影像中的注意力機制詳解
注意力機制目前主要有通道注意力機制和空間注意力機制兩種
一、 前言
我們知道,輸入一張圖片,神經網路會提取影像特征,每一層都有不同大小的特征圖,如圖1所示,展示了 VGG網路在提取影像特征時特征圖的大小變化,
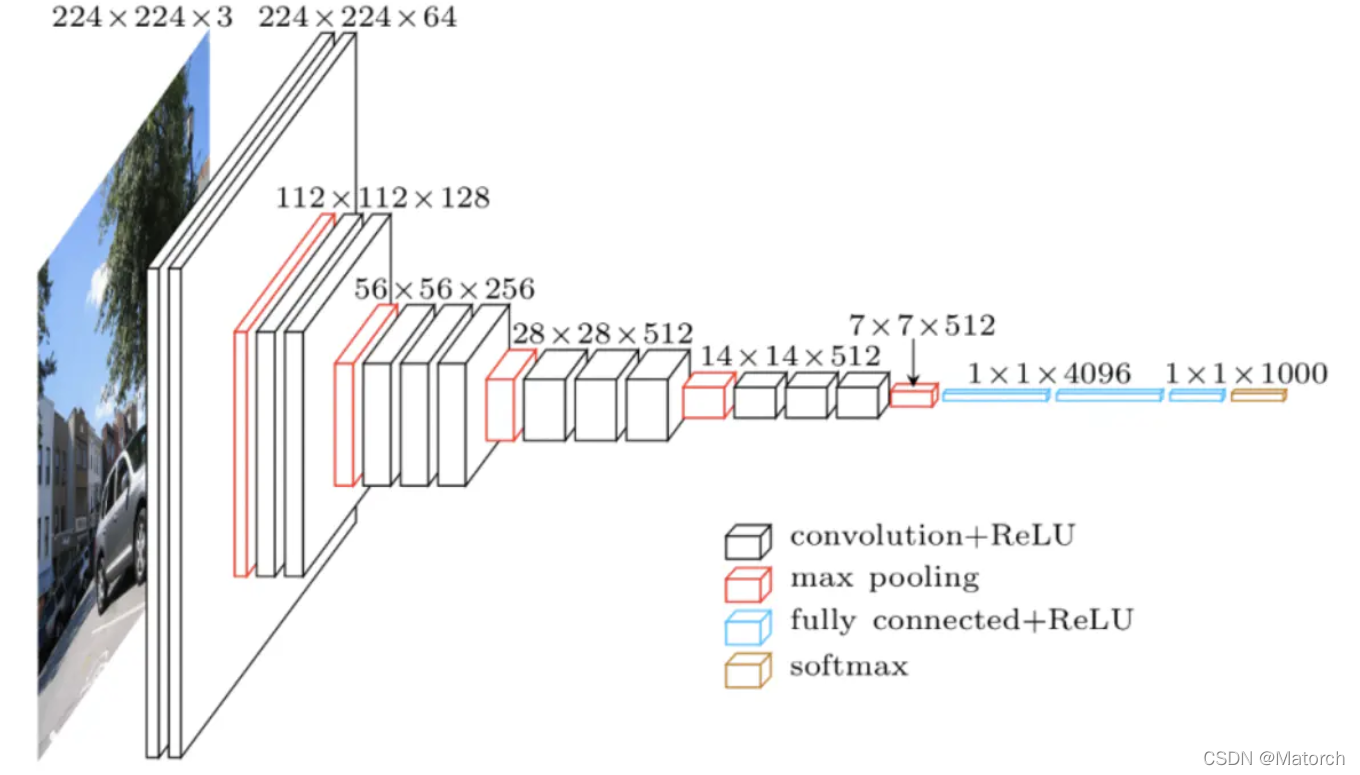
其中,特征圖常見的矩陣形狀為 [ C , H , W ] {[C,H,W]} [C,H,W](圖1中的數字為 [ H , W , C ] {[H,W,C]} [H,W,C]格式),當model在training時,特征圖的矩陣形狀為 [ B , C , H , W ] {[B,C,H,W]} [B,C,H,W],其中B表示為batch size(批處理大小),C表示為channels(通道數),H表示為特征圖的high(高度),W表示為特征圖的weight(寬度)
提問:為什么特征圖的維度就是 [ B , C , H , W ] {[B,C,H,W]} [B,C,H,W],而不是其他什么維度格式?
