??大家好,我是陳哈哈,北漂五年,相信大家和我一樣,
都有一個大廠夢,作為一名資深Java選手,深知面試重要性,接下來我準備用100天時間,基于Java崗面試中的高頻面試題,以每日3題的形式,帶你過一遍熱門面試題及恰如其分的解答,
??一路走來,隨著問題加深,發現不會的也愈來愈多,但底氣著實足了不少,相信不少朋友和我一樣,榷訓月累才是最有效的學習方式!想起高三時一個同學的座右銘:只有沉下去,才能浮上來,共勉(juan),

這是由蔣玉樹先生所拍攝的照片《小店》
在四川涼山,母親臨時有事,讓自己的女兒幫忙看店
突然天上下起了雪,在這個只有一面墻的小店里
女孩兒一邊搓著手,一邊欣賞著美景
這是我們之前文章結尾《一張照片背后的故事》模塊的其中一張,今天看到還是挺扎心的,決定這個欄目重新打開,繼續分享給大家,
車票
- 面試題1:分布式id生成方案有哪些?
- 追問1:雪花演算法生成的ID由哪些部分組成?
- 面試題2:分布式鎖在專案中有哪些應用場景
- 面試題3:分布式鎖有哪些解決方案
- 每日小結
??本欄目Java開發崗高頻面試題主要出自以下各技術堆疊:Java基礎知識、集合容器、并發編程、JVM、Spring全家桶、MyBatis等ORMapping框架、MySQL資料庫、Redis快取、RabbitMQ訊息佇列、Linux操作技巧等,
面試題1:分布式id生成方案有哪些?
??分布式系統中我們會對一些資料量大的業務進行分拆,如:用戶表,訂單表,因為資料量巨大一張表無法承接,就會對其進行分庫分表,但一旦涉及到分庫分表,就會引申出分布式系統中唯一主鍵ID的生成問題,
唯一ID的特性:
- 全域唯一
- 趨勢有序,方便進行時間先后判斷
- 高可用
- 資訊安全,ID雖然趨勢有序,但是不可以被看出規則,免得被爬,例如爬取你專案的商品URL串列是有序的https://xxxx.xxx/1-10000,有手就能爬
延伸:基于MAC地址生成UUID的演算法造成的MAC地址泄露,這個漏洞曾被用于尋找梅麗莎病毒的制作者位置,
常見的方案有:UUID,資料庫主鍵自增,Redis自增ID,雪花演算法,
| 描述 | 優點 | 缺點 | |
|---|---|---|---|
| UUID | UUID是通用唯一標識碼的縮寫,其目的是讓分布式系統中的所有元素都有唯一的辨識資訊,而不需要通過中央控制器來指定唯一標識,生成演算法的核心思想是結合機器的網卡、當地時間、一個隨記數來生成UUID, | 1. 降低全域節點的壓力,使主鍵生成速度更快,因為是本機生成,也沒有性能問題; 2. 生成全球唯一的ID,遷移資料容易; | 1. UUID占用16個字符,空間占用多; 2. 無序,資料寫入IO隨機性很大,索引效率下降; 3. 可讀性差 |
| 資料庫主鍵自增 | MySQL資料庫設定主鍵自增即可自動增長 | 1. INT和BIGINT型別占用空間較小; 2. 主鍵自動增長,IO寫入連續性好; 3. 數字型別查詢速度優于字串 | 1. 并發性能不高,受限于資料庫性能,依賴資料庫查詢; 2. 分庫分表,需要改造,復雜; 3. 自增:資料和資料量泄露 |
| Redis自增 | Redis計數器,原子性自增 | 不依賴于資料庫,且性能優于資料庫, | 1. 需要考慮Reids宕機資料丟失等問題; 2. 自增出現的資料量泄露問題 |
| 雪花演算法(snowflake) | 分布式ID的經典解決方案,twitter開源的分布式ID生成演算法,核心思想是:一個Long型別的ID,其中41bit作為毫秒數,10bit作為機器碼,12bit作為毫秒內序列號, | 不依賴外部組件,高性能,低延遲,按時間有序,一般不會造成ID碰撞 | 時鐘回撥問題,依賴于機器的時間 |
追問1:雪花演算法生成的ID由哪些部分組成?
