??大家好,我是 herosunly,985 院校碩士畢業,現擔任演算法研究員一職,熱衷于機器學習演算法研究與應用,曾獲得阿里云天池安全惡意程式檢測第一名,科大訊飛惡意軟體分類挑戰賽第三名,CCF 惡意軟體家族分類第四名,科大訊飛阿爾茨海默綜合癥預測挑戰賽第四名,科大訊飛事件抽取挑戰賽第七名,Datacon 大資料安全分析比賽第五名,擁有多項發明專利,對機器學習和深度學習擁有自己獨到的見解,今天給大家分享的是 AI 賦能安全技術總結與展望,歡迎大家在評論區留言,和大家一起成長進步,
文章目錄
- 1. 背景
- 2. 惡意樣本檢測
- 3. 基于UEBA的例外檢測
- 4. 總結與展望
1. 背景
??伴隨著人工智能技術的蓬勃發展,當前網路空間已經邁進到人工智能時代,人工智能對網路空間產生了變革性的影響,如何使用人工智能技術構建更可靠的網路安全系統就變得至關重要,具體來說,人工智能賦能安全,是指基于海量資料的基礎上利用人工智能來自動識別或回應潛在網路威脅的工具和技術,
??伴隨著人工智能技術的蓬勃發展,在網路空間安全中的很多細分領域涌現出與人工智能相關的新應用,比如惡意樣本檢測、惡意流量檢測、惡意域名檢測、例外檢測、網路釣魚檢測與防護、威脅情報構建等,在人工智能賦能安全蓬勃發展浪潮中,機器學習技術(包括深度學習技術)在應對網路空間威脅方面起著至關重要的作用,
??為了幫助初學者少走彎路以及更多人了解AI賦能安全,筆者總結了2021年AI賦能安全的一些經典案例(AI比賽和論文),希望能夠啟發大家的思維,最終推動AI賦能安全的發展與進步,由于AI賦能安全的細分領域較多,鑒于篇幅和時間的原因,以下主要介紹其中的兩大方面:惡意樣本檢測、基于UEBA的例外檢測,為了讓大家能夠深刻理解其中的要點,筆者提煉出相應的核心方法論,希望讀者能夠舉一反三,靈活應用到自己的作業生活中,
2. 惡意樣本檢測
??從檢測方法上來說,惡意樣本檢測包括靜態檢測、動態檢測、混合態檢測,其中靜態檢測是指在不運行惡意樣本的條件下,進行程式分析的檢測方法,而動態檢測是指將樣本放在隔離環境(沙箱)中自動地動態執行,然后提取其運行程序中的行程操作行為、網路操作行為、檔案操作行為等動態行為,而混合態檢測指的是綜合靜態檢測與動態檢測的檢測方法,簡單說明下,靜態檢測與動態檢測的主要區別在于是否運行惡意樣本,在靜態檢測中往往是對二進制檔案或者反匯編后的 ASM 檔案進行檢測(后續提到的 CCF 惡意軟體檢測即基于二進制檔案與 ASM 檔案進行檢測);而動態檢測往往是對沙箱運行出的 API 序列進行檢測;除此之外,兩者的主要區別在于,靜態檢測的執行效率遠遠高于動態檢測,但動態檢測往往能夠獲得更加完整的資訊,即動態檢測的漏報率往往低于靜態檢測,
??近年來,不同家族的惡意檔案如勒索軟體、 木馬、 病毒、 挖礦程式等惡意軟體不斷涌現, 對用戶和機構帶來了很多麻煩和經濟的損失,為了提升海量惡意軟體分析的高效性, 需要對惡意軟體的家族進行區分,考慮到在很多場景中算力較為有限,無法提供GPU計算資源,在此條件下使用傳統機器學習方法更為恰當,在傳統機器學習方法中,如何進行有效的特征工程,往往是作業中的重中之重,接下來將會分享一種核心方法論:小顆粒度分析法,
??主要內容來自于2021年12月份的論文:Malware Classification Using Static Disassembly and Machine Learning,本論文提出了四大類特征:PE section對應的大小(虛擬大小、原始大小、兩者比例)、PE section中不同權限section的大小(可讀、可寫、可執行段對應的虛擬大小之和、原始大小之和、兩者比例)、內容復雜度(PE和ASM檔案原始大小、使用zlib對PE和ASM檔案進行壓縮后的檔案大小、壓縮前后PE和ASM檔案的比例)和匯入庫,
?&emsp什么是細顆粒度分析法呢?對應到上述的文章中,一般來說往往只會考慮到 PE section 中的原始大小,而忽略其虛擬大小,也就是說在大小這個維度上將其細分考慮,即同時考慮到原始大小和虛擬大小則為細顆粒度分析,另外,將 PE section 按照不同權限進行劃分,劃分后再進行 PE section 對應的大小的建模,本質上是將整個檔案的建模細分為不同的 section 進行建模,我們可以將其理解為二層的細顆粒度分析法,當然,顆粒度也并非越小越好(即層數越高越好),需要根據實際資料、具體場景、模型效果來綜合判定,
??為了提高模型的運行效率,往往會使用特征篩選的方法來減少無效特征,具體來說是使用隨機森林模型并通過基尼系數進行特征篩選得到 40 維特征,其維度數遠遠小于常用的 N-gram 特征,提高了模型的運行效率,實驗任務為惡意樣本家族九分類,總資料量為 10868 個,其中 80%作為訓練集(使用 auto-sklearn 和 5 折交叉經驗確定模型及其超引數),20%作為測驗集,實驗結果表明:使用論文提出的四大類特征的效果較好,位于實驗結果第二名(準確率為 0.994),而第一名(0.9948)是采用了所有特征(特征選擇后為 10343 維度),
