
- step1:下載安裝包并上傳解壓,如下圖所示:
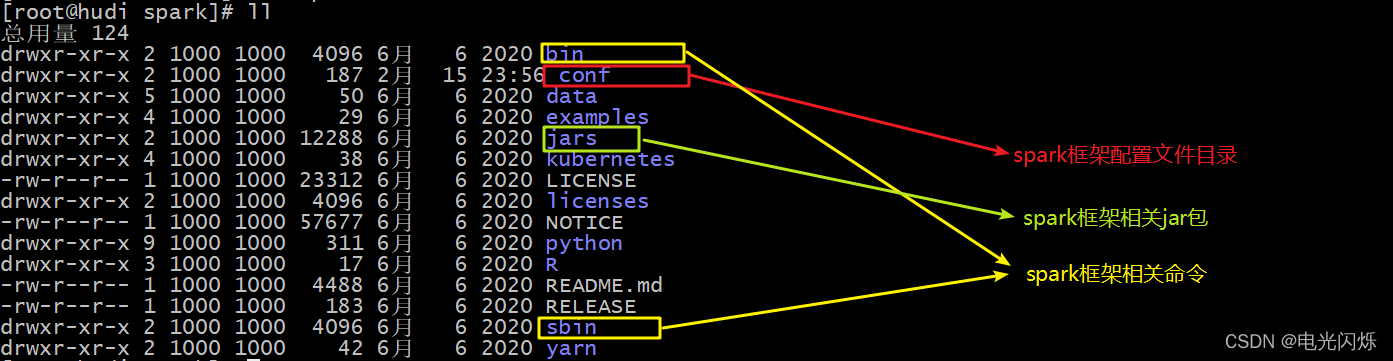
- step2:各個目錄含義:
- step3:安裝scala,下載上傳并解壓scala包,如第一步圖所示,并配置scala的環境變數,驗證如下圖所示:
export SCALA_HOME=/opt/module/scala
export PATH=$PATH:$SCALA_HOME/bin
- step4:修改組態檔,$SPARK_HOME/conf/spark-env.sh,修改增加如下內容:
JAVA_HOME=/usr/java/jdk1.8.0_181
SCALA_HOME=/opt/module/scala
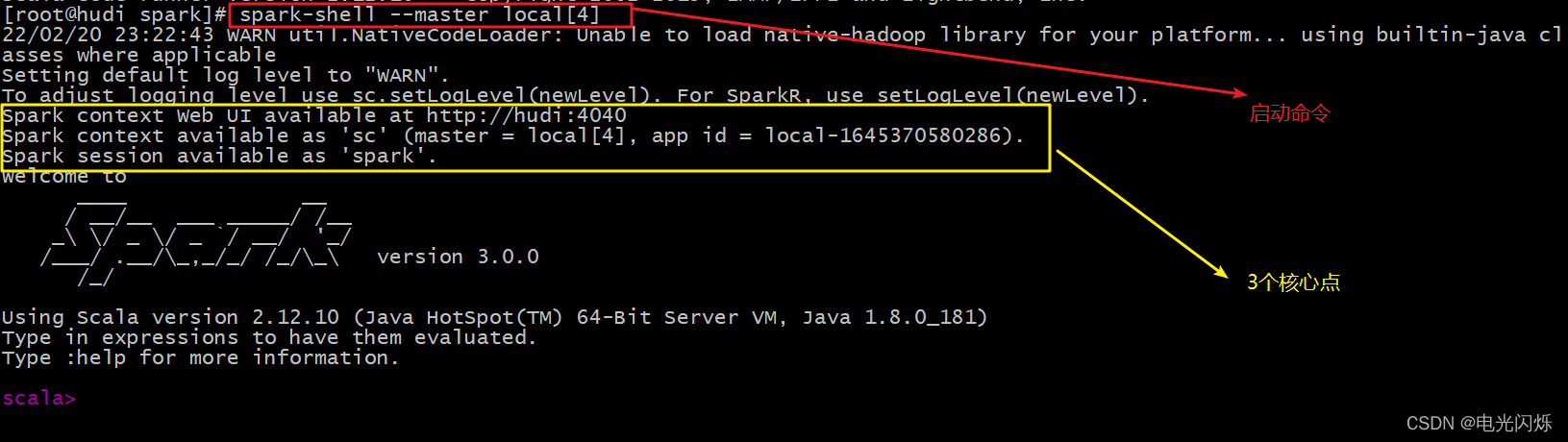
HADOOP_CONF_DIR=/opt/module/hadoop/etc/hadoop- step5:啟動spark-shell,啟動命令(spark-shell --master local[4]),如下圖所示:
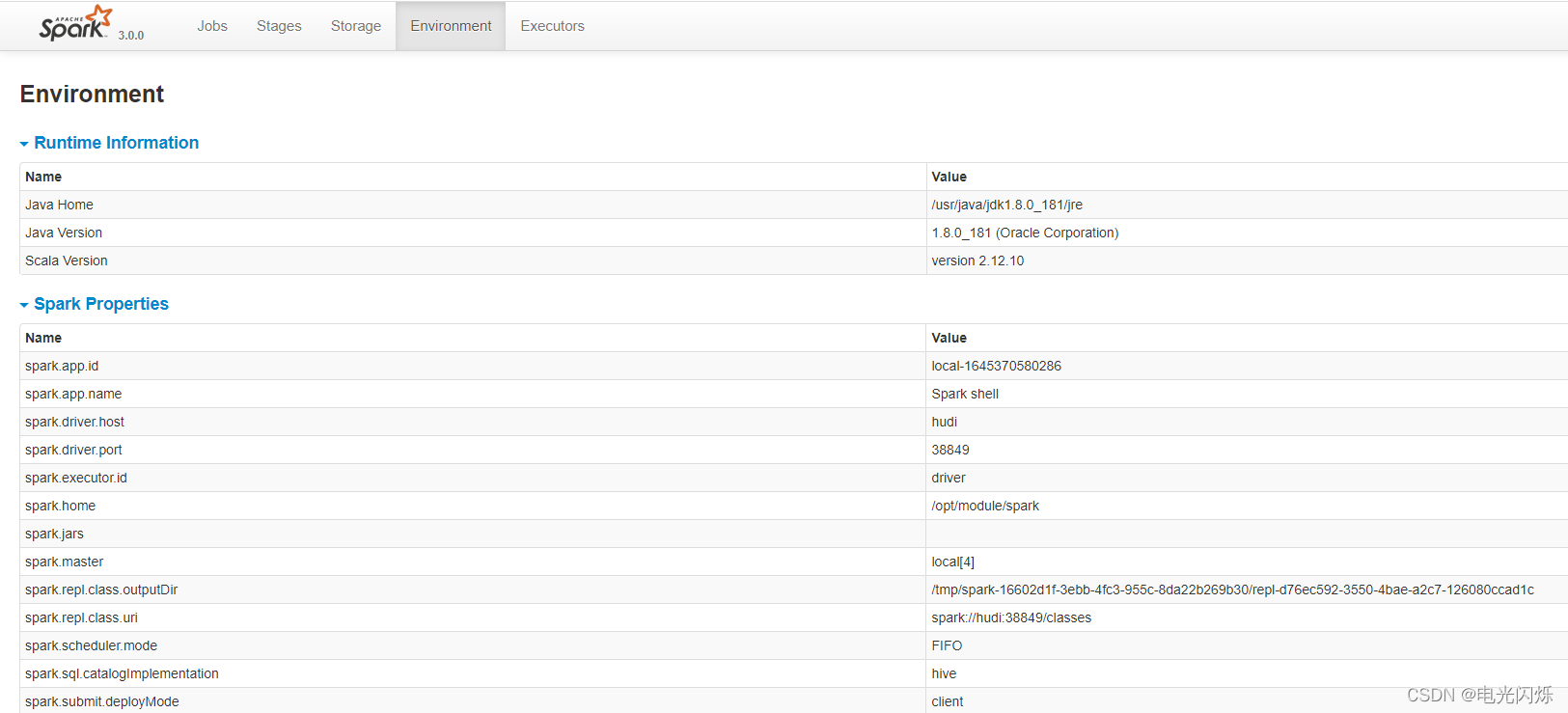
- step6:在web頁面(http://hudi:4040/environment/)查看spark:
