本文主要介紹Kafka架構、高性能、高可用以及mac本地安裝kafka,本文參考網上材料和kafka書籍,學習總結,分享出來希望能幫到大家,如有問題及時指出,
一、什么是Kafka?
Kafka是一個訊息佇列,把訊息放到佇列里邊的叫生產者,從佇列里邊消費的叫消費者,Kafka雖然是基于磁盤做的資料存盤,但卻具有高性能、高吞吐、低延時、可持久化、可水平擴展、支持流資料處理等特點,
訊息佇列(Message Queue)是一種行程間通信或同一行程的不同執行緒間的通信方式,主要解決應用耦合、異步訊息、流量削鋒等問題,實作高性能、高可用、可伸縮和最終一致性架構,是大型分布式系統不可缺少的中間件,訊息發布者只管把訊息發布到 MQ 中而不用管誰來取,訊息使用者只管從 MQ 中取訊息而不管是誰發布的,這樣發布者和使用者都不用知道對方的存在,

Kafka的特性
Kafka是一種分布式的,基于發布/訂閱的訊息系統,主要特性如下:
| 特性 | 分布式 | 高性能 | 持久性和擴展性 |
|---|---|---|---|
| 描述 | 多磁區 | 高吞吐量 | 資料可持久化 |
| 多副本 | 低延遲 | 容錯性 | |
| 多訂閱者 | 高并發 | 支持水平在線擴展 | |
| 基于ZooKeeper調度 | 時間復雜度為O(1) | 訊息自動平衡 |
二、Kafka的使用場景
(1)日志收集:一個公司可以用Kafka可以收集各種服務的log,通過kafka以統一介面服務的方式開放給各種consumer,例如hadoop、Hbase、Solr等,
(2)訊息系統:解耦、冗余存盤、流量削峰、快取資料、異步處理等,
(3)用戶活動跟蹤:Kafka經常被用來記錄web用戶或者app用戶的各種活動,如瀏覽網頁、搜索、點擊等活動,這些活動資訊被各個服務器發布到kafka的topic中,然后訂閱者通過訂閱這些topic來做實時的監控分析,或者裝載到hadoop、資料倉庫中做離線分析和挖掘,
(4)運營指標:Kafka也經常用來記錄運營監控資料,包括收集各種分布式應用的資料,生產各種操作的集中反饋,比如報警和報告,
(5)流式處理:完整的流處理庫,視窗連接、變換、聚合和spark streaming、storm、flink配合使用,
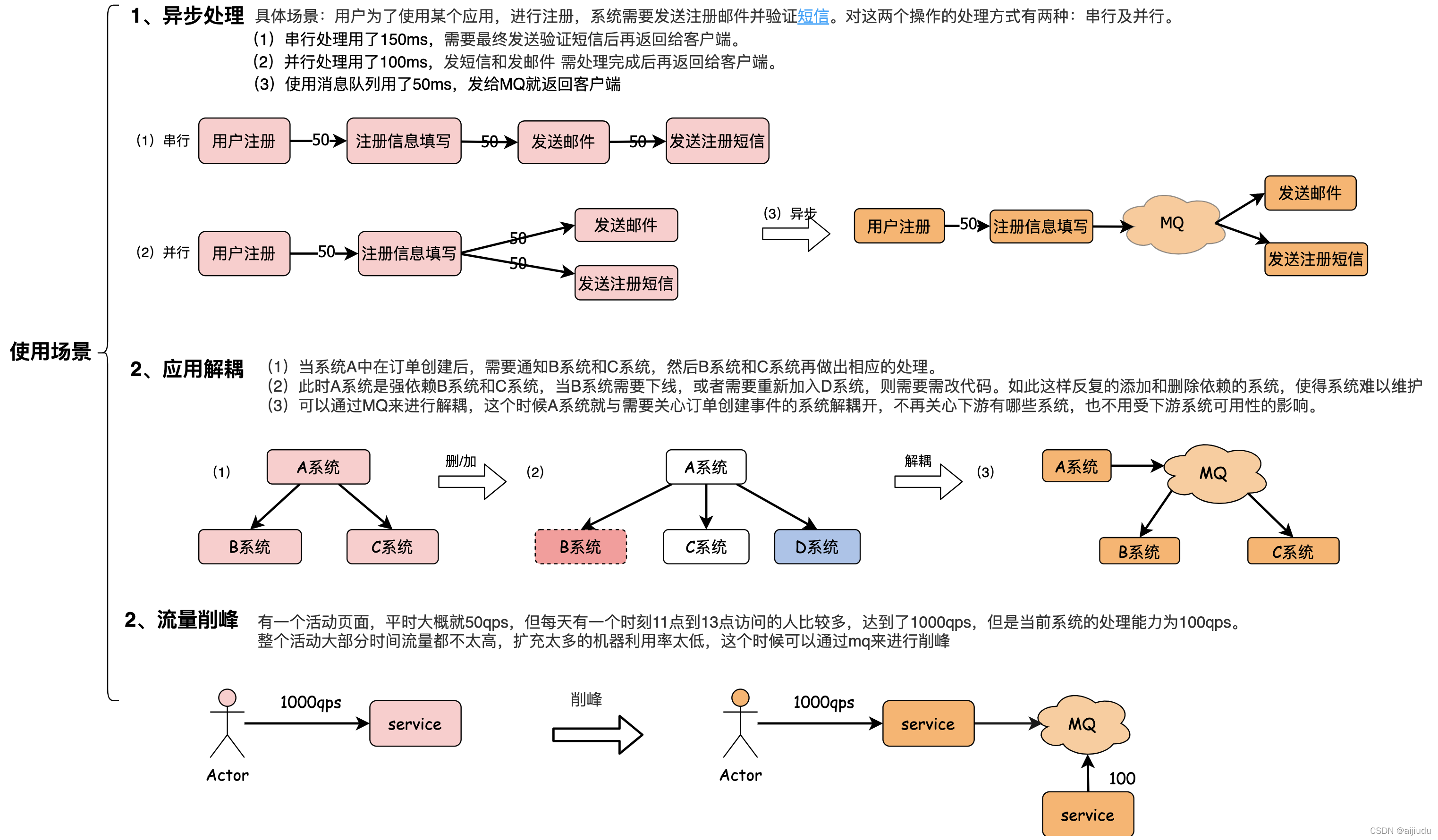
訊息佇列(系統)的基本使用場景:
三、kafka系統架構
Kafka系統架構
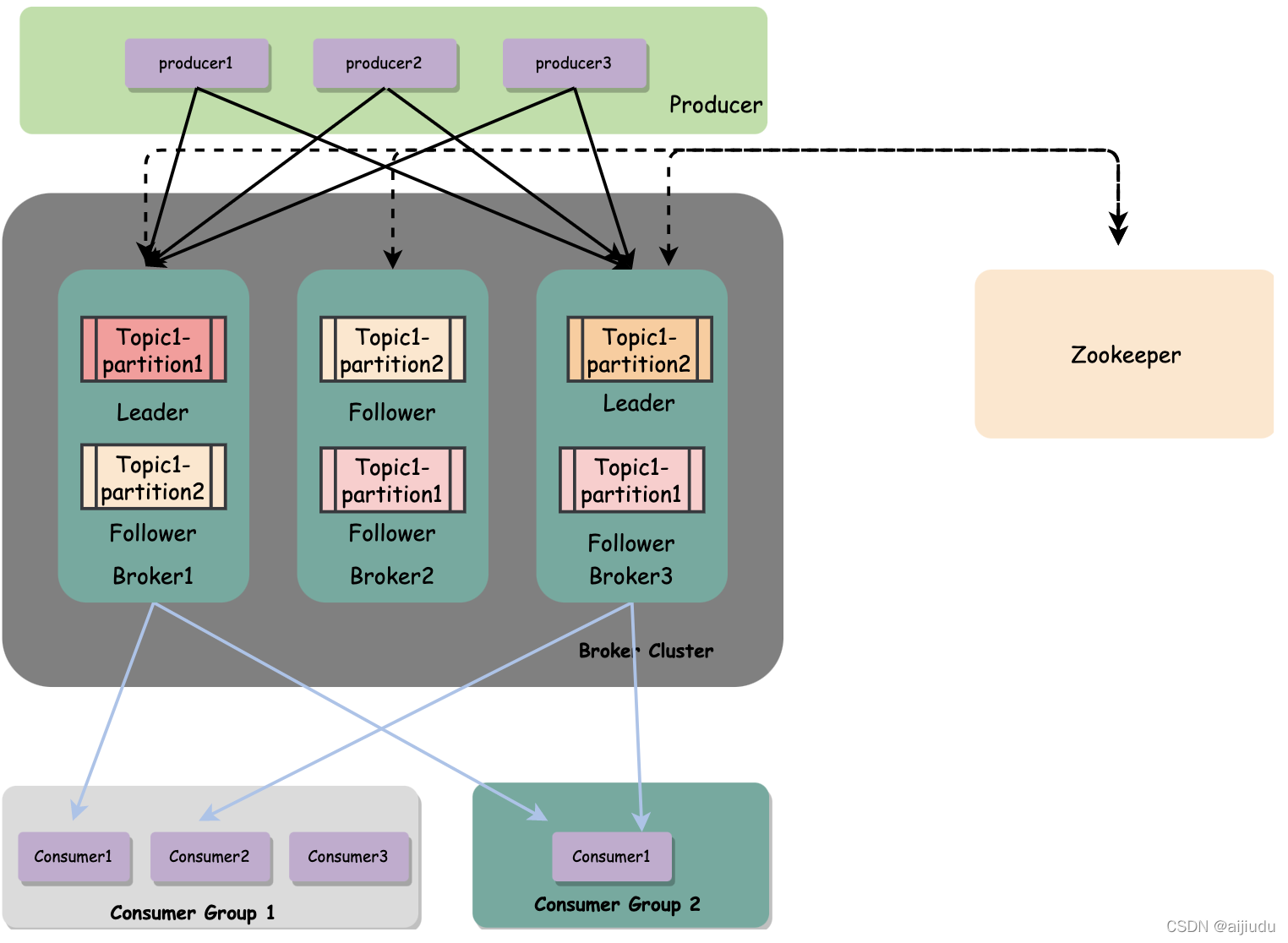
Producer生產者/Consumer消費者:Kafka是一個訊息佇列,把訊息放到佇列里邊的叫生產者,從佇列里邊消費的叫消費者,
topic:一個訊息中間件,佇列不單單只有一個,我們往往會有多個佇列,而我們生產者和消費者就得知道:把資料丟給哪個佇列,從哪個佇列訊息,我們需要給佇列取名字,叫做topic(相當于資料庫里邊表的概念),給佇列取了名字以后,生產者就知道往哪個佇列丟資料了,消費者也知道往哪個佇列拿資料了,我們可以有多個生產者往同一個佇列(topic)丟資料,多個消費者往同一個佇列(topic)拿資料
Partition:為了提高一個佇列(topic)的吞吐量,Kafka會把topic進行磁區(Partition),
Topic & Partition
Topic在邏輯上可以被認為是一個Queue,Kafka中每條訊息都必須指定一個Topic,一個Topic中的訊息可以分布在集群中的多個Broker中,Consumer根據訂閱的Topic到對應的Broker上去拉取訊息,為了提升整個集群的吞吐量,物理上一個Topic可以分成多個Partition,每個Partition在磁盤上對應一個檔案夾,該檔案夾下存放了這個Partition的所有訊息檔案和索引檔案,

