關于BERT
作者:白鹿(花名)
宣告:以下介紹均以bert_base為基礎進行介紹;
網路結構
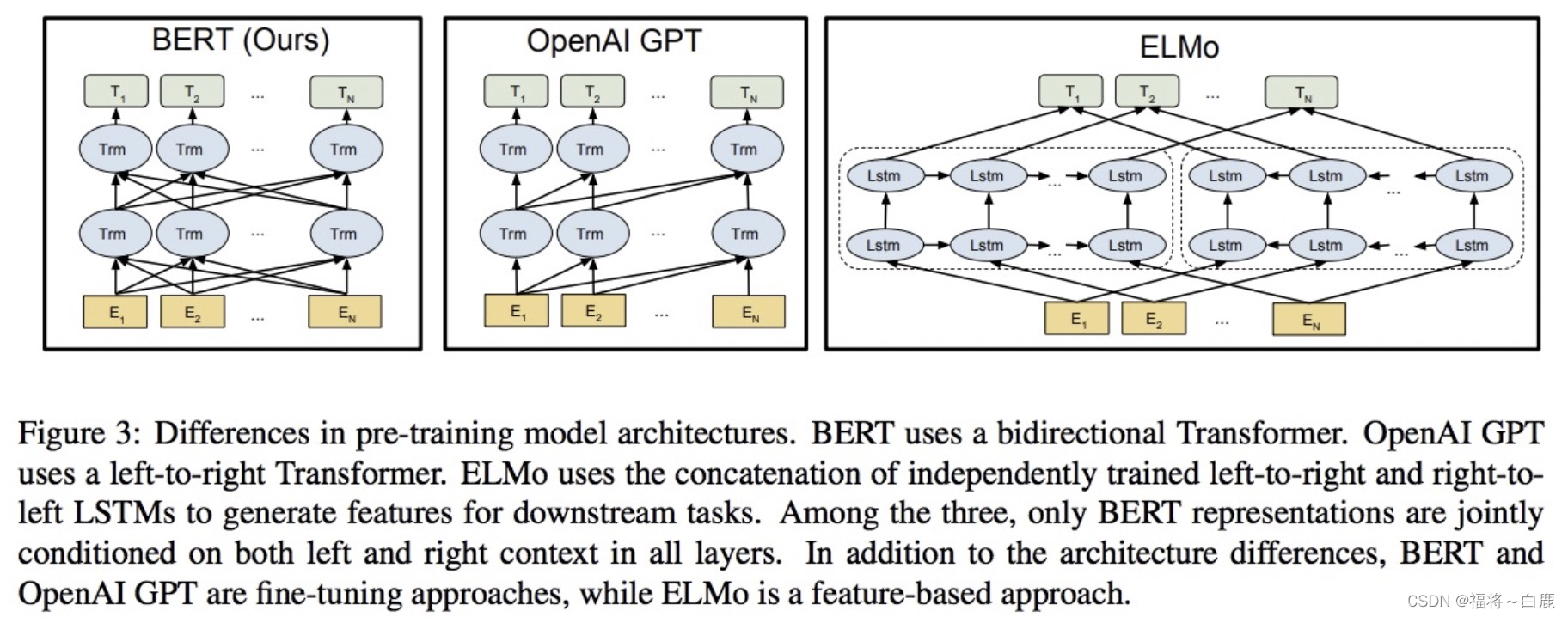
- 從上面的架構圖中可以看到, 宏觀上BERT分三個主要模塊.
- 最底層黃色標記的Embedding模塊.
- 中間層藍色標記的Transformer模塊.
- 最上層綠色標記的預微調模塊.