回答:pytorch在處理影像時,讀入的影像處理為 [ C , H , W ] {[C,H,W]} [C,H,W]格式,如果在訓練時加入batch size,那么就有多個特征圖,將batch size放在第一維,自然就是 [ B , C , H , W ] {[B,C,H,W]} [B,C,H,W],這是pytorch的處理方式
在網路提取影像特征層時,通過在卷積層之間添加通道注意力機制、空間注意力機制可以增強網路提取影像的能力,在撰寫代碼時,考慮的是特征圖間的attention機制,因此代碼輸入是 [ B , C , H , W ] {[B,C,H,W]} [B,C,H,W]的特征圖,輸出仍然是 [ B , C , H , W ] {[B,C,H,W]} [B,C,H,W]維的特征圖,讓我們接下來通過三篇論文來看這兩種注意力機制是如何作業的,
二、SENet——通道注意力機制
1. 論文介紹
論文名稱:Squeeze-and-Excitation Networks
論文鏈接:https://arxiv.org/pdf/1709.01507.pdf
論文代碼: https://github.com/hujie-frank/SENet
SEBlock結構圖:
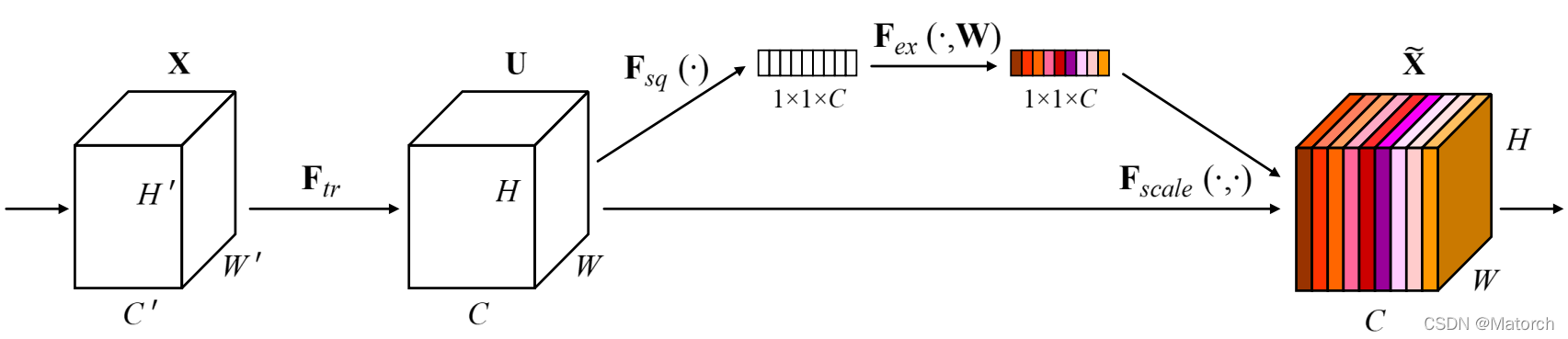
Abstract: The central building block of convolutional neural networks (CNNs) is the convolution operator, which enables networks to construct informative features by fusing both spatial and channel-wise information within local receptive fields at each layer. A broad range of prior research has investigated the spatial component of this relationship, seeking to strengthen the representational power of a CNN by enhancing the quality of spatial encodings throughout its feature hierarchy. In this work, we focus instead on the channel relationship and propose a novel architectural unit, which we term the “Squeeze-and-Excitation” (SE) block, that adaptively recalibrates channel-wise feature responses by explicitly modelling interdependencies between channels. We show that these blocks can be stacked together to form SENet architectures that generalise extremely effectively across different datasets. We further demonstrate that SE blocks bring significant improvements in performance for existing state-of-the-art CNNs at slight additional computational cost. Squeeze-and-Excitation Networks formed the foundation of our ILSVRC 2017 classification submission which won first place and reduced the top-5 error to 2.251%, surpassing the winning entry of 2016 by a relative improvement of ~25%. Models and code are available at https://github.com/hujie-frank/SENet.