Broker:一臺Kafka服務器叫做Broker,Kafka集群就是多臺Kafka服務器,一個topic會分為多個partition,實際上partition會分布在不同的broker中,
總結:生成者往topic丟資料,實際上資料會再partition中,partition分布在不同的Broker(服務器)上,
備份:分布式肯定會帶來問題:“萬一其中一臺broker(Kafka服務器)出現網路抖動或者掛了,怎么辦?”資料存在不同的partition上,那kafka就把這些partition做備份,備份散落在不同的broker上,備份磁區僅僅用作于備份,不做讀寫,如果某個Broker掛了,那就會選舉出其他Broker的partition來作為主磁區,這就實作了高可用,
Consumer Group:消費者實際上也是從partition中取,下面圖的情況,是一個消費者消費兩個磁區的資料,多個消費者可以組成一個消費者組,消費組1有三個消費者,因為只有兩個partition,所以一個空閑,消費組2只有一個消費者,就要消費兩個partition,無論是新增的消費者組還是原本的消費者組,都能消費topic的全部資料,
offset:Kafka就是用offset來表示消費者的消費進度到哪了,每個消費者會都有自己的offset,說白了offset就是表示消費者的消費進度,
這里要注意,因為Kafka讀取訊息的時間復雜度為O(1),即與檔案大小無關,所以這里洗掉過期檔案與提高Kafka性能無關,另外,Kafka會為每一個Consumer Group保留一些metadata資訊(當前消費的訊息的位置,即offset),這個offset由Consumer控制,Consumer會在消費完一條訊息后遞增該offset,當然,Consumer也可將offset設成一個較小的值,重新消費一些訊息,因為offet由Consumer控制,所以Kafka Broker是無狀態的,它不需要標記訊息是否被消費過,也不需要通過Broker去保證同一個Consumer Group只有一個Consumer能消費某一條訊息,因此也就不需要鎖機制,從而保證了Kafka的高吞吐率,
四、Kafka高性能
Producer生產訊息,以Partition的維度,按照一定的路由策略,提交訊息到Broker集群中各Partition的Leader節點,Consumer以Partition的維度,從Broker中的Leader節點拉取訊息并消費訊息,
Producer生產訊息會涉及大量的訊息網路傳輸,如果Producer每生產一個訊息就發送到Broker會造成大量的網路消耗,嚴重影響到Kafka的性能,為了解決這個問題,Kafka使用了批量發送的方式, Broker在持久化訊息、讀取訊息的時候,如果采用傳統的IO讀寫方式,會嚴重影響Kafka的性能,為了解決這個問題,Kafka采用了順序寫+零拷貝的方式,
下面分別從批量發送訊息、持久化訊息、零拷貝三個角度介紹Kafka如何提高性能,
1 批量發送訊息
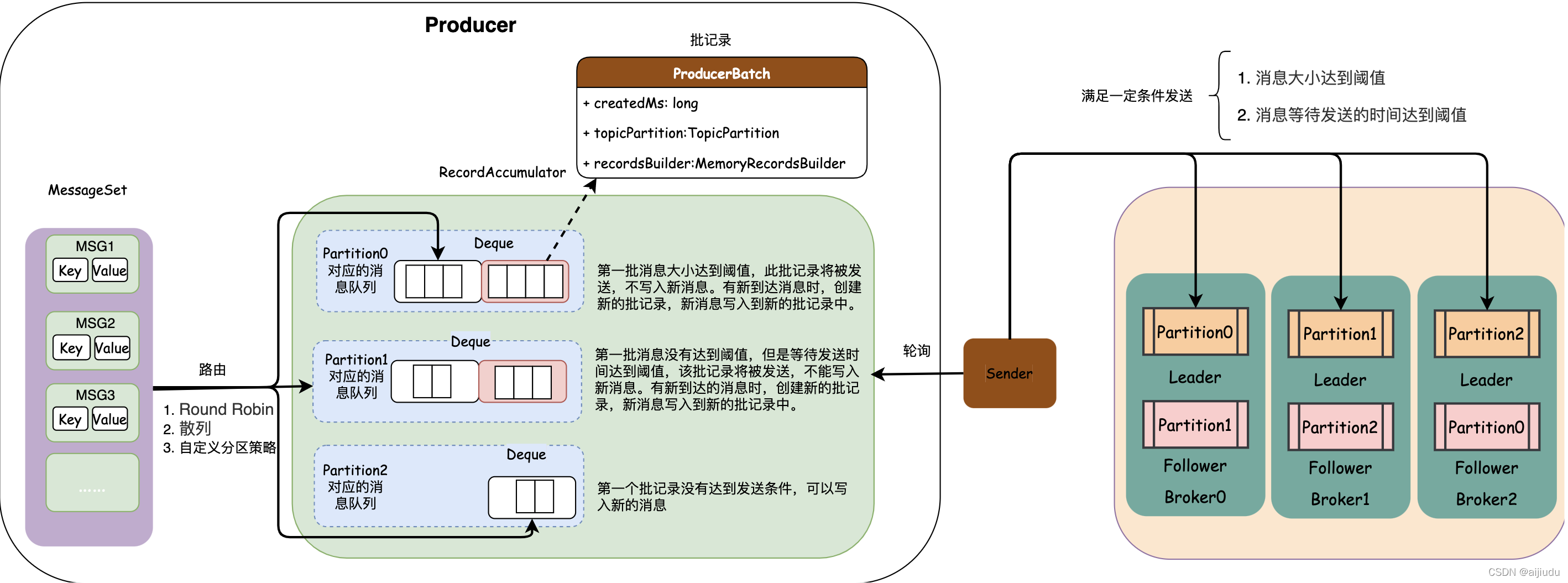
Kafka通過將Topic劃分成多個Partition,如下圖所示,訊息經過路由策略,被分發到不同的Partition對應的本地佇列(序列化訊息并壓縮訊息后,追加到本地的記錄收集器(RecordAccumulator),Sender不斷輪詢記錄收集器,當滿足一定條件時,將佇列中的資料發送到Partition Leader節點,
路由策略:Kafka的路由策略主要有三種:
-
Round Robin:Producer將訊息均衡地分配到各Partition本地佇列上,是最常用的磁區策略,
-
散列:Kafka對訊息的key進行散列,根據散列值將訊息路由到特定的Parttion上,鍵相同的訊息總是被路由到相同的Partition上,
-
自定義磁區策略:Kafka支持自定義磁區策略,可以將某一系列的訊息映射到相同的Partition,
