En點擊下方“AI演算法與影像處理”,一起進步!
重磅干貨,第一時間送達大家好,我是 阿潘~
很多小伙伴期待已久的實戰專案來了,今天分享一個國外論壇medium大佬的文章,從 0 做專案的整個程序,具有很大的參考價值,大家感興趣的可以試著參考這個思路去實作,比起直接跑別人現有的完整,一定能更有識訓和成就感,
如果文章對你有幫助,記得“在看+點贊+分享”!
主要流程包括:
1、確定目標(分割mask ---> 動漫人臉)
2、確定技術路線(語意分割 + 語意合成)
3、實作(資料集標注 + 模型調優 + 界面撰寫)
PS:原作者并沒有開源資料集和代碼, 不過給了所有參考資料的原始碼和資料集鏈接!復現應該沒有問題

目標
該專案的目標是建立一個深度學習模型,從分割mask生成動漫人臉肖像,

segmentation mask to anime face portrait
在這個專案中,首先手動標注一小批影像,然后使用資料增強和 U-Net 模型來乘以分割mask的數量來構建資料集,最后,訓練一個 GauGAN 模型,用于從分割mask中合成動漫人臉,
1. 語意分割
語意分割是為影像中的每個像素分配標簽(也稱為類 id)的程序,它的結果是一個分割mask,它是一個大小為高度 * 寬度的陣列,每個像素都包含一個類 ID,
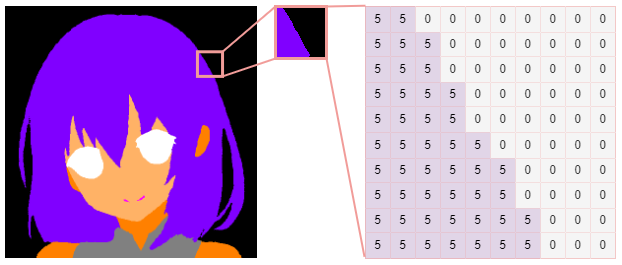
class id: 0 = background, 5 = hair
1.1 Dataset
在進入影像生成任務之前,我們需要一個分割mask資料集,用于訓練生成模型將mask轉換為影像,
不幸的是,我在互聯網上找不到任何動漫人臉分割資料集,盡管如此,Danbooru2019-Portraits 上有一個動漫肖像(512 x 512px)資料集,所以我決定從 Danbooru 肖像中標注的分割mask,
資料集鏈接:https://www.gwern.net/Crops#danbooru2019-portraits
1.2 Annotation
要標注影像,我們必須確定類,最初的想法是列出 15 個類:
background, body, ear, face, eyeball, pupil, eyelash, nose, mouth, hair, hair_accessory, eyebrow, glasses, clothes, hand后來為了簡單起見,將其縮減為 7 個類,最終的類串列如下:
background, skin, face, eye, mouth, hair, clothes有許多不同的注釋工具,這里使用的是 labelme,
https://github.com/wkentaro/labelme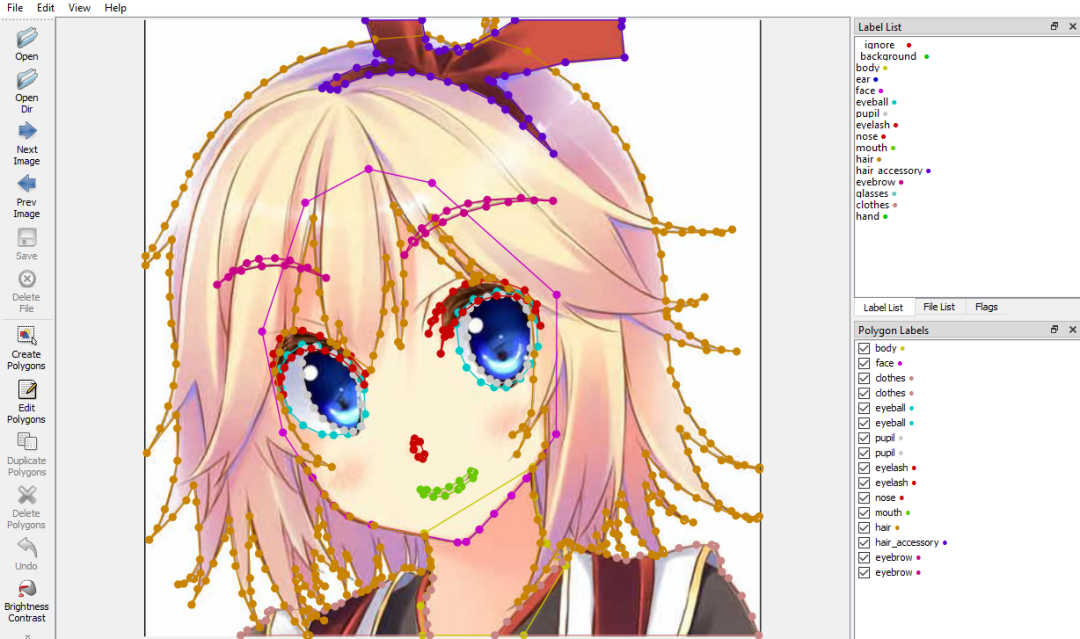
labelme GUI