摘要重點:
卷積神經網路(CNN)的核心組成部分是卷積算子,它使網路能夠通過融合每層區域感受野中的空間和通道資訊來構建資訊特征,之前的大量研究已經調查了這種關系的空間成分,并試圖通過在CNN的特征層次中提高空間編碼的質量來增強CNN,在這項作業中,我們將重點放在通道(channel-wise)關系上,并提出了一個新的名為SE模塊的架構單元,它通過顯式地建模通道之間的相互依賴性,自適應地重新校準通道特征回應,這些模塊可以堆疊在一起形成SENet網路結構,并在多個資料集上非常有效地推廣,
SEBlock創新點:
- SEBlock會給每個通道一個權重,讓不同通道對結果有不同的作用力,
- 這個SE模塊能夠非常方便地添加進目前主流的神經網路當中,
2. 演算法解讀
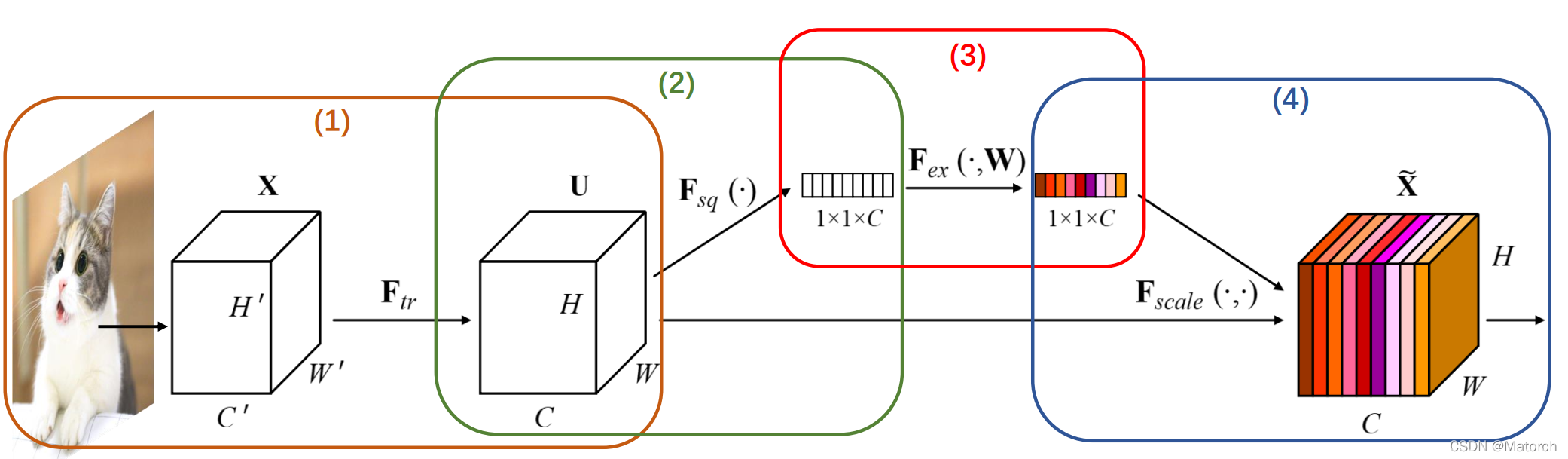
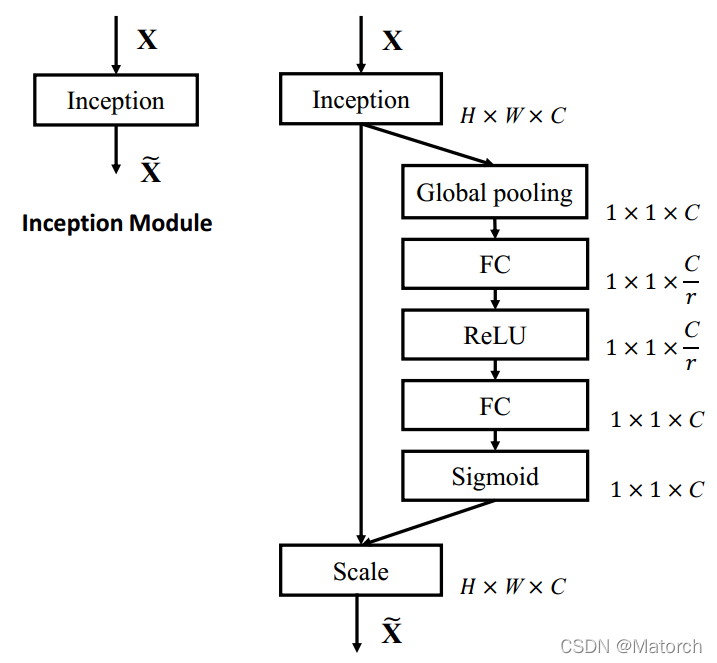
圖3展示了通道注意力機制的四個步驟,具體如下:
-
從單張影像開始,提取影像特征,當前特征層U的特征圖維度為 [ C , H , W ] {[C,H,W]} [C,H,W],
-
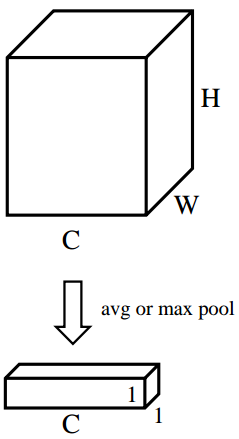
對特征圖的 [ H , W ] {[H,W]} [H,W]維度進行平均池化或最大池化,池化過后的特征圖大小從 [ C , H , W ] {[C,H,W]} [C,H,W]-> [ C , 1 , 1 ] {[C,1,1]} [C,1,1], [ C , 1 , 1 ] {[C,1,1]} [C,1,1]可理解為對于每一個通道C,都有一個數字和其一一對應,圖4對應了步驟(2)的具體操作,
- 對 [ C , 1 , 1 ] {[C,1,1]} [C,1,1]的特征可以理解為,從每個通道本身提取出來的權重,權重表示了每個通道對特征提取的影響力,全域池化后的向量通過MLP網路后,其意義為得到了每個通道的權重,圖5對應了步驟(3)的具體操作,
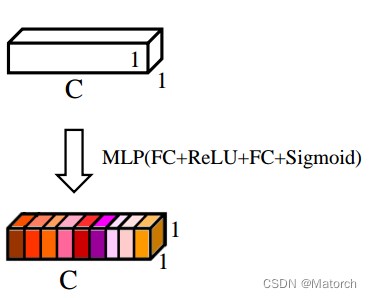
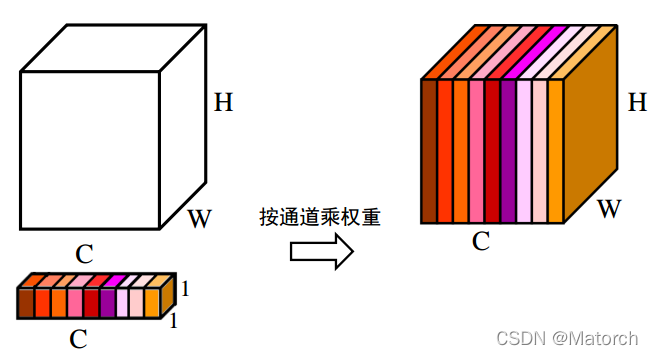
- 上述步驟,得到了每個通道C的權重 [ C , 1 , 1 ] {[C,1,1]} [C,1,1],將權重作用于特征圖U [ C , H , W ] {[C,H,W]} [C,H,W],即每個通道各自乘以各自的權重,可以理解為,當權重大時,該通道特征圖的數值相應的增大,對最終輸出的影響也會變大;當權重小時,該通道特征圖的數值就會更小,對最終輸出的影響也會變小,圖6對應了步驟(4)的具體操作,
原論文中給出了通道注意力網路細節,這里展示出來,如圖7所示,
3. Pytorch代碼實作
import torch
import torch.nn as nn
class SEBlock(nn.Module):
def __init__(self, mode, channels, ratio):
super(SEBlock, self).__init__()
self.avg_pooling = nn.AdaptiveAvgPool2d(1)
self.max_pooling = nn.AdaptiveMaxPool2d(1)
if mode == "max":
self.global_pooling = self.max_pooling
elif mode == "avg":
self.global_pooling = self.avg_pooling
self.fc_layers = nn.Sequential(
nn.Linear(in_features = channels, out_features = channels // ratio, bias = False),