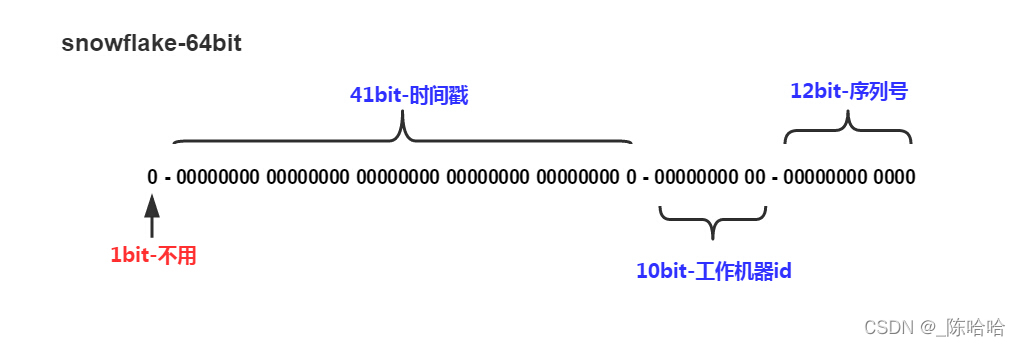
??如上圖的所示,Snowflake 演算法由下面幾部分組成:
- 1位符號位:
??由于 long 型別在 java 中帶符號的,最高位為符號位,正數為 0,負數為 1,且實際系統中所使用的ID一般都是正數,所以最高位為 0,
- 41位時間戳(毫秒級):
??需要注意的是此處的 41 位時間戳并非存盤當前時間的時間戳,而是存盤時間戳的差值(當前時間戳 - 起始時間戳),這里的起始時間戳一般是ID生成器開始使用的時間戳,由程式來指定,所以41位毫秒時間戳最多可以使用 (1 << 41) / (1000x60x60x24x365) = 69年,
- 10位資料機器位:
??包括5位資料標識位和5位機器標識位,這10位決定了分布式系統中最多可以部署 1 << 10 = 1024 s個節點,超過這個數量,生成的ID就有可能會沖突,
- 12位毫秒內的序列:
??這 12 位計數支持每個節點每毫秒(同一臺機器,同一時刻)最多生成 1 << 12 = 4096個ID加起來剛好64位,為一個Long型,
SnowFlake演算法實作了:
- 生成的id按時間趨勢遞增
- 唯一,整個分布式系統內不會產生重復id(datacenterId和workerId來做區分)
??演算法的github鏈接
課間休息,進入《一張照片背后的故事》環節

張良善在1986年,成為一名西藏運輸兵,每條西藏公路上都有他的身影
1992年,張良善懷孕的妻子,重病住院
領導了解情況后批準他回家,可當時西藏的將士們缺衣少食
如果不在惡劣天氣來臨前運輸完物資,將士們很可能有生命危險
他選擇留下來,繼續為將士們運輸物資
但當任務結束后,妻子卻因難產而死
最后他親手雕刻了妻子的墓碑,并跪在墳前痛哭
面試題2:分布式鎖在專案中有哪些應用場景
??說使用場景前我們要知道為什么用分布式鎖,正所謂“從哪來,到哪去”,在從前用戶體量小時,單機就可以滿足用戶請求數,雖然有一定的并發度,但通過簡單的鎖機制就可以控制資源獲取,隨著業務體量增大,并發度單機抗不住了,為滿足業務高可用開始使用集群,集群間的并發事務畢竟不能通過各臺的單機鎖實作,各玩兒各的還不亂套了,于是就出現了分布式鎖,
??分布式鎖是協調集群中多應用之間的共享資源的獲取的一種方式,可以說它是一種約束、規則,
??那么分布式鎖應該滿足什么條件呢?也就是它應該具備怎樣的約束、規則?