在這項乏味的作業上辛勤作業數周后,設法標注了 200 張影像

examples of annotated masks

left: original image, middle: segmentation mask, right: visualization of the annotation
1.3 Data Augmentation
當然,200 張帶注釋的影像不足以讓我們訓練我們的網路,我們需要使用資料增強技術來增加資料集的大小,
通過隨機旋轉、鏡像和扭曲影像,我從這 200 個樣本中生成了 3000 多個資料,換句話說,現在我有 3200 個資料,
examples of augmented masks
然而,這些資料在內容和風格方面高度重復,因為它們僅從 200 個樣本中擴充而來,為了訓練網路將分割掩碼轉換為高質量和多樣化的動漫面孔,我們需要的不僅僅是 200 + 3000 個資料點,因此,我將首先使用這些資料來訓練一個 U-Net 模型來學習從動漫人臉到分割掩碼的翻譯,然后我會將整個 Danbooru 肖像資料集輸入到經過訓練的 U-Net 模型中,以生成更多不同人臉的分割掩碼,

anime face portraits to segmentation mask
1.4 U-Net
U-Net 最初是為了分割醫學影像進行診斷而引入的,它通過使用跳躍連接來解決傳統 FCN(全卷積網路)中發生的資訊丟失問題,在精確分割方面做得非常好,
U-Net 的架構與 Autoencoder 相似,但從下采樣端到上采樣端有額外的連接層,
