在建模之前要對資料進行探索性分析,首先要對資料分布有一個大致了解,matplotlib里面有自帶的hist()函式,直接data.hist(),全部特征的分布狀態就能在一張畫布上展示出來,對于一個樣本量較小的資料集來說,非常方便(700多個樣本,60幾個特征),比如這樣:
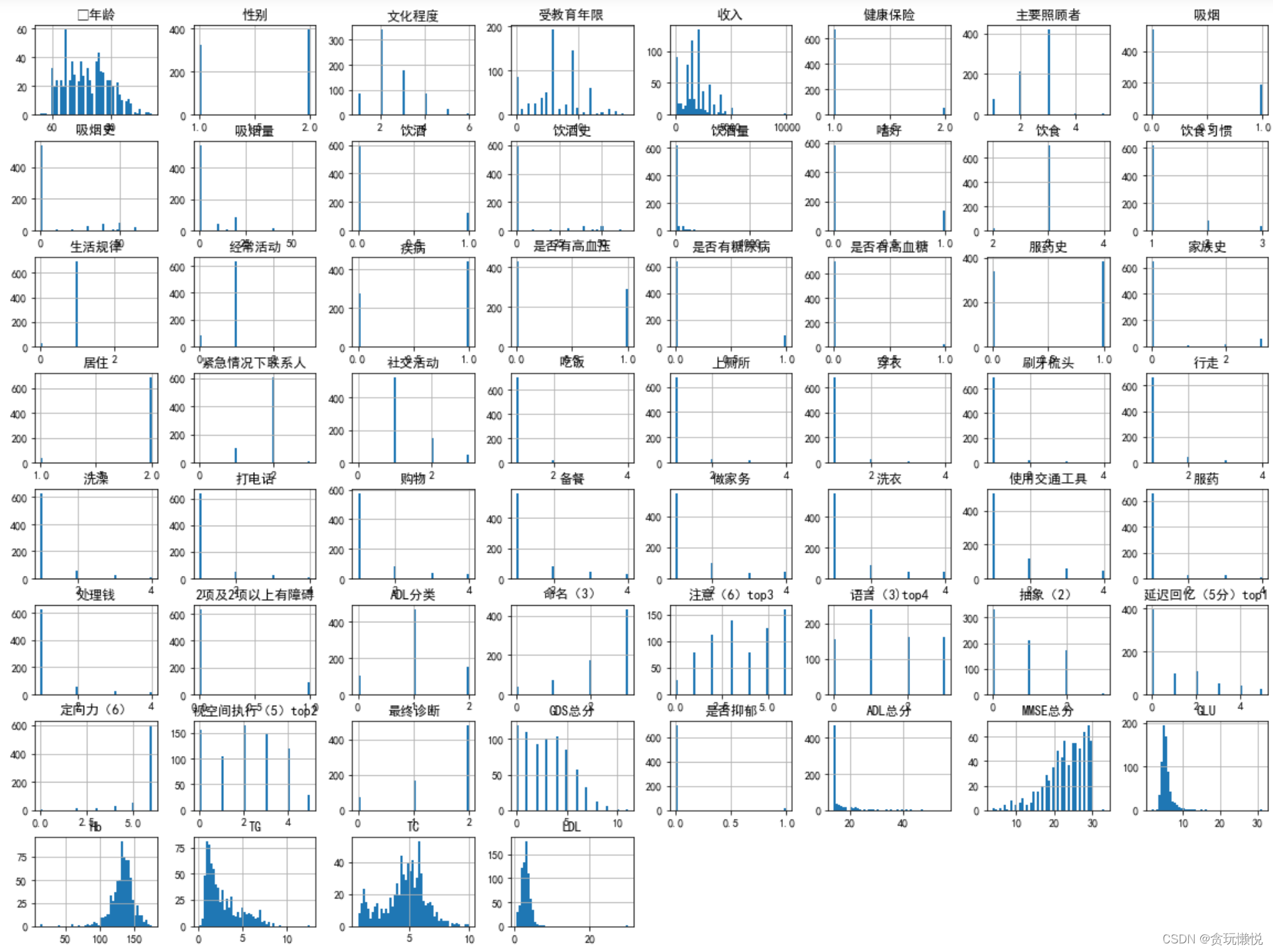
在一個樣本量為300多萬的資料集上面跑了一下,效果也還可以,優點是速度真的很快(對比后面自己寫的那個函式),但是真的沒法看得很精細,比如這個資料集的幾個特征分布圖都有這樣的特點(拿第一行第四幅圖舉例):大量資料集中在0附近,往后就空空如也,如果真的資料在后面的區間里沒有分布,那為什么函式要畫出來呢?