- step7:在spark-shell中執行spark的算子,驗證是否能成功運行:
# 上傳檔案到HDFS集群
hdfs dfs -mkdir -p /datas/
hdfs dfs -put /opt/module/spark/README.md /datas
# 在spark-shell中讀取檔案
val datasRDD = sc.textFile("/datas/README.md")
# 查看該檔案的條目數
datasRDD.count
# 獲取第一條資料
datasRDD.first
4. 在spark-shell中運行hudi程式
首先使用spark-shell命令列,以本地模式(LocalMode:--master local[2])方式運行,模擬產生Trip乘車交易資料,將其保存至Hudi表,并且從Hudi表加載資料查詢分析,其中Hudi表資料最后存盤在HDFS分布式檔案系統上,
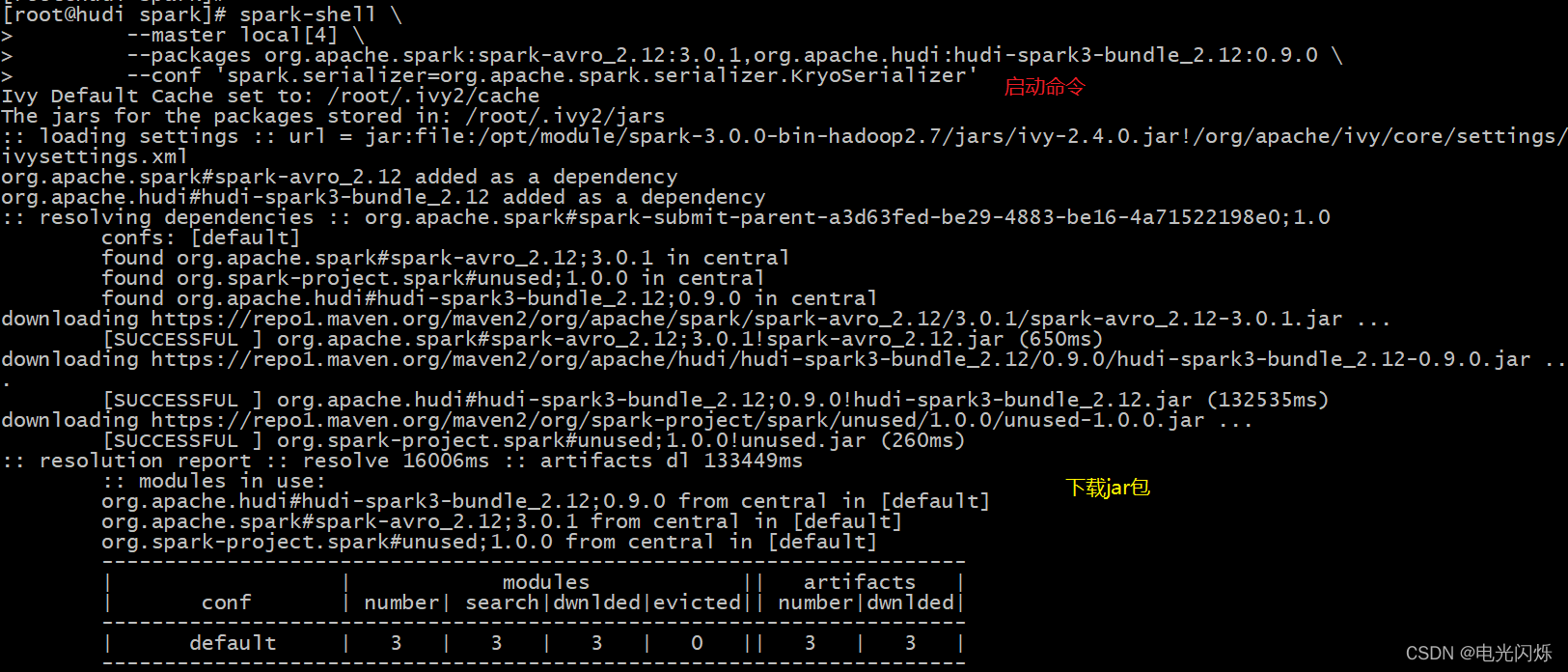
在服務器中執行如下spark-shell命令,會在啟動spark程式時,匯入hudi包,請注意,執行此命令時需要聯網,從遠程倉庫中下載對應的jar包:
spark-shell \
