各變數間相關關系能否代表因果關系?目前仍無定論,雖然以卡爾 皮爾遜(Karl Pearson)為代表的一些在 20 世紀頗負盛名的統計學家堅持認為相關關系不能指示因果關系,但我們目前所作的研究都是基于肯定的答案去分析資料,同時理性的我們不會被眼前好不容易做出來的顯著相關結果蒙住雙眼,我們仍在孜孜不倦的驗證它的正確性,
相關,一個關于x的函式可以通過x的變化解釋總趨勢,但是,自變數x也能在多大程度上解釋這種趨勢呢?以及解釋到多少是可以信服這個解釋呢?今天,一個仍在不斷發展推進的方法出現在我們眼前——結構方程模型!
當然,你仍可以默認其為Y ~X,
結構方程模型為解釋傳統路徑分析不好解決的潛在變數(潛變數:latent variable)而出現,潛變數在社會學、心理學等領域應用廣泛,例如張三對作業的滿意程度,對生活的幸福感或者是你喜歡看紙質版書籍還是電子版書籍等這種沒有定論,不好觀測,單一資料指向性不充分但當集合大量資料時可以對觀測變數造成不可忽視的影響的變數,
而我們生態學中幾乎全部資料都是可觀測的自然資料,即觀測變數,因此暫不討論潛變數的影響,
但雖然我們不考慮潛變數,我們仍可使用結構方程模型,而且能夠更充分地發揮其價值,
需要注意的是,結構方程方程模型比回歸更強,卻又基于傳統的路徑分析,目前仍無法實作機器自主確定模型解釋,因此,構建模型是所有事件的開端,研究者依據研究內容進行大膽假設推理建模,第一步要盡量涉及全部自己想要的路徑,計算出模型不合理時再進行優化,
🆗,話不多說,能做結構方程模型的軟體有很多,但是我并不推薦,所以直接放R語言,
做結構方程模型的R包目前應用最廣泛的就倆,lavaan 和 piecewiseSEM包,出圖的包我推薦semPlot包
#第一種方法,lavaan包
#安裝包
install.packages("lavaan", dependencies=TRUE)
#加載包
library(lavaan)
#建模,使用sem函式
sem.model1 <- sem (
model = "Sh ~ bio
Shy ~ Sh+bio
AMFSh ~ Sh + Shy
ttl ~ bio + Shy + Sh+ AMFSh",data = se)
#查看結果
summary (sem.model1, standardize = TRUE, rsq=TRUE,modindices=TRUE)看一下我的模型
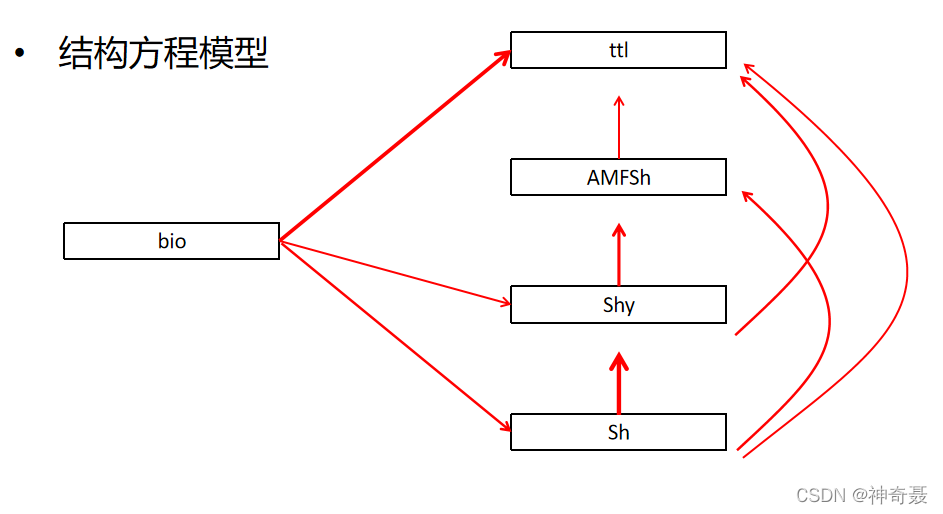
第二種方法:
#安裝加載包
install.packages("piecewiseSEM", dependencies=TRUE)
library(piecewiseSEM)
library(nlme)
#構建模型
#注意 random 項是將不同樣點作為隨機效應納入模型
sem.model2 <- psem (
lme(Sh ~ bio, random = ~ 1 | sam, data = se),
lme(Shy ~ Sh +bio,random = ~ 1 | sam, data = se),
lme(AMFSh ~ Sh + Shy,random = ~ 1 | sam, data = se),
lme(ttl ~ bio + Shy + Sh + AMFSh, random = ~ 1 | sam, data = se))
#查看結果
summary(sem.model2)lavaan 和 piecewiseSEM包的區別就在于后者加入了隨機效應,
同時二者的判斷標準不同
lavaan的檢驗是卡方檢驗,單獨檢驗某缺失路徑的重要性 ,piecewiseSEM是在此基礎上綜合所有缺失路徑的結果構建 Fisher’s C 值,
個人建議優先使用lavaan,行不通的時候再使用piecewiseSEM,
畫圖畫圖
#作圖
install.packages("semPlot", dependencies=TRUE)
library(semPlot)
#semPaths中what值為路徑解釋度,layout為出圖的形式,具體引數大家可以直接??semPaths進行查看
semPaths(sem.model1,what = "stand",layout = "tree2")如果想充分了解結構方程模型的理論和發展背景,可以查閱相關資料,
本文參考:
Grace JB. 2006. Structural Equation Modeling and Natural Systems. Cambridge: Cambridge University Press.
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/433226.html
標籤:AI