flink資料狀態一致性
- 1狀態一致性級別
- 1.1 AT-MOST-ONCE (最多一次):
- 1.2 AT-LEAST-ONCE (至少一次):
- 1.3 EXACTLY-ONCE (精確一次):
- 1.4 分布式快照與至少一次事件傳遞和重復資料洗掉的比較
- 2flink內部實作狀態一致性
- 3 端到端的一致性
- 3.1 Source
- 3.2 Sink
- 3.2.1 冪等寫入
- 3.2.2 事務寫入
- 3.2.2.1 兩階段提交
- 3.2.2.2 flink的兩階段提交
1狀態一致性級別
1.1 AT-MOST-ONCE (最多一次):
- 這本質上是一『盡力而為』的方法,保證資料或事件最多由應用程式中的所有算子處理一次, 這意味著如果資料在被流應用程式完全處理之前發生丟失,則不會進行其他重試或者重新發送,下圖中的例子說明了這種情況,

1.2 AT-LEAST-ONCE (至少一次):
- 應用程式中的所有算子都保證資料或事件至少被處理一次,這通常意味著如果事件在流應用程式完全處理之前丟失,則將從源頭重放或重新傳輸事件,然而,由于事件是可以被重傳的,因此一個事件有時會被處理多次,這就是所謂的至少一次,
下圖的例子描述了這種情況:第一個算子最初未能成功處理事件,然后在重試時成功,接著在第二次重試時也成功了,其實是沒有必要的,
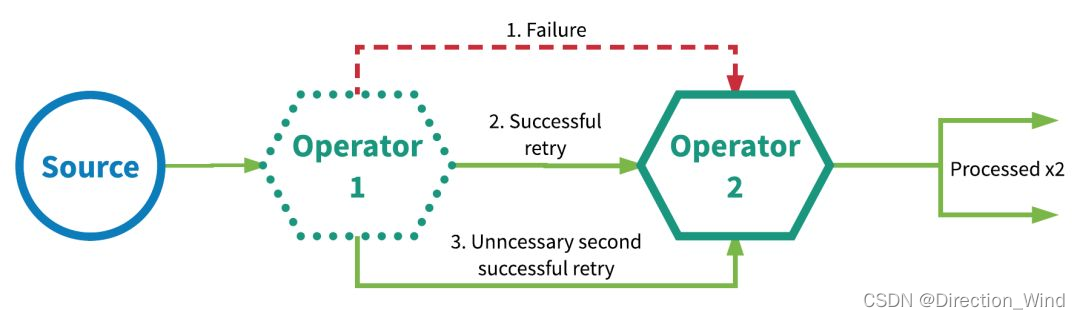
1.3 EXACTLY-ONCE (精確一次):
即使是在各種故障的情況下,流應用程式中的所有算子都保證事件只會被『精確一次』的處理,(也有文章將 Exactly-once 翻譯為:完全一次,恰好一次)
通常使用兩種流行的機制來實作『精確一次』處理語意,
- 分布式快照 / 狀態檢查點
- 至少一次事件傳遞和對重復資料去重
實作『精確一次』的分布式快照/狀態檢查點方法受到 Chandy-Lamport 分布式快照演算法的啟發[1],通過這種機制,流應用程式中每個算子的所有狀態都會定期做 checkpoint,如果是在系統中的任何地方發生失敗,每個算子的所有狀態都回滾到最新的全域一致 checkpoint 點,在回滾期間,將暫停所有處理,源也會重置為與最近 checkpoint 相對應的正確偏移量,整個流應用程式基本上是回到最近一次的一致狀態,然后程式可以從該狀態重新啟動,下圖描述了這種 checkpoint 機制的基礎知識,