本地佇列:
Producer會為每個Partition都創建一個雙端佇列來快取客戶端訊息,佇列的每個元素是一個批記錄(ProducerBatch),批記錄使用createdMs表示批記錄的創建時間(批記錄中第一條訊息加入的時間), topicPartion表示對應的Partition元資料,當Producer生產的訊息經過序列化,會被先寫入到recordsBuilder物件中,滿足發送條件,就會被Sender發送到Partition對應的Leader節點,
Sender發送資料到Broker的條件有兩個:
-
訊息大小達到閾值
-
訊息等待發送的時間達到閾值
Sender:Sender讀取記錄收集器,得到每個Leader節點對應的批記錄串列,找出準備好的Broker節點并建立連接,然后將各個Partition的批記錄發送到Leader節點,
//Sender讀取記錄收集器,按照節點分組,創建客戶端請求,發送請求
public void run(long now) {
Cluster cluster = metadata.fetch();
//獲取準備發送的所有磁區
ReadCheckResult result = accumulator.ready(cluster, now);
//建立到Leader節點的網路連接,移除還沒有準備好的節點
Iterator<Node> iter = result.readyNodes.iterator();
while(iter.hasNext()) {
Node node = iter.next();
if (!this.client.read(node, now)) {
iter.remove();
}
//讀取記錄收集器,回傳的每個Leader節點對應的批記錄串列,每個批記錄對應一個磁區
Map<Integer, List<RecordBatch>> batches = accumulator.drain(cluster, result.readyNodes,
this.maxRequestSize, now);
//以節點為級別的生產請求串列,即每個節點只有一個客戶端請求
List<ClientRequest> requests = createProduceRequests(batches, now);
for (ClientRequest request : requests) {
client.send(request, now);
}
//這里才會執行真正的網路讀寫,比如將上面的客戶端請求發送出去
this.client.poll(pollTimeout, now);
}
}具體的步驟如下:
1、訊息被記錄收集器收集,并按照Partition追加到佇列尾部一個批記錄中,
2、Sender通過ready()從記錄收集器中找出已經準備好的服務端節點,規則是Partition等待發送的訊息大小和等待發送的時間達到閾值,
3、節點已經準備好,如果客戶端還沒有和它們建立連接,通過connect()建立到服務端的連接,
4、Sender通過drain()從記錄收集器獲取按照節點整理好的每個Partition的批記錄,
5、Sender得到每個節點的批記錄后,為每個節點創建客戶端請求,并將訊息發送到服務端,
訊息格式:每個訊息檔案都是一個log entry序列,其格式如下圖所示:
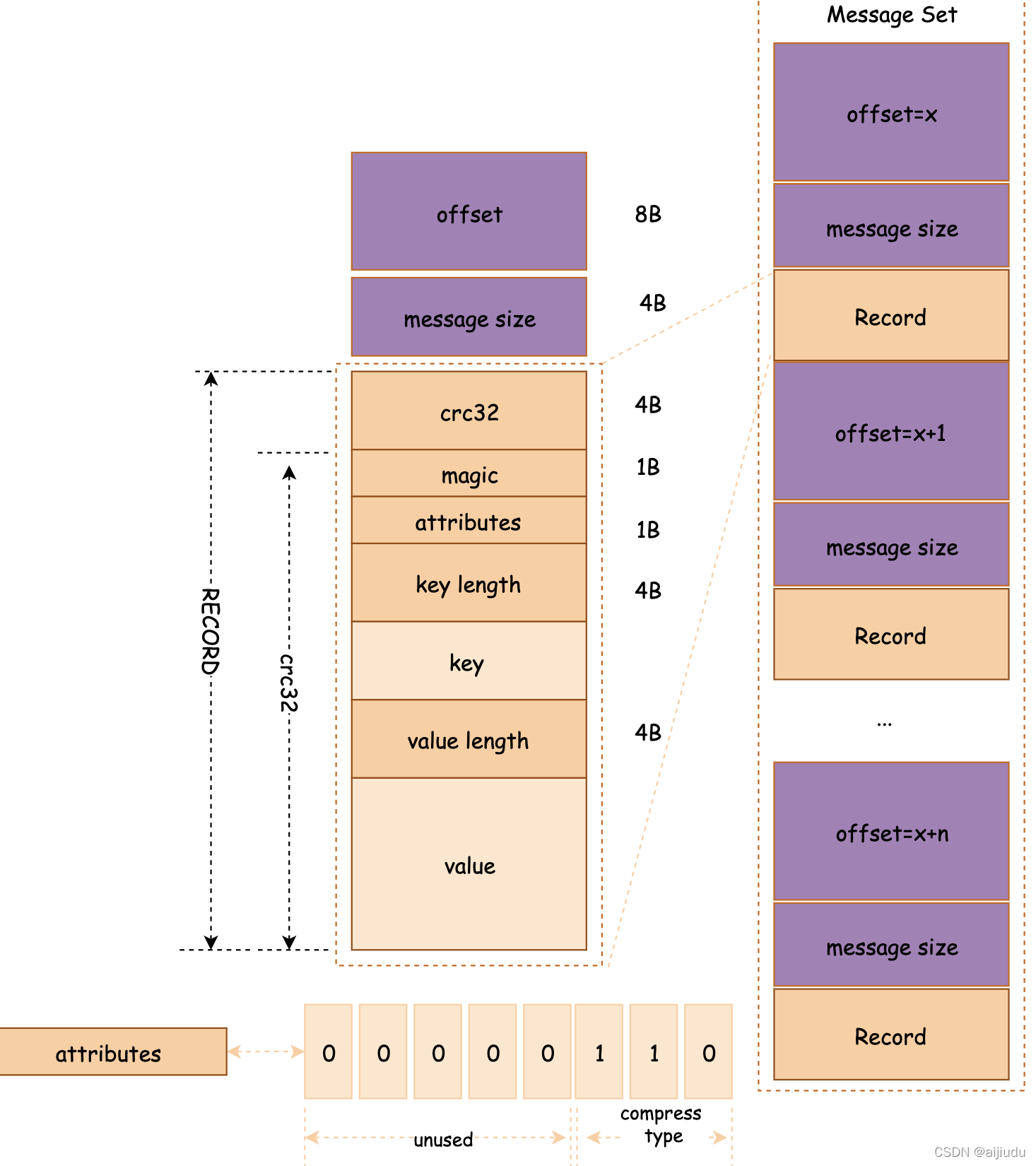
上圖左側的“RECORD”部分就是Kafka的訊息格式,一條完整的訊息包含RECORD、offset以及message size,其中offset用來標識它在Partition中的偏移量,這個offset是邏輯值,而非實際物理偏移值,message size表示訊息的大小,與訊息對應的還有訊息集的概念,訊息集中包含一潭訓者多條訊息,訊息集不僅是存盤于磁盤以及在網路上傳輸(Produce & Fetch)的基本形式,而且是kafka中壓縮的基本單元,詳細結構參考上圖右側,下面來具體描述一下訊息(RECORD)格式中的各個欄位,從crc32開始算起,各個欄位的解釋如下:
crc32(4B):crc32校驗值,校驗范圍為magic至value之間,
magic(1B):訊息格式版本號,0.9.X版本的magic值為0,
attributes(1B):訊息的屬性,總共占1個位元組,低3位表示壓縮型別:0表示NONE、1表示GZIP、2表示SNAPPY、3表示LZ4,其余位保留,
key length(4B):表示訊息的key的長度,如果為-1,則表示沒有設定key,即key=null,
key:可選,如果沒有key則無此欄位,
value length(4B):實際訊息體的長度,如果為-1,則表示訊息為空,
value:訊息體,可以為空,
2 持久化訊息-順序寫
Broker中需要將大量的訊息做持久化,而且存在大量的訊息查詢場景,如果采用傳統的IO操作,會帶來大量的磁盤尋址,影響訊息的查詢速度,限制了Kafka的性能,為了解決這個問題,Kafka采用順序寫的方式來做訊息持久化,
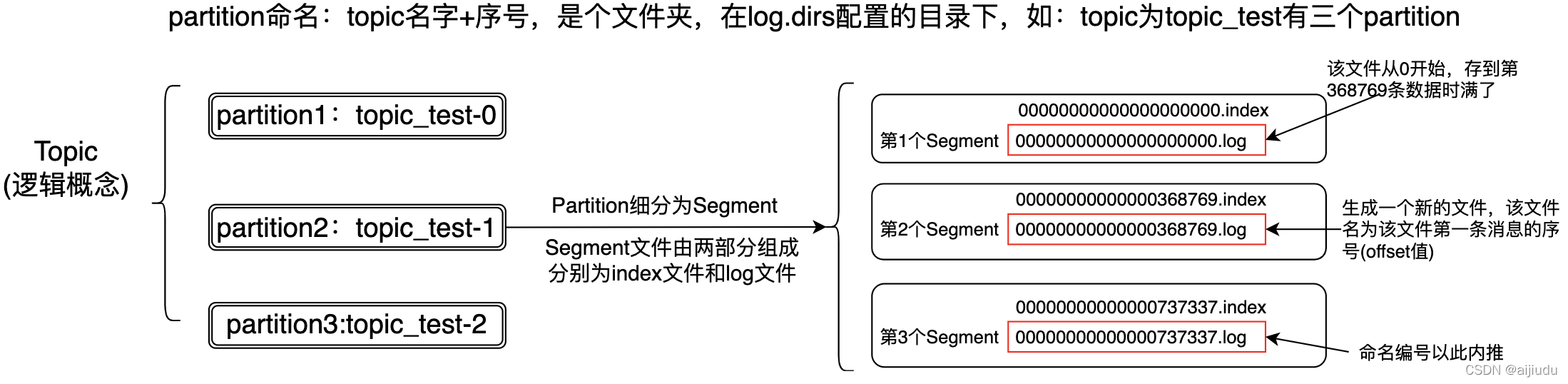
Topic是一個邏輯概念,如下圖:partition命名:opic為topic_test有三個partition,partition的命名是topic名字+序號,是個檔案夾,在log.dirs配置的目錄下,partition可以細分為Segment,Segment檔案由兩部分組成
分別為index檔案和log檔案,
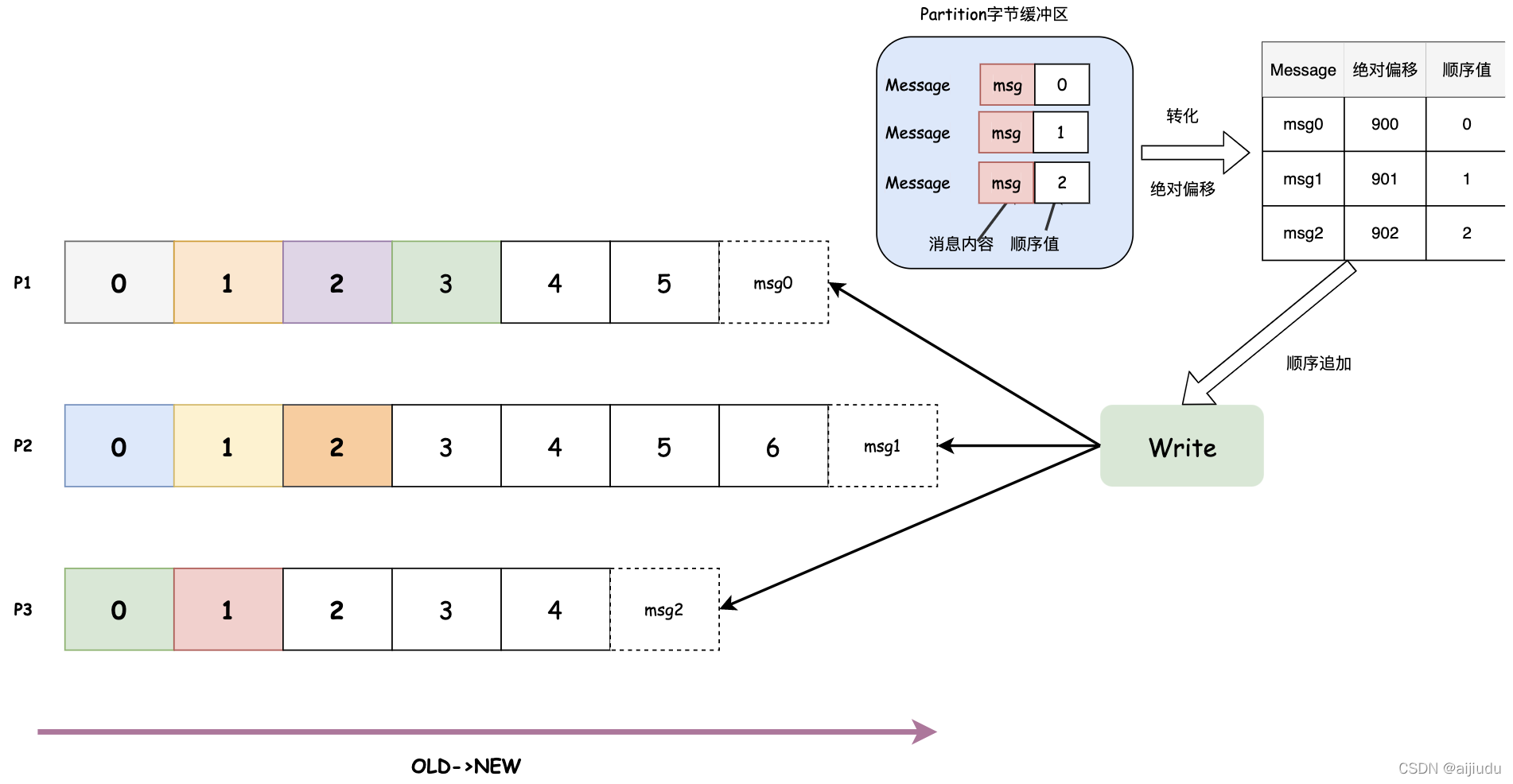
寫訊息:Producer傳遞到Broker的訊息集中的每條訊息都會分配一個順序值(只是相對于本批次的序號)用來標記Producer所生產訊息的順序,每一批訊息的順序值都從0開始,服務端會將每條訊息的順序值轉換成絕對偏移量(Broker從Partition維度來標記訊息的順序,用于控制Consumer消費訊息的順序),Kafka通過nextOffset(下一個偏移量)來記錄存盤在日志中最近一條訊息的偏移量,訊息發送到Broker后,每條訊息都被順序寫該Partition所對應的檔案中,因此效率非常高,這是Kafka高吞吐率的一個很重要的保證,
下圖給出一個例子,Producer寫到Partition的訊息有3條訊息,對應的順序值是[0,1,2],訊息寫入前,nextOffset是899,msg0、msg1、msg2是連續寫入的三條訊息,訊息被寫入后其絕對偏移量分別是900、901、902,對應的順序值分別是0、1、2,nextOffset變成902,
3 基于索引檔案的查詢
Kafka通過索引檔案提高對磁盤上訊息的查詢效率,
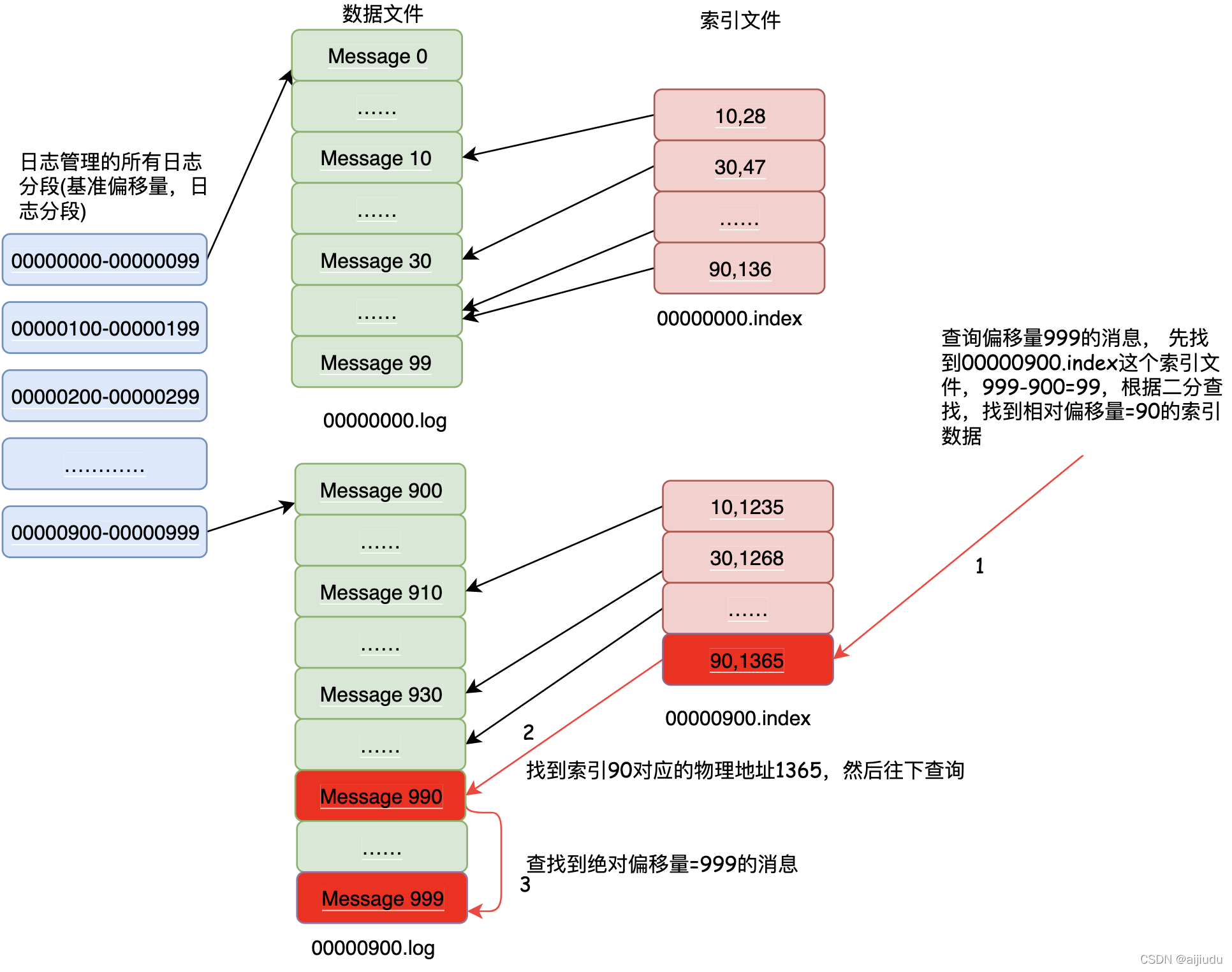
如上圖所示:假設有1000條訊息,每100條訊息寫滿了一個日志分段,一共會有10個日志分段,客戶端要查詢偏移量為938的訊息內容,如果沒有索引檔案,我們必須從第一個日志分段的資料檔案中,從第一條訊息一直往前讀,直到找到偏移量為999的訊息,有了索引檔案后,我們可以在最后一個日志分段的索引檔案中,首先使用絕對偏移量999減去基準偏移量900得到相對偏移量99,然后找到最接近相對偏移量99的索引資料90,相對偏移量90對應的物理地址是1365,然后再到資料檔案中,從檔案物理位置1365開始往后讀訊息,直到找到偏移量為999的訊息,
Kafka的索引檔案的特性:
-
索引檔案映射偏移量到檔案的物理位置,它不會對每條訊息都建立索引,所以是稀疏的,
-
索引條目的偏移量存盤的是相對于“基準偏移量”的“相對偏移量” ,不是訊息的“絕對偏移量” ,
-
偏移量是有序的,查詢指定的偏移量時,使用二分查找可以快速確定偏移量的位置,
