
隨著 8.0 的發布,Elastic 很高興能夠將 PyTorch 機器學習模型上傳到 Elasticsearch 中,以在 Elastic Stack 中提供現代自然語言處理 (NLP), 現在,Elasticsearch 用戶能夠集成用于構建 NLP 模型的最流行的格式之一,并將這些模型作為 NLP 資料管道的一部分通過我們的 Inference processor 整合到 Elasticsearch 中, 添加 PyTorch 模型以及新的 ANN 搜索 API的能力為 Elastic Enterprise Search 添加了一個全新的向量(雙關語),
NLP 在 Elastic Stack 7.x 和 8.0 中的區別
Elasticsearch 一直是進行 NLP 的好地方,但從歷史上看,它需要在 Elasticsearch 之外進行一些處理,或者撰寫一些非常復雜的插件, 借助 8.0,用戶現在可以在 Elasticsearch 中更直接地執行命名物體識別、情感分析、文本分類等操作——無需額外的組件或編碼, 不僅在 Elasticsearch 中本地計算和創建向量在水平可擴展性方面是“勝利”(通過在服務器集群中分布計算)——這一變化還為 Elasticsearch 用戶節省了大量時間和精力,
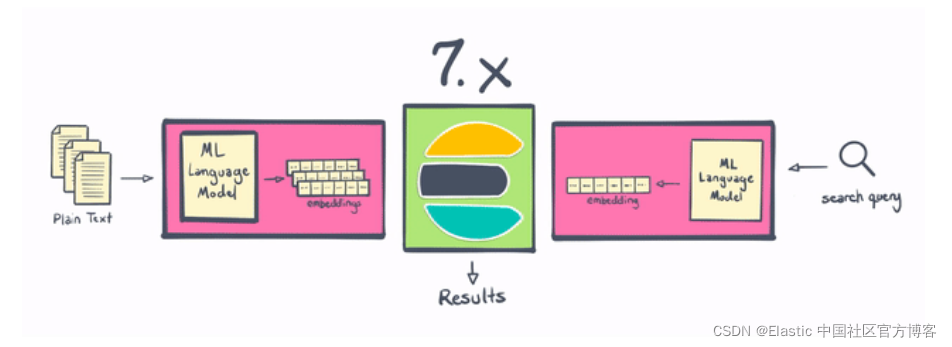
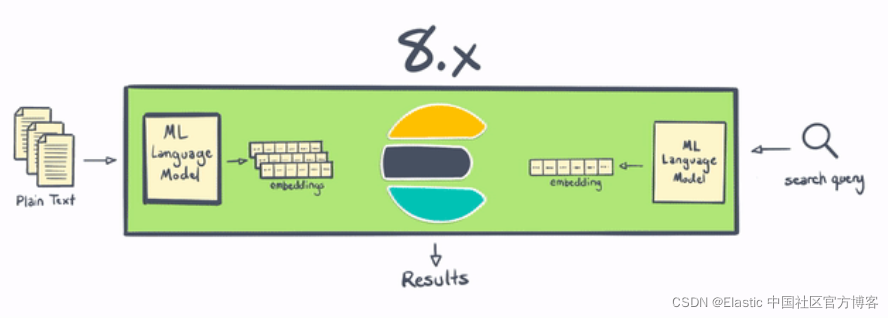
借助 Elastic 8.0,用戶可以直接在 Elasticsearch 中使用 PyTorch 機器學習模型(例如 BERT),并在 Elasticsearch 中使用這些模型進行推理, 這些模型可以是你自己的自定義模型,也可以是在 Hugging Face 等存盤庫中發布到社區的模型,
通過使用戶能夠直接在 Elasticsearch 中執行推理,將現代 NLP 的強大功能集成到搜索應用程式和體驗(想想:無需編碼)、本質上更高效(得益于 Elasticsearch 的分布式計算能力)和 NLP 本身比以往任何時候都更容易 變得更快,因為你不需要將資料移出到單獨的行程或系統中,
什么是自然語言處理?
NLP 是指我們可以使用軟體來操作和理解口語或書面文本或自然語言的方式, 2018 年,Google 開源了一種用于 NLP 預訓練的新技術,稱為來自 Transformers 的雙向編碼器呈現,或 BERT, BERT 通過在沒有任何人工參與的情況下對互聯網大小的資料集(例如,想想所有的維基百科和數字書籍)進行訓練來利用 “transfer learning”,
Transfer learning 允許對 BERT 模型進行預訓練以進行通用語言理解,一旦模型只經過一次預訓練,它就可以被重用并針對更具體的任務進行微調,以了解語言的使用方式,
為了支持類 BERT 模型(使用與 BERT 相同的標記器的模型),Elasticsearch 將首先通過 PyTorch 模型支持支持大多數最常見的 NLP 任務, PyTorch 是最受歡迎的現代機器學習庫之一,擁有大量活躍用戶,它是一個支持深度神經網路的庫,例如 BERT 使用的 Transformer 架構,
以下是一些示例 NLP 任務:
- 情緒分析:用于識別正面與負面陳述的二元分類
- 命名物體識別 (NER):從非結構化文本構建結構,嘗試提取名稱、位置或組織等細節
- 文本分類:零樣本分類允許你根據你選擇的類對文本進行分類,而無需進行預訓練,
- 文本嵌入:用于 k 近鄰 (kNN) 搜索
Elastic Stack NLP 能做什么?