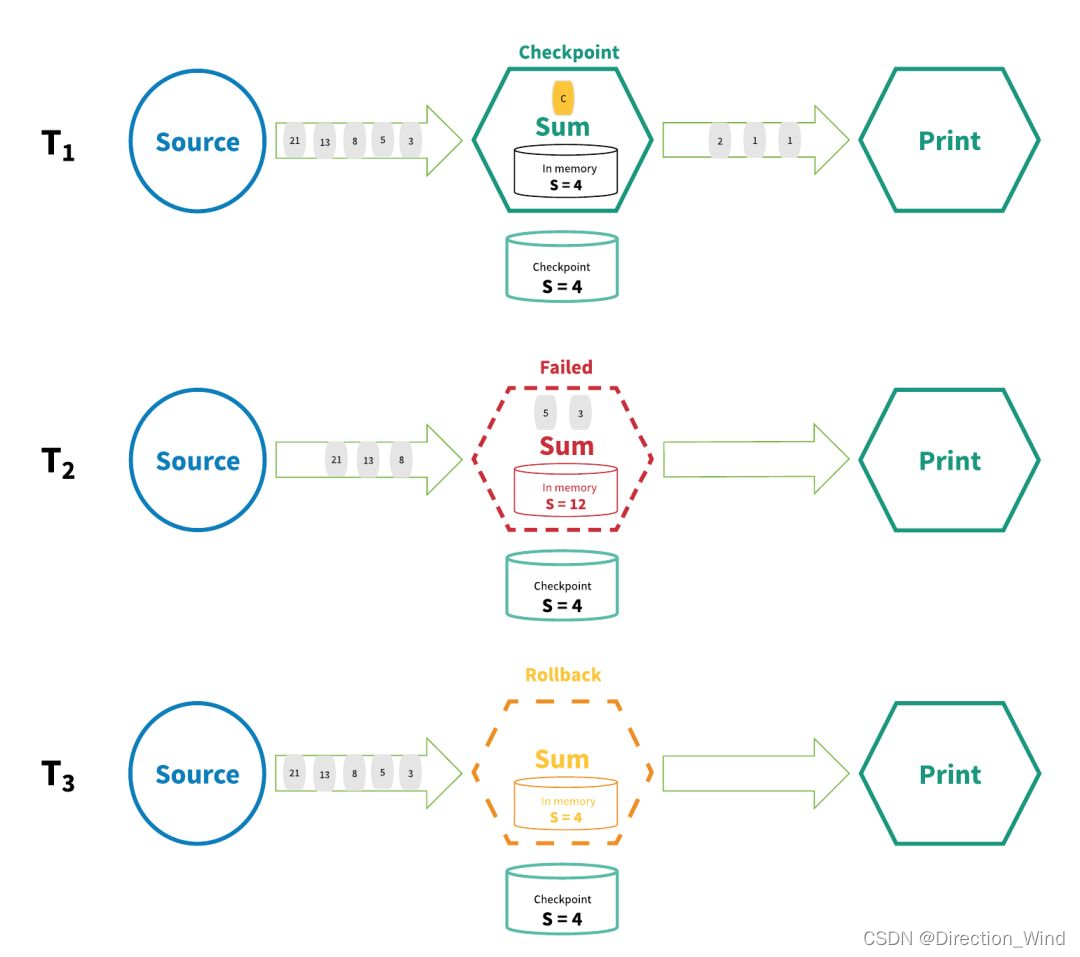
在上圖中,流應用程式在 T1 時間處正常作業,并且做了checkpoint,然而,在時間 T2,算子未能處理輸入的資料,此時,S=4 的狀態值已保存到持久存盤器中,而狀態值 S=12 保存在算子的記憶體中,為了修復這種差異,在時間 T3,處理程式將狀態回滾到 S=4 并“重放”流中的每個連續狀態直到最近,并處理每個資料,最終結果是有些資料已被處理了多次,但這沒關系,因為無論執行了多少次回滾,結果狀態都是相同的,
另一種實作『精確一次』的方法是:在每個算子上實作至少一次事件傳遞和對重復資料去重來,使用此方法的流處理引擎將重放失敗事件,以便在事件進入算子中的用戶定義邏輯之前,進一步嘗試處理并移除每個算子的重復事件,此機制要求為每個算子維護一個事務日志,以跟蹤它已處理的事件,利用這種機制的引擎有 Google 的 MillWheel[2] 和 Apache Kafka Streams,下圖說明了這種機制的要點,
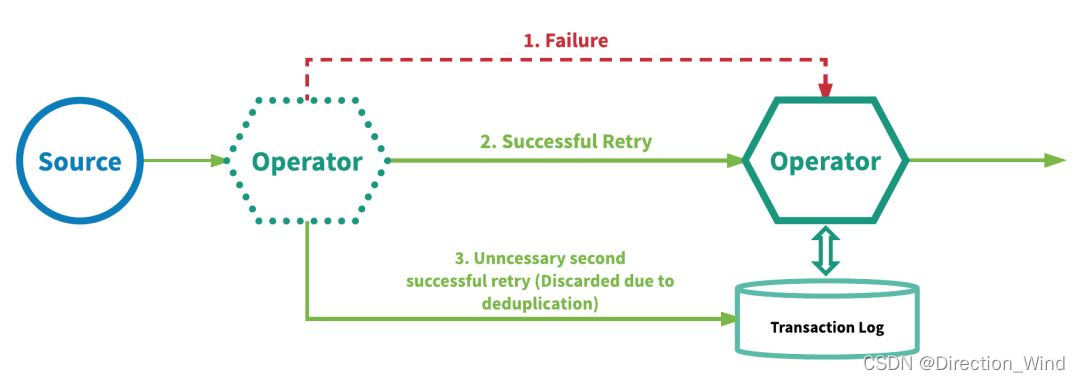
這里所說的的狀態一致性是flink系統內部的狀態,如果要保證端到端,從接受到發出資料都保障一致性,還需要其他系統能力支持,這部分后面說,
絕大多數情況我們會希望exactly-once,但相比at-least-once,exactly-once的性能與速度會相對較慢一點,這是由于checkpoint的機制造成的,
我們主要關注的是精確一致性,所以在這里我們也只講精確一致性相關的概念,
我們所說的flink內的精確一致性,真的是精確的只發送一次資料么?
現在讓我們重新審視『精確一次』處理語意真正對最終用戶的保證,『精確一次』這個術語在描述正好處理一次時會讓人產生誤導,
有些人可能認為『精確一次』描述了事件處理的保證,其中流中的每個事件只被處理一次,實際上,沒有引擎能夠保證正好只處理一次,在面對任意故障時,不可能保證每個算子中的用戶定義邏輯在每個事件中只執行一次,因為用戶代碼被部分執行的可能性是永遠存在的,
那么,當引擎宣告『精確一次』處理語意時,它們能保證什么呢?如果不能保證用戶邏輯只執行一次,那么什么邏輯只執行一次?當引擎宣告『精確一次』處理語意時,它們實際上是在說,它們可以保證引擎管理的狀態更新只提交一次到持久的后端存盤,