鎖的互斥性:在分布式集群應用中,共享資源的鎖在同一時間只能被一個物件獲取,可重入:為了避免死鎖,這把鎖是可以重入的,并且可以設定超時,高效的加鎖和解鎖:能夠高效的加鎖和解鎖,獲取鎖和釋放鎖的性能也好,阻塞、公平:可以根據業務的需要,考慮是使用阻塞、還是非阻塞,公平還是非公平的鎖,
課間休息,進入《一張照片背后的故事》環節
默
是心靈的寄托
面試題3:分布式鎖有哪些解決方案
??分布式鎖在面試中問到的常見實作方式有以下三種:資料庫分布式鎖、Redis實作分布式鎖、ZooKeeper實作分布式鎖,
3-1、資料庫分布式鎖
??該方案利用了主鍵惟一的特點,若多個請求同時提交到資料庫,基于ACID特性,能保證只有一個執行緒能夠操做成功,
??如果是使用悲觀鎖(排它鎖)select ... where ... for update的加鎖方式,由于其復雜的加鎖和解鎖、事務等一系列消耗性能的操作,滿足不了多少并發,
??而樂觀鎖是基于版本號控制的方式實作,類似于CAS(Compare And Swap 比較并替換)鎖,它認為操作的程序并不會存在并發的情況,只有在update version的時候才會去比較,
??樂觀鎖實作方式還是存在很多問題的,一個是并發性能問題,再者不可重入以及沒有失效時間的功能、非公平鎖,只要當前的庫表中已經存在該資訊,執行插入就會失敗,
??當然也有相對的解決方案:比如針對不可重復的問題,可以通過增加欄位保存當前執行緒的資訊以及可重復的次數,只要判斷是當前執行緒,可重復的次數就會+1,每次執行釋放鎖就會-1,直到為0,
??再比如針對非公平鎖可以增加一個中間表的形式,作為一個排隊佇列,競爭的執行緒都會按照時間存盤于這個中間表,當要某個執行緒嘗試獲取某個方法的鎖的時候,檢查中間表中是否已經存在等待的佇列來解決,每次只要獲取中間表中最小的時間的鎖,也能實作公平的排隊等候效果,
3-2、基于redis實作分布式鎖
??Redis實作分布式鎖的方式有多種,可以使用setnx、getset、expire、del 這四個命令來實作,
- setnx:命令表示
如果key不存在,就會執行set命令,若是key已經存在,不會執行任何操作, - getset:將key設定為給定的value值,并回傳原來的舊value值,若是key不存在就會回傳回傳nil ,
- expire:
設定key生存時間,當當前時間超出了給定的時間,就會自動洗掉key, - del:洗掉key,它可以洗掉多個key,語法如下:DEL key [key …],若是key不存在直接忽略,