Embedding模塊:
BERT中的該模塊是由三種Embedding共同組成而成, 如下圖
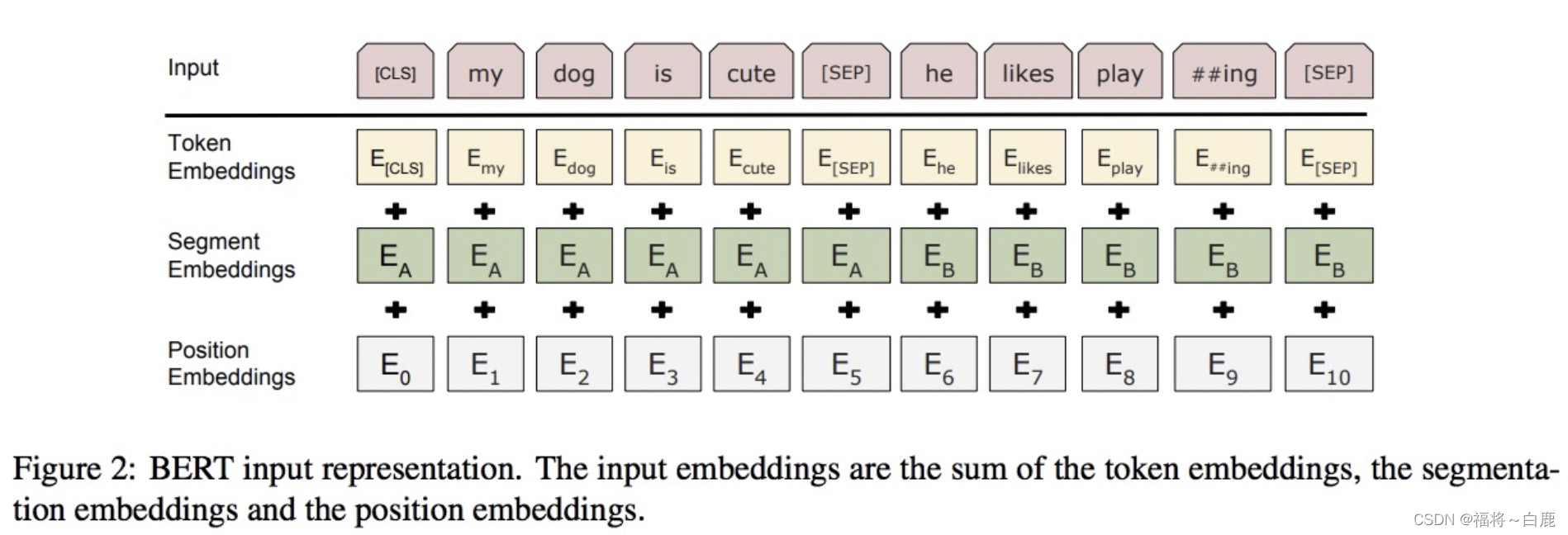
Token Embeddings 是詞嵌入張量, 以[CLS]為起始位標志,[SEP]為結束位標識, 用于之后的分類任務.
Segment Embeddings 是句子分段嵌入張量, 是為了服務后續的兩個句子為輸入的預訓練任務.
Position Embeddings 是位置編碼張量, 此處注意和傳統的Transformer不同, 不是三角函式計算的固定位置編碼, 而是通過學習得出來的.
整個Embedding模塊的輸出張量就是這3個張量的直接加和結果.
雙向Transformer模塊:
BERT中只使用了經典Transformer架構中的Encoder部分, 完全舍棄了Decoder部分. 而兩大預訓練任務也集中體現在訓練Transformer模塊中.
Base:12
Large:24
預微調模塊:
經過中間層Transformer的處理后, BERT的最后一層根據任務的不同需求而做不同的調整即可.
比如對于sequence-level的分類任務, BERT直接取第一個[CLS] token 的final hidden state, 再加一層全連接層后進行softmax來預測最終的標簽.