nn.ReLU(),
nn.Linear(in_features = channels // ratio, out_features = channels, bias = False),
)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
b, c, _, _ = x.shape
v = self.global_pooling(x).view(b, c)
v = self.fc_layers(v).view(b, c, 1, 1)
v = self.sigmoid(v)
return x * v
if __name__ == "__main__":
model = SEBlock("max", 54, 9)
feature_maps = torch.randn((8, 54, 32, 32))
model(feature_maps)
4. 個人理解
通道注意力機制為什么有效的原因:特征圖在提取影像特征的程序當中,不可避免的就是會出現有些特征圖層作用大,而有些特征圖層作用小,因此由通道本身提取出的權重施加在特征圖上,保證了在特征圖提取特征的基礎上,自適應地給定通道權重,讓作用大的特征圖對結果的影響更大一點,因此在最終結果上是比普通的卷積層要更有效提取特征一點,
三、ECANet——通道注意力機制(一維卷積替換SENet中的MLP)
1. 論文介紹
論文名稱:ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks
論文鏈接:https://arxiv.org/pdf/1910.03151.pdf
論文代碼:https://github.com/BangguWu/ECANet
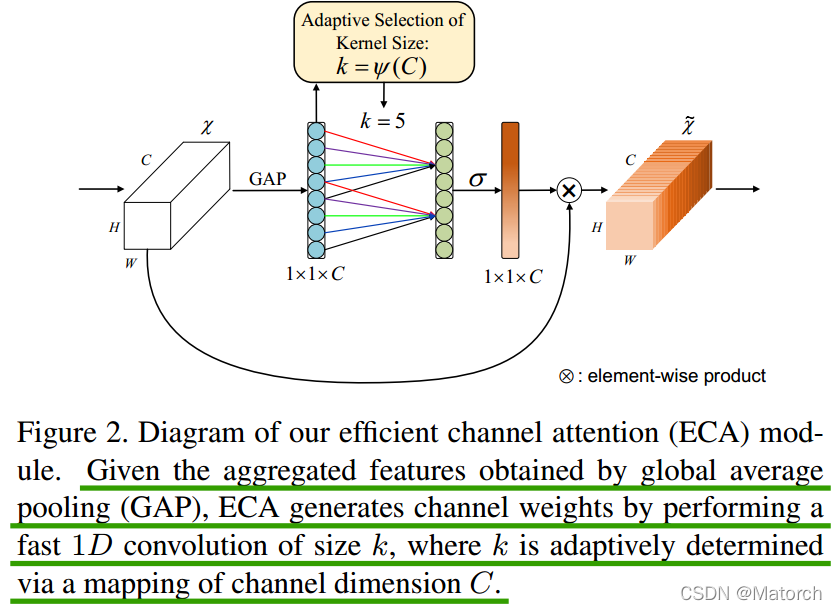
ECABlock主要結構圖
Abstract: Recently, channel attention mechanism has demonstrated to offer great potential in improving the performance of deep convolutional neural networks (CNNs). However, most existing methods dedicate to developing more sophisticated attention modules for achieving better performance, which inevitably increase model complexity. To overcome the paradox of performance and complexity trade-off, this paper proposes an Efficient Channel Attention (ECA) module, which only involves a handful of parameters while bringing clear performance gain. By dissecting the channel attention module in SENet, we empirically show avoiding dimensionality reduction is important for learning channel attention, and appropriate cross-channel interaction can preserve performance while