文章目錄
- 一、環境準備
- 二、Spark環境搭建
- 1. Spark部署方式
- 2. 安裝spark
- 1) 下載Spark
- 關于版本的選擇
- 2)安裝Spark
- 上傳安裝包
- 解壓并創建軟鏈接
- Spark的目錄結構
- 配置環境變數
- 配置Hadoop資訊
- 修改日志級別
- 3)測驗安裝
- 注意
- 進入scala互動界面
- 運行代碼
- 4)配置pyspark
- 安裝python
- 安裝pyspark開發包
- 5) 配置Spark偽Standalone模式
- 切換至組態檔目錄
- spark-env.sh
- slaves
- 6) 測驗standalone模式
- standalone啟動
- 查看行程
- web查看
- 測驗
- 停止
- 7) 配置Web互動式環境
- 3. 代碼提交
- 撰寫wordcount程式
- 提交代碼到local
- 提交代碼到Standalone
- 提交代碼到YARN
- 三、相關資源
一、環境準備
-
虛擬機安裝
虛擬機軟體:VMware
作業系統 :Ubuntu1804
參考:https://blog.csdn.net/tangyi2008/article/details/120311293
-
JDK1.8
-
Hadoop安裝
版本:2.7.7
參考:https://blog.csdn.net/tangyi2008/article/details/121908766
二、Spark環境搭建
1. Spark部署方式
- Local模式:單機模式
- 集群模式:
- Standalone模式:使用Spark自帶的簡單集群管理器
- YARN模式:使用YARN作為集群管理器
- Mesos模式:使用Mesos作為集群管理器
- Kubernetes模式:實驗階段
2. 安裝spark
1) 下載Spark
Spark官網的Download界面https://spark.apache.org/downloads.html可選版本較少,比較這里打開的網頁,只有三個版本可選,
可以在下載頁面的下方進入它的release archives:https://archive.apache.org/dist/spark/ 選擇想要的版本,
關于版本的選擇
這里以2.4.8版本為例,我們下載的安裝檔案應該是形如:spark-2.4.8-bin-xxxxxx.tgz的檔案,很多人很困惑如何選擇這些版本,
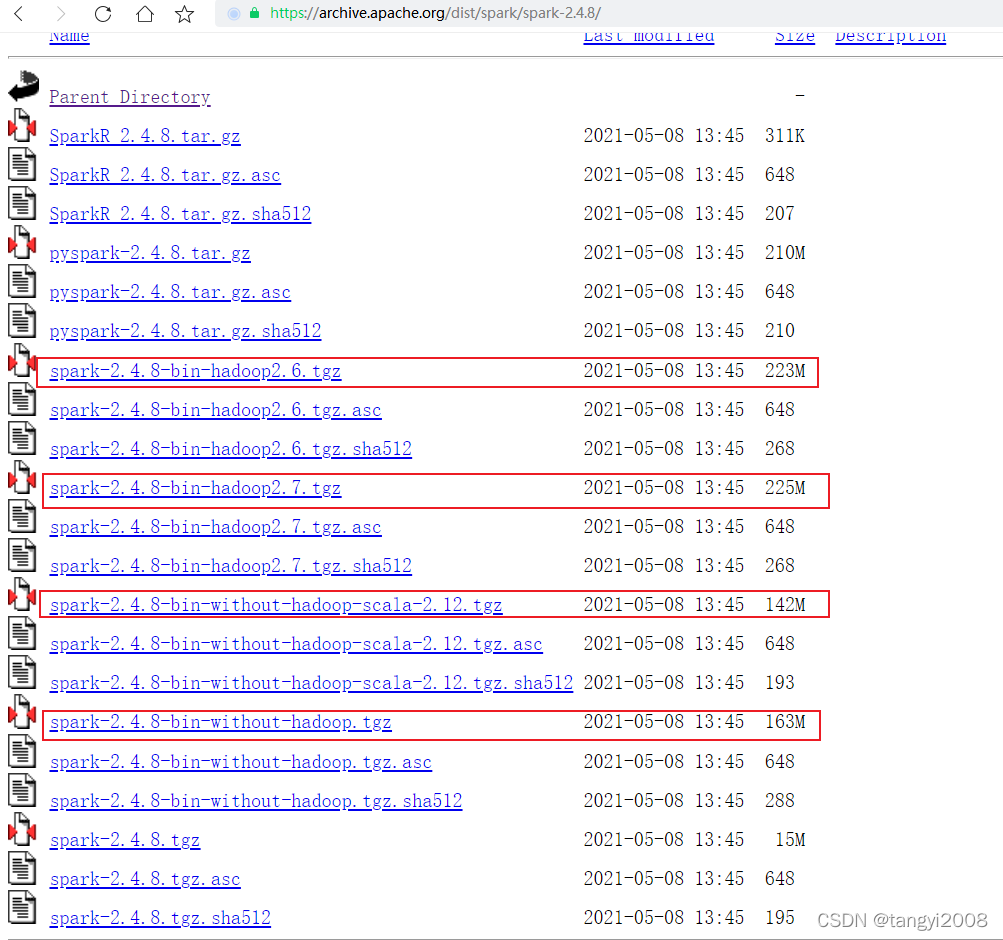
之所以會有這么多版本的選擇,是因為Spark需要一些Hadoop客戶端的依賴包(需要訪問HDFS和YARN), 這些版本主要分為兩類:
-
pre-packaged binary,將Hadoop客戶端的依賴包編譯到所下載的壓縮包當中,比如spark-2.4.8-bin-hadoop2.6.tgz 和spark-2.4.8-bin-hadoop2.7.tgz ,
-
“Hadoop free” binary,需要自己通過配置
SPARK_DIST_CLASSPATH變數,以便可以包含指定版本的Hadoop的相關jar包,比如:spark-2.4.8-bin-without-hadoop-scala-2.12.tgz、spark-2.4.8-bin-without-hadoop.tgz ,
