作者:志敏,徙遠
回顧2021年,云原生領域有哪些重要意義的事件?
1. 基于容器的分布式云管理加速落地:
2021年5月阿里云峰會上,阿里云發布了一云多形態的部署方式,基于飛天架構的一朵云可以全面覆寫從核心地域到客戶資料中心的各種計算場景,為客戶提供低成本、低延遲、本地化的公共云產品,
在一云多形態發布之前,阿里云容器服務在 2019 年云棲大會上發布了云下Kubernetes 注冊集群能力,支持統一納管云上云下不同 Kubernetes 集群,2021年,阿里云容器服務進一步全面升級了中心云、本地云、邊緣云容器集群的統一管理,能夠將成熟的云原生可觀測、安全防護能力部署到用戶環境,更可以將云端先進的中間件、資料分析和 AI 能力下沉到本地,滿足客戶對于產品豐富度以及資料管控的需求,加速業務創新,并依托強大的彈性算力,通過托管彈性節點,企業可以按需從本地擴容到云端,實作秒級伸縮,從容應對周期性或突發業務流量高峰,

截至 2021 年,基于 Kubernetes 來屏蔽異構環境的差異,搭建分布式云架構已經成為企業和云廠商的共識,
2. Knative1.0正式發布:
Knative 作為一款基于 Kubernetes 之上的開源 Serverless 編排框架,提供面向 Kubernetes 標準化 API 進行 Serverless 應用編排能力,Knative 支持諸多特性:基于流量的自動彈性、灰度發布、多版本管理、縮容到0、事件驅動 Eventing等,根據 CNCF 2020 中國云原生調查報告,Knative 已經成為 Kubernetes 上安裝 Serverless 的首選,
2021 年 11 月,Knative 發布了 1.0 版本,同月 Google 宣布將 Knative 捐贈給云原生計算基金會 (CNCF),阿里云提供了 Knative 的托管,并結合阿里云基礎設施提供了比如冷啟動優化、基于預測的智能彈性等增強,實作了社區標準和云服務優勢的深度整合,
2021年容器技術取得了哪些突破?背后是解決什么問題?
在2021年,企業對容器的擁抱更加積極,對容器核心技術的啟動效率、資源開銷、調度效率都有了更高的要求,阿里云容器團隊也支持了新一代的容器架構升級,通過對容器、裸金屬、作業系統等全堆疊優化,持續挖掘容器的潛能,
高效調度: 全新升級 Cybernetes 調度器,支持對多架構神龍的 NUMA 負載感知、拓撲調度和細粒度的資源隔離和混部,提升應用性能30%,此外,在調度器上做了大量端到端優化,在1000節點規模集群中,可以提供20000Pods/min以上的調度速度,確保在線服務和離線任務都能高效地運行在 K8s 上;

高性能容器網路: 最新一代的阿里云容器網路 Terway 3.0,一方面通過神龍芯片 offload 虛擬化網路開銷,一方面在 OS 內核中通過 eBPF 實作容器 Service 轉發和網路策略,真正實作零損耗,高性能,

容器優化 OS: 面向容器場景,推出輕量、快速、安全、鏡像原子管理的容器優化作業系統 LifseaOS,相比傳統作業系統軟體包數量減少 60%,鏡像大小減少 70%,OS 首次啟動從傳統 OS 的 1min 以上下降到了 2s 左右,支持鏡像只讀和 ostree 技術,將 OS 鏡像版本化管理,更新作業系統上的軟體包、或者固化的配置時,以整個鏡像為粒度進行更新,

高密部署極致彈性: 基于阿里云安全沙箱容器 2.0,優化沙箱容器內的資源開銷,最小可達 30M 左右,實作了在單一物理機上的 2000 實體的高密服務能力,同時通過管控鏈路的縮短以及組件的精簡,并輔以對沙箱記憶體分配流程、host cgroup 管理流程和 IO 鏈路的優化,實作了 Serverless 場景的 6 秒 3000 彈性容器實體的彈性能力,
企業對容器的應用規模呈現什么趨勢?核心訴求點是什么?