data.hist(bins=50,figsize=(20,15))
plt.show()
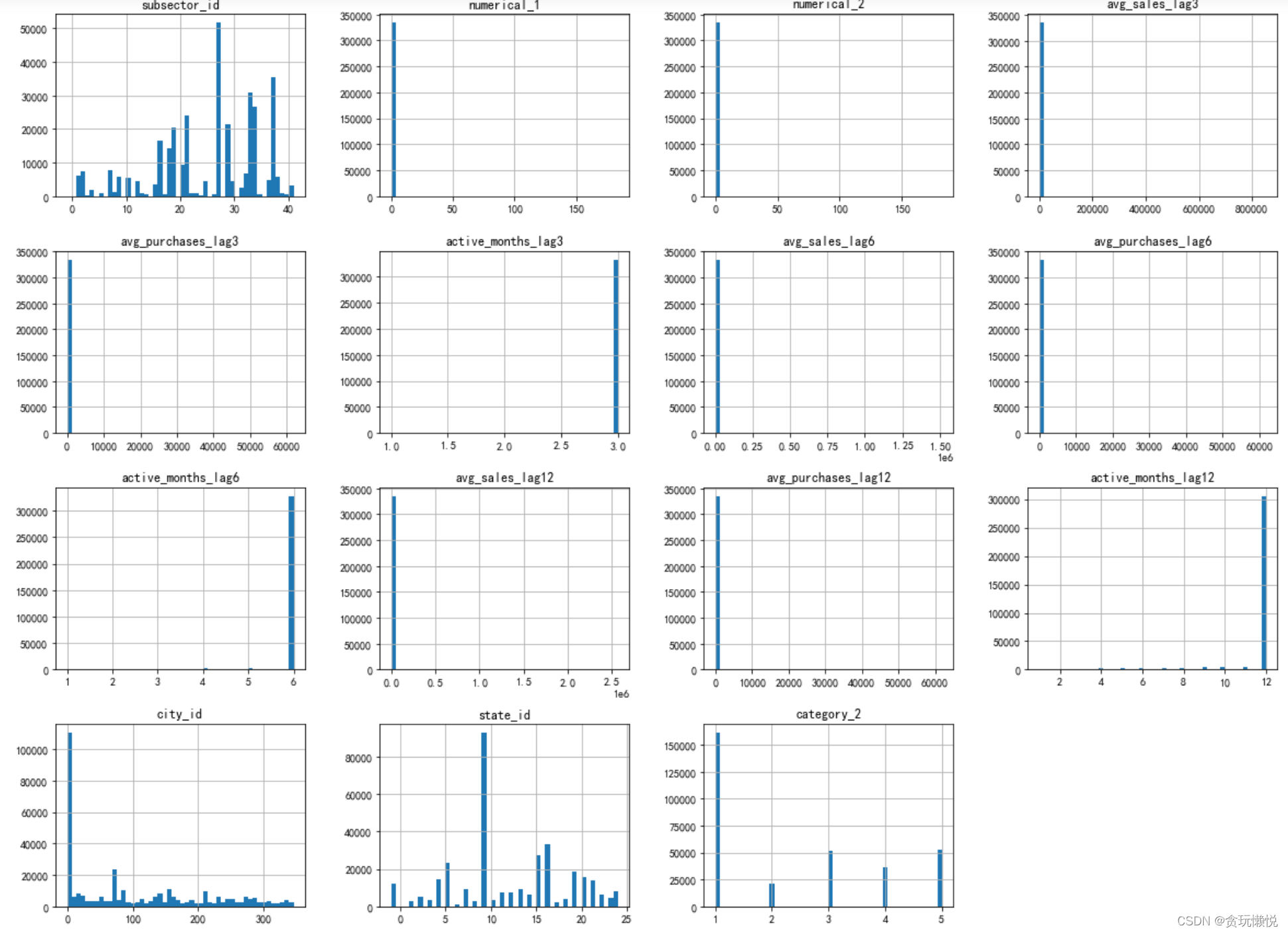 這個時候還是要結合.value_counts()函式來看一下:
這個時候還是要結合.value_counts()函式來看一下:
merchant['avg_sales_lag3'].value_counts().sort_index()
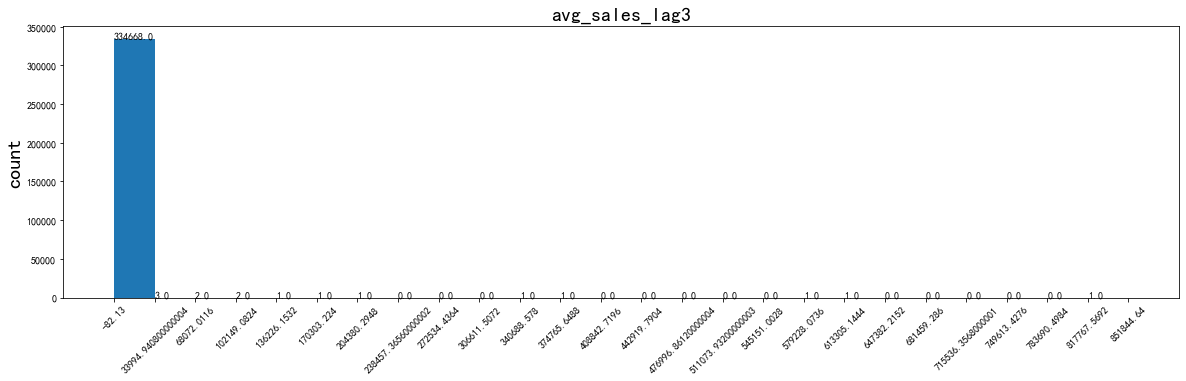
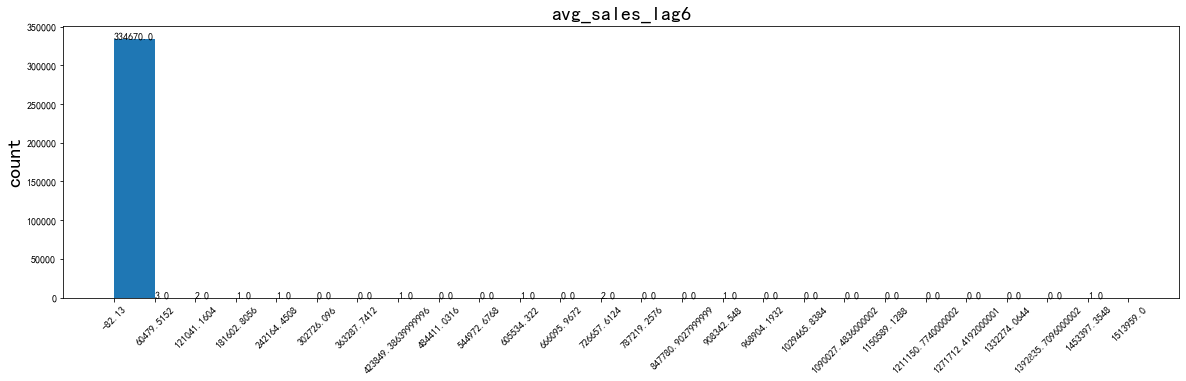
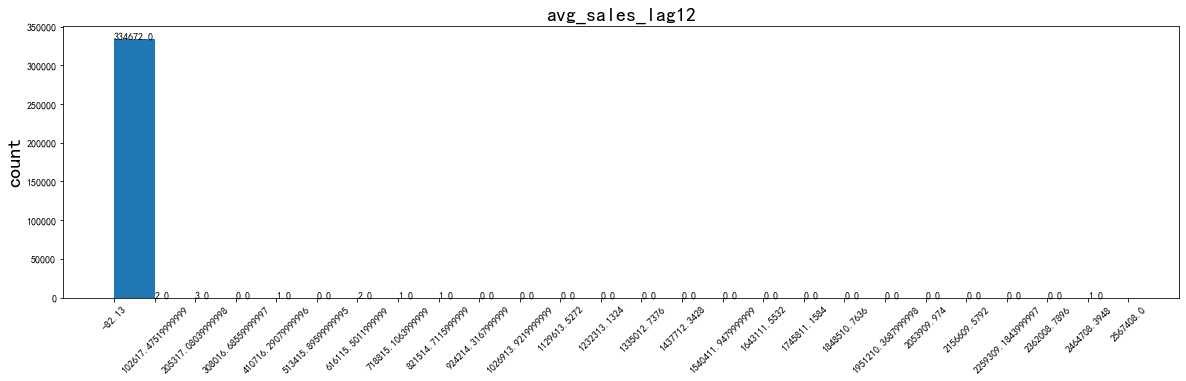
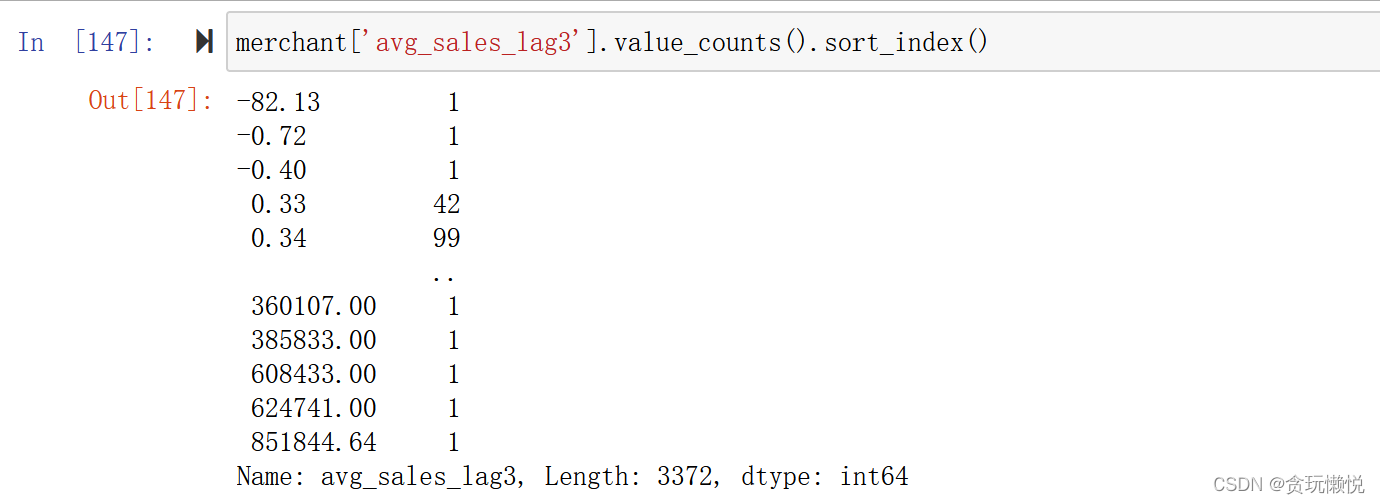 可以看到:資料不僅分布在大于0的區間,其實小于0的區間還是存在蠻多樣本的,而當數值非常大的時候資料分布得很稀疏,“貧富差距”及其大得偏態分布樣本,試想一下,如果這個變數存在一些缺失值,要怎樣填補呢?如果直接用均值來填補的話,是不是很容易因為最大值太大而把資料分布拉偏呢?但當我用data.hist()方法來進行資料探索的時候,我真的因為對這個變數分布認識得不到位,而選擇了不恰當的填補方式,