??加鎖實際上就是在redis中,給Key鍵設定一個值,為避免死鎖,并給定一個過期時間,
SET lock_key random_value NX PX 10000
值得注意的是:
- random_value 是客戶端生成的唯一的字串,
- NX 代表只在鍵不存在時,才對鍵進行設定操作,
- PX 10000 設定鍵的過期時間為10000毫秒,
??說到Redis分布式鎖,目前基本都是直接引入了Redisson框架,做了很好的封裝,非常簡便,看看下面的代碼片段感受一下:
Rlock rlock = redisson.getLock("myLock");
rlock.lock();
rlock.unlock();
??是不是感覺很簡單,因為多執行緒競爭共享資源的復雜的程序它在底層都幫你實作了,屏蔽了這些復雜的程序,而你也就成為了優秀的API呼叫者,
??當然,面試中大概率會考察其實作原理,下面通過Redisson的架構圖,看看這個開源框架對Redis分布式鎖的實作原理;
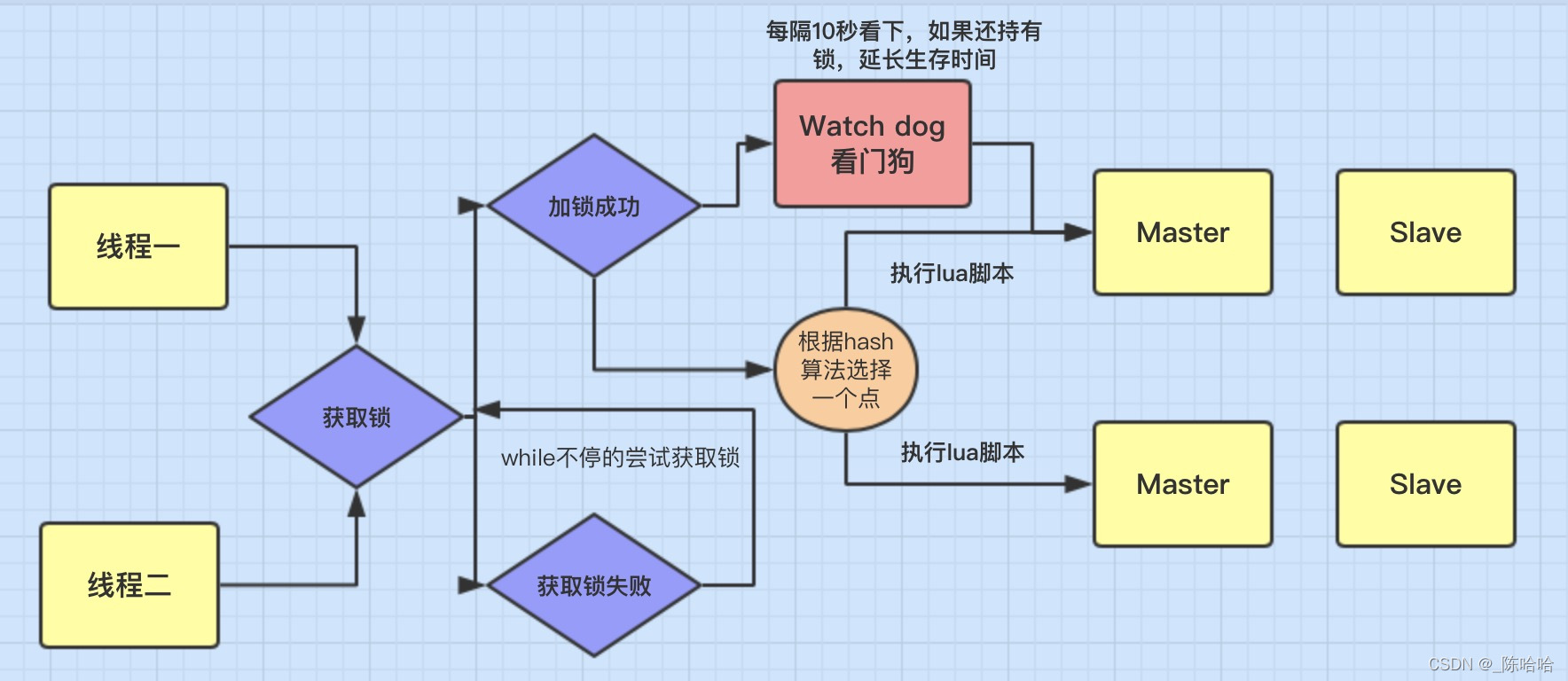
3-2-1、加鎖機制
-
執行緒去獲取鎖,獲取成功:執行lua腳本,保存資料到redis資料庫,(lua腳本實作了業務執行的
原子性,語法簡單好上手) -
執行緒去獲取鎖,獲取失敗:一直通過while自旋嘗試獲取鎖,獲取成功后,執行lua腳本,保存資料到redis資料庫,
3-2-2、watch dog自動延期機制
??在一個分布式環境下,假如一個執行緒獲得鎖后,突然服務器宕機了,那么在一定時間(過期時間)后這個鎖要自動釋放,如果不設定默認是30s,這個過期時間的目的是防止死鎖的發生,
??而實際開發中會有這種情況,比如過期時間設了10s,但由于網路延遲或介面本身慢查詢等原因,導致請求時間超過10s還沒結束(注意,這里并未宕機,不應該釋放鎖),但在10s時鎖被釋放,其他執行緒進來也操作該資料,就可能造成資料不一致問題,
??所以這個時候看門狗就出現了,它的作用就是執行緒1業務還沒有執行完,時間就過了,執行緒1還想持有鎖的話,就會啟動一個watch dog后臺執行緒,不斷的延長鎖key的生存時間,
??值得注意的是,正常這個看門狗執行緒是不啟動的,還有就是這個看門狗啟動后對整體性能也會有一定影響,所以不建議開啟watch dog,
3-2-3、為啥要用lua腳本呢?