我們這里選擇“Hadoop free” binary形式的spark-2.4.8-bin-without-hadoop.tgz進行下載,直接使用瀏覽器下載過慢,可以使用迅雷加速下載,也可以去后面的網盤資源進行下載,
2)安裝Spark
這里約定虛擬機主機名為node1,用戶名為xiaobai, 安裝路徑為/home/xiaobai/opt,如果不是,請自行修改相應組態檔,
上傳安裝包
將下載好的安裝包上傳至虛擬機(當然你也可以直接在虛擬機中下載,省得上傳檔案)
解壓并創建軟鏈接
tar -xvf spark-2.4.8-bin-without-hadoop.tgz -C ~/opt
cd ~/opt
ln -s spark-2.4.8-bin-without-hadoop spark
Spark的目錄結構
ls ~/opt/spark

- bin: 可執行腳本,比如常用的spark-shell, pyspark等,
- data:示例程式使用資料
- jars:依賴的jar包
- R:R API包
- yarn:整合yarn相關內容
- conf:組態檔目錄
- examples:示例程式
- kubernetes:K8S相關內容
- licenses:許可檔案
- python:python API包
- sbin:管理使用的腳本,比如: start-all.sh、start-master.sh等,
配置環境變數
vi ~/.bashrc修改 .bashrc 檔案,在檔案末尾添加Spark的PATH路徑
export SPARK_HOME=/home/xiaobai/opt/spark
export PATH=$SPARK_HOME/bin:$PATH
運行下面的命令使配置生效
source ~/.bashrc
配置Hadoop資訊
因為我們下載的是“Hadoop free” 版本,所以要配置SPARK_DIST_CLASSPATH 變數才能正常運行,
cd ~/opt/spark/conf
cp spark-env.sh.template spark-env.sh
vi spark-env.sh
在檔案末尾添加配置如下資訊
export SPARK_DIST_CLASSPATH=$(/home/xiaobai/opt/hadoop/bin/hadoop classpath)
修改日志級別
這一步可選,將日志級別調整至WARN級別,不至于看到過多的無效列印資訊
cd ~/opt/spark/conf
cp log4j.properties.template log4j.properties #日志組態檔
vi log4j.properties
修改如下配置:
log4j.rootCategory= WARN, console
日志也可以通過代碼進行調整,假設SparkContext物件為sc,則可以通過方法setLogLevel進行級別調整
sc.setLogLevel("WARN")
3)測驗安裝
到此,Spark安裝完成,此時便可使用Spark的local模式了,
注意
我們下載的Spark版本是基于scala 2.11.12,這時會報如下錯誤,但不影響使用.