-
指定偏移量如果在索引檔案中不存在,可以找到小于等于指定偏移量的最大偏移量,
-
稀疏索引可以通過記憶體映射方式,將整個索引檔案都放入記憶體,加快偏移量的查詢,
由于Broker是將訊息持久化到當前日志的最后一個分段中,寫入檔案的方式是追加寫,采用了對磁盤檔案的順序寫,對磁盤的順序寫以及索引檔案加快了Broker查詢訊息的速度,
4 零拷貝
Kafka中存在大量的網路資料持久化到磁盤(Producer到Broker)和磁盤檔案通過網路發送(Broker到Consumer)的程序,這一程序的性能直接影響到Kafka的整體性能,Kafka采用零拷貝這一通用技術解決該問題,
零拷貝技術可以減少資料拷貝和共享總線操作的次數,消除傳輸資料在存盤器之間不必要的中間拷貝次數,減少用戶應用程式地址空間和作業系統內核地址空間之間因為背景關系切換而帶來的開銷,從而有效地提高資料傳輸效率,
(1)傳統的檔案拷貝
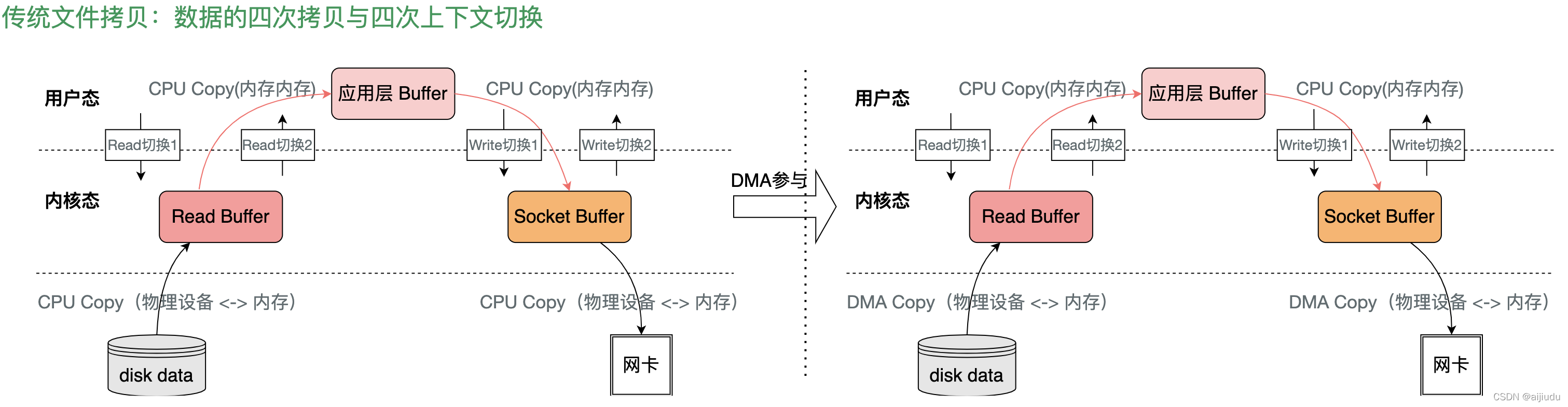
傳統檔案拷貝:資料的四次拷貝與四次背景關系切換
4次拷貝:
-
一個讀操作發生后,CPU/DMA執行了一次資料拷貝,資料從磁盤拷貝到內核空間;
-
cpu將資料從內核空間拷貝至用戶空間
-
呼叫send(),cpu發生第三次資料拷貝,由cpu將資料從用戶空間拷貝至內核空間(socket緩沖區)
-
send()執行結束后,CPU/DMA執行第四次資料拷貝,將資料從內核拷貝至協議引擎
4 次背景關系切換:
-
read 系統呼叫時:用戶態切換到內核態;
-
read 系統呼叫完畢:內核態切換回用戶態;
-
write 系統呼叫時:用戶態切換到內核態;
-
write 系統呼叫完畢:內核態切換回用戶態;
DMA 技術:DMA【協處理器(一塊獨立的芯片)】負責記憶體與其他組件之間的資料拷貝,CPU 僅需負責管理,而無需負責全程的資料拷貝;DMA僅僅能用于設備間交換資料時進行資料拷貝,但是設備內部的資料拷貝還需要 CPU 來親力親為,
Kafka 作為一個訊息佇列,涉及到磁盤 I/O 主要有兩個操作:
-
Provider 向 Kakfa 發送訊息,Kakfa 負責將訊息以日志的方式持久化落盤;(mmap 機制)
-
Consumer 向 Kakfa 進行拉取訊息,Kafka 負責從磁盤中讀取一批日志訊息,然后再通過網卡發送;
(2)kafka provider持久化資料(寫入)采用memory map-零拷貝技術(mmap 也至少需要 4 次背景關系切換)
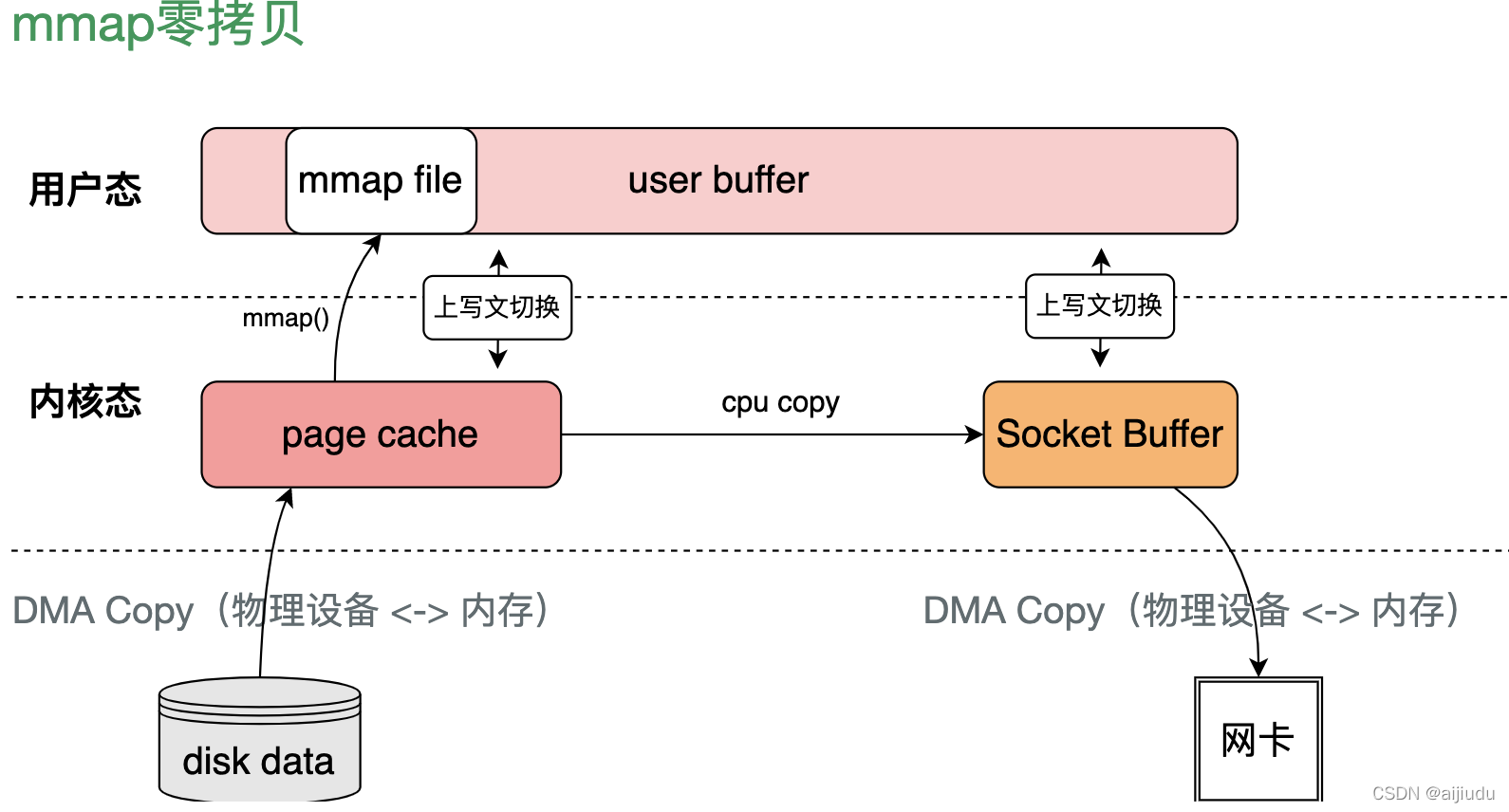
零拷貝技術是一個思想,指的是指計算機執行操作時,CPU 不需要先將資料從某處記憶體復制到另一個特定區域,零拷貝不是不進行拷貝,而是 CPU 不再全程負責資料拷貝時的搬運作業,
mmap:僅代替 read 系統呼叫,將內核空間地址映射為用戶空間地址,write 操作直接作用于內核空間,通過 DMA 技術以及地址映射技術,用戶空間與內核空間無須資料拷貝,實作了 zero copy
mmap 技術有如下特點:
-
利用 DMA 技術來取代 CPU 來在記憶體與其他組件之間的資料拷貝,例如從磁盤到記憶體,從記憶體到網卡;
-
用戶空間的 mmap file 使用虛擬記憶體,實際上并不占據物理記憶體,只有在內核空間的 kernel buffer cache 才占據實際的物理記憶體;
-
mmap() 函式需要配合 write() 系統調動進行配合操作,這與 sendfile() 函式有所不同,后者一次性代替了 read() 以及 write();因此 mmap 也至少需要 4 次背景關系切換;
-
mmap 僅僅能夠避免內核空間到用戶空間的全程 CPU 負責的資料拷貝,但是內核空間內部還是需要全程 CPU 負責的資料拷貝;