significantly decreasing model complexity. Therefore, we propose a local crosschannel interaction strategy without dimensionality reduction, which can be efficiently implemented via 1D convolution. Furthermore, we develop a method to adaptively select kernel size of 1D convolution, determining coverage of local cross-channel interaction. The proposed ECA module is efficient yet effective, e.g., the parameters and computations of our modules against backbone of ResNet50 are 80 vs. 24.37M and 4.7e-4 GFLOPs vs. 3.86 GFLOPs, respectively, and the performance boost is more than 2% in terms of Top-1 accuracy. We extensively evaluate our ECA module on image classification, object detection and instance segmentation with backbones of ResNets and MobileNetV2. The experimental results show our module is more efficient while performing favorably against its counterparts.
摘要重點:
近年來,通道注意機制在改善深度卷積神經網路(CNN)性能方面顯示出巨大的潛力,然而,大多數現有方法致力于開發更復雜的注意模塊,以獲得更好的性能,這不可避免地增加了模型的復雜性,為了克服性能和復雜性之間的矛盾,本文提出了一種高效的通道注意(ECA)模塊,該模塊只涉及少量引數,同時帶來明顯的性能增益,通過剖析SENet中的通道注意模塊,我們實證地表明,避免維度縮減對于學習通道注意非常重要,適當的跨通道互動可以在顯著降低模型復雜度的同時保持性能,因此,我們提出了一種無降維的區域交叉信道互動策略,該策略可以通過一維卷積有效地實作,
ECABlock創新點
-
針對SEBlock的步驟(3),將MLP模塊(FC->ReLU>FC->Sigmoid),轉變為一維卷積的形式,有效減少了引數計算量(我們都知道在CNN網路中,往往連接層是引數量巨大的,因此將全連接層改為一維卷積的形式)
-
一維卷積自帶的功效就是非全連接,每一次卷積程序只和部分通道的作用,即實作了適當的跨通道互動而不是像全連接層一樣全通道互動,
2. 論文解讀
給定通過平均池化(average pooling)獲得的聚合特征 [ C , 1 , 1 ] {[C,1,1]} [C,1,1],ECA模塊通過執行卷積核大小為k的一維卷積來生成通道權重,其中k通過通道維度C的映射自適應地確定,
圖中與SEBlock不一樣的地方僅在于SEBlock的步驟(3),用一維卷積替換了全連接層,其中一維卷積核大小通過通道數C自適應確定,
自適應確定卷積核大小公式:
k
=
∣
l
o
g
2
C
+
b
γ
∣
o
d
d
{k=|\cfrac{log_2{C}+b}{\gamma}|_{odd}}
k=∣γlog2?C+b?∣odd?
