文章目錄
- 01 引言
- 02 hive資料模型
- 2.1 DataBase資料庫
- 2.2 Table表
- 2.2.1 內部表
- 2.2.2 外部表
- 2.3 Partition磁區
- 2.3.1 Partition磁區型別
- 2.3.1.1 靜態磁區
- 2.3.1.2 動態磁區
- 2.3.2 Partition磁區例子
- 2.4 Bucket分桶
- 2.4.1 分桶特性
- 2.4.2 分桶好處
- 2.5 磁區與分桶的區別
- 03 文末
01 引言
在前面的教程,已經把Hive環境搭建起來了,有興趣的同學可以參閱:
- 《Hive教程(01)- 初識Hive》
- 《Hive教程(02)- Hive安裝》
既然有了hive的環境,此時大家肯定十分迫切的想把hive用起來,但是用之前,我們是很有必要了解hive的幾種資料模型的,也就是需要知道hive把資料最終存在了hdfs的哪里?
02 hive資料模型
hive資料模型關系圖如下:
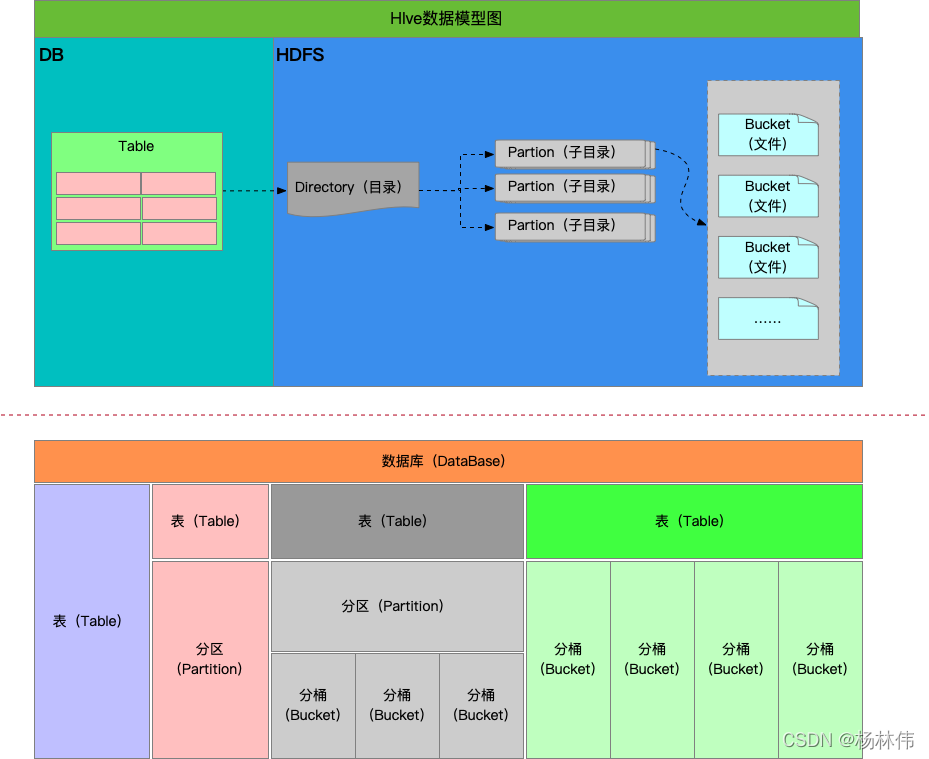
從上圖,可以看到 hive 主要有幾種資料模型,分別是:
- DataBase:資料庫
- Table:表
- Partition:磁區
- Bucket:桶
2.1 DataBase資料庫
DataBase資料庫:相當于關系型資料庫中的命名空間,作用是將資料庫應用隔離到不同的資料庫模式中 ,
相關的命令:
create database資料庫名use資料庫名- 以及
drop database資料庫名等陳述句;
2.2 Table表
Table表:表是由存盤的資料以及描述表的一些元資料組成,資料存盤再分布式檔案系統中,元資料存盤在關系型資料庫中;
hive表分四種:
- MANGED_TABLE :內部表
- EXTERNAL_TABLE:外部表
- INDEX_TABLE:索引表
- VIRTUAL_VIEW :視圖表
相關的命令(查看表的具體資訊使用):
desc tablenamedesc formatted tablename
2.2.1 內部表
hive 會默認把資料存盤到 /user/hive/warehouse 目錄里面:
CREATE TABLE managed_table (dummy STRING);
LOAD DATA INPATH '/user/tom/data.txt' INTO table managed_table;
描述: 根據上面的代碼,