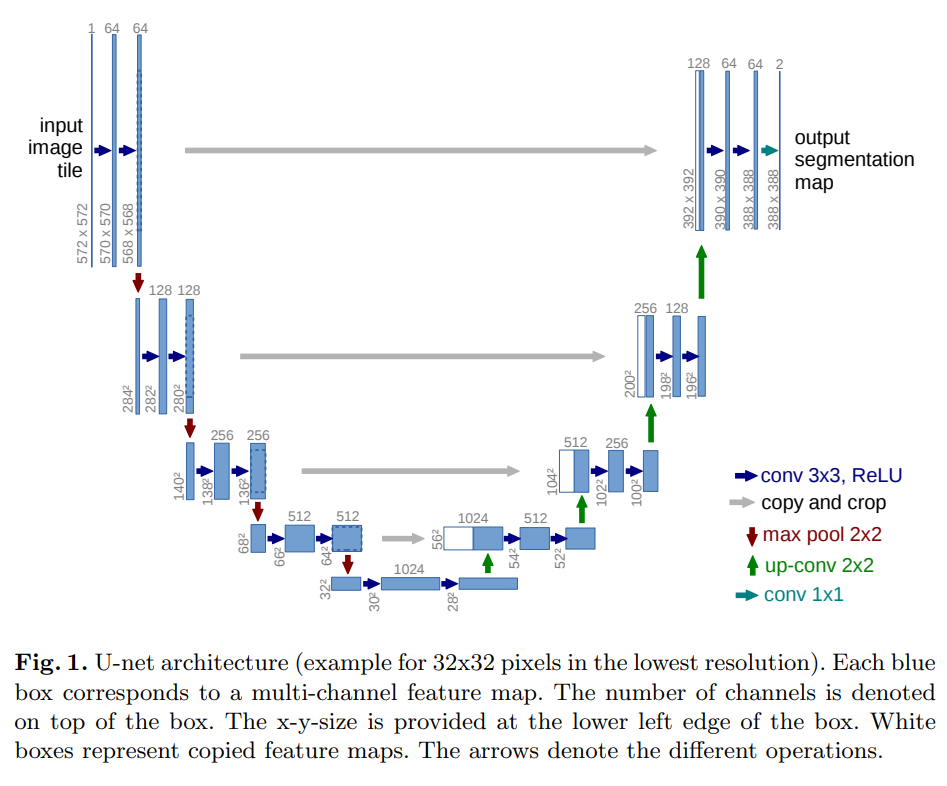
source: https://arxiv.org/abs/1505.04597
在下采樣部分,我使用預訓練的 MobileNetV2 從輸入影像中提取特征,在上采樣部分,我使用了由 Conv2DTranspose、Batchnorm 和 ReLU 層組成的塊,
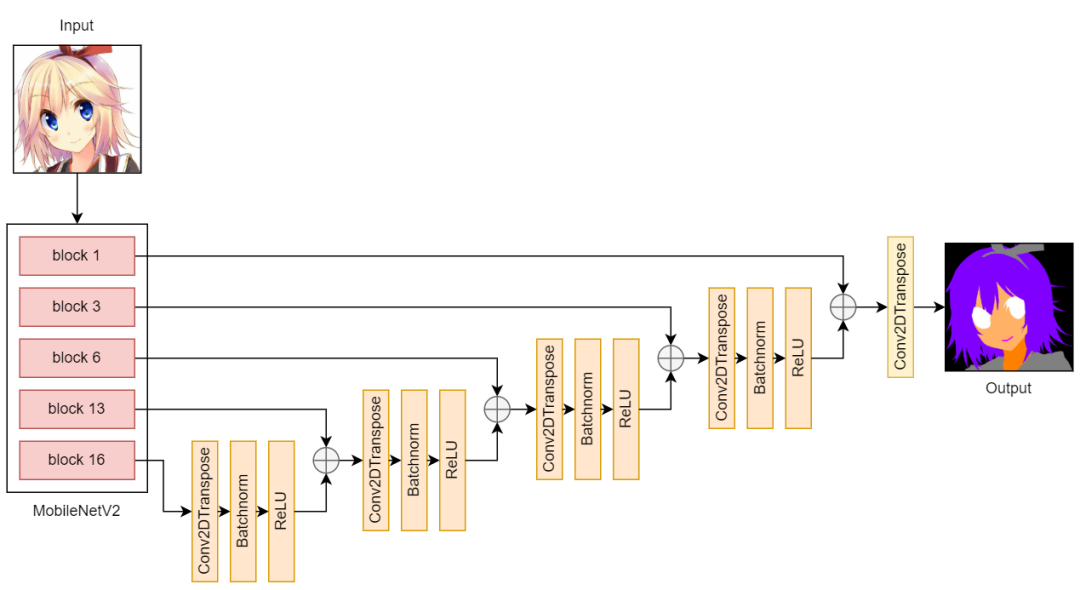
U-Net v1, v2 architecture
在我的 U-Net 版本 1 中,輸入和輸出大小為 128 x 128px,經過訓練的模型確實學習了從動漫人臉到分割mask的非常好的映射,但由于我想在我后來的合成模型中擁有 512 x 512px 的輸入和輸出,我將 U-Net 輸出的大小調整為 512 x 512px 并進行插值,然而,結果看起來是像素化的,它未能捕捉到出現在小區域(例如嘴巴)中的某些類別,
在版本 2 中,我只是將輸入和輸出大小更改為 512 x 512px(我一開始并沒有這樣做,因為我不希望輸出嘈雜并在影像中令人困惑的區域中填充隨機點,例如 衣服),正如我所料,v2 的輸出很嘈雜,不過,它們看起來比 v1 更好,
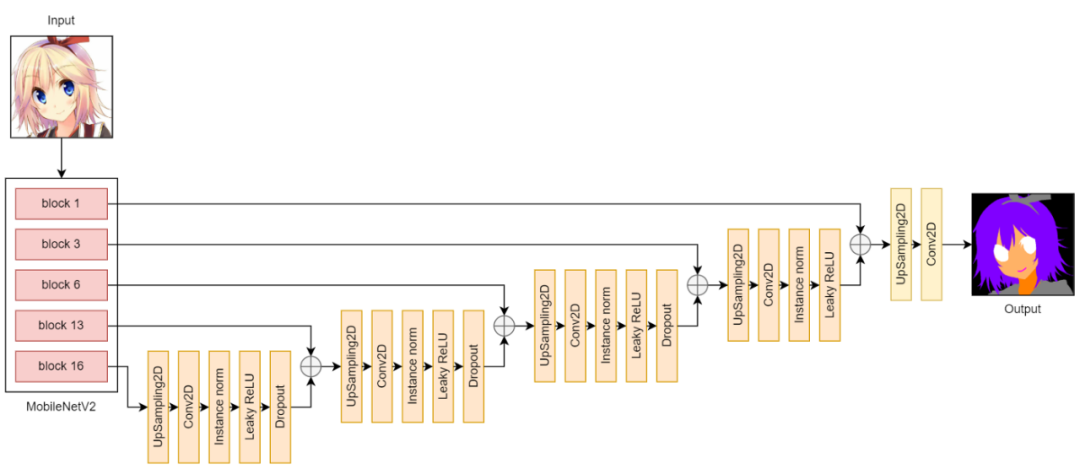
U-Net v3 architecture
在版本 3 中,我嘗試通過用 UpSampling2D 層替換 Conv2DTranspose 層來減輕噪音和棋盤偽影,現在的結果比 v2 的要好得多,噪音更少,棋盤偽影更少,