利用 mmap() 替換 read(),配合 write() 呼叫的整個流程如下:
-
用戶行程呼叫 mmap(),從用戶態陷入內核態,將內核緩沖區映射到用戶快取區;
-
DMA 控制器將資料從硬碟拷貝到內核緩沖區(可見其使用了 Page Cache 機制);
-
mmap() 回傳,背景關系從內核態切換回用戶態;
-
用戶行程呼叫 write(),嘗試把檔案資料寫到內核里的套接字緩沖區,再次陷入內核態;
-
CPU 將內核緩沖區中的資料拷貝到的套接字緩沖區;
-
DMA 控制器將資料從套接字緩沖區拷貝到網卡完成資料傳輸;
-
write() 回傳,背景關系從內核態切換回用戶態,
(3)kafka Consumer拉取資料(讀)采用sendfile-零拷貝技術
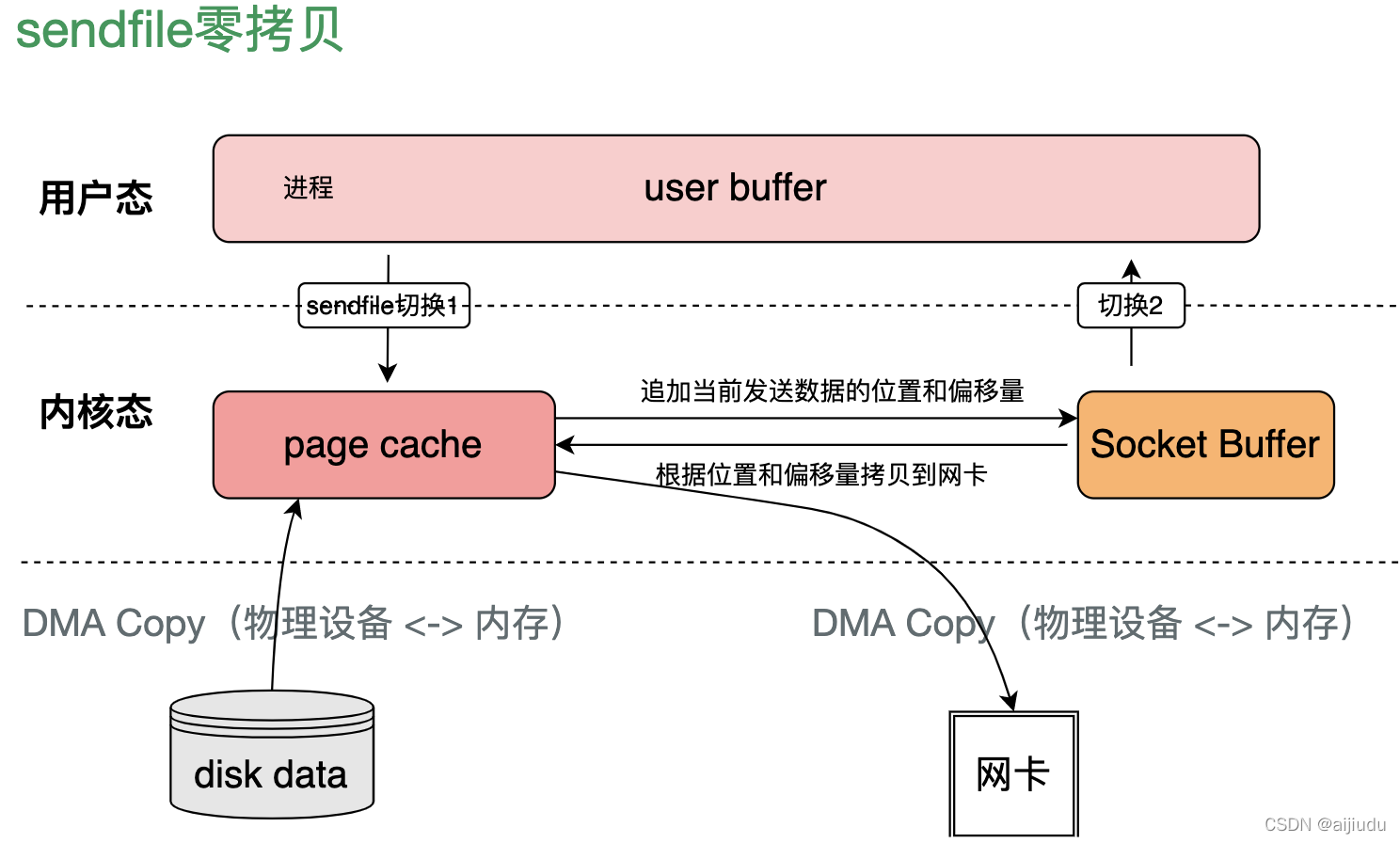
sendfile:一次代替 read/write 系統呼叫,通過使用 DMA 技術以及傳遞檔案描述符代替資料拷貝,實作了 zero copy,
sendfile流程如下:
-
將檔案拷貝到page cache中;
-
向socket buffer中追加當前要發生的資料在page cache中的位置和偏移量;
-
根據socket buffer中的位置和偏移量直接將page cache的資料copy到網卡設備中;
kafka讀資料采用sendfile機制優點:
-
sendfile 依賴于 DMA 技術,將四次CPU全程負責的拷貝與四次背景關系切換減少到兩次,避免了內核空間到用戶空間的CPU全程負責的資料移動;
-
sendfile 基于 Page Cache 實作,因此如果有多個 Consumer 在同時消費一個主題的訊息,那么由于訊息一直在 page cache 中進行了快取,因此只需一次磁盤 I/O,就可以服務于多個 Consumer;
缺點:因為用戶執行緒根本就不能夠通過 sendfile 系統呼叫得到傳輸的資料(傳遞檔案描述符代替資料拷貝:page cache 以及 socket buffer 都在內核空間中;資料在傳輸中沒有被更新;),所以無法修改資料,
五、Kafka高可靠
1 訊息備份
Kafka允許同一個Partition存在多個訊息副本(Replica),每個Partition的副本通常由1個Leader及0個以上的Follower組成,生產者將訊息直接發往對應Partition的Leader,Follower會周期地向Leader發送同步請求,Kafka的Leader機制在保障資料一致性地同時降低了訊息備份的復雜度,
同一Partition的Replica不應存盤在同一個Broker上,因為一旦該Broker宕機,對應Partition的所有Replica都無法作業,這就達不到高可用的效果,為了做好負載均衡并提高容錯能力,Kafka會盡量將所有的Partition以及各Partition的副本均勻地分配到整個集群上,
2 ISR & LEO & HW
ISR(In-Sync Replicas)指的是一個Partition中與Leader“保持同步”的Replica串列(實際存盤的是副本所在Broker的BrokerId),這里的保持同步不是指與Leader資料保持完全一致,只需在replica.lag.time.max.ms時間內與Leader保持有效連接,官方解釋如下
If a follower hasn't sent any fetch requests or hasn't consumed up to the leaders log end offset for at least this time, the leader will remove the follower from isr,( default value =10000 )
Follower周期性地向Leader發送FetchRequest請求(資料結構見下),發送時間間隔配置在replica.fetch.wait.max.ms中,默認值為500,