上面描述的兩種機制都使用持久的后端存盤作為真實性的來源,可以保存每個算子的狀態并自動向其提交更新,對于機制 1 (分布式快照 / 狀態檢查點),此持久后端狀態用于保存流應用程式的全域一致狀態檢查點(每個算子的檢查點狀態),對于機制 2 (至少一次事件傳遞加上重復資料洗掉),持久后端狀態用于存盤每個算子的狀態以及每個算子的事務日志,該日志跟蹤它已經完全處理的所有事件,
提交狀態或對作為真實來源的持久后端應用更新可以被描述為恰好發生一次,然而,如上所述,計算狀態的更新 / 更改,即處理在事件上執行任意用戶定義邏輯的事件,如果發生故障,則可能不止一次地發生,換句話說,事件的處理可以發生多次,但是該處理的效果只在持久后端狀態存盤中反映一次,因此,我們認為有效地描述這些處理語意最好的術語是『有效一次』(effectively once),
1.4 分布式快照與至少一次事件傳遞和重復資料洗掉的比較
從語意的角度來看,分布式快照和至少一次事件傳遞以及重復資料洗掉機制都提供了相同的保證,然而,由于兩種機制之間的實作差異,存在顯著的性能差異,
-
機制 1(分布式快照 / 狀態檢查點)的性能開銷是最小的,因為引擎實際上是往流應用程式中的所有算子一起發送常規事件和特殊事件,而狀態檢查點可以在后臺異步執行,但是,對于大型流應用程式,故障可能會更頻繁地發生,導致引擎需要暫停應用程式并回滾所有算子的狀態,這反過來又會影響性能,流式應用程式越大,故障發生的可能性就越大,因此也越頻繁,反過來,流式應用程式的性能受到的影響也就越大,然而,這種機制是非侵入性的,運行時需要的額外資源影響很小,
-
機制 2(至少一次事件傳遞加重復資料洗掉)可能需要更多資源,尤其是存盤,使用此機制,引擎需要能夠跟蹤每個算子實體已完全處理的每個元組,以執行重復資料洗掉,以及為每個事件執行重復資料洗掉本身,這意味著需要跟蹤大量的資料,尤其是在流應用程式很大或者有許多應用程式在運行的情況下,執行重復資料洗掉的每個算子上的每個事件都會產生性能開銷,但是,使用這種機制,流應用程式的性能不太可能受到應用程式大小的影響,對于機制 1,如果任何算子發生故障,則需要發生全域暫停和狀態回滾;對于機制 2,失敗的影響更加區域性,當在算子中發生故障時,可能尚未完全處理的事件僅從上游源重放/重傳,性能影響與流應用程式中發生故障的位置是隔離的,并且對流應用程式中其他算子的性能幾乎沒有影響,從性能角度來看,這兩種機制的優缺點如下,
分布式快照 / 狀態檢查點的優缺點:
- 優點:
- 較小的性能和資源開銷