--master local[4] \
--packages org.apache.spark:spark-avro_2.12:3.0.1,org.apache.hudi:hudi-spark3-bundle_2.12:0.9.0 \
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer'
啟動后如下所示:
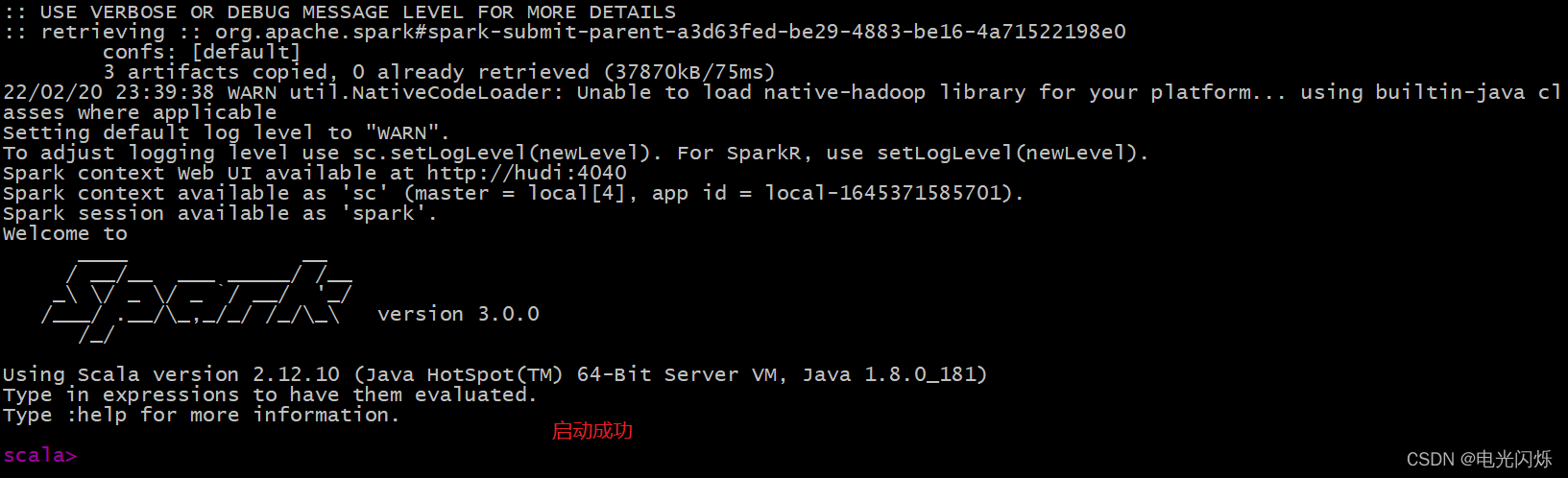
會將jar包下載到root命令下,如下圖所示:
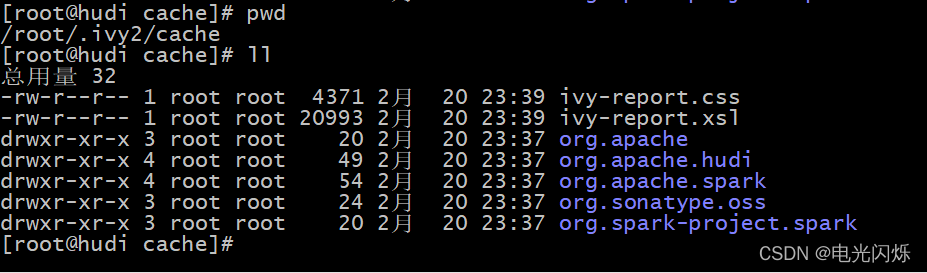
如果服務器不能聯網,可以先將jar包上傳到服務器,然后在通過spark-shell啟動時,通過--jars命令指定jar包,如下所示:
spark-shell \
--master local[4] \
--jars /opt/module/Hudi/packaging/hudi-spark-bundle/target/hudi-spark3-bundle_2.12-0.8.0.jar \
--packages org.apache.spark:spark-avro_2.12:3.0.1,org.apache.hudi:hudi-spark3-bundle_2.12:0.9.0 \