- 對于不同的任務, 微調都集中在預微調模塊, 幾種重要的NLP微調任務架構圖展示如下
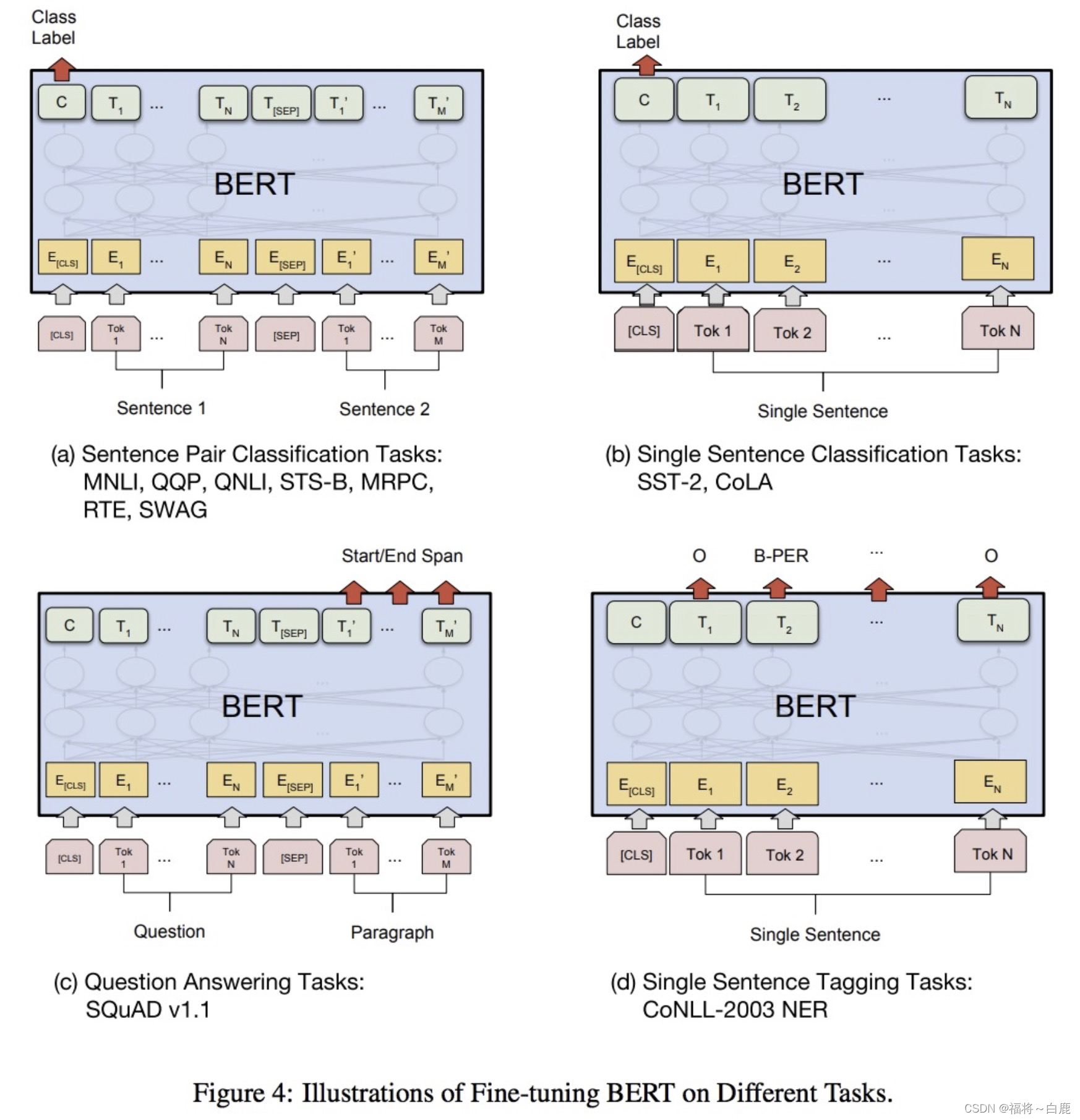
從上圖中可以發現, 在面對特定任務時, 只需要對預微調層進行微調, 就可以利用Transformer強大的注意力機制來模擬很多下游任務, 并得到SOTA的結果. (句子對關系判斷, 單文本主題分類, 問答任務(QA), 單句貼標簽(NER))
BERT的預訓練任務介紹
BERT包含兩個預訓練任務:
任務一: Masked LM (帶mask的語言模型訓練)
任務二: Next Sentence Prediction (下一句話預測任務)
- 任務一: Masked LM (帶mask的語言模型訓練)

關于傳統的語言模型訓練, 都是采用left-to-right, 或者left-to-right + right-to-left結合的方式, 但這種單向方式或者拼接的方式提取特征的能力有限. 為此BERT提出一個深度雙向表達模型(deep bidirectional representation). 即采用MASK任務來訓練模型.