hive會把檔案data.txt檔案存盤在managed_table表的warehouse目錄下,即hdfs://user/hive/warehouse/managed_table目錄,
2.2.2 外部表
外部表與內部表的行為上有些差別,我們能夠控制資料的創建和洗掉,洗掉外部表的時候,hive只會洗掉表的元資料,不會洗掉表資料(資料路徑是在創建表的時候指定的):
CREATE EXTERNAL TABLE external_table (dummy STRING)
LOCATION '/user/tom/external_table';
LOAD DATA INPATH '/user/tom/data.txt' INTO TABLE external_table;
描述:利用EXTERNAL關鍵字創建外部表,Hive不會去管理表資料,所以它不會把資料移到/user/hive/warehouse目錄下,
2.3 Partition磁區
Partition磁區:hive的磁區是根據某列的值進行粗略的劃分,每個磁區對應HDFS上的一個目錄,
創建磁區表語法:
CREATE TABLE table_name (column1 data_type, column2 data_type)
PARTITIONED BY (partition1 data_type, partition2 data_type,….);
磁區表基于磁區鍵把具有相同磁區鍵的資料存盤在一個目錄下,在查詢某一個磁區的資料的時候,只需要查詢相對應目錄下的資料,而不會執行全表掃描,提高查詢資料的效率,也就是說,
hive在查詢的時候會進行磁區剪裁 ,每個表可以有一個或多個磁區鍵,
2.3.1 Partition磁區型別
2.3.1.1 靜態磁區
- 把輸入資料檔案單獨插入磁區表的叫靜態磁區;
- 通常在加載檔案(大檔案)到
Hive表的時候,首先選擇靜態磁區; - 在加載資料時,靜態磁區比動態磁區更節省時間;
- 你可以通過
alter table add partition陳述句在表中添加一個磁區,并將檔案移動到表的磁區中; - 我們可以修改靜態磁區中的磁區;
- 您可以從檔案名、日期等獲取磁區列值,而無需讀取整個大檔案;
- 如果要在
Hive使用靜態磁區,需要把hive.mapred.mode設定為strict,set hive.mapred.mode=strict; - 靜態磁區是在嚴格模式進行下;
- 你可以在
Hive的內部表和外部表使用靜態磁區,
2.3.1.2 動態磁區
- 對磁區表的一次性插入稱為動態磁區,