隨著企業進一步的大規模使用容器,企業內部使用容器的范圍也從開始的在線業務逐漸向 AI 大資料演進,對 GPU 等異構資源的管理和 AI 任務和作業管理的需求也越來越多,同時,開發人員在考慮如何通過云原生技術,以統一架構、統一技術堆疊支撐更多型別的作業負載,以避免不同負載,使用不同架構和技術,帶來“煙囪”系統、重復投入和運維負擔,
深度學習、AI任務,正是社區尋求云原生技術支撐的重要作業負載之一, 在阿里云,我們提出“云原生AI”的定義、技術全景圖和參考架構,以期為這個全新技術領域,提供可落地的最佳實踐,并推出了云原生 AI 套件,通過資料計算類任務的編排、管理,以及對各種異構計算資源的容器化統一調度和運維,顯著提高 GPU/NPU 等異構計算集群的資源使用效率和 AI 工程交付速度,
針對 AI 計算類任務的特性,在 Kubernetes 核心 Scheduler Framework 的基礎上進行了大量擴展和增強,提供了支持 Gang Scheduling、Capacity Scheduling、Binpack 等任務調度策略,提升集群的資源利用率,并與 K8s 社區積極合作,持續推動 K8s 調度器框架演進,保證了 K8s 調度器通過標準的 plugin 機制,可按需擴展出各種調度策略,來滿足各種作業負載的調度需求,同時避免了類似其他 custom scheduler 對集群資源分配帶來資料不一致的風險,
支持 GPU 共享調度和拓撲感知調度,NPU/FPGA 等定制芯片調度,提升 AI 任務的資源利用率,同時通過阿里云自研 cGPU 方案,在無需修改應用容器的前提下,提供了 GPU 顯存和算力的隔離,
在計算和存盤分離的大背景驅動下,基于 Fluid 提供一層高效便捷的資料抽象,將資料從存盤抽象出來,通過資料親和性調度和分布式快取引擎加速,實作資料和計算之間的融合,從而加速計算對資料的訪問,并支持以 Alluxio 和 JindoFS 為快取引擎,
支持 GPU 等異構資源的彈性伸縮,通過智能的削峰填谷,避免不必要的云上資源消費,同時支持彈性模型訓練和模型推理,
企業對容器的應用提出了哪些新的需求?
隨著5G、IoT、音視頻、直播、CDN 等行業和業務的發展,我們看到一個行業趨勢:企業開始將更多的算力和業務下沉到距離資料源或者終端用戶更近的地方,從而來獲得很好的回應時間和降低成本,
這明顯區別傳統的中心式的云計算模式,從而延伸出邊緣計算,邊緣計算作為云計算的延伸,將被廣泛應用于混合云/分布式云、IoT 等場景,它需要未來的基礎設施能夠去中心化、邊緣設施自治、以及強大的邊緣云端托管能力,云原生架構的新邊界——“云邊端一體“的IT基礎設施開始出現在整個行業面前,而這也是企業對云原生技術、容器化應用在新場景落地的需求,
邊緣計算云原生架構和技術體系需要解決以下問題:云邊運維協同、彈性協同、網路協同、邊緣IoT設備管理、輕量化、成本優化等,針對云邊端一體的新需求,在2021年,OpenYurt 社區(CNCF Sandbox專案)也發布了 0.4、0.5 等版本,持續優化邊緣容器的 IoT 設備管理、資源開銷、網路協同等能力,
從技術維度看,容器發展亟待解決的主要問題是什么?
隨著企業的 K8s 應用大規模使用和落地,如何持續提升 K8s 集群的整體穩定性是核心挑戰,K8s 集群作為一個分布式系統存在高度復雜性,在應用、基礎設施、部署程序中任何一個地方的問題,都可能導致業務系統的故障,這不僅需要應用 K8s 的企業有對云原生容器技術的高可用體系保障,還需要企業云原生運維體系理念的整體升級,
以 SLO 定義驅動可觀測性體系: 針對 K8s 的容量規模建設了性能壓測常態化能力,必須對 K8s 集群之上的業務場景能夠對包括節點數、POD 數、Job 數,核心 Verb 的 QPS 數有明確了解,結合業務的真實場景進行 SLO 的梳理,持續關注請求量,延遲、錯誤數、飽和度等黃金指標,
常態化的故障演練和混沌測驗: 比如結合混沌工程理念的 ChaosBlade,對容器集群的不同風險動作,注入不同的例外案例,從VM、K8s、網路、存盤到應用的全方面故障模擬,
精細化的流控風控: 針對壓測和故障演練程序中發現的例外進行防護能力建設,可以借助 Kubernetes 在1.20 beta了 API 優先級和公平性的細粒度流控策略,阿里云容器服務也內置了自研的 UserAgentLimiter 進一步保障 K8s,
除了全域高可用能力的建設外,需要有SRE團隊平臺化能力的建設:
打造統一的K8s運維服務界面,沉淀運維和可觀測能力,讓每個 SRE/DEV 能夠無差別的OnCAll 或支持,有 2 個子目標:1)盡量避免發生問題;2)盡快發現和定位問題,以及盡快恢復問題,建設全域高可用應急體系,
重實踐和演練: 基于場景進行實踐,知行合一,從知觸發,到行完成是一個倍訓,然后不斷通過知行的一個回圈程序,以賽帶練,比如雙十一大促,限電,斷網等極端場景,穩定性建設,需要針對極端場景進行,容量的規劃和壓測,組件治理等都是需要一些特殊的場景催生,有了賽場,要打好這場仗,就需要通力協作,就會不斷形成一個大的協同協作機制,
固化知識,沉淀 playbook: 這件事是要打造標準,在做標準的程序中,有的先一步落到系統里面,有的沉淀到 playbook 里面,有的體現到流程里面,流程一定是我們優秀工程師和SRE的最佳實踐,系統、playbook、流程都是不斷轉化的,相輔相成的,
容器技術在2022年的發力點是什么?容器的未來有哪些想象空間?