[ERROR] Failed to construct terminal; falling back to unsupported
java.lang.NumberFormatException: For input string: "0x100"

可以修改環境變數TERM的值為xterm-color解決:
vi ~/.bashrc
在檔案末尾添加
export TERM=xterm-color
使配置生效
source ~/.bashrc
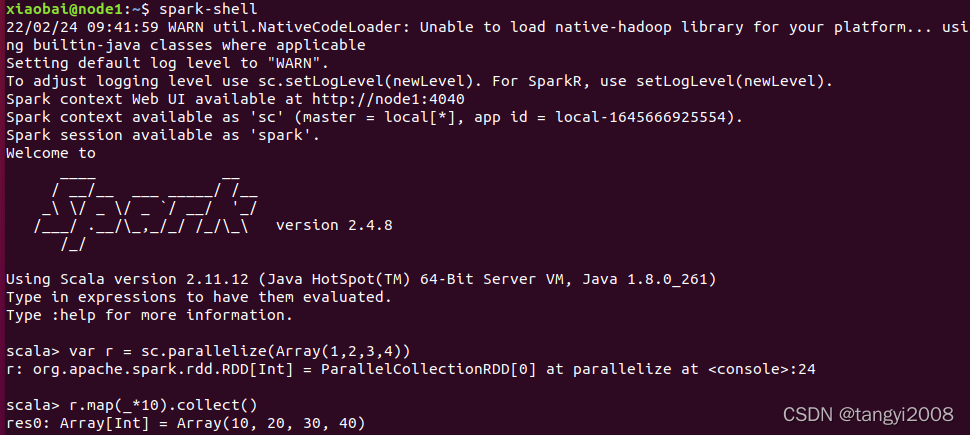
進入scala互動界面
使用如下命令進入scala互動界面:
spark-shell
運行代碼
var r = sc.parallelize(Array(1,2,3,4))
r.map(_*10).collect()
4)配置pyspark
安裝python
如果是ubuntu18+版本,系統已經默認安裝Python3
在ubuntu16以前,系統默認安裝python2, 需要運行命令sudo apt-get install python3安裝python3,當然也可以安裝像Anaconda這樣的Python發行版
創建python3的軟鏈接,這樣在使用Pyspark時,會以系統設定的python環境運行,
sudo ln -s /usr/bin/python3 /usr/bin/python
安裝pyspark開發包
注意,這里的Pyspark指的是在使用python編程時需要使用的pyspark模塊,類似Mysql與pymysql的關系,
可能使用在線安裝和手動拷貝中的其中一種安裝形式,推薦使用手動拷貝的方式,
- 在線安裝
sudo apt install python3-pip #安裝pip3
sudo pip install pyspark==2.4.8 -i https://pypi.tuna.tsinghua.edu.cn/simple
- 手動拷貝
進入python互動界面,查看python的path值
import sys
sys.path

將~/opt/spark/python/lib下的py4j-0.10.7-src.zip和pyspark.zip解壓拷貝到某一path路徑,比如:
cd ~/opt/spark/python/lib
unzip py4j-0.10.7-src.zip -d /usr/local/lib/python3.6/dist-packages
unzip pyspark.zip -d /usr/local/lib/python3.6/dist-packages
5) 配置Spark偽Standalone模式
這里配置Standalone模式,為了方便初學者,這里只配置一臺從節點,所以將其稱為"偽Standalone模式"
切換至組態檔目錄
cd ~/opt/spark/conf
spark-env.sh
vi spark-env.sh
添加如下配置資訊
export SPARK_MASTER_HOST=node1 #設定主節點地址
export SPARK_WORKER_MEMORY=2g #設定節點記憶體大小,此處為4G,
export SPARK_WORKER_CORES=2 #設定節點參與計算的核心數
export SPARK_WORKER_INSTANCES=1 #設定節點實體數
export JAVA_HOME=/home/xiaobai/opt/jdk
export HADOOP_CONF_DIR=/home/xiaobai/opt/hadoop/etc/hadoop
slaves
vi slaves
配置從節點資訊
node1
6) 測驗standalone模式