- 通常動態磁區表從非磁區表加載資料,
- 在加載資料的時候,動態磁區比靜態磁區會消耗更多時間,
- 如果需要存盤到表的資料量比較大,那么適合用動態磁區,
- 假如你要對多個列做磁區,但又不知道有多少個列,那么適合使用動態磁區,
- 動態磁區不需要
where子句使用limit, - 不能對動態磁區執行修改,
- 可以對內部表和外部表使用動態磁區,
- 使用動態磁區之前,需要把模式修改為非嚴格模式,
set hive.mapred.mode=nostrict,
2.3.2 Partition磁區例子
借用大象教程(https://www.hadoopdoc.com/hive/hive-data-model)里的一張圖片:
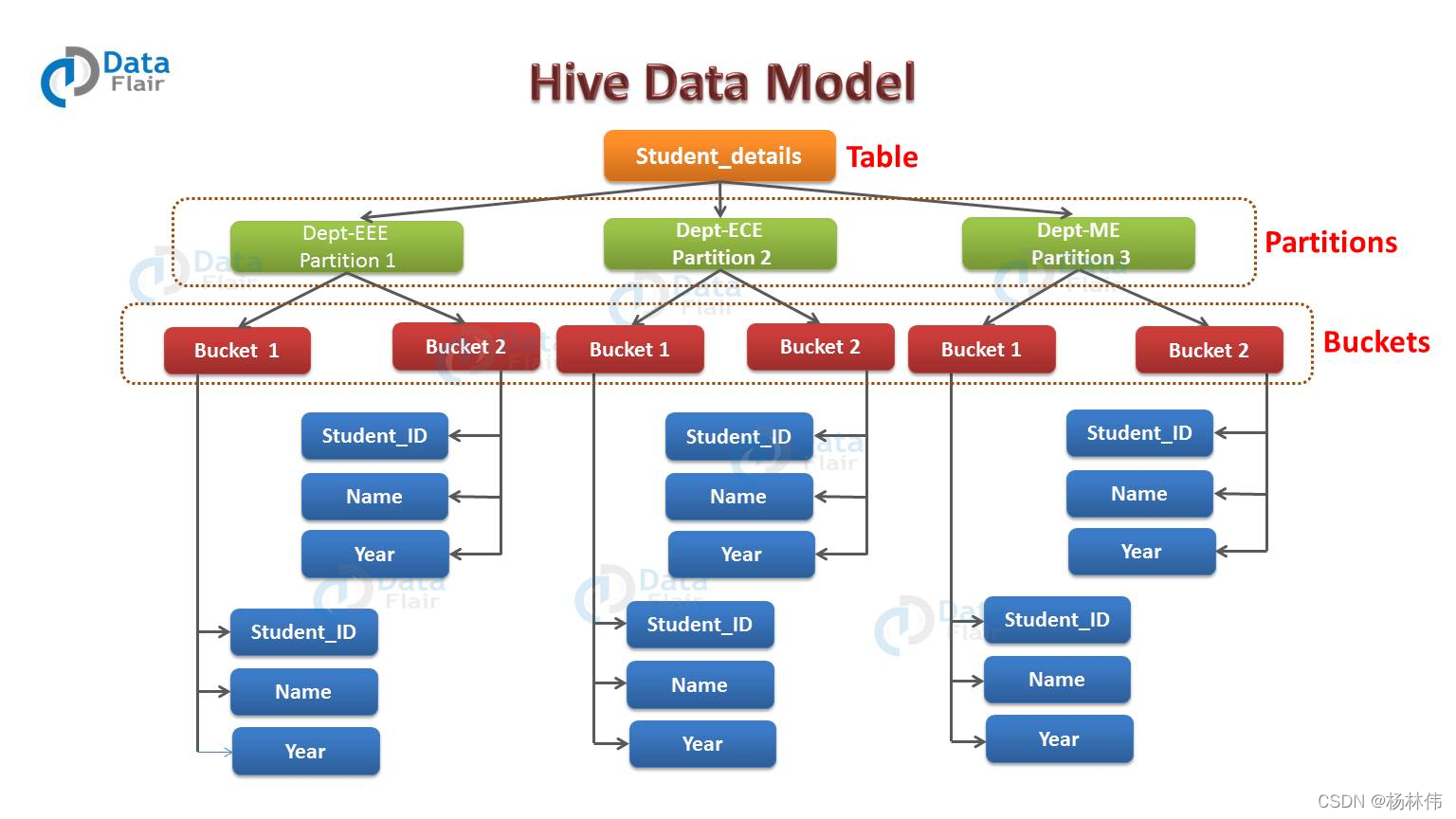
如上圖所示,假如你有一個存盤學生資訊的表,表名為 student_details,列分別是 student_id,name,department,year 等,現在,如果你想基于 department列對資料進行磁區,那么屬于同一個 department的學生將會被分在同一個磁區里面(在物理上,一個磁區其實就是表目錄下的一個子目錄),
假如所有 department = EEE 的學生資料被存盤在 /user/hive/warehouse/student_details/department=EEE 目錄下,那么查詢 department 為 EEE 的學生資訊,只需要查詢 EEE 目錄下的資料即可,不需要全表掃描,這樣查詢的效率就比較高,
而在真實生產環境中,你需要處理的資料可能會有幾百
TB,如果不磁區,在你只需要表的其中一小部分資料的時候,你不得不走全表掃描,這樣的查詢將會非常慢而且浪費資源,可能95%的資料跟你的查詢陳述句并沒有關系,
2.4 Bucket分桶
Bucket通描述:
hive可以對每一個表或者是磁區,進一步組織成桶,也就是說桶是更為細粒度的資料范圍劃分,hive是針對表的某一列進行分桶,hive采用對表的列值進行哈希計算,然后除以桶的個數求余的方式決定該條記錄存放在哪個桶中(分桶的好處是可以獲得更高的查詢處理效率,使取樣更高效),
要使用hive的分桶功能,首先需要打開hive對桶的控制:
set hive.enforce.bucketing=true;
分桶表創建命令:
CREATE TABLE table_name
PARTITIONED BY (partition1 data_type, partition2 data_type,….)