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer'在spark命令列中匯入Hudi的相關包和定義變數(表的名稱和資料存盤路徑):
import org.apache.hudi.QuickstartUtils._
import scala.collection.JavaConversions._
import org.apache.spark.sql.SaveMode._
import org.apache.hudi.DataSourceReadOptions._
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
val tableName = "hudi_trips_cow"
val basePath = "hdfs://hudi:8020/datas/hudi-warehouse/hudi_trips_cow"
val dataGen = new DataGenerator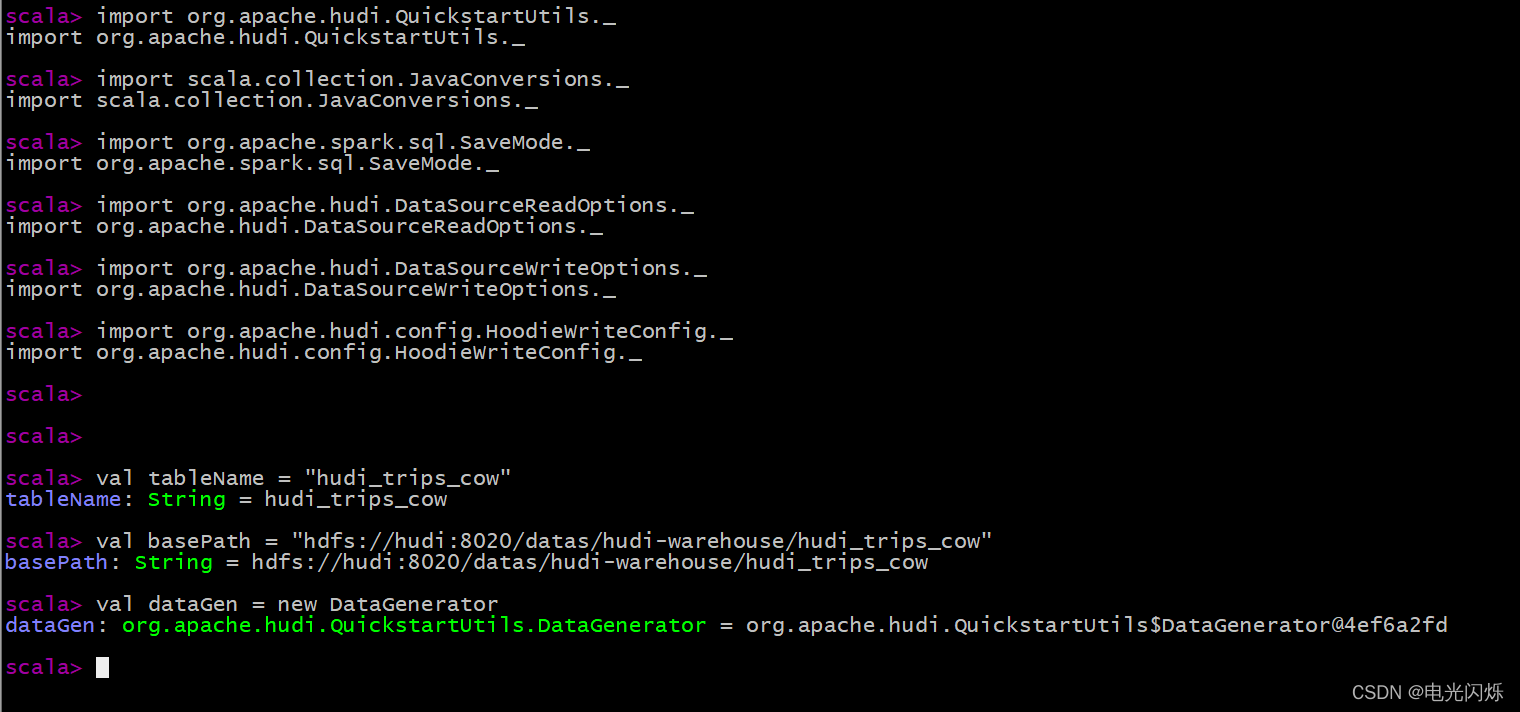
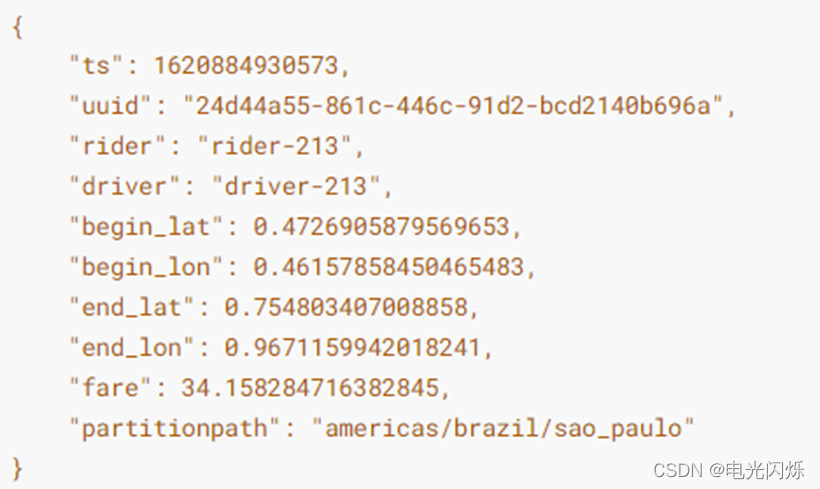
