
前言
什么是腦裂問題
ES在主節點上產生分歧,產生多個主節點,從而使集群分裂,使得集群處于例外狀態,這個現象叫做腦裂,腦裂問題其實就是同一個集群的不同節點對于整個集群的狀態有不同的理解,導致操作錯亂,類似于精神分裂
舉個栗子:
下圖是一個有兩個節點的elasticsearch集群,集群維護一個單個索引并有一個分片和一個復制節點,節點1在啟動時被選舉為主節點并保存主分片(在下面的schema里標記為0P),而節點2保存復制分片(0R)
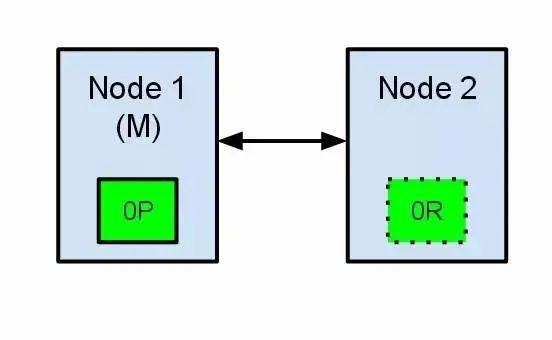
這時如果在兩個節點之間的通訊中斷了(網路問題或只是因為其中一個節點無回應(例如stop-the-world垃圾回收,es行程被占用,記憶體溢位等))
此時,兩個節點都會覺得對方掛了,
對于節點1來說,他自己就是master,所以不需要做什么
對于節點2,因為此時集群就只有他一個節點,當他選舉一個節點當master,那就只會是他自己,在elasticsearch集群,是由主節點來決定將分片平均的分布到節點上的,節點2保存的是復制分片,但它相信主節點不可用了,所以它會自動提升復制節點為主節點,
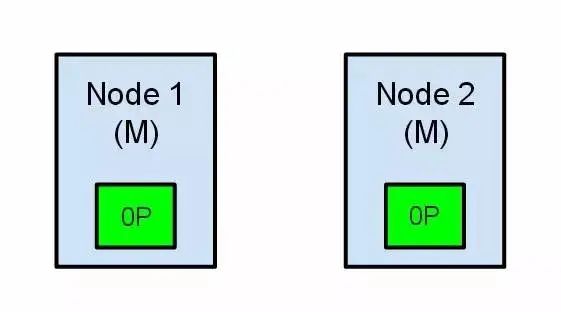
那么此時,整個es集群就會出現兩個master,打在節點1上的索引請求會將索引資料分配在主節點,同時打在節點2的請求會將索引資料放在分片上,
也就是說,如果資料添加到es集群,就會出現分散到兩個分片中,分片的兩份資料分開了,不做一個全量的重索引很難對它們進行重排序,查詢集群資料的請求都會成功完成,但是請求回傳的結果是不同的,訪問不同的節點,會發現集群狀態不一樣,可用節點數不一樣,而且結果資料也會不一樣
解決思路
腦裂主要是在master節點掛掉或子節點聯系不上master時出現,那么我們就要盡可能保證不會出現節點掛掉的情況
1、網路問題
保證網路穩定,及時預警,重啟集群
2、master節點負載過大
避免master節點因為作業負載過大出現回應中斷從而引發腦裂
可以在jvm.options中增加堆記憶體大小或者修改合適的GC處理器
-Xms4g
-Xmx4g
## G1GC Configuration
# to use G1GC, uncomment the next two lines and update the version on the
# following three lines to your version of the JDK
# 8-13:-XX:-UseConcMarkSweepGC
# 8-13:-XX:-UseCMSInitiatingOccupancyOnly
14-:-XX:+UseG1GC也可以對集群的節點做讀寫分離,master節點專門做集群master管理,master節點配置
node.master: true
node.data: false同時設定一批data節點負責存盤資料和處理請求
node.master: false
node.data: true如果確實還是頂不住,那么就可以再設定一批client節點只負責處理用戶請求,實作請求轉發,負載均衡等功能,讓data節點只負責存盤資料
node.master: false
node.data: false3、優化方法方面
由于elasticsearch6.X和elasticsearch7.X配置出入較大,所以這部分的優化分為兩種
elasticsearch6.X:
discovery.zen.ping.multicast.enabled: falsediscovery.zen.ping.unicast.hosts: ["master1", "master2", "master3"]discovery.zen.ping_timeout:5discovery.zen.minimum_master_nodes:2
discoveryzen.ping.multicast.enabled
將data節點的默認的master發現方式由multicast(多播)修改為unicast(單播),使新加入的節點快速確定master位置
discovery.zen.ping.unicast.hosts
提供其他 Elasticsearch 服務節點的單點廣播發現功能,配置集群中基于主機 TCP 埠的其他 Elasticsearch 服務串列
discovery.zen.ping_timeout
節點等待回應的時間,默認值是3秒,增加這個值,會增加節點等待回應的時間,從一定程度上會減少誤判