standalone啟動
~/opt/spark/sbin/start-all.sh
可以使用
start-master.sh、start-slave.sh和start-slaves.sh分別啟動Master節點,本機slave節點和所有slave節點此外,還會經常用到historysever,會用到腳本:
start-history-server.sh,需要在spark-env.sh中配置SPARK_HISTORY_OPTS引數:SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://node1:9000/sparklog/ -Dspark.history.fs.cleaner.enabled=true"
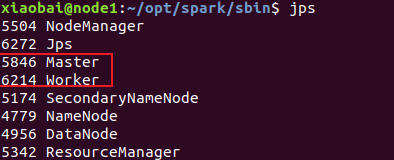
查看行程
jps
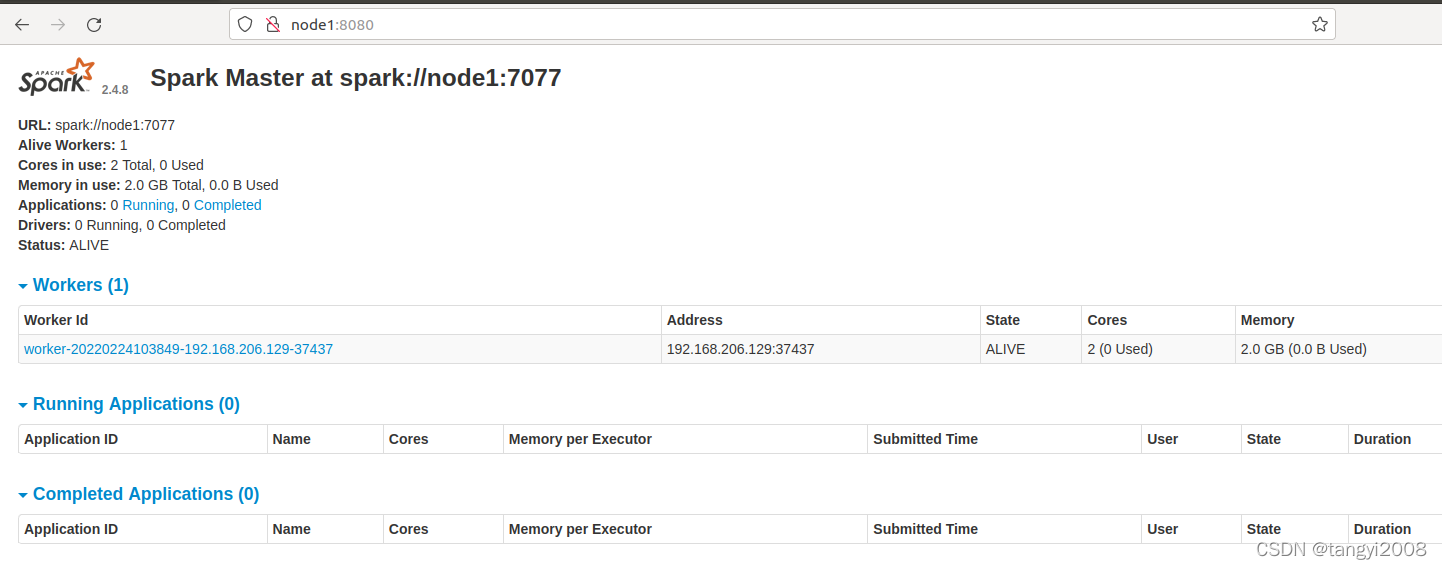
web查看
node1:8080
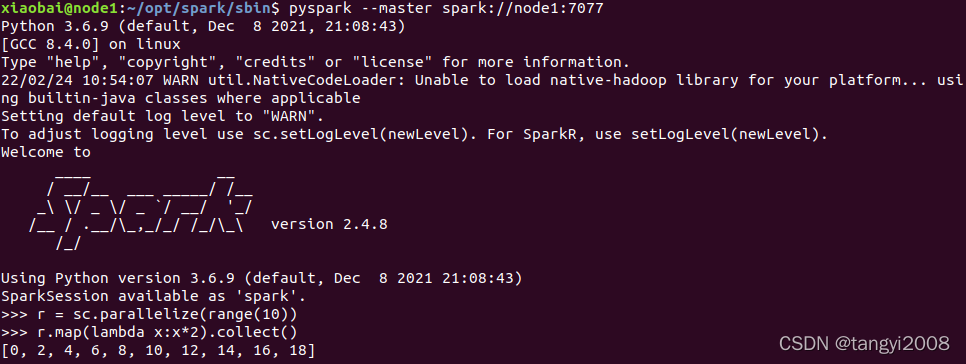
測驗
pyspark --master spark://node1:7077
運行測驗代碼
r = sc.parallelize(range(10))
r.map(lambda x:x*2).collect()
停止
~/opt/spark/sbin/stop-all.sh
可以使用
stop-master.sh、stop-slave.sh和stop-slaves.sh分別停止Master節點,本機slave節點和所有slave節點
7) 配置Web互動式環境
安裝jupyter
sudo pip3 install jupyter -i https://pypi.tuna.tsinghua.edu.cn/simple
啟動jupyter進入互動界面
jupyter notebook
或者
jupyter lab
嘗試運行代碼
from pyspark import SparkConf, SparkContext
conf = SparkConf().setMaster('local').setAppName("My App")
sc = SparkContext(conf = conf)
logFile = "file:///home/xiaobai/opt/spark/README.md"
logData = sc.textFile(logFile, 2).cache()
numAs = logData.filter(lambda line: 'a' in line).count()
numBs = logData.filter(lambda line: 'b' in line).count()
print('Lines with a: %s, Lines with b: %s' % (numAs, numBs))
3. 代碼提交
撰寫wordcount程式
vi wordcount.py
撰寫代碼:
from pyspark import SparkConf, SparkContext
conf = SparkConf().setAppName("My App")
sc = SparkContext(conf = conf)
logFile = "file:///home/xiaobai/opt/spark/README.md"
logData = sc.textFile(logFile, 2).cache()
numAs = logData.filter(lambda line: 'a' in line).count()