構建DataGenerator物件,用于模擬生成Trip乘車資料(10條json資料):
val inserts = convertToStringList(dataGen.generateInserts(10))
將模擬資料List轉換為DataFrame資料集:
val df = spark.read.json(spark.sparkContext.parallelize(inserts, 2))
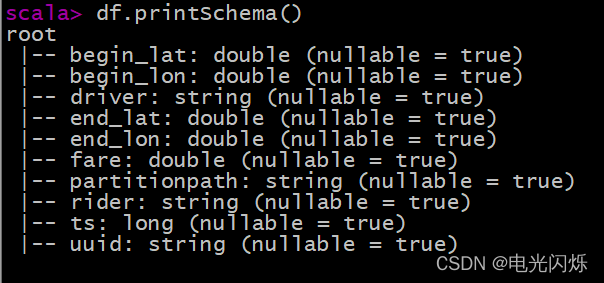
查看轉換后DataFrame資料集的Schema資訊:
選擇相關欄位,查看模擬樣本資料:
df.select("rider", "begin_lat", "begin_lon", "driver", "fare", "uuid", "ts").show(10, truncate=false)
將模擬產生Trip資料,保存到Hudi表中,由于Hudi誕生時基于Spark框架,所以SparkSQL支持Hudi資料源,直接通過format指定資料源Source,設定相關屬性保存資料即可,
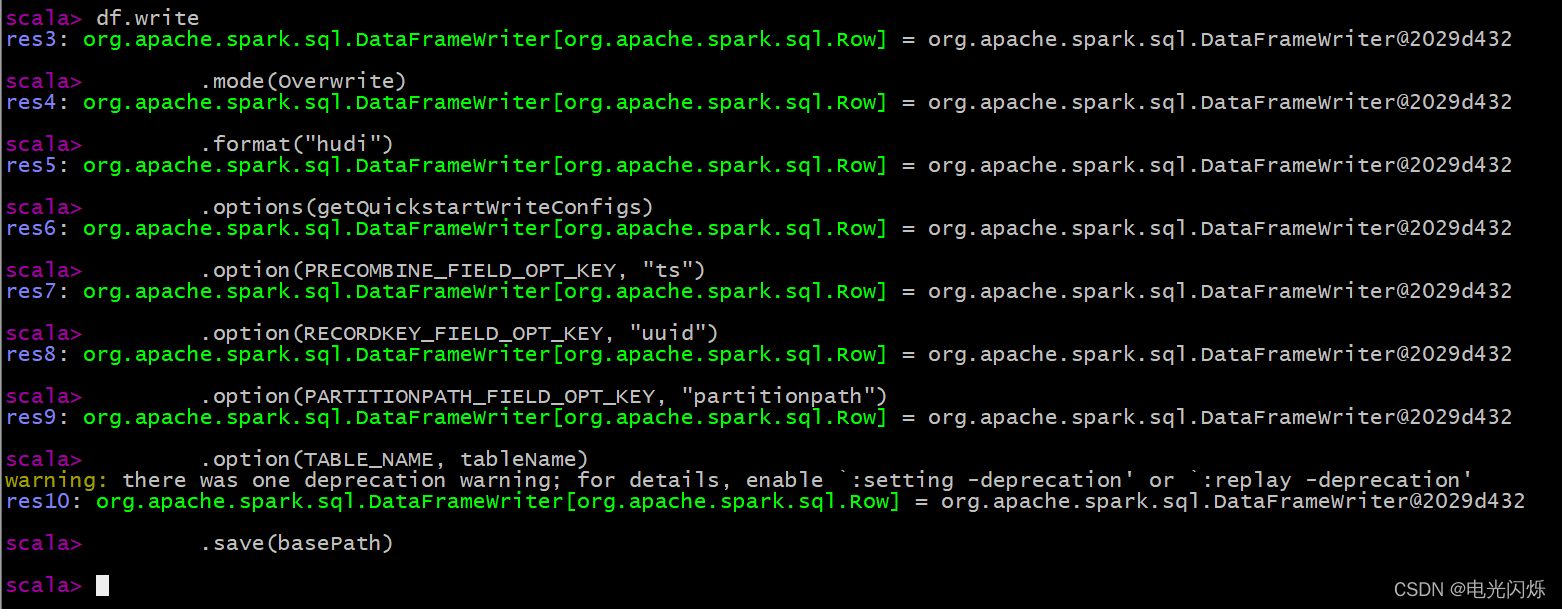
df.write
