本篇內容:
- 物體抽取內容的初步資料處理
(之后會發關于匯入neo4j資料庫的相關內容)
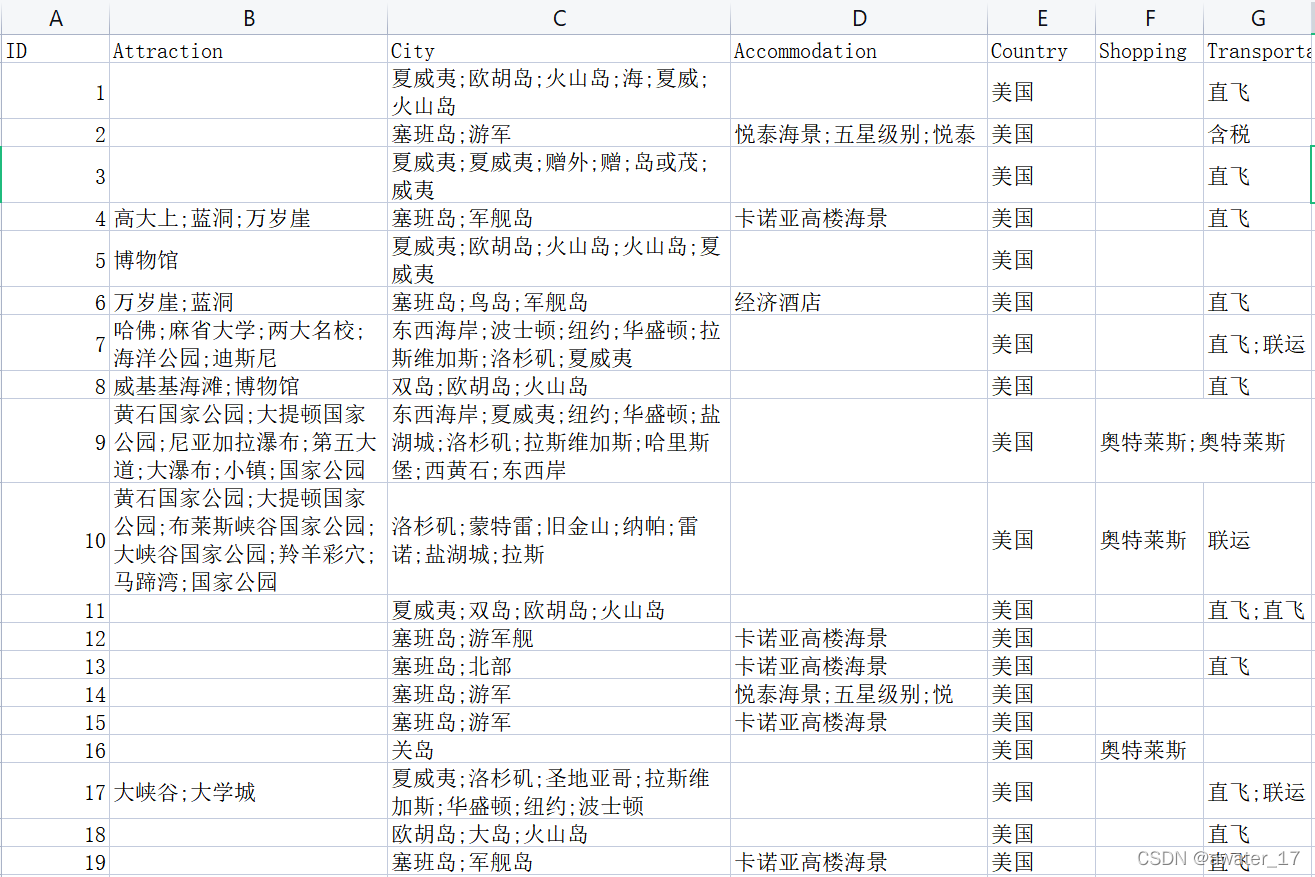
初始資料:進行物體抽取之后的結果資料↓
(這里方便舉例,只拿出了小部分資料,這里解釋一下資料含義,最左邊是每個旅游產品的ID,第二串列示的是旅游產品中包含的景點,第三列是途徑城市,第四列是住宿地點,后邊同理)
下面我們就正式開始!