??這個不用多說,主要是如果你的業務邏輯復雜的話,通過封裝在lua腳本中一起發送給redis,像存盤程序,因為redis是單執行緒的,這樣就保證這段復雜業務邏輯執行的原子性,
3-2-4、可重入鎖機制
??可重入鎖是指一個鎖在被一個執行緒持有后,在該執行緒未釋放鎖前的任何時間內,只要再次訪問被該鎖鎖住的函式區都可以再次進入對應的鎖區域,可重入鎖有一個可重入度的概念,即每次重新進入一次該鎖的鎖住的區域都會遞增可重入度,每次退出一個該鎖鎖住的區域都會遞減可重入度,最終釋放全部鎖后,可重入度為0,
??可重入鎖指的是可重復可遞回呼叫的鎖,在外層使用鎖之后,在內層仍然可以使用,如果沒有可重入鎖的支持,在第二次嘗試獲得鎖時將會進入死鎖狀態,
??Redisson的可重入鎖機制和Hash型別有關,比如下面是一個key值:
127.0.0.1:6379> HGETALL myLock
1) "285475da-9152-4c83-822a-67ee2f116a79:52"
2) "2"
??Hash型別相當于我們java的 <key,<key1,value>> ,Hash資料型別的key值包含了當前執行緒資訊,hash 結構的 key 是鎖的名稱,key1 是客戶端 ID,value 是該客戶端加鎖的次數,
- 缺點
- 獲取鎖是非阻塞
- 非公平鎖,不支持須要公平鎖的場景
- redis主從存在延遲,在master宕機發生主從切換時,可能會致使鎖失效