- 缺點:
- 對性能的影響較大
- 拓撲越大,對性能的潛在影響越大
至少一次事件傳遞以及重復資料洗掉機制的優缺點:
- 優點:
- 故障對性能的影響是區域的
- 故障的影響不一定會隨著拓撲的大小而增加
- 缺點:
- 可能需要大量的存盤和基礎設施來支持
- 每個算子的每個事件的性能開銷
雖然從理論上講,分布式快照和至少一次事件傳遞加重復資料洗掉機制之間存在差異,但兩者都可以簡化為至少一次處理加冪等性,對于這兩種機制,當發生故障時(至少實作一次),事件將被重放/重傳,并且通過狀態回滾或事件重復資料洗掉,算子在更新內部管理狀態時本質上是冪等的,
2flink內部實作狀態一致性
從我另一篇文章
Flink checkpoint具體操作流程詳解與報錯除錯方法匯總
中有詳細的闡述了,flink內checkpoint的執行流程,這里就不展開講了,對這部分知識有了解的讀者應該清楚,節點做checkpoint的快照部分前是同步的,也就是,這個節點會等待所有上游并發節點的 checkpoint barrier全部到來才會發出做快照的命令,之后才是異步做快照的階段,
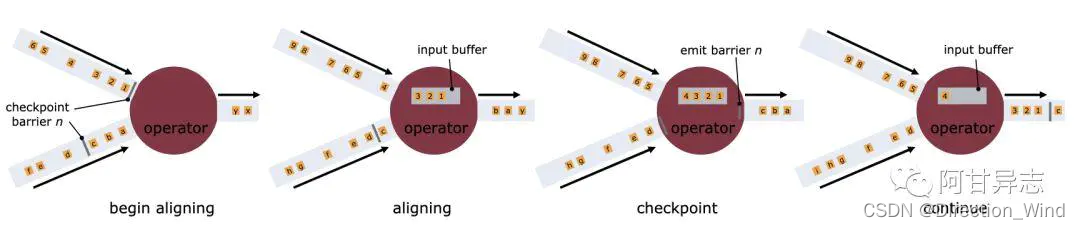
在我們程式處理中通常要求能夠滿足Exactly once語意,保證資料的準確性,flink 通過checkpoint機制提供了Exactly-Once與At-Least-Once 兩種不同的消費語意實作, 可以將程式處理的所有資料都保存在狀態內部,當程式發生例外失敗重啟可以從最近一次成功checkpoint中恢復狀態資料,通過checkpoint中barrier對齊機制來實作這兩不同的語意,barrier對齊發生在一個處理節點需要接收上游不同處理節點的資料,由于不同的上游節點資料處理速度不一致,那么就會導致下游節點接收到 barrier的時間點也會不一致,這時候就需要使用barrier對齊機制:在同一checkpoint中,先到達的barrier是否需要等待其他處理節點barrier達到后在發送后續資料,barrier將資料流分為前后兩個checkpoint(chk n,chk n+1)的概念,如果不等待那么就會導致chk n的階段處理了chk n+1階段的資料,但是在source端所記錄的消費偏移量又一致,如果chk n成功之后,后續的任務處理失敗,任務重啟會消費chk n+1階段資料,就會到致資料重復訊息,如果barrier等待就不會出現這樣情況,因此barrier需要對齊那么就是實作Exactly once語意,否則實作的是at least once語意,由于狀態是屬于flink內部存盤,所以flink 僅僅滿足內部Exactly once語意,