1. 物體內容抽取
我們知道,圖資料庫的基本資料結構是“物體-關系-物體”,將這些原始資料構建成圖網路,首先應該根據需要確定我們需要提取的物體和關系,
在這里,我們確定具體需求為:
- 每個產品作為一個物體;每一列中所有出現的景點、地點等名稱都是物體
- 我們需要建立的關系是產品與Attraction、City…之間的關系,共六個,
(1)統計每個分類下總共出現的物體個數:
由于后邊需要建立物體間的關系,我們在這里為每個物體都加入了編號,我們在這里借助字典完成,知識很基礎,在這里就不贅述啦~
attra_e={}
city_e={}
accom_e={}
country_e={}
shop_e={}
trans_e={}
product_e={} #創建每個物體的字典
#字典函式
def set_dic(entity_name,dic_name,startBy):
number = 1
for i in df[entity_name]:
a = pd.isnull(i)#判斷單元格是否為空
if a == False:
i = i.split(';')#物體間被;分隔
for j in i:
if j in dic_name.keys():
continue
else:
dic_name[j] = startBy+str(number)
number = number + 1
可以看看結果:
{'高大上': '1011',
'藍洞': '1012',
'萬歲崖': '1013',
'博物館': '1014',
'哈佛': '1015',
'麻省大學': '1016',
'兩大名校': '1017',
'海洋公園': '1018',
'迪斯尼': '1019',
'威基基海灘': '10110',
'黃石國家公園': '10111',
'大提頓國家公園': '10112',
'尼亞加拉瀑布': '10113',
'第五大道': '10114',
'大瀑布': '10115',
'小鎮': '10116',
'國家公園': '10117',
'布萊斯峽谷國家公園': '10118',
'大峽谷國家公園': '10119',
'羚羊彩穴': '10120',
'馬蹄灣': '10121',
'大峽谷': '10122',
'大學城': '10123'}
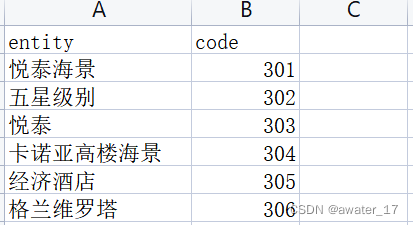
(2)將每個物體及其編號寫入檔案:
在這里要注意兩點,不然后期匯入neo4j的時候你會傷心~
①一定要寫入csv檔案
②一定要注意編碼格式為“UTF8"
以下是寫入模塊的函式:
#第一個引數是:物體的字典名
#第二個引數是:檔案名(記得加.csv)
def write_entity(entity_dic,OutPut):
mulu = '你自己的目錄'
with open(mulu+str(OutPut),'w',newline='',encoding='utf-8') as csvfile:
writer = csv.writer(csvfile)
number = 1
writer.writerow(['entity','code'])
for key,value in entity_dic.items():
writer.writerow([key,value])
number = number+1
print('寫入完成!')
看看結果:
2. 關系內容抽取
將關系寫入檔案:
既然物體已經抽取完成,那么我們接下來的作業就要分別抽取出”產品“這個物體與其他每個物體的關系,這時我們就要改變之前的縱向思維變為橫向思維,
我們的思路大概是(以抽取product和Attraction之間的關系為例):
①按行遍歷串列
②取出Attraction中以;分割開的,包含的所有的景點物體名稱
③從之前創建出的景點物體字典中取出其對應的value也就是景點的編碼值,然后將該product的編碼和Attraction中的每一個景點的編碼都寫入csv檔案中,
以下是關系抽取+寫入csv檔案的函式:
def relationship_extracted(entity1,entity2,entity_dic,OutPut):
mulu = '你的目錄'
with open(mulu+str(OutPut),'w',newline='',encoding='utf-8') as csvfile:
writer = csv.writer(csvfile)
writer.writerow(['product',entity2])
df_1 = df[[entity1,entity2]]
data = pd.DataFrame(df_1)
for indexs in data.index:
l = data.loc[indexs].values[0:]
a = pd.isnull(l[1])
if a == False:
c = l[1].split(';')
for i in c:
writer.writerow([product_e[l[0]],entity_dic[i]])
print('寫入完成!')
下面是得到的結果:
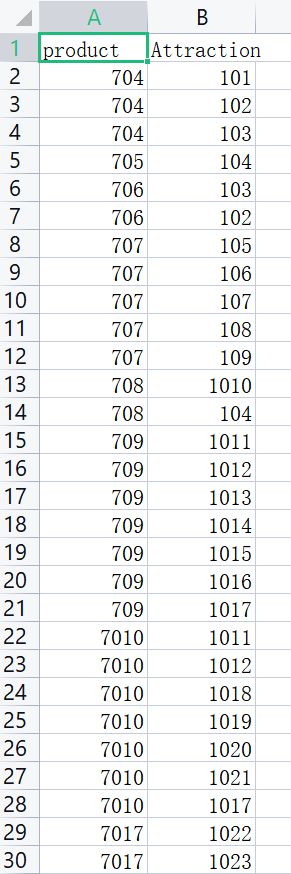
(例如:第一行就表示,編號為704的產品中對應了101這個景點)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/433215.html
標籤:AI
上一篇:cs224n學習筆記3