3-3、基于zookeeper實作分布式鎖
??基于以上兩種實作方式,有了基于zookeeper實作分布式鎖的方案,由于zookeeper有以下特點:
-
維護了一個有層次的資料節點,類似檔案系統,
-
有以下資料節點:臨時節點、持久節點、臨時有序節點(分布式鎖實作基于的資料節點)、持久有序節點,
-
zookeeper可以和client客戶端通過心跳的機制保持長連接,如果客戶端鏈接zookeeper創建了一個臨時節點,那么這個客戶端與zookeeper斷開連接后會自動洗掉,
-
zookeeper的節點上可以注冊上用戶事件(自定義),如果節點資料洗掉等事件都可以觸發自定義事件,
-
zookeeper保持了統一視圖,各服務對于狀態資訊獲取滿足一致性,
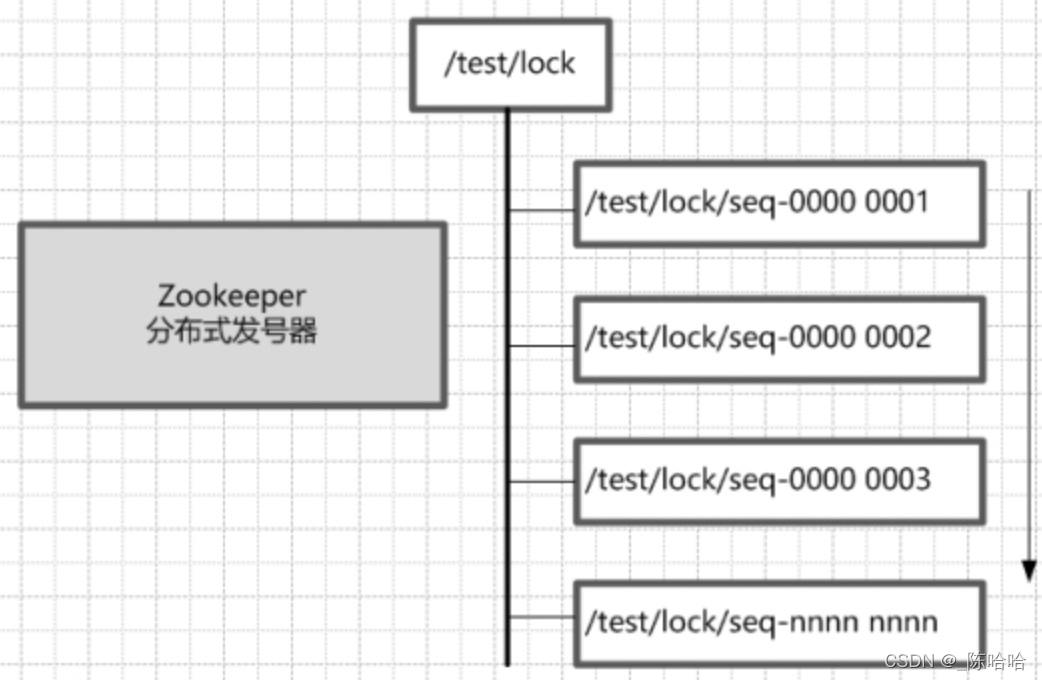
??Zookeeper的每一個節點,都是一個天然的順序發號器,在每一個節點下面創建子節點時,只要選擇的創建型別是有序(EPHEMERAL_SEQUENTIAL 臨時有序或者PERSISTENT_SEQUENTIAL 永久有序)型別,那么,新的子節點后面,會加上一個次序編號,這個次序編號,是上一個生成的次序編號加一
- 排他鎖(非公平鎖)
??排他鎖核心是保證當前有且僅有一個事務獲得鎖,并且鎖釋放之后,所有正在等待獲取鎖的事務都能夠被通知到,