至此實作了flink系統內部的Exactly once語意,
3 端到端的一致性
端到端的資料一致性,主要分三部分
- source
- flink內部:這部分由flink內部實作,這節就不提了
- sink
3.1 Source
需要外部源支持可重設資料的讀取位置,例如kafka,或增量保存資料的資料源,自己記錄offset,例如 mysql 記錄消費到了 多少的id, kafka consumer作為source,可以將偏移量保存下來,如果后續任務出現了故障,恢復的時候可以由連接器重置偏移量,重新消費資料,保證一致性
3.2 Sink
sink端要保證,任務從故障恢復時,資料不會重新寫入到持久化存盤中,一半包括兩種情況:冪等寫入,事務寫入
3.2.1 冪等寫入
所謂冪等操作,是說一個操作,可以重復執行很多次,但只導致一次結果更改,也就是說,后面再重復執行就不起作用了,這種一般用于,下游的持久化存盤沒有事務支持的情況,例如redis,
這種情況一般的資料格式可以支持重復輸出,例如統計關注的 uid: uid,重復輸出也不會影響資料的準確性
3.2.2 事務寫入
事務寫入需要下游系統支持事務,例如kafka,mysql等,利用flink的兩階段提交,來實作資料的exactly-once.
3.2.2.1 兩階段提交
在分布式系統中,可以使用兩階段提交來實作事務性從而保證資料的一致性,兩階段提交分為:預提交階段與提交階段,通常包含兩個角色:協調者與執行者,協調者用于用于管理所有執行者的操作,執行者用于執行具體的提交操作,具體的操作流程:
- 首先協調者會送預提交(pre-commit)命令有的執行者
- 執行者執行預提交操作然后發送一條反饋(ack)訊息給協調者
- 待協調者收到所有執行者的成功反饋,則發送一條提交資訊(commit)給執行者
- 執行者執行提交操作
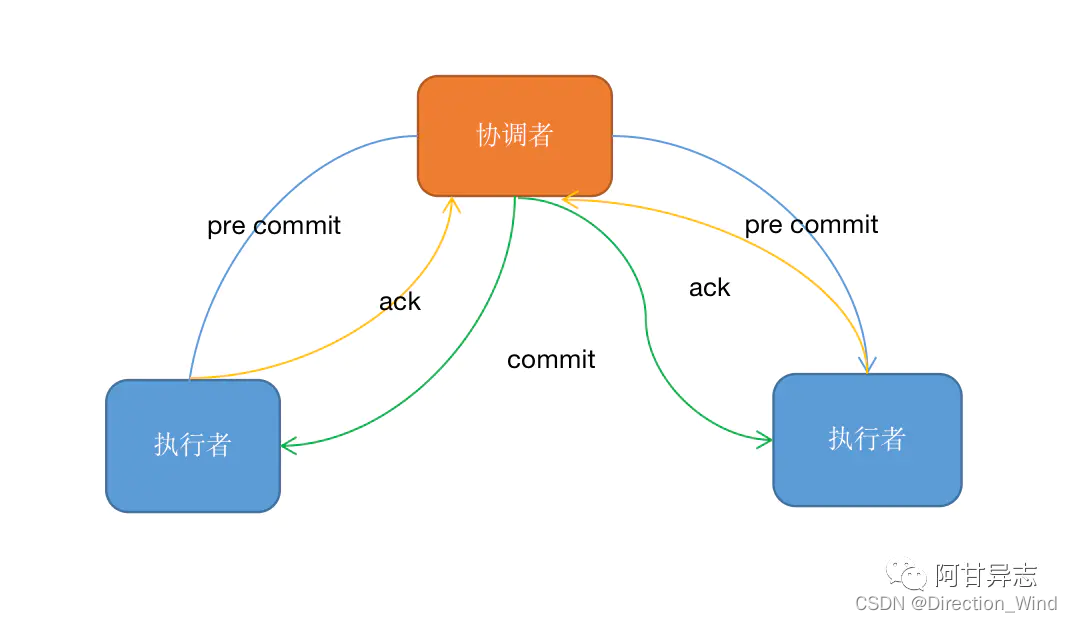
如果在流程2中部分預提交失敗,那么協調者就會收到一條失敗的反饋,則會發送一條rollback訊息給所有執行者,執行回滾操作,保證資料一致性;但是如果在流程4中,出現部分提交成功部分提交失敗,那么就會造成資料的不一致,因此后面也提出了3PC或者通過其他補償機制來保證資料最終一致性,接下看看flink 是如何做到2PC,保證資料的一致性,