CLUSTERED BY (column_name1, column_name2, …)
SORTED BY (column_name [ASC|DESC], …)]
INTO num_buckets BUCKETS;
每個桶只是表目錄或者磁區目錄下的一個檔案,如果表不是磁區表,那么桶檔案會存盤在表目錄下,如果表是磁區表,那么桶檔案會存盤在磁區目錄下,所以你可以選擇把磁區分成 n 個桶,那么每個磁區目錄下就會有 n 個檔案,
舉例:從2.3.1 Partition磁區例子圖可以看到,每個磁區有 2 個桶,因此每個磁區就會有 2 個檔案,每個檔案將會存盤該磁區下的資料,
2.4.1 分桶特性
資料分桶原理是基于對分桶列做哈希計算,然后對哈希的結果和分桶數取模,分桶特性如下:
- 哈希函式取決于分桶列的型別,
- 具有相同分桶列的記錄將始終存盤在同一個桶中,
- 使用
clustered by將表分成桶, - 通常,在表目錄中,每個桶只是一個檔案,并且桶的編號是從 1 開始的,
- 可以先磁區再分桶,也可以直接分桶,
- 此外,分桶表創建的資料檔案大小幾乎是一樣的,
2.4.2 分桶好處
- 與非分桶表相比,分桶表提供了高效采樣,通過采樣,我們可以嘗試對一小部分資料進行查詢,以便在原始資料集非常龐大時進行測驗和除錯;
- 由于資料檔案的大小是幾乎一樣的,
map端的join在分桶表上執行的速度會比磁區表快很多,在做map端join時,處理左側表的map知道要匹配的右表的行在相關的桶中,因此只需要檢索該桶即可; - 分桶表查詢速度快于非分桶表;
- 分桶的還提供了靈活性,可以使每個桶中的記錄按一列或多列進行排序, 這使得
map端join更加高效,因為每個桶之間的join變為更加高效的合并排序(merge-sort),
2.5 磁區與分桶的區別
磁區與分桶的區別:
- 磁區和分桶最大的區別就是分桶隨機分割資料庫,磁區是非隨機分割資料庫;
- 磁區是水平劃分,表的部分列的集合,可以為頻繁使用的資料建立磁區,這樣查找磁區中的資料時就不需要掃描全表,這對于提高查找效率很有幫助;
- 分桶是垂直劃分,桶是通過對指定列進行哈希計算來實作的,通過哈希值將一個列名下的資料切分為一組桶,并使每個桶對應于該列名下的一個存盤檔案;
(hive使用對分桶所用的值進行hash,并用hash結果除以桶的個數做取余運算的方式來分桶,保證了每個桶中都有資料,但每個桶中的資料條數不一定相等); - 分桶是存盤在檔案中,磁區是存放在檔案夾中,分桶要比磁區查詢效率高,
03 文末
本文主要講解了Hive的四種資料模型( DataBase資料庫、Table表、Partition磁區、Bucket桶),如有疑問的童鞋歡迎評論區留言,謝謝閱讀,本文完!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/431064.html
標籤:其他