可以看到:資料不僅分布在大于0的區間,其實小于0的區間還是存在蠻多樣本的,而當數值非常大的時候資料分布得很稀疏,“貧富差距”及其大得偏態分布樣本,試想一下,如果這個變數存在一些缺失值,要怎樣填補呢?如果直接用均值來填補的話,是不是很容易因為最大值太大而把資料分布拉偏呢?但當我用data.hist()方法來進行資料探索的時候,我真的因為對這個變數分布認識得不到位,而選擇了不恰當的填補方式,
當資料量非常大時,容易出現的一個情況就是:有些連續性變數的取值范圍很大、很散,而分型別變數索取的幾個值之間距離也很大,這時候對分類變數畫出的直方圖也特別奇怪,
而且如果資料中有NaN、inf的情況下,直接data.hist()這種方法行不通,會報錯,反而是把每個特征單獨挑出來用plt.hist()繪制直方圖不會報錯,就直接把里面的NaN、inf忽略了,所以在資料沒有處理得很干凈的時候,直接使用data.hist()來粗略地探索資料分布比較麻煩,也不靈活,
所以就想到將數值型連續變數與分型別變數分開進行資料探索,對于連續數值型變數,可以用直方圖,而對于分型別變數,可以用條形圖來呈現大致分布,
下面是對于這個功能撰寫的一個自定義函式,需要輸入的引數有:
| 引數 | 作用 |
|---|---|
| data | dataframe形式的資料集 |
| variablet | 特征名稱,得是字串 |
| va_type | 兩個選擇:‘numeric’時對數值型變數繪制直方圖,‘category’時對分型別變數繪制條形圖 |