checkerboard artifacts of v2

U-Net segmentation results
最后,我將整個 Danbooru 資料集輸入 U-Net v3 以構建我的分割掩碼資料集,
2. 影像語意合成
現在,我們有了分割蒙版資料集,是時候深入研究主要任務——影像語意合成,正如之前所說,這不過是從分割mask到真實影像的轉換的一個花哨的名稱,

Semantic Image Synthesis: segmentation mask to anime face portrait
2.1 GauGAN

source: https://github.com/NVlabs/SPADE
GauGAN 由 Nvidia 開發,用于從分割mask合成逼真的影像,在他們的展示網站上,他們展示了 GauGAN 如何出色地通過幾筆畫來生成逼真的風景影像,
demo鏈接:https://www.nvidia.com/en-us/research/ai-playground/
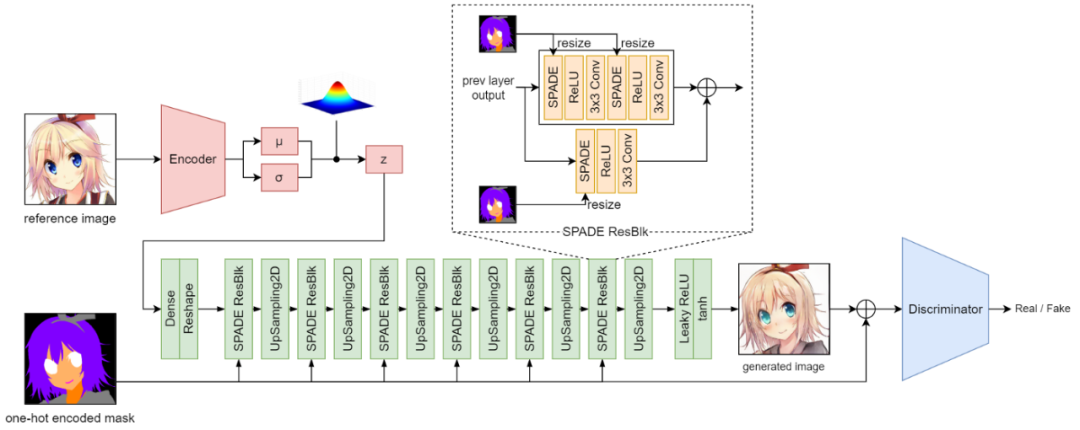
GauGAN architecture
上圖展示了 GauGAN 模型的架構,綠色塊完全代表發電機,鑒別器是一個 PatchGAN,
2.2 SPADE
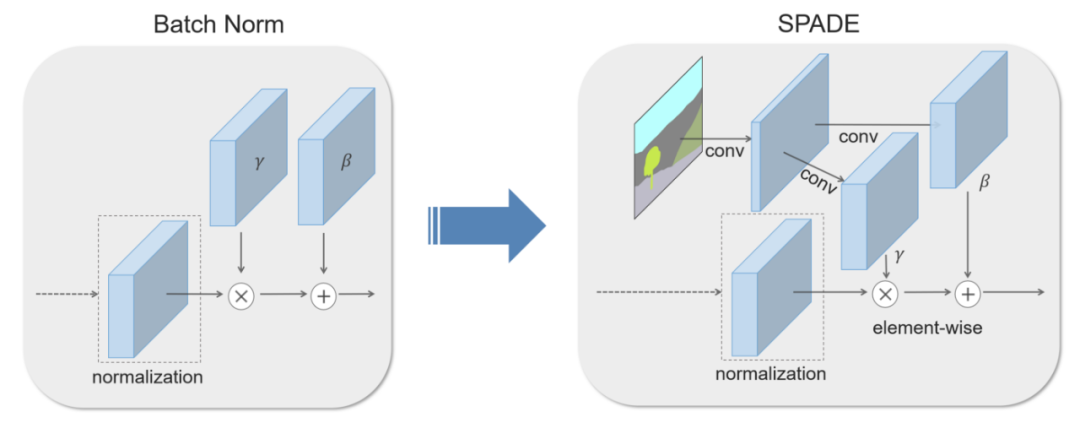
source: https://nvlabs.github.io/SPADE/
GauGAN 的核心是 SPADE(Spatially-Adaptive Denormalization)模塊,它是從 Batch Norm 修改而來的歸一化層,它旨在克服 pix2pixHD 中的挑戰:在具有統一類 ID 的大區域丟失語意資訊,
這是通過將 Conv 層引入Batch Norm來解決的,這樣它具有不同的引數集(β,γ),這些引數以分割mask為條件,并且會隨著不同的區域而變化,這意味著 SPADE 允許生成器在統一標簽區域中學習更多細節,