日前,國際權威咨詢機構 Forrester 發布全球容器能力報告《 The Forrester WaveTM: PublicCloud Container Platforms, Q1 2022 》,報告顯示,阿里云是國內唯一進入該報告“領導者”象限的服務商,且容器產品綜合能力評分最高,
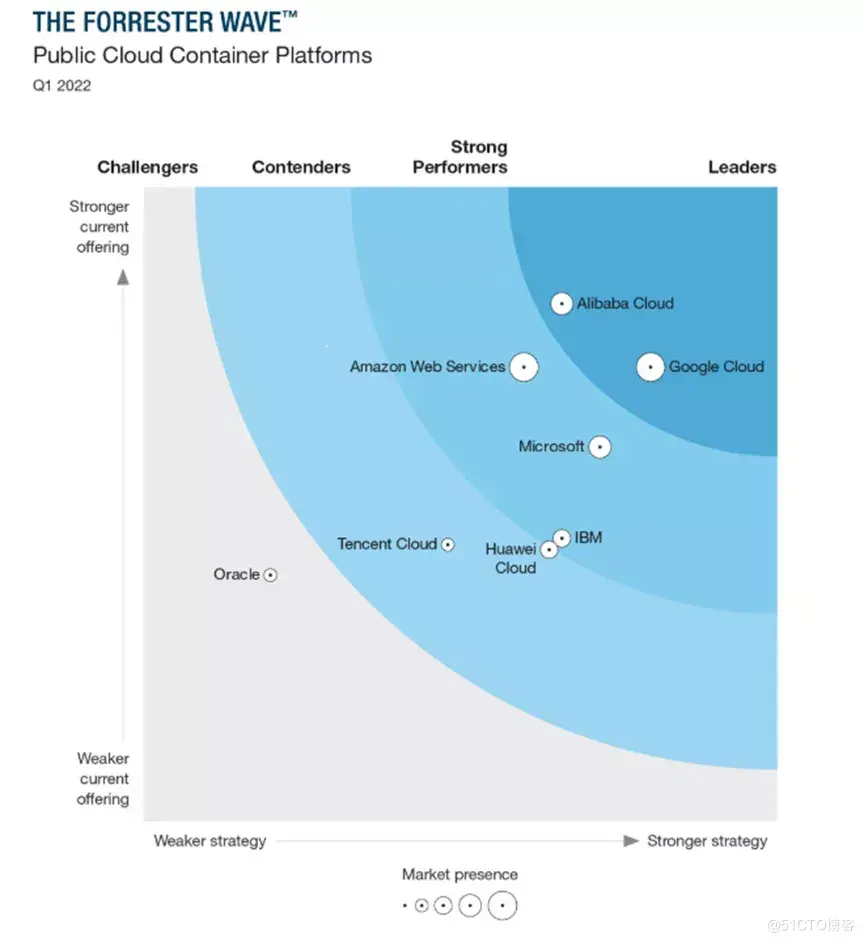
 阿里云容器技術在2022年會重點關注幾個方向:
阿里云容器技術在2022年會重點關注幾個方向:
綠色低碳: 持續發揮容器技術的高效調度和彈性能力,幫助企業提升整體的IT效率,結合最新的節能資料中心技術、新一代神龍架構、自研芯片、容器優化作業系統實作上下游的全堆疊優化,提升應用的整體性能和調度效率,以資料驅動的方式,根據應用運行時資源畫像實作智能化調度和實時調整,簡化應用資源配置的復雜性,進一步提升應用的混合部署,降低資源成本,助力企業整體 的 FinOps 管理,
AI 工程化: AI 要成為企業生產力,就必須以工程化的技術來解決模型開發、部署、管理、預測、推理等全鏈路生命周期管理的問題,我們發現,AI 工程化領域有三大亟待推進的事情:資料和算力的云原生化,調度和編程范式的規模化,開發和服務的標準化貧訓化, 這些需要持續優化 GPU 等異構架構的高效調度,結合分布式快取、分布式資料集加速等技術,結合 KubeflowArena 的AI任務流水線和生命周期管理,全面升級AI工程化能力,
智能自治: 通過引入更多的資料化智能化手段,推動容器的智能化運維體系,降低企業對復雜容器集群和應用的管理,增強 K8s master、組件和節點的自愈自恢復能力,提供更加友好的例外診斷、K8s 配置推薦、彈性預測等能力.
安全合規: 全面推進 DevOps 向 DevSecOps 演進,面向 Helm、Operator 等 OCI Artifacts 優化整體的安全定義、簽名、同步和三方交付;加固容器的南北向和東西向的網路隔離和治理,推進零信任的鏈路安全;進一步提升安全容器和機密計算容器的性能和可觀測能力,
點擊??此處???,進入阿里云 ACK Anywhere 官網,?
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/431073.html
標籤:其他