3.2.2.2 flink的兩階段提交
以sink kafka為例,flink兩階段提交步驟詳解:
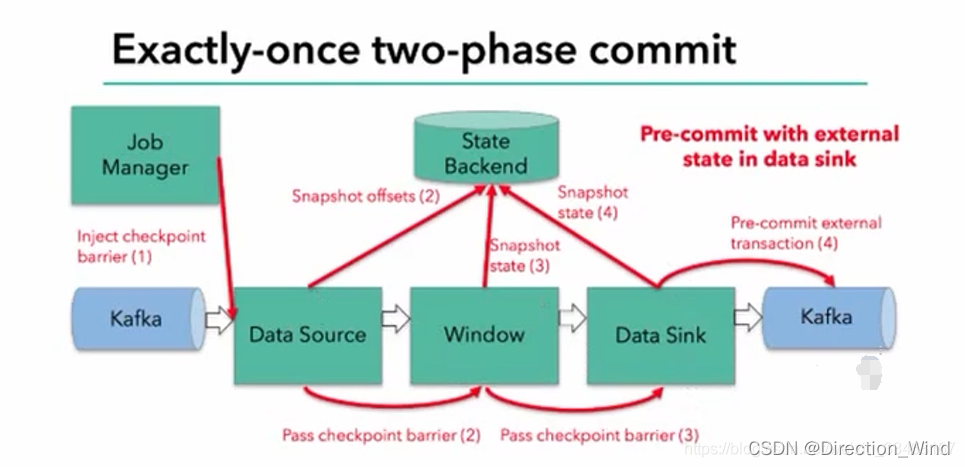
- 第一條資料來了之后,開啟一個kafka的事務(transaction) ,正常寫入kafka磁區日志但標記為未提交,這就是”預提交’
- jobmanager 觸發checkpoint操作,barrier 從source開始向下傳遞,遇到barrier的算子將狀態存入狀態后端,并通知jobmanager
- sink 連接器收到barrier,保存當前狀態,存入checkpoint,通知jobmanager, 并開啟下一階段的事務,用于提交下個檢查點的資料
- jobmanager 收到所有任務的通知,發出確認資訊,表示checkpoint 完成
- sink任務收到jobmanager的確認資訊,正式提交這段時間的資料
外部kafka關閉事務,提交的資料可以正常消費了,
如果在這期間出現任何的資料問題,flink都會回滾資料,之前預提交的資料不會被正式寫入到kafka中,但如果沒有問題,也只需要提交一個事務,sink kafka的下游就可以正常消費,sink算子不能存資料,這樣的話,資料即發到了下游,有沒有被消費到,出問題又可以回滾,但如果是redis,下游資料已經寫入到存盤中, 就上flink回滾,寫入的資料也無法撤回,這就是兩階段提交的重要性,
個人理解,如果用兩階段提交,資料的實時性就沒有那么高,因為需要根據checkpoint的時間間隔來一批一批的寫入資料,沒有辦法每條資料都及時的處理完并sink出,所以對實時性有要求的,可以自定義實作冪等性sink來保證資料的一致性,
參考:
https://mp.weixin.qq.com/s/hFtPx6PSyobt6Pm6XvUrHg
https://blog.csdn.net/wypblog/article/details/103900577
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/431491.html
標籤:其他
上一篇:HBase、ClickHouse、StarRocks
下一篇:zookeeper隨堂筆記