discovery.zen.minimum_master_nodes
一個節點需要看到的具有master節點資格的最小數量,然后才能在集群中做操作,官方的推薦值是(N/2)+1,其中N是具有master資格的節點的數量,設定這個引數后,只有足夠的master候選節點時,才可以選舉出一個master
elasticsearch7.X:
官網檔案中有這么一段話
If the cluster is running with a completely default configuration then it will automatically bootstrap a cluster based on the nodes that could be discovered to be running on the same host within a short time after startup. This means that by default it is possible to start up several nodes on a single machine and have them automatically form a cluster which is very useful for development environments and experimentation. However, since nodes may not always successfully discover each other quickly enough this automatic bootstrapping cannot be relied up
譯:如果集群以完全默認的配置運行,那么它將在啟動后的短時間內根據可以發現在同一主機上運行的節點自動引導集群,這意味著默認情況下,可以在一臺機器上啟動多個節點并讓它們自動形成一個集群,這對于開發環境和實驗非常有用,但是,由于節點可能并不總是足夠快地成功發現彼此,因此不能依賴這種自動引導,也不能在生產部署中使用,
所以需要配置如下引數,讓集群內的節點更快的互相發現
cluster.initial_master_nodes: ["node-1", "node-2"]discovery.seed_hosts: ["host1", "host2"]
discovery.seed_hosts
在沒有任何網路配置的情況下,Elasticsearch將直接系結到可用的環回地址,并掃描本地埠9300到9305,以連接到同一服務器上運行的其他節點,集群中的節點能夠發現彼此并選擇一個主節點
cluster.initial_master_nodes
使用一組初始的符合主條件的節點引導集群
腦裂修復
當elasticsearch集群重新選舉出一個master節點時,由于之前索引的兩份拷貝已經不一樣了,elasticsearch會認為選出來的master保留的分片是“主拷貝”并將這份拷貝推送給集群中的其他節點,
這種情況就很容易導致正確的節點上的資料被選舉出來的master節點的錯誤資料覆寫掉,造成資料丟失,
所以需要
1、給所有資料重新索引
POST _reindex{"source": {"index": "twitter"},"dest": {"index": "new_twitter","op_type": "create"}}
2、逐個關閉節點并備份資料,分析比對資料是否是最新的,如果是保存的資料是最新的,啟動它并且讓它被選為主節點,然后就可以啟動集群的其他節點了
最后
腦裂問題很難被徹底解決,在elasticsearch的問題串列里仍然有關于這個的問題, 描述了在一個極端情況下正確設定了minimum_master_nodes的引數時仍然產生了腦裂問題,elasticsearch專案組正在致力于開發一個選主演算法的更好的實作,但如果你已經在運行elasticsearch集群了那么你需要知道這個潛在的問題,

掃碼關注我的微信公眾號:Java架構師進階編程 獲取最新面試題,電子書
專注分享Java技術干貨,包括JVM、SpringBoot、SpringCloud、資料庫、架構設計、面試題、電子書等,期待你的關注!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/431394.html
標籤:其他
上一篇:如何創建一個適合作業表大小且視圖始終與底部對齊的android底部作業表?
下一篇:安全最佳實踐+Klocwork