??為了幫助大家更好的理解細顆粒度分析法,再對大家較為常用的特征之一:熵進行細顆粒度分析法進行分析,在2021年CCF基于人工智能的惡意軟體家族分類比賽中,前幾名的隊伍都構建了熵直方圖作為其中一部分特征,具體來說,在二進制檔案上滑動一個固定位元組長度的視窗,步長也為固定位元組長度,通過計算在該視窗中每個位元組的出現次數,并計算每個視窗上的以2為底的熵,使用計算出的熵值作為下標,將視窗中每個位元組的出現次數自增到特征矩陣相應下標所對應的向量上,隨后滑動視窗繼續計算對應位元組視窗的熵值,在生成特征時,展開該特征矩陣為一維特征向量,計算位元組熵時滑動視窗示意圖如下圖所示,在實際比賽程序中,我們通過上述方法提取的位元組統計值特征維數為256,
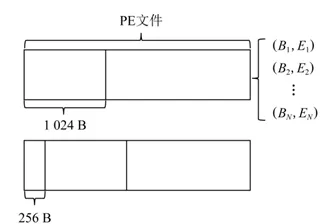
??為了方便大家對此特征進行理解,特意進行更加細致的講解:
??原本的資訊熵是對每個位元組求資訊熵,由于位元組大小范圍為[0, 255],所以一共是256個bins,每個bin內僅僅包含一個位元組,不同滑窗但位于相同bin的資料會進行相加,
??同時我們將熵的值進行細粒度劃分,其中資訊熵的最大值為 l o g 2 ( n ) log_2(n) log2?(n),n為bin的個數,原本bin的個數為256個,所以最大值為8,如果熵每隔1作為其間隔,那么最終的維度數為256*8=2048維,
??如果我們只考慮高4位對應的熵值,然后再乘以2就能近似得到8位對應的熵值,本質是是將ASCII碼對應的字符(0~127)一視同仁處理,
??由于高4位總共只有16個取值,所以將原有的n從256轉換成了16,此時熵的最大值即為 l o g 2 16 = 4 log_2{16}=4 log2?16=4,同樣,我們在熵的維度上進行細粒度的劃分,將熵乘以4以后每個bin的距離為1,那么熵這一維的維度數為16,
??那么最終的維度數為16*16=256,簡單總結下就是把熵值進行了小顆粒度劃分,從而將一維特征表示成了二維特征,
??順便提一句,個人也在該比賽中使用了上述特征,并最終取得了第四名的優異成績,也歡迎大家報名參加各項AI比賽,說不定會找到屬于自己的一片天地,

3. 基于UEBA的例外檢測
??用戶與物體行為分析系統采用的UEBA 技術( User and Entity Behaviours Analytics),是網路安全領域里進行例外檢測的重要手段之一,在傳統檢測設備(如 IDS、 IPS、 NGIPS、 NGIDS、FW、 NGFW )中,需要根據專家經驗來構建規則,然后通過檢索匹配的方法來進行威脅檢測,但在部分實際場景中,由于威脅不斷演變,所以往往需要靈活的對規則中的部分閾值進行及時調整,從而達到較好的檢測效果,
??而所謂的UEBA手段不僅是從資料分析的視角去發現關鍵問題,從聚焦資料內容本身到內容背景關系關系、行為分析等,從單點單條檢測到多維度大資料分析來發現更多更準確的有價值資訊,
??2021年的CCF舉辦了基于UEBA的用戶上網例外行為分析比賽,該比賽是基于無標簽的用戶日常上網日志資料,從而構建用戶上網行為基線和上網行為評價模型,依據上網行為與基線的距離確定偏離程度,從而評價上網行為與基線的偏離程度,
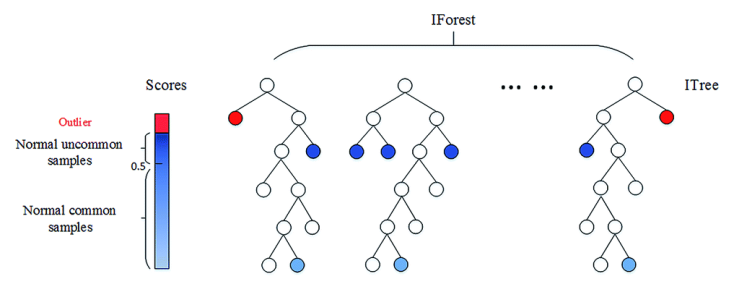
其中第一名使用了將全域語意和區域語意相結合的核心方法論,其中全域指的是基于全部資料構建模型,而區域指的是用戶和部門來構建模型,其中每個用戶建立一個模型,每個部門建立一個模型,然后對上述三大模型進行集成,其中模型均采用的是孤立森林,
??孤立森林具有檢測效果好,并且時間復雜度低(時間復雜度)的特點,模型結構如下圖所示:
4. 總結與展望
??本文主要介紹了AI賦能安全的兩大應用場景:惡意樣本檢測與基于UEBA的例外檢測,同時也分享了兩大核心方法論:細粒度分析法和全域語意和區域語意相結合的方法,
??隨著深度學習技術在NLP、CV、推薦系統等領域的蓬勃發展,筆者很看好Transformer等預訓練模型、對比學習、Prompt Learning等技術能夠成功應用于網路空間安全中,讓我們一起努力,為AI賦能安全盡出自己的一份力量,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/431055.html
標籤:AI
上一篇:R語言常用基礎函式:使用edit函式呼叫資料編輯器手動自定義編輯資料物件不改變原始資料物件內容、使用fix函式呼叫資料編輯器手動自定義編輯資料物件并直接覆寫原資料內容