因此,在我們的問題中,生成的影像可能如下所示:

2.3 Pretrained Encoder
encoder 實際上是可選的,因為可以直接從高斯分布中采樣 z(潛在向量)而無需任何輸入(就像 vanilla GAN),這里使用了encoder ,因為我想用參考影像對生成的影像進行樣式設定,
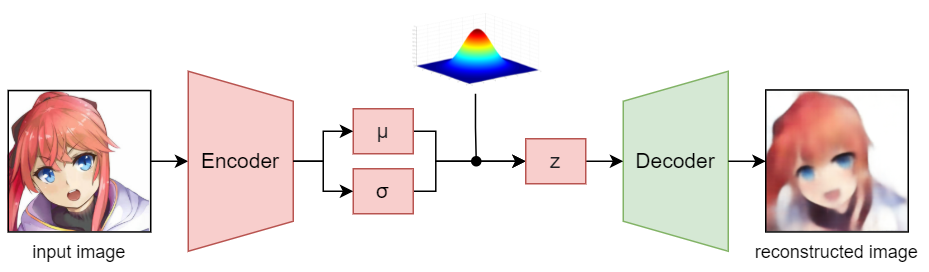
VAE architecture
由于與encoder一起訓練 GauGAN 是不穩定的,需要更多的時間和資源,所以我提前使用 VAE 訓練了我的編碼器,然后在 GauGAN 模型的訓練程序中使用預訓練的encoder對 z 進行采樣,
2.4 Results
以下是從不同的分割mask和參考影像生成的影像的結果,