numBs = logData.filter(lambda line: 'b' in line).count()
print('Lines with a: %s, Lines with b: %s' % (numAs, numBs))
提交代碼到local
spark-submit wordcount.py
提交代碼到Standalone
請確保已開啟master和worker
spark-submit --master spark://node1:7077 wordcount.py
提交代碼到YARN
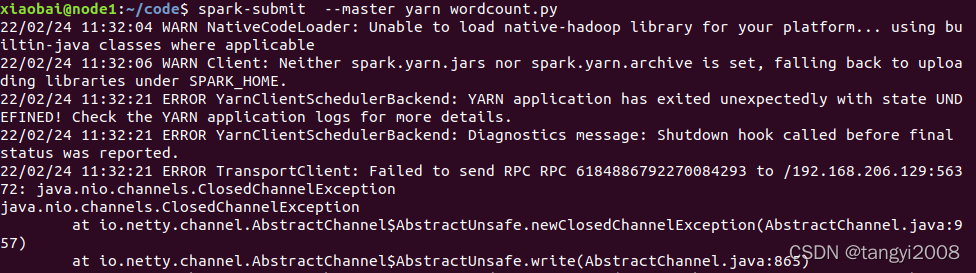
spark-submit --master yarn wordcount.py
注意:
因為我們采用的是偽分布式,主機記憶體可能不夠,可能導致如下錯誤
ERROR TransportClient: Failed to send RPC RPC 6184886792270084293 to /192.168.206.129:56372: java.nio.channels.ClosedChannelException
可以修改Hadoop的yarn-site.xml配置,然后重啟YARN即可,
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
spark-submit常用引數,可以使用help命令查看:
spark-submit --help常用引數:
Options: --master MASTER_URL spark://host:port, mesos://host:port, yarn, k8s://https://host:port, or local (Default: local[*]). --deploy-mode DEPLOY_MODE Whether to launch the driver program locally ("client") or on one of the worker machines inside the cluster ("cluster"), (Default: client). --class CLASS_NAME Your application's main class (for Java / Scala apps). --name NAME A name of your application. --jars JARS Comma-separated list of jars to include on the driver and executor classpaths. --packages Comma-separated list of maven coordinates of jars to include on the driver and executor classpaths. Will search the local maven repo, then maven central and any additional remote repositories given by --repositories. The format for the coordinates should be groupId:artifactId:version
三、相關資源
鏈接:https://pan.baidu.com/s/1u3Qbj2VQ8UbuSuGQOWjWCg
提取碼:nuli
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/432170.html
標籤:其他
上一篇:Flink RPC原始碼流程