??大多數同學都知道資料有mysql、mongodb、oracle、nosql等等,這些是我們在學校能接觸到最多的資料庫,今天我們就來認識2個企業中比較常用的資料庫clickhouse和elasticsearch,對大資料感興趣的同學可以參考下面的文章👇:
- hadoop專題: hadoop系列文章.
- spark專題: spark系列文章.
- flink專題: Flink系列文章.
??處理大資料這一方面不只有hadoop這一脈、類似的像支持分布式的資料產品clickhouse和elasticsearch也都有自己的特點,在企業中運用也較多,本篇博客就是給它倆掃盲!
目錄
- 1. clickhouse
- 1.1 clickhouse介紹
- 1.2 clickhouse的特點
- 2. elasticsearch
- 2.1 elasticsearch介紹
- 2.2 elasticsearch特點
- 3. clickhouse和elasticsearch對比
- 3.1 兩者的分布式架構
- 3.2 存盤架構
- 3.3 查詢架構
- 3.4 總結
- 4. 參考文章
1. clickhouse
1.1 clickhouse介紹
ClickHouse是一個用于聯機分析(OLAP)的列式資料庫管理系統(DBMS),它是俄羅斯yandex公司于2016年開源的一個列式資料庫管理系統,這里需要注意的是列式資料庫,我們常用的資料庫如:MySQL、Postgres和MS SQL Server都是行式資料庫:
- 行式存盤資料庫:處于同一行中的資料總是被物理的存盤在一起,
- 列式存盤資料庫:來自不同列的值被單獨存盤,來自同一列的資料被存盤在一起,
這兩種存盤的方式適用不同的業務場景,沒有絕對的誰比誰好,只是使用的場景有所不同,例如:進行了何種查詢、多久查詢一次以及各類查詢的比例;每種型別的查詢(行、列和位元組)讀取多少資料;讀取資料和更新之間的關系;使用的資料集大小以及如何使用本地的資料集;是否使用事務,以及它們是如何進行隔離的;資料的復制機制與資料的完整性要求;每種型別的查詢要求的延遲與吞吐量等等,根據用戶使用的場景來選擇,
前面說到,clickhouse適合OLAP的場景,下面列舉一些OLAP場景的特征:
- 資料庫的資料不能修改
- 絕大多數是讀請求
- 沒有更新或者大量更新
- 寬表
- 允許簡單查詢
- 事務不必須