??Zookeeper的強一致性特性,能夠很好地保證在分布式高并發情況下節點的創建一定能夠保證全域唯一性,即Zookeeper將會保證客戶端無法重復創建一個已經存在的資料節點,可以利用Zookeeper這個特性,實作排他鎖,
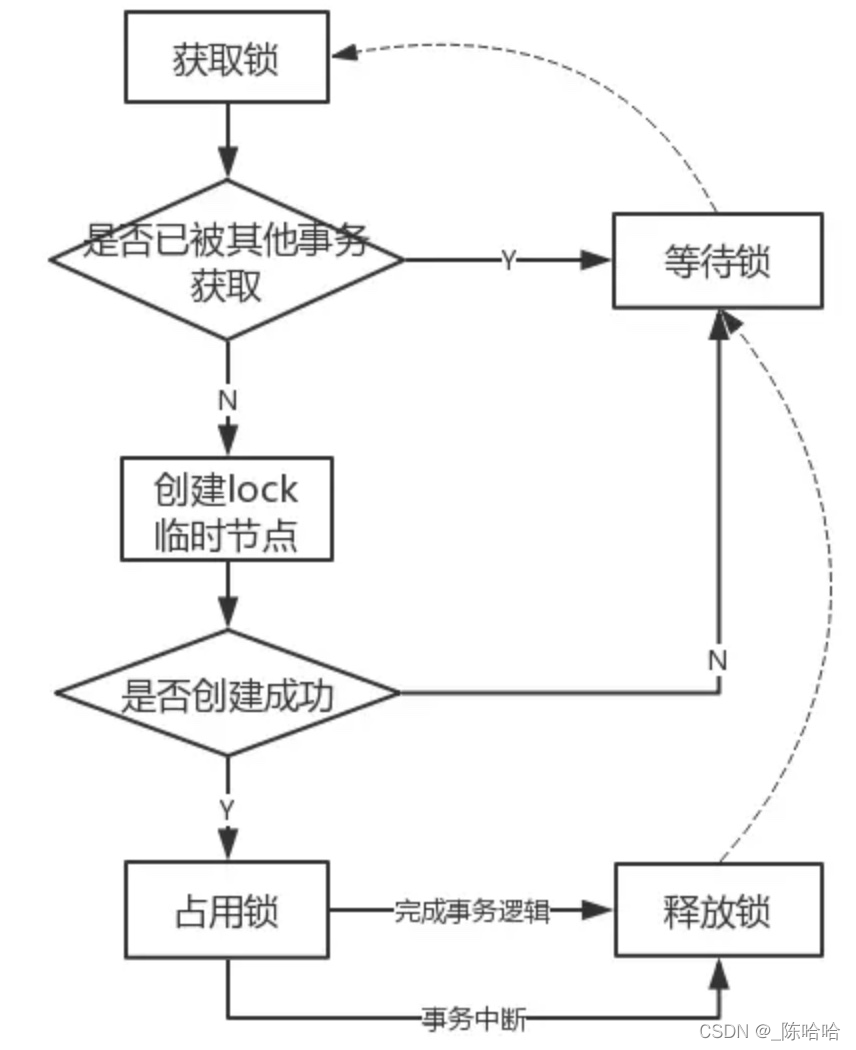
-
定義鎖:通過Zookeeper上的資料節點來表示一個鎖
-
獲取鎖:客戶端通過呼叫 create 方法創建表示鎖的臨時節點,可以認為創建成功的客戶端獲得了鎖,同時可以讓沒有獲得鎖的節點在該節點上注冊Watcher監聽,以便實時監聽到lock節點的變更情況
-
釋放鎖:以下兩種情況都可以讓鎖釋放
– 當前獲得鎖的客戶端發生宕機或例外,那么Zookeeper上這個臨時節點就會被洗掉
– 正常執行完業務邏輯,客戶端主動洗掉自己創建的臨時節點
基于Zookeeper實作排他鎖流程:
三、共享鎖
??共享鎖與排他鎖的區別在于,加了排他鎖之后,資料物件只對當前事務可見,而加了共享鎖之后,資料物件對所有事務都可見,
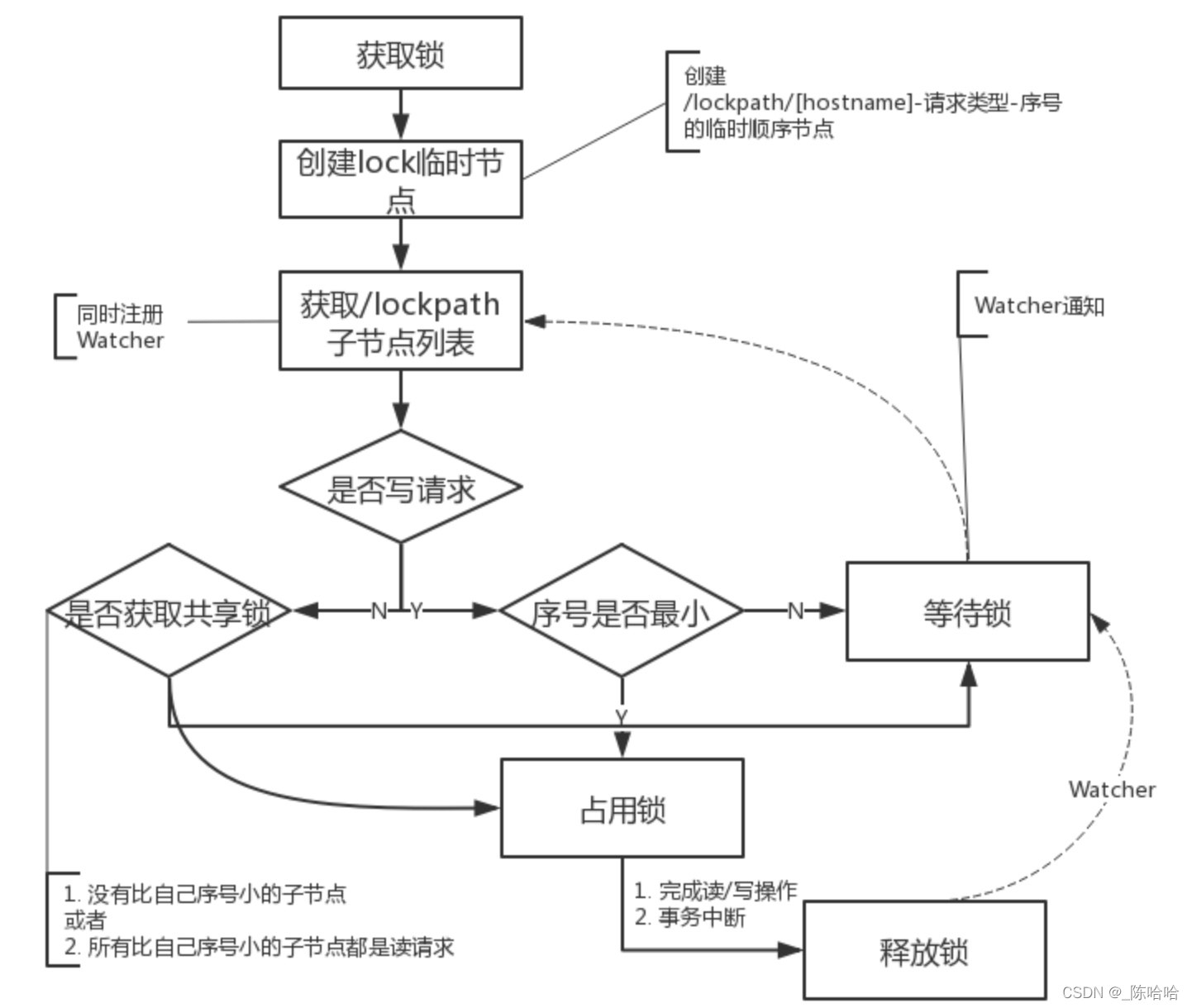
定義鎖:通過Zookeeper上的資料節點來表示一個鎖,是一個類似于 /lockpath/[hostname]-請求型別-序號 的臨時順序節點獲取鎖:客戶端通過呼叫 create 方法創建表示鎖的臨時順序節點,如果是讀請求,則創建 /lockpath/[hostname]-R-序號 節點,如果是寫請求則創建 /lockpath/[hostname]-W-序號節點
判斷讀寫順序:大概分為幾個步驟- 創建完節點后,獲取 /lockpath 節點下的所有子節點,并對該節點注冊子節點變更的Watcher監聽
- 確定自己的節點序號在所有子節點中的順序
- 對于讀請求:1. 如果沒有比自己序號更小的子節點,或者比自己序號小的子節點都是讀請求,那么表明自己已經成功獲取到了共享鎖,同時開始執行讀取邏輯 2. 如果有比自己序號小的子節點有寫請求,那么等待
- 對于寫請求,如果自己不是序號最小的節點,那么等待
- 接收到Watcher通知后,重復步驟1)
釋放鎖:與排他鎖邏輯一致
基于Zookeeper實作共享鎖流程:
三種方案總的來看:
性能: 快取 > Zookeeper >= 資料庫,
可靠性: Zookeeper > 快取 > 資料庫
每日小結
??今天我們復習了Redis中常考的幾個問題,你做到心中有數了么?對了,如果你的朋友也在準備面試,請將這個系列扔給他,如果他認真對待,肯定會感謝你的!!好了,今天就到這里,學廢了的同學,記得在評論區留言:打卡 + 日期,,給同學們以激勵,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/432173.html
標籤:其他