.mode(Overwrite)
.format("hudi")
.options(getQuickstartWriteConfigs)
.option(PRECOMBINE_FIELD_OPT_KEY, "ts")
.option(RECORDKEY_FIELD_OPT_KEY, "uuid")
.option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath")
.option(TABLE_NAME, tableName)
.save(basePath)
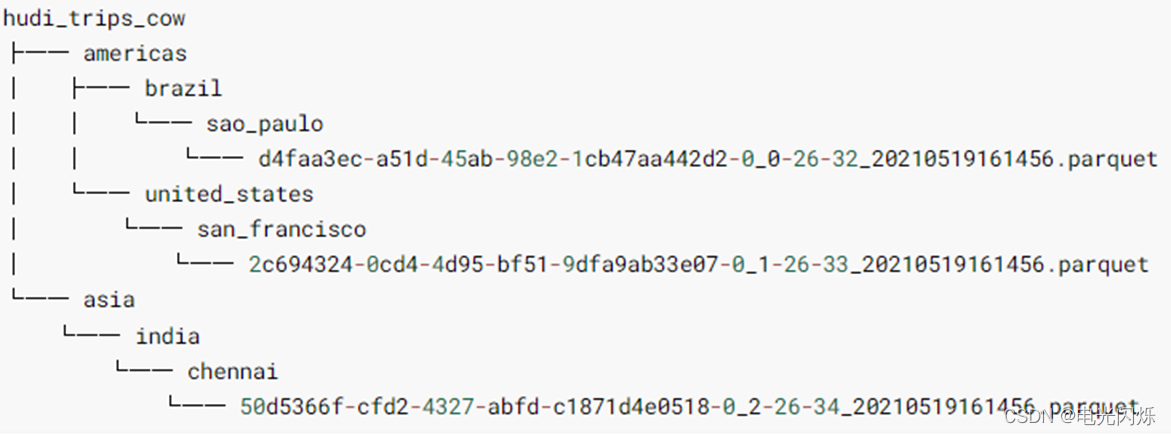
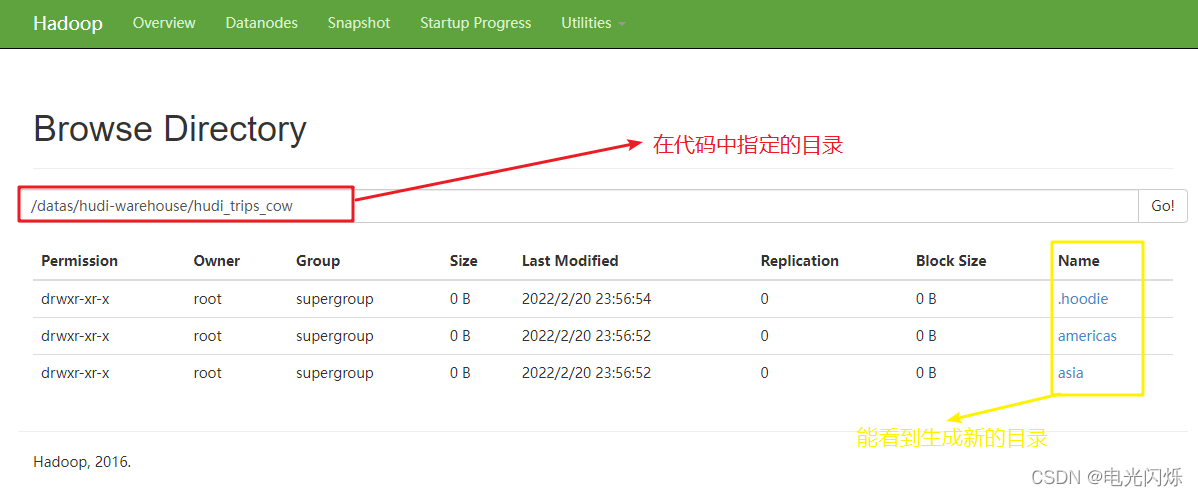
資料保存成功以后,查看HDFS檔案系統目錄:/datas/hudi-warehouse/hudi_trips_cow,結構如下,并且可以發現Hudi表資料存盤在HDFS上,以PARQUET列式方式存盤的:
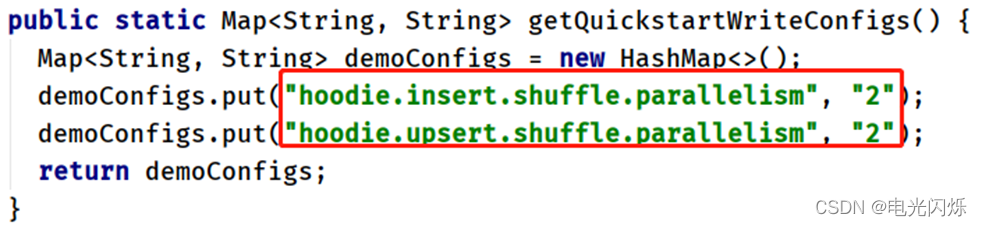
引數:getQuickstartWriteConfigs,設定寫入/更新資料至Hudi時,Shuffle時磁區數目:
引數:PRECOMBINE_FIELD_OPT_KEY,資料合并時,依據主鍵欄位

引數:RECORDKEY_FIELD_OPT_KEY,每條記錄的唯一id,支持多個欄位

引數:PARTITIONPATH_FIELD_OPT_KEY,用于存放資料的磁區欄位

從Hudi表中讀取資料,同樣采用SparkSQL外部資料源加載資料方式,指定format資料源和相關引數options:
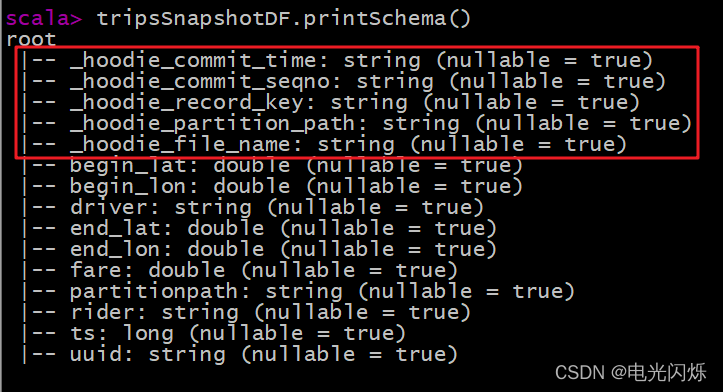
val tripsSnapshotDF = spark.read.format("hudi").load(basePath + "/*/*/*/*")
其中指定Hudi表資料存盤路徑即可,采用正則Regex匹配方式,由于保存Hudi表屬于磁區表,并且為三級磁區(相當于Hive中表指定三個磁區欄位),使用運算式:/*/*/*/* 加載所有資料:
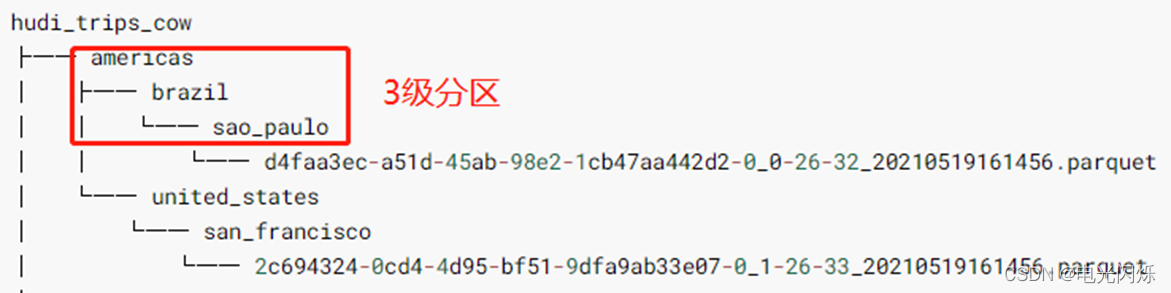
列印獲取Hudi表資料的Schema資訊(回發現比原先保存到Hudi表中資料多5個欄位,這些欄位屬于Hudi管理資料時使用的相關欄位):
將獲取Hudi表資料DataFrame注冊為臨時視圖,采用SQL方式依據業務查詢分析資料:
tripsSnapshotDF.createOrReplaceTempView("hudi_trips_snapshot")查詢業務一:乘車費用 大于 20 資訊資料
spark.sql("select fare, begin_lon, begin_lat, ts from hudi_trips_snapshot where fare > 20.0").show()
查詢業務二:選取欄位查詢資料
spark.sql("select _hoodie_commit_time, _hoodie_record_key, _hoodie_partition_path, rider, driver, fare from hudi_trips_snapshot").show()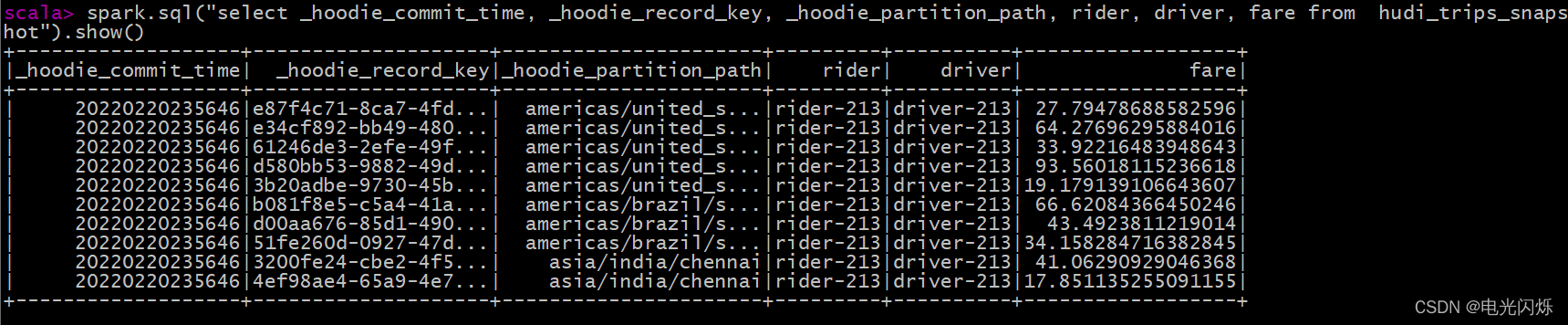
注:Hudi系列博文為通過對Hudi官網學習記錄所寫,其中有加入個人理解,如有不足,請各位讀者諒解???
注:其他相關文章鏈接由此進(包括Hudi在內的各大資料相關博文) -> 大資料基礎知識點 文章匯總
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/430283.html
標籤:其他
下一篇:HiveSql抽樣