- 資料一致性要求低
為什么列式存盤更適合OLAP呢?我們簡單來舉例:
- 行式存盤資料庫獲取某些列的資料繪制報表
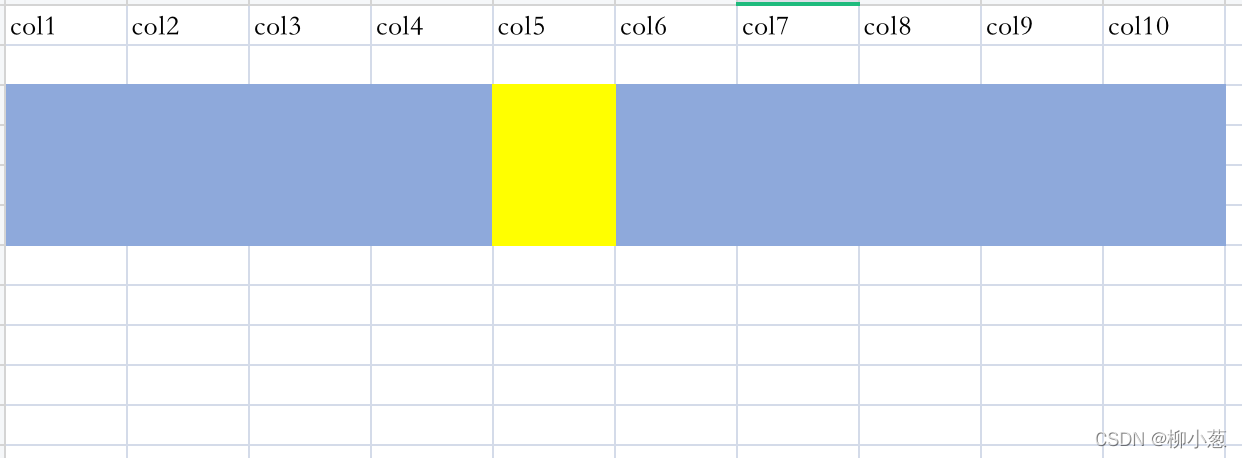
在行式存盤的資料庫中,如果我們需要取出指定列的資料,你首先需要讀取整行資料,然后從整行資料,然后再從讀取的行資料中讀取你需要的列資料,
- 列式存盤資料庫獲取某些列的資料繪制報表
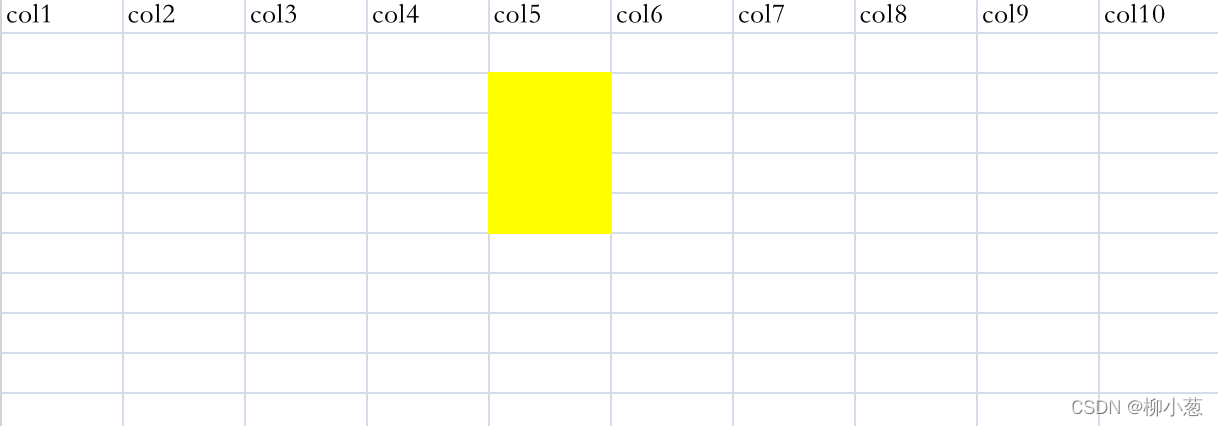
而在列式村存盤中,你只需要讀取存盤列的一小部分資料即可,這這大大降低了I/O操作的消耗和體積,資料量越大,越能凸顯出這種優勢,
但clickhouse也有自己的缺點:
- 不支持事務(ACID),
- 缺少高頻率,低延遲的修改或洗掉已存在資料的能力,僅能用于批量洗掉或修改資料,
- 不擅長根據主鍵按行粒度查詢,
1.2 clickhouse的特點
這個章節主要講述clickhouse資料庫的一些特點:
- 支持資料壓縮,資料壓縮可以達到更優異的性能,在一些列式資料庫管理系統中(例如:InfiniDB CE 和 MonetDB) 并沒有使用資料壓縮,
- 資料存盤硬碟:許多的列式資料庫(如 SAP HANA, Google PowerDrill)只能在記憶體中作業,對設備要求高,而clickhouse是在磁盤上作業,成本低,
- 多核心并行處理:會使用服務器上一切可用的資源,從而以最自然的方式并行處理大型查詢,
- 多服務器分布式處理:列式存盤資料庫中唯一份支持分布式查詢的資料庫,
- 支持SQL:入手快,許多情況下與ANSI SQL標準相同,
- 支持資料復制和資料完整性:使用異步的多主復制技術,當資料被寫入任何一個可用副本后,系統會在后臺將資料分發給其他副本,以保證系統在不同副本上保持相同的資料,
- 角色的訪問控制
2. elasticsearch
2.1 elasticsearch介紹
Elasticsearch是一個實時分布式和開源的全文搜索和分析引擎, 它可以從RESTful Web服務介面訪問,并使用模式少JSON(JavaScript物件符號)檔案來存盤資料,它是基于Java編程語言,這使Elasticsearch能夠在不同的平臺上運行,使用戶能夠以非常快的速度來搜索非常大的資料量,