Elastic Stack NLP 1_嗶哩嗶哩_bilibili
Elasticsearch 中的自然語言處理
在將 NLP 模型集成到 Elastic 平臺時,我們希望為上傳和管理模型提供出色的用戶體驗,使用用于上傳 PyTorch 模型的 Eland 客戶端和用于管理 Elasticsearch 集群上模型的 Kibana 的 ML 模型管理用戶界面,用戶可以嘗試不同的模型并很好地了解它們在資料上的表現,我們還希望使其可跨集群中的多個可用節點進行擴展,并提供良好的推理吞吐量性能,
Elastic Stack NLP 作業流程
Elastic Stack NLP 2_嗶哩嗶哩_bilibili
為了使這一切成為可能,我們需要一個機器學習庫來執行推理,在 Elasticsearch 中添加對 PyTorch 的支持需要使用原生庫 libtorch,它支持 PyTorch,并且僅支持已匯出或保存為 TorchScript 表示的 PyTorch 模型,這是 libtorch 需要的模型的表示,它將允許 Elasticsearch 避免運行 Python 解釋器,
通過與在 PyTorch 模型中構建 NLP 模型的最流行的格式之一集成,Elasticsearch 可以提供一個平臺,該平臺可處理大量 NLP 任務和用例,許多優秀的庫可用于訓練 NLP 模型,因此我們暫時將其留給其他工具,無論你是使用 PyTorch NLP、Hugging Face Transformers 還是 Facebook 的 fairseq 等庫來訓練模型,你都可以將模型匯入 Elasticsearch 并對這些模型進行推理, Elasticsearch 推理最初將僅在攝取時進行,未來還可以擴展以在查詢時引入推理,
到目前為止,已經有一些方法可以通過 API 呼叫和插件以及其他選項將 NLP 模型集成到 Elasticsearch 和 Elasticsearch 之間,但是通過在你的 Elasticsearch 資料管道中集成 NLP 模型,你可以獲得以下好處:
- 圍繞你的 NLP 模型構建更好的基礎架構
- 擴展你的 NLP 模型推理
- 維護你的資料安全和隱私
NLP 模型可以集中管理,并且可以協調加載和分發這些模型,
對 PyTorch 模型的推理呼叫可以分布在集群周圍,并且可以允許用戶在未來根據負載進行擴展,通過不移動資料并針對基于 CPU 的推理優化云虛擬機,可以提高性能,通過在 Elasticsearch 中整合 NLP 模型,我們可以將資料保存在一個整體集中、安全的網路中,同時考慮到資料隱私和合規性,通用基礎設施、查詢性能和資料隱私都可以通過在 Elasticsearch 中整合 NLP 模型得到增強,
展示
在接下來的環節中,我們將使用一個簡單的例子來展示如何使用 Elastic NLP,如果要在集群中執行自然語言處理任務,則必須部署適當的訓練模型, Eland 和 Kibana 提供工具支持,可幫助你準備和管理模型,
選擇一個訓練好的模型編輯