semantic image synthesis results
2.5 Latent Attribute Vectors
除了使用參考影像來控制輸出影像的風格外,我們還可以直接操縱潛在向量 z 來做到這一點,為此,我們首先需要找出潛在空間中的屬性向量,
動漫角色面部最重要的屬性之一是頭發顏色,但是,由于資料集沒有帶有頭發顏色的標簽,我必須自己使用 i2v 來標記它們,i2v 是一個用于估計插圖示簽的庫,然后,我們可以通過使用 t-SNE 將樣本影像的潛在向量投影到 2D 空間來可視化潛在空間以及估計的標簽,
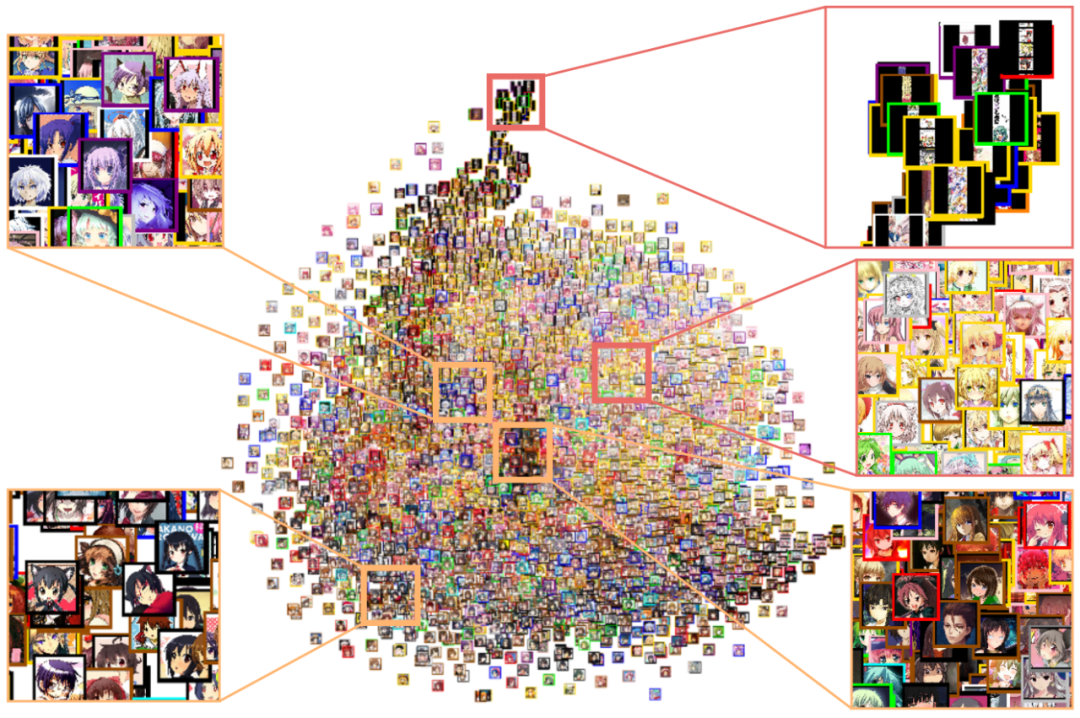
t-SNE of 4000 samples (estimated hair colors are indicated by image border colors)
最后,通過計算不同標簽的潛在向量之間的距離和方向,我們可以得到屬性向量,下面的影片演示了使用提取的屬性向量在頭發顏色之間進行的轉換,
3. GUI
使用 python tkinter 庫創建了一個 GUI,用于編輯生成的影像和分割mask,以下是演示視頻:
4. 總結
這個專案還有改進的空間,尤其是語意分割模型(U-Net)和語意影像合成模型(GauGAN),以下是未來要做的事情的清單:
尋找更好的模型架構以從原始影像中獲得更準確的分割掩碼
改進 GauGAN 模型以消除頭發區域出現的噪聲
訓練生成模型以生成隨機分割mask
參考資料
[1] D. Gwern Branwen, “Anime Crop Datasets: Faces, Figures, & Hands”, Gwern.net, 2022. https://www.gwern.net/Crops#danbooru2019-portraits
[2] “ wkentaro/labelme: Image Polygonal Annotation with Python (polygon, rectangle, circle, line, point and image-level flag annotation).”, GitHub, 2022. https://github.com/wkentaro/labelme
[3] O. Ronneberger, P. Fischer and T. Brox, “U-Net: Convolutional Networks for Biomedical Image Segmentation”, arXiv.org, 2022. https://arxiv.org/abs/1505.04597
[4] Odena, et al., “Deconvolution and Checkerboard Artifacts”, Distill, 2016. http://doi.org/10.23915/distill.00003
[5] “The NVIDIA AI Playground”, NVIDIA, 2022. https://www.nvidia.com/en-us/research/ai-playground/
[6] “NVlabs/SPADE: Semantic Image Synthesis with SPADE”, GitHub, 2022. https://github.com/NVlabs/SPADE
[7] “Semantic Image Synthesis with Spatially-Adaptive Normalization”, Nvlabs.github.io, 2022. https://nvlabs.github.io/SPADE/
[8] “rezoo/illustration2vec: A simple deep learning library for estimating a set of tags and extracting semantic feature vectors from given illustrations.”, GitHub, 2022. https://github.com/rezoo/illustration2vec
推薦閱讀
科研人必備新神器,ReadPaper!愛了真好用!
CVPR2021 最具創造力的那些作業成果!或許這就是計算機視覺的魅力!
英偉達又一個GAN!PoE-GAN,AI繪圖細節拉滿,看完直接沸騰了!
如果文章對你有幫助,記得“在看+點贊+分享”!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/433218.html
標籤:AI
上一篇:Jetson Xavier NX基于YOLOv5+CSI攝像頭實作目標檢測
下一篇:python實作柵格影像的裁剪