Elasticsearch最初是用于做全文檢索的場景,可多數時候是用來做精確查詢加速,查詢條件很多,可以任意組合,查詢速度很快,替代其它很多資料庫復雜條件查詢的場景需求,現在es已經成為事實上的檔案型資料庫,使用Json格式來存盤資料,
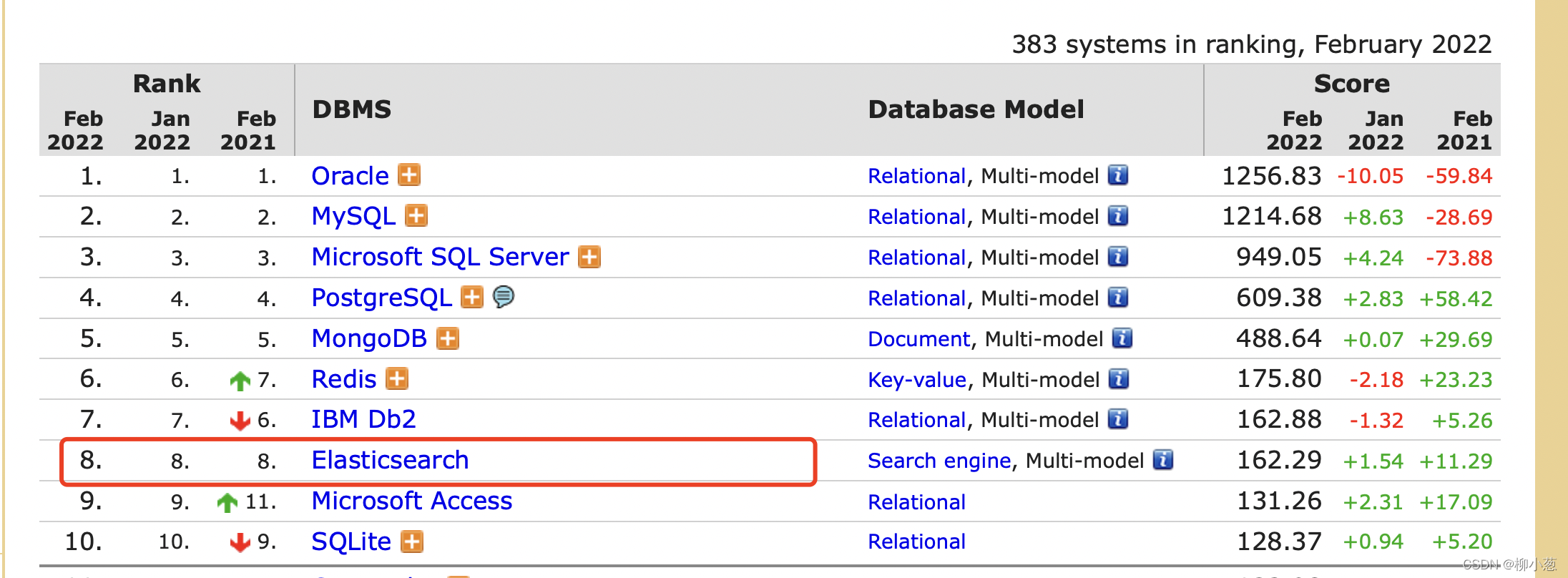
根據2022年2月份的資料es資料庫排名第8,下面我們介紹一下es資料適用的場景:
- ES作為網站的主要后端系統:比如博客的資料直接在es上進行檢索,
- 作為大資料分析的承載工具:資料進行hadoop生態處理后,可以輸入es中資料庫提供查詢,
- 資料分析
- 機器學習
es和傳統的資料庫的概念有著對應關系:
| 關系型資料庫 | ES |
|---|---|
| Table | Index(Type) |
| Row | Document |
| Column | Field |
| Schema | Mapping |
| SQL | DSL |
解釋一下:es中的表稱為索引、行稱為檔案、列稱為域等,
2.2 elasticsearch特點
這里介紹一下es的特點,es作為NoSQL資料庫代表之一,非常適合于非結構化檔案類資料存盤、更創新支持智能分詞匹配模糊查詢,特點如下:
- 分布式的檔案存盤,每個欄位都被索引且可用于搜索,
- 分布式的實時分析搜索引擎,海量資料下近實時秒級回應,
- 簡單的restful api,天生的兼容多語言開發,
- 易擴展,處理PB級結構化或非結構化資料,
3. clickhouse和elasticsearch對比
3.1 兩者的分布式架構
- Elasticsearch采用的是主備同步機制,由主節點負責同步到備節點,這種方式會更加簡單高效,
- ClickHouse引入了外置的ZooKeeper集群,來進行分布式DDL任務、主備同步任務等操作的下發,多副本之間的資料同步(data shipping)任務下發也是依賴于ZooKeeper集群,但最終多副本之間的資料傳輸還是通過Http協議來進行點對點的資料拷貝,同時多副本都可寫,資料同步是完全多向的,對用戶的易用性略差,用戶門檻相對較高,
3.2 存盤架構
- Elasticsearch會將資料先寫入記憶體,然后隔一段時間將記憶體資料寫入磁盤,是一個接近實時的系統,
- ClickHouse是直接使用磁盤進行讀寫,
在資料‘寫的快‘這方面Elasticsearch更快,但是在寫入吞吐能力上ClickHouse更強,