1: 在原始訓練文本中, 隨機的抽取15%的token作為參與MASK任務的物件.
2: 在這些被選中的token中, 資料生成器并不是把它們全部變成[MASK], 而是有下列3種情況.
2.1: 在80%的概率下, 用[MASK]標記替換該token, 比如my dog is hairy -> my dog is [MASK]
2.2: 在10%的概率下, 用一個隨機的單詞替換token, 比如my dog is hairy -> my dog is apple
2.3: 在10%的概率下, 保持該token不變, 比如my dog is hairy -> my dog is hairy
3: 個人想法: 模型在訓練的程序中, 并不知道它將要預測哪些單詞? 哪些單詞是原始的樣子? 哪些單詞被遮掩成了[MASK]? 哪些單詞被替換成了其他單詞? 正是在這樣一種高度不確定的情況下, 反倒逼著模型快速學習該token的分布式背景關系的語意, 盡最大努力學習原始語言說話的樣子. 同時因為原始文本中只有15%的token參與了MASK操作, 并不會破壞原語言的表達能力和語言規則.
- 任務二: Next Sentence Prediction (下一句話預測任務)
在NLP中有一類重要的問題比如QA(Quention-Answer)需要模型能夠很好的理解兩個句子之間的關系, 從而需要在模型的訓練中引入對應的任務. 在BERT中引入的就是Next Sentence Prediction任務. 采用的方式是輸入句子對(A, B), 模型來預測句子B是不是句子A的真實的下一句話.
1: 所有參與任務訓練的陳述句都被選中作為句子A.(此處其實是引入了是亂數來控制正負例的構造比例,樣本量足夠大的時候基本可以達到正負例樣本均衡狀態)