public class FetchRequest {
private final short versionId;
private final int correlationId;
private final String clientId;
private final int replicaId;
private final int maxWait; // Follower容忍的最大等待時間: 到點Leader立即回傳結果,默認值500
private final int minBytes; // Follower容忍的最小回傳資料大小:當Leader有足夠資料時立即回傳,兜底等待maxWait回傳,默認值1
private final Map<TopicAndPartition, PartitionFetchInfo> requestInfo; // Follower中各Partititon對應的LEO及獲取數量
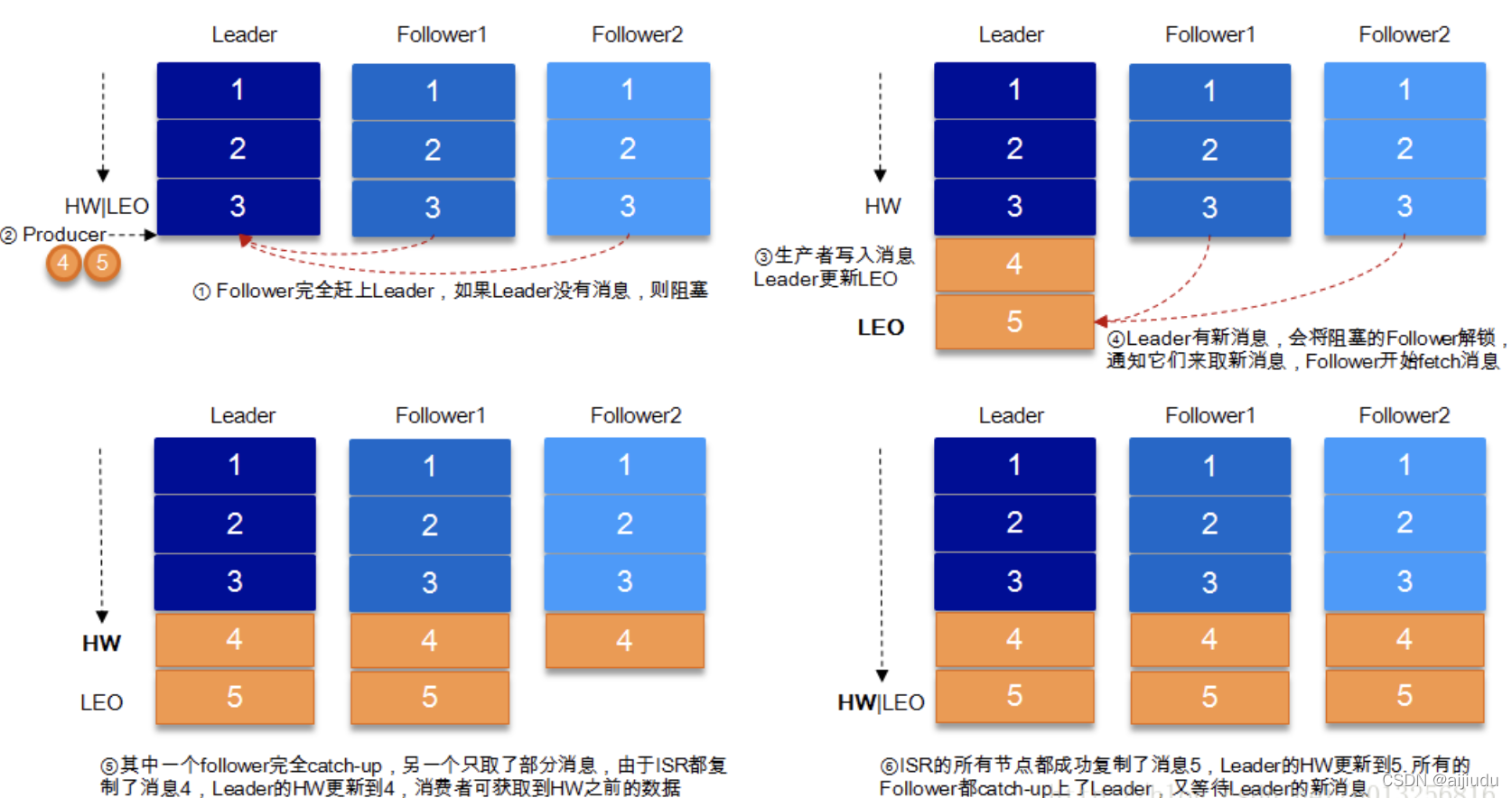
}各Partition的Leader負責維護ISR串列并將ISR的變更同步至ZooKeeper,被移出ISR的Follower會繼續向Leader發FetchRequest請求,試圖再次跟上Leader重新進入ISR,
ISR中所有副本都跟上了Leader,通常只有ISR里的成員才可能被選為Leader,當Kafka中unclean.leader.election.enable配置為true(默認值為false)且ISR中所有副本均宕機的情況下,才允許ISR外的副本被選為Leader,此時會丟失部分已應答的資料,
每個Kafka副本物件都有下面兩個重要屬性:
LEO(log end offset) ,即日志末端偏移,指向了副本日志中下一條訊息的位移值(即下一條訊息的寫入位置)
HW(high watermark),即已同步訊息標識,因其類似于木桶效應中短板決定水位高度,故取名高水位線
所有高水位線以下訊息都是已備份過的,消費者僅可消費各磁區Leader高水位線以下的訊息,對于任何一個副本物件而言其HW值不會大于LEO值
Leader的HW值由ISR中的所有備份的LEO最小值決定(Follower在發送FetchRequest時會在PartitionFetchInfo中會攜帶Follower的LEO)
下圖詳細的說明了當Producer生產訊息至Broker后,ISR以及HW和LEO的流轉程序:
3 Acks
為了講清楚ISR的作用,下面介紹一下生產者可以選擇的訊息應答方式,生產者發送訊息中包含acks欄位,該欄位代表Leader應答生產者前Leader收到的應答數
-
acks=0
生產者無需等待服務端的任何確認,訊息被添加到生產者套接字緩沖區后就視為已發送,因此acks=0不能保證服務端已收到訊息,使用場景較少,本文不做任何討論
-
acks=1
Leader將訊息寫入本地日志后無需等待Follower的訊息確認就做出應答,如果Leader在應答訊息后立即宕機且其他Follower均未完成訊息的復制,則該條訊息將丟失
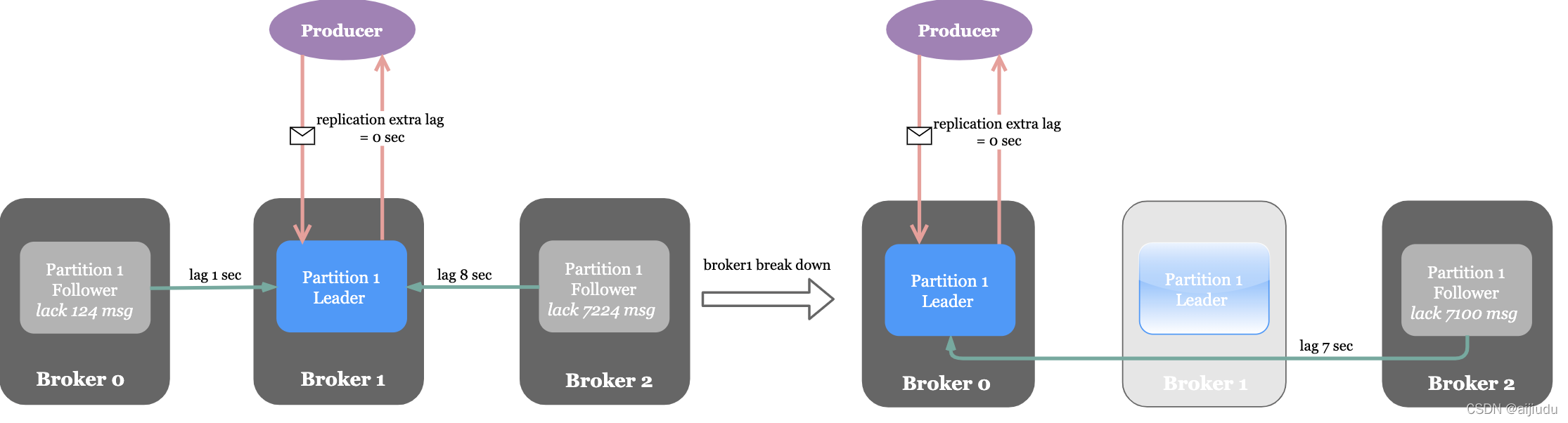
上圖左側的穩態場景下,Partition1的資料冗余備份在Broker0和Broker2上;Broker0中的副本與Leader副本因網路開銷等因素存在1秒鐘同步時間差,Broker0中的副本落后124條訊息;Broker2中的副本存在8秒鐘同步時間差,Broker2中的副本落后7224條訊息,若圖中的Broker1突然宕機且Broker0被選為Partition1的Leader,則在Leader宕機前寫入的124條訊息未同步至Broker0中的副本,這次宕機會造成少量訊息丟失,
-