其中k表示卷積核大小,C表示通道數,
∣
∣
o
d
d
{| |_{odd}}
∣∣odd?表示k只能取奇數,
γ
{\gamma}
γ和
b
{b}
b在論文中設定為2和1,用于改變通道數C和卷積核大小和之間的比例,
(如何理解通道C自適應確定卷積核大小:當通道數多的時候,我需要卷積核k稍大一點,當通道數少的時候,我需要卷積核k稍微小一點,這樣能充分融合部分通道間的互動)
3. Pytorch代碼實作
import math
import torch
import torch.nn as nn
class ECABlock(nn.Module):
def __init__(self, channels, gamma = 2, b = 1):
super(ECABlock, self).__init__()
kernel_size = int(abs((math.log(channels, 2) + b) / gamma))
kernel_size = kernel_size if kernel_size % 2 else kernel_size + 1
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.conv = nn.Conv1d(1, 1, kernel_size = kernel_size, padding = (kernel_size - 1) // 2, bias = False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
v = self.avg_pool(x)
v = self.conv(v.squeeze(-1).transpose(-1, -2)).transpose(-1, -2).unsqueeze(-1)
v = self.sigmoid(v)
return x * v
if __name__ == "__main__":
features_maps = torch.randn((8, 54, 32, 32))
model = ECABlock(54, gamma = 2, b = 1)
model(features_maps)
這里對比了兩個論文的代碼實作,可以看到,只是把MLP更換為了一維卷積,
# SEBlock 采用全連接層方式
def forward(self, x):
b, c, _, _ = x.shape
v = self.global_pooling(x).view(b, c)
v = self.fc_layers(v).view(b, c, 1, 1)
v = self.sigmoid(v)
return x * v
# ECABlock 采用一維卷積方式
def forward(self, x):
v = self.avg_pool(x)
v = self.conv(v.squeeze(-1).transpose(-1, -2)).transpose(-1, -2).unsqueeze(-1)
v = self.sigmoid(v)
return x * v
4.個人理解
ECABlock本身沒有大的內容上的改變,只是替換了全連接層,減少了資料量而已(有時候做減法比做加法好)
四、 CBAMBlock——通道注意力機制和空間注意力機制混合使用(SEBlock或ECABlock后接空間注意力機制)
1. 論文介紹
論文名稱:CBAM: Convolutional Block Attention Module
論文鏈接:https://arxiv.org/pdf/1807.06521v2.pdf
論文代碼:https://github.com/luuuyi/CBAM.PyTorch(復現版本)
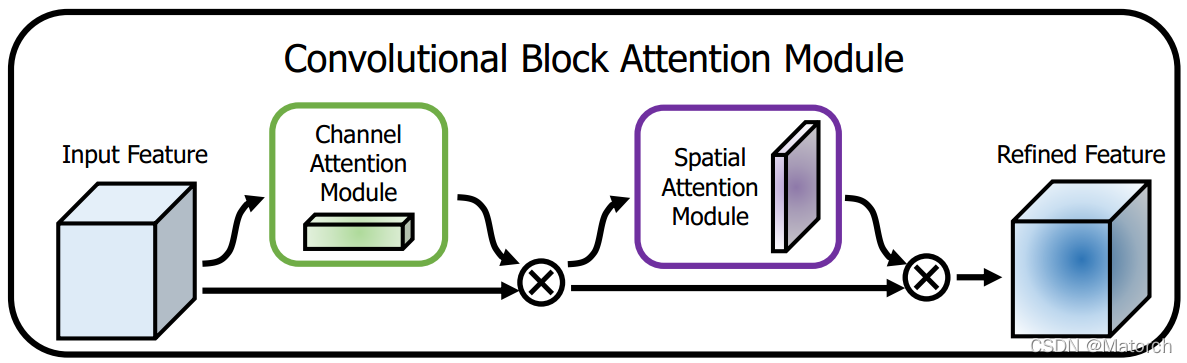
CBAMBlock結構圖
Abstract: We propose Convolutional Block Attention Module (CBAM), a simple yet effective attention module for feed-forward convolutional neural networks. Given an intermediate feature map, our module sequentially infers attention maps along two separate dimensions, channel and spatial, then the attention maps are multiplied to the input feature map for adaptive feature refinement. Because CBAM is a lightweight and general module, it can be integrated into any CNN architectures seamlessly with negligible overheads and is end-to-end trainable along with base CNNs. We validate our CBAM through extensive experiments on ImageNet-1K, MS COCO detection, and VOC 2007 detection datasets. Our experiments show consistent improvements in classification and detection performances with various models, demonstrating the wide applicability of CBAM. The code and models will be publicly available.