1.1: 其中50%的B是原始文本中真實跟隨A的下一句話. (標記為IsNext, 代表正樣本)
1.2: 其中50%的B是原始文本中隨機抽取的一句話. (標記為NotNext, 代表負樣本)
2: 在任務二中, BERT模型可以在測驗集上取得97%-98%的準確率.
Bert細節概括
關于max_senquence_length, (句子對組合長度<=512)

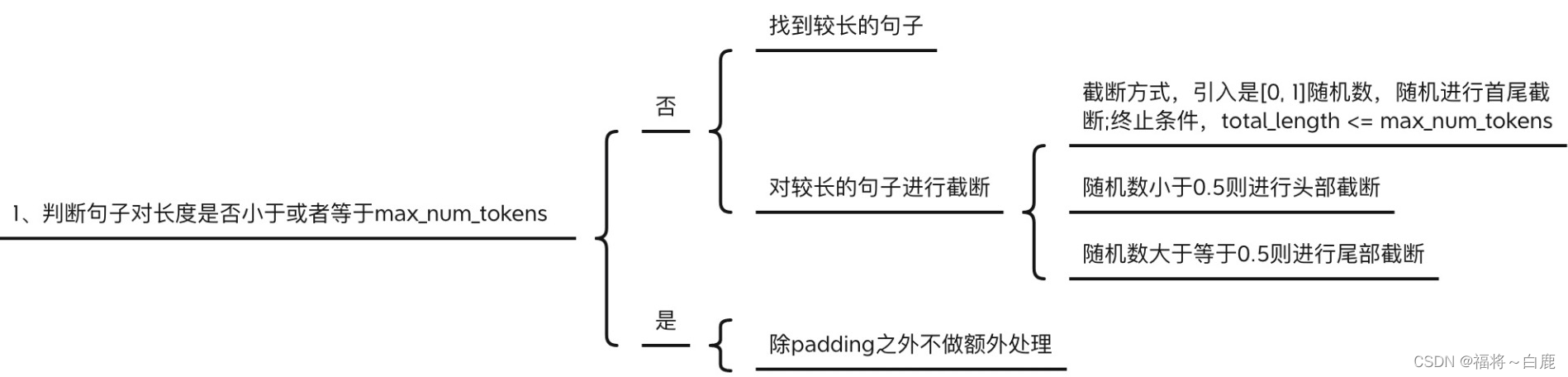
關于句子對max_sentence_length構造
由子詞mask向全詞mask轉變
- 2018年首版bert發布時,mask采用子詞mask
- 2019年5月發布升級版bert,采用全詞mask
Whole Word Masking (wwm),一般翻譯為全詞 Mask 或整詞 Mask,出是 Google 在2019年5月發布的一項升級版的BERT中,主要更改了原預訓練階段的訓練樣本生成策略,簡單來說,原有基于WordPiece的分詞方式會把一個完整的詞切分成若干個子詞,在生成訓練樣本時,這些被分開的子詞會隨機被mask, 在全詞Mask中,如果一個完整的詞的部分WordPiece子詞被 Mask,則同屬該詞的其他部分也會被 Mask,即全詞Mask,
BERT預訓練送入網路的資料格式
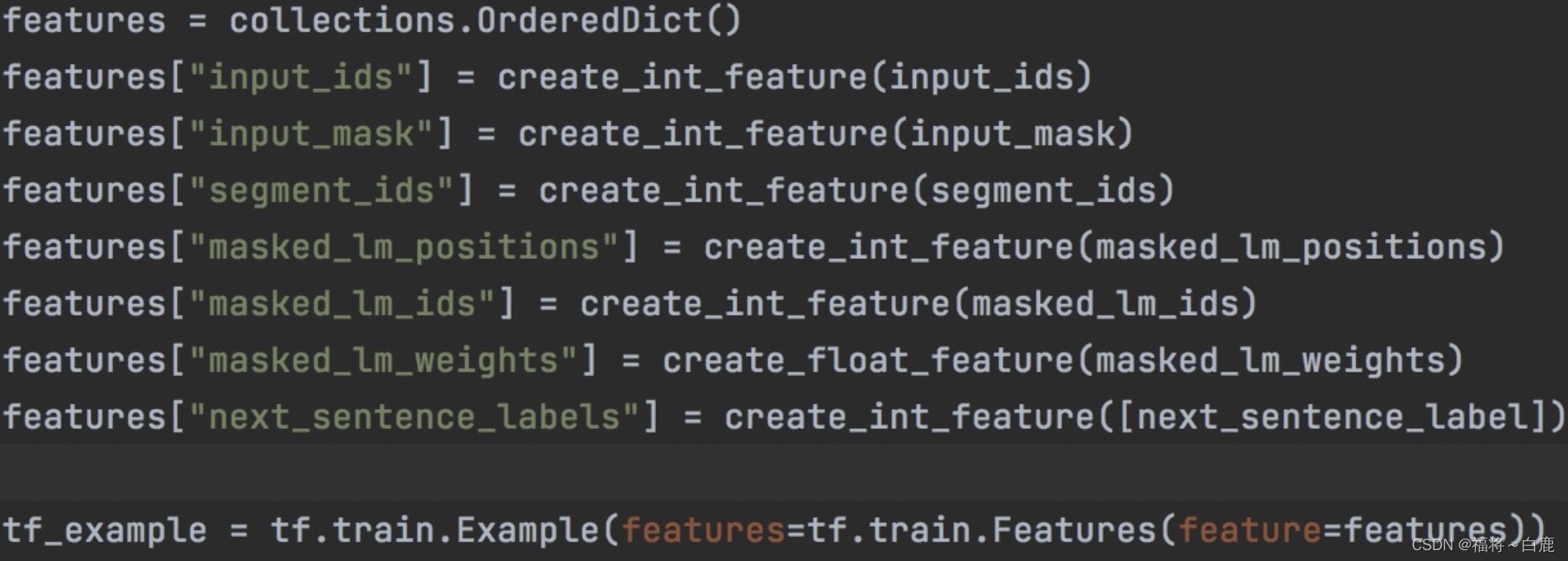
模型微調送入BERT的資料格式

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/431469.html
標籤:AI