acks=all
Leader將等待ISR中的所有副本確認后再做出應答,因此只要ISR中任何一個副本還存活著,這條應答過的訊息就不會丟失,acks=all是可用性最高的選擇,但等待Follower應答引入了額外的回應時間,Leader需要等待ISR中所有副本做出應答,此時回應時間取決于ISR中最慢的那臺機器,下圖中因復制產生的額外延遲為3秒,
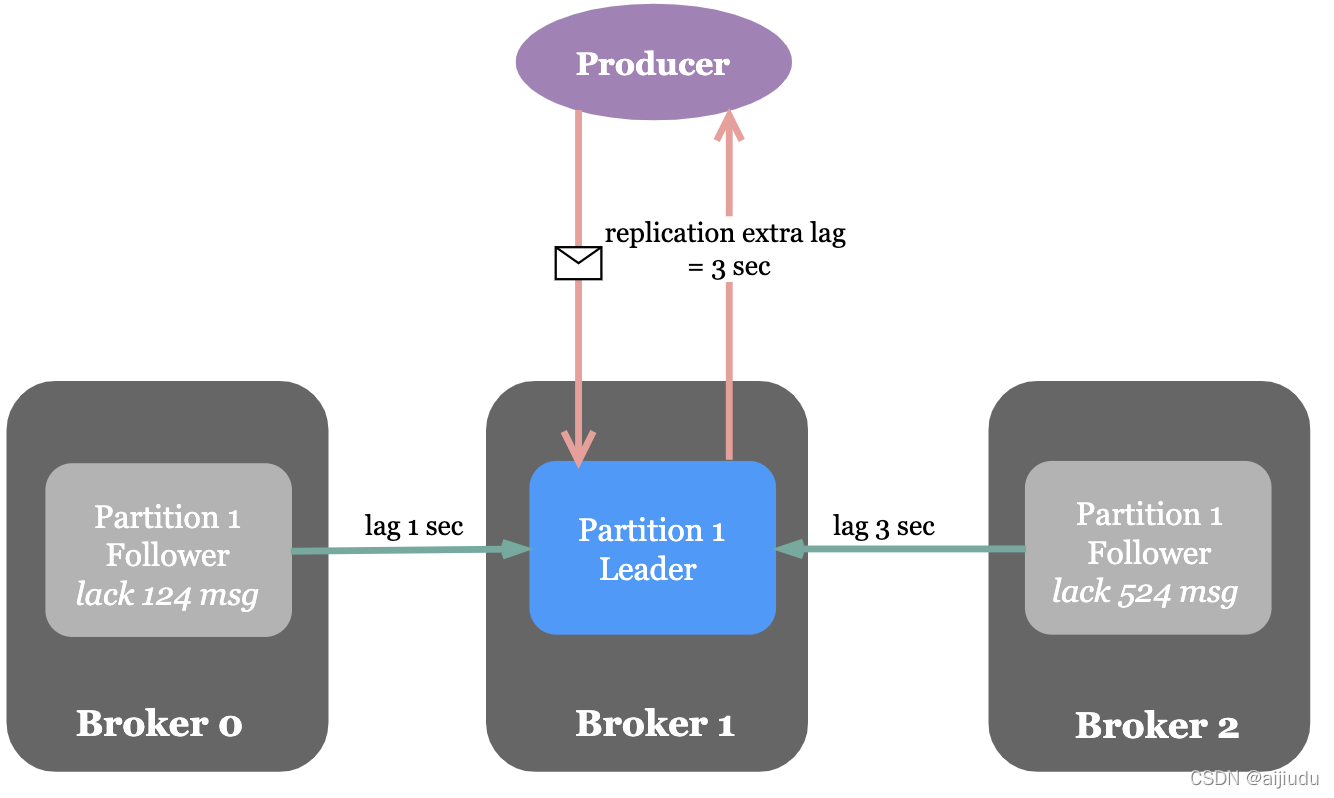
Broker的配置項min.insync.replicas(默認值為1)代表了正常寫入生產者資料所需要的最少ISR個數,當ISR中的副本數量小于min.insync.replicas時,Leader停止寫入生產者生產的訊息,并向生產者拋出NotEnoughReplicas例外,阻塞等待更多的Follower趕上并重新進入ISR,被Leader應答的訊息都至少有min.insync.replicas個副本,因此能夠容忍min.insync.replicas-1個副本同時宕機,
小結:發送的acks=1訊息會出現丟失情況,為不丟失訊息可配置生產者acks=all & min.insync.replicas >= 2
kafka故障恢復,Broker故障場景分析,Controller故障恢復本文不做介紹,
六、MAC本地安裝Kafka
本地安裝kafka創建topic、producer和consumer
1 安裝
直接使用brew安裝kafka
brew install kafka
2 啟動kafka服務
我們需要先后啟動zookeeper和kafka服務,
它們都需要進入 /usr/local/Cellar/kafka/3.1.0目錄,然后再啟動相應的命令,
cd /usr/local/Cellar/kafka/3.1.0
啟動zookeeper服務,運行命令:
zookeeper-server-start /usr/local/etc/kafka/zookeeper.properties
啟動kafka服務,運行命令:
kafka-server-start /usr/local/etc/kafka/server.properties3 創建Topic,顯示資料
新版本的kafka,已經不需要依賴zookeeper來創建topic,新版的kafka創建topic指令為下:
/usr/local/Cellar/kafka/3.1.0/bin$ kafka-topics --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic topic_demo
查看topic
kafka-topics --list --bootstrap-server localhost:9092
生產者:
wangzhibin:/usr/local/Cellar/kafka/3.1.0/bin$ kafka-console-producer --broker-list localhost:9092 --topic topic_demo
>hahha
>kafka
>spark
查看topic檔案:cd /usr/local/var/lib/kafka-logs/topic_demo-0
消費者:
wangzhibin:/usr/local/Cellar/kafka/3.1.0/bin$ kafka-console-consumer --bootstrap-server localhost:9092 --topic topic_demo --from-beginning
hahha
kafka
spark
暫停kafka
kafka-server-stop轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/430288.html
標籤:其他
上一篇:公司來了個卷王之王,讓人崩潰