摘要重點:
我們提出了卷積塊注意模塊(CBAM),一種簡單而有效的前饋卷積神經網路注意模塊,給定一個中間的特征圖,我們的模塊采用兩個獨立的注意力機制,通道注意力和空間注意力,然后將注意力機制得到的權重乘以輸入特征圖以進行自適應特征細化,因為CBAM是一個輕量級的通用模塊,它可以無縫地集成到任何CNN架構中,開銷可以忽略不計,并且可以與基礎CNN一起進行端到端培訓,我們通過在ImageNet-1K、MS COCO檢測和VOC 2007檢測資料集上的大量實驗來驗證我們的CBAM,我們的實驗表明,各種模型在分類和檢測性能上都有一致的改進,證明了CBAM的廣泛適用性,代碼和模型將公開提供,
CBAM創新點
- 在SENet或ECANet的基礎上,在通道注意力模塊后,接入空間注意力模塊,實作了通道注意力和空間注意力的雙機制
- 選擇SENet還是ECANet主要取決于通道注意力的連接是MLP還是一維卷積
- 注意力模塊不再采用單一的最大池化或平均池化,而是采用最大池化和平均池化的相加或堆疊,通道注意力模塊采用相加,空間注意力模塊采用堆疊方式,
2. 論文解讀
在上述兩篇論文中已經實作了通道注意力方法的全連接(SENet)或卷積(ECANet)實作,這一篇論文與上文的最大不同點就在于,加入了空間注意力機制,
1) 通道注意力機制
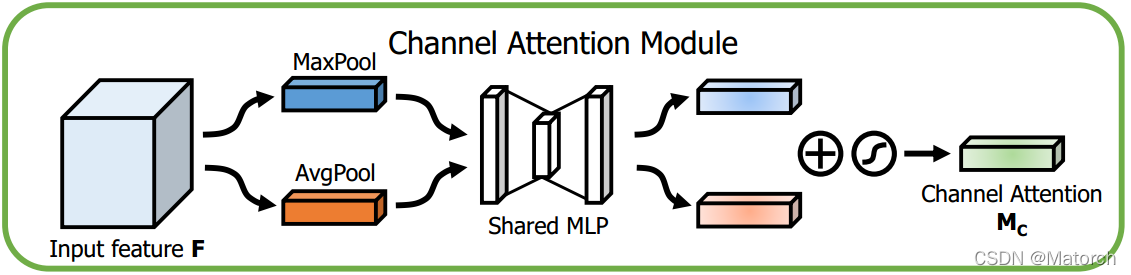
- 特征圖分別經過MaxPool和AvgPool,形成兩個 [ C , 1 , 1 ] {[C,1,1]} [C,1,1]的權重向量
- 兩個權重向量分別經過同一個MLP網路(由于是同一個網路,因此也可看作是網路引數共享的MLP),映射成每個通道的權重
- 將映射后的權重相加,后接Sigmoid輸出
- 將得到的通道權重 [ C , 1 , 1 ] {[C,1,1]} [C,1,1]與原特征圖 [ C , H , W ] {[C,H,W]} [C,H,W]按通道相乘
整體上和SENet基本一致,只是將單一的平均池化變為了同時采用最大池化和平均池化方法,之后若將MLP稍加修改,改成一維卷積,就成為了ECANet的變形版本
2) 空間注意力機制
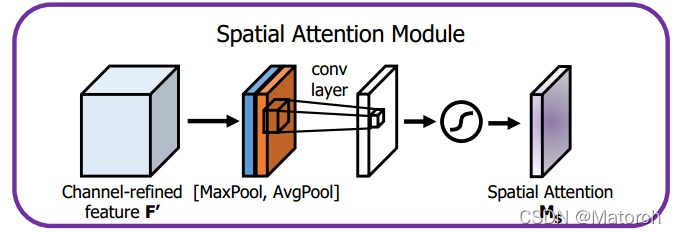
- 特征圖分別經過MaxPool和AvgPool,形成兩個 [ 1 , H , W ] {[1,H,W]} [1,H,W]的權重向量,即按通道最大池化和平均池化,通道數從 [ C , H , W ] {[C,H,W]} [C,H,W]變為 [ 1 , H , W ] {[1,H,W]} [1,H,W],對同一特征點的所有通道池化,
- 得到的兩張特征圖進行堆疊,形成 [ 2 , H , W ] {[2,H,W]} [2,H,W]的特征圖空間權重
- 經過一層卷積層,特征圖維度從 [ 2 , H , W ] {[2,H,W]} [2,H,W]變為 [ 1 , H , W ] {[1,H,W]} [1,H,W],這 [ 1 , H , W ] {[1,H,W]} [1,H,W]的特征圖表征了特征圖上的每個點的重要程度,數值大的更重要
- 將得到的空間權重 [ 1 , H , W ] {[1,H,W]} [1,H,W]與原特征圖 [ C , H , W ] {[C,H,W]} [C,H,W]相乘,即特征圖上 [ H , W ] {[H,W]} [H,W]的每一個點都賦予了權重
我們可以看成大小為 [ H , W ] {[H,W]} [H,W]的特征圖,在每一個點 ( x , y ) , x ∈ ( 0 , H ) , y ∈ ( 0 , W ) {(x,y),x\in(0,H),y\in(0,W)} (x,y),x∈(0,H),y∈(0,W)上,都有C個數值,數值表征了特征圖該點的重要程度,通過感受野反推回原影像,即表示了該區域的重要程度,我們需要讓網路自適應關注需要關注的地方(數值大的地方更易受到關注),空間注意力機制應運而生,
3. Pytorch代碼實作
通道注意力機制——全連接層版本
import math
import torch
import torch.nn as nn
class Channel_Attention_Module_FC(nn.Module):
def __init__(self, channels, ratio):
super(Channel_Attention_Module_FC, self).__init__()
self.avg_pooling = nn.AdaptiveAvgPool2d(1)
self.max_pooling = nn.AdaptiveMaxPool2d(1)
self.fc_layers = nn.Sequential(
nn.Linear(in_features = channels, out_features = channels // ratio, bias = False),
nn.ReLU(),
nn.Linear(in_features = channels // ratio, out_features = channels, bias = False),
nn.Sigmoid()
)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
b, c, h, w = x.shape
avg_x = self.avg_pooling(x).view(b, c)
max_x = self.max_pooling(x).view(b, c)
v = self.fc_layers(avg_x) + self.fc_layers(max_x)
v = self.sigmoid(v).view(b, c, 1, 1)
return x * v
通道注意力機制——一維卷積版本
class Channel_Attention_Module_Conv(nn.Module):
def __init__(self, channels, gamma = 2, b = 1):
super(Channel_Attention_Module_Conv, self).__init__()
kernel_size = int(abs((math.log(channels, 2) + b) / gamma))
kernel_size = kernel_size if kernel_size % 2 else kernel_size + 1