def data_distribution_explore(data,variable,va_type):
if va_type=='numeric':
distri=data[variable].values.tolist()
plt.figure(figsize=(20,5))
nums,bins,patches = plt.hist(distri,bins=25)
plt.xticks(bins,bins)
plt.xticks(rotation=45)
for num,bin in zip(nums,bins):
plt.annotate(num,xy=(bin,num),xytext=(bin+1.5,num+0.5))
plt.title(variable,fontsize=20)
# plt.xlabel(variable,fontsize=20)
plt.ylabel('count',fontsize=20)
if va_type =='category':
distri=data[variable].value_counts().sort_index()
plt.figure(figsize=(20,5))
bar=plt.bar(distri.index, distri.values, 0.6)
for rect in bar:
height = rect.get_height()
plt.annotate('{}'.format(height),
xy=(rect.get_x() + rect.get_width() / 2, height),
xytext=(0, 0.8),#柱子上方距離
textcoords="offset points",
ha='center', va='bottom')
plt.title(variable,fontsize=20)
# plt.xlabel(variable,fontsize=20)
plt.ylabel('count',fontsize=20)
plt.show()
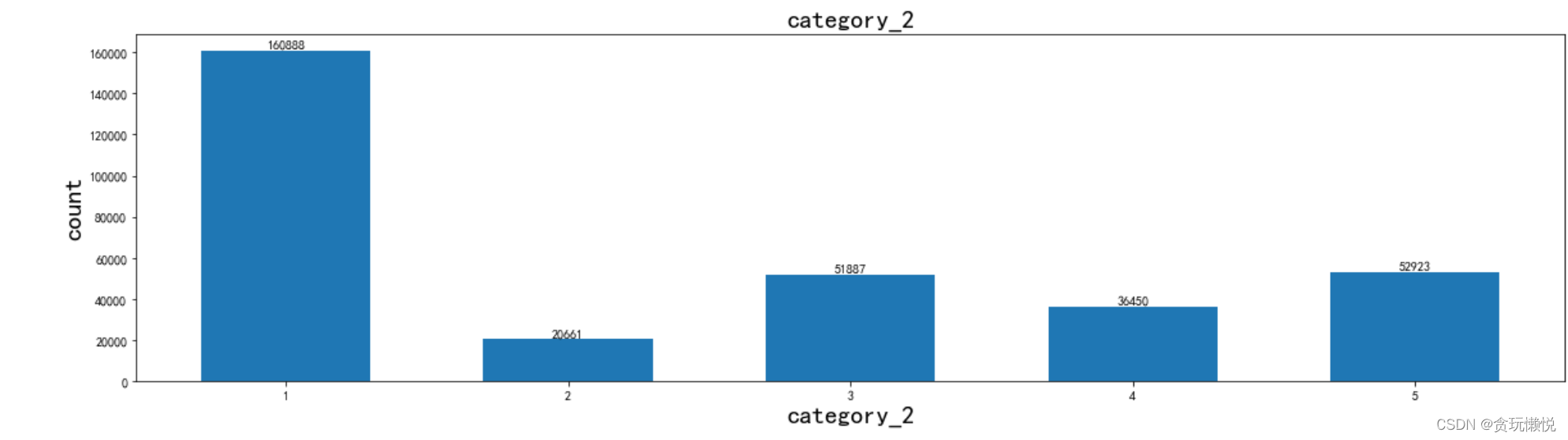
應用效果如下:
data_distribution_explore(merchant,'category_2',va_type='category')
for i in ['avg_sales_lag3','avg_sales_lag6','avg_sales_lag12']:
data_distribution_explore(merchant,i,va_type='numeric')
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/433213.html
標籤:AI
上一篇:tensorflow 安裝GPU版本,CUDA與cuDNN版本對應關系,RTX3050Ti (notebook)
下一篇:cs224n學習筆記3