3.3 查詢架構
- Elasticsearch是一個搜索引擎,而搜索引擎能處理的查詢復雜度是確定的、有上限的,所有的搜索查詢經過確定的若干個階段就可以得出結果,它完全不具備資料庫計算引擎的流式處理能力,它是完全回合制的request-response資料處理,當用戶需要回傳的資料量很大時,就很容易出現查詢失敗,或者觸發GC,一般來說Elasticsearch的搜索引擎能力上限就是兩階段的查詢,像多表關聯這種查詢是完全超出其能力上限的,
- ClickHouse的計算引擎特點則是極致的向量化,完全用c++模板手寫的向量化函式和aggregator算子使得它在聚合查詢上的處理性能達到了極致,配合上存盤極致的并行掃描能力,輕松就可以把機器資源跑滿,
尤其是ClickHouse支持SQL而Elasticsearch用的是DSL(難懂、難上手)
3.4 總結
Elasticsearch只有在完全搜索場景下面(where過濾后的記錄數較少),并且記憶體足夠的運行環境下,才能展現出并發上的優勢,而在分析場景下(where過濾后的記錄數較多),ClickHouse憑借極致的列存和向量化計算會有更加出色的并發表現,兩者的側重不同而已,同時ClickHouse并發處理能力立足于磁盤吞吐,而Elasticsearch的并發處理能力立足于記憶體Cache,ClickHouse更加適合低成本、大資料量的分析場景,它能夠充分利用磁盤的帶寬能力,
4. 參考文章
本文只是對ClickHouse和Elasticsearch進行一個初步的認識,并未對它們的原理進行深入了解,了解它們在大資料分析處理中的"位置",
- ClickHouse檔案: ClickHouse檔案.
- Elasticsearch官網: Elasticsearch官網.
- 鏈接: Elasticsearch教程-bootwiki.
- 知乎: ES既是搜索引擎又是資料庫?真的有那么全能嗎?.
- 知乎: 掌握它才說明你真正懂Elasticsearch.
- 阿里云社區: 獨家深度 | 一文看懂 ClickHouse vs Elasticsearch:誰更勝一籌?.
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/431493.html
標籤:其他
上一篇:zookeeper隨堂筆記
下一篇:SQL被當成代碼?谷歌的理由絕了