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.conv = nn.Conv1d(1, 1, kernel_size = kernel_size, padding = (kernel_size - 1) // 2, bias = False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
v = self.avg_pool(x)
v = self.conv(v.squeeze(-1).transpose(-1, -2)).transpose(-1, -2).unsqueeze(-1)
v = self.sigmoid(v)
return x * v
空間注意力機制
class Spatial_Attention_Module(nn.Module):
def __init__(self, k: int):
super(Spatial_Attention_Module, self).__init__()
self.avg_pooling = torch.mean
self.max_pooling = torch.max
# In order to keep the size of the front and rear images consistent
# with calculate, k = 1 + 2p, k denote kernel_size, and p denote padding number
# so, when p = 1 -> k = 3; p = 2 -> k = 5; p = 3 -> k = 7, it works. when p = 4 -> k = 9, it is too big to use in network
assert k in [3, 5, 7], "kernel size = 1 + 2 * padding, so kernel size must be 3, 5, 7"
self.conv = nn.Conv2d(2, 1, kernel_size = (k, k), stride = (1, 1), padding = ((k - 1) // 2, (k - 1) // 2),
bias = False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
# compress the C channel to 1 and keep the dimensions
avg_x = self.avg_pooling(x, dim = 1, keepdim = True)
max_x, _ = self.max_pooling(x, dim = 1, keepdim = True)
v = self.conv(torch.cat((max_x, avg_x), dim = 1))
v = self.sigmoid(v)
return x * v
CBAM模塊(空間注意力和通道注意力二者結合)
class CBAMBlock(nn.Module):
def __init__(self, channel_attention_mode: str, spatial_attention_kernel_size: int, channels: int = None,
ratio: int = None, gamma: int = None, b: int = None):
super(CBAMBlock, self).__init__()
if channel_attention_mode == "FC":
assert channels != None and ratio != None and channel_attention_mode == "FC", \
"FC channel attention block need feature maps' channels, ratio"
self.channel_attention_block = Channel_Attention_Module_FC(channels = channels, ratio = ratio)
elif channel_attention_mode == "Conv":
assert channels != None and gamma != None and b != None and channel_attention_mode == "Conv", \
"Conv channel attention block need feature maps' channels, gamma, b"
self.channel_attention_block = Channel_Attention_Module_Conv(channels = channels, gamma = gamma, b = b)
else:
assert channel_attention_mode in ["FC", "Conv"], \
"channel attention block must be 'FC' or 'Conv'"
self.spatial_attention_block = Spatial_Attention_Module(k = spatial_attention_kernel_size)
def forward(self, x):
x = self.channel_attention_block(x)
x = self.spatial_attention_block(x)
return x
if __name__ == "__main__":
feature_maps = torch.randn((8, 54, 32, 32))
model = CBAMBlock("FC", 5, channels = 54, ratio = 9)
model(feature_maps)
model = CBAMBlock("Conv", 5, channels = 54, gamma = 2, b = 1)
model(feature_maps)
4. 個人理解
空間注意力機制與通道注意力機制有異曲同工之妙,都是通過提取權重,作用在原特征圖上,只不過一個是在
[
H
,
W
]
{[H,W]}
[H,W]維度上,一個是在
[
C
]
{[C]}
[C]維度上,這樣的方法在不增加過多的計算量的前提下能提點,不失為一個好的trick,
Attention is all you need!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/432137.html
標籤:AI