根據概述,你可以通過多種方式在 Elastic Stack 中使用 NLP 功能, 在確定要執行哪種型別的 NLP 任務后,你必須選擇合適的訓練模型,
最簡單的方法是使用已經針對你要執行的分析型別進行了微調的模型, 例如,Hugging Face 上有可用于特定 NLP 任務的模型和資料集, 這些說明假定你正在使用其中一種模型,并且不描述如何創建新模型, 有關支持的模型架構的當前串列,請參閱第三方 NLP 模型,
如果你選擇使用集群中提供的 lang_ident_model_1 執行語言識別,則不需要進一步的步驟來匯入或部署模型, 你可以跳到在攝取管道中使用模型,
匯入訓練好的模型和詞匯
選擇模型后,你必須將其及其標記器詞匯表匯入集群, 匯入模型時,由于其大小,必須將其分塊并一次匯入一個塊,以便分段存盤,
經過訓練的模型必須采用 TorchScript 表示,才能與 Elastic Stack 機器學習功能一起使用,
Eland 將 Hugging Face 轉換器模型到其 TorchScript 表示的轉換和分塊程序封裝在一個 Python 方法中; 因此,這是推薦的匯入方法,
- 安裝 Eland Python 客戶端,
- 運行 eland_import_hub_model 腳本, 例如:
eland_import_hub_model --url <clusterUrl> \
--hub-model-id elastic/distilbert-base-cased-finetuned-conll03-english \
--task-type ner - 指定 URL 以訪問你的集群, 例如,https://<user>:<password>@<hostname>:<port>,
- 在 Hugging Face 模型中心中指定模型的識別符號,
- 指定 NLP 任務的型別, 支持的值為 fill_mask、ner、text_classification、text_embedding 和 zero_shot_classification,
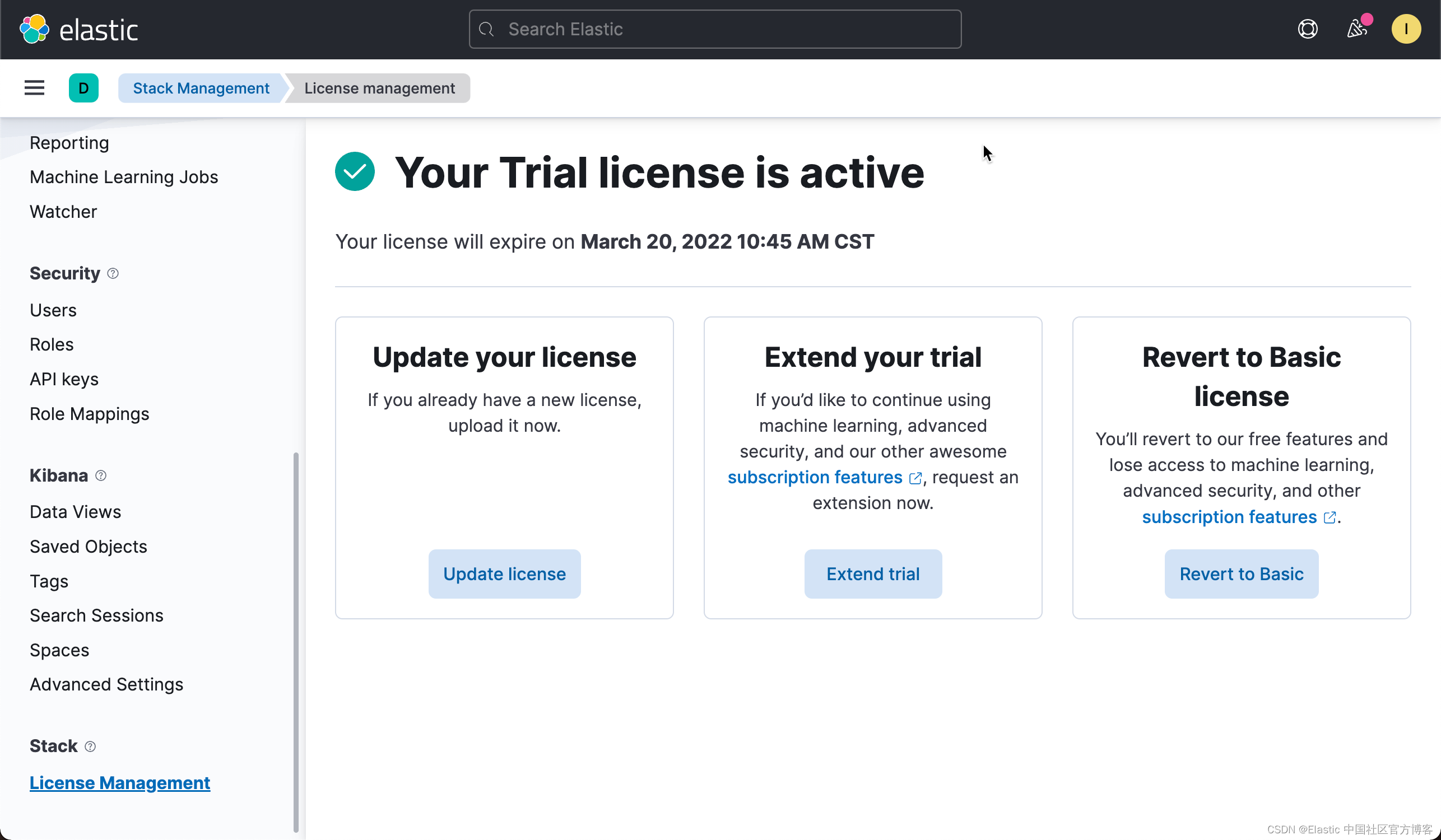
如果你還沒有安裝好自己的 Elastic Stack 8.0,請參考我之前的文章 “Elastic Stack 8.0 安裝 - 保護你的 Elastic Stack 現在比以往任何時候都簡單”,在進行下面的操作之前,我們必須啟動白金版試用:
如果我們的 Elasticsearch 位于 https://192.168.0.3:9200,那么我們可以使用如下的命令來執行:
python -m pip install elandgit clone https://github.com/elastic/eland我們進入到下載的代碼根目錄中,如果你部署的 Elasticsearch 集群不是使用自簽名的,那么一下的步驟你直接跳過,針對自簽名集群,你需要修改如下的檔案:
eland/bin/eland_import_hub_model
在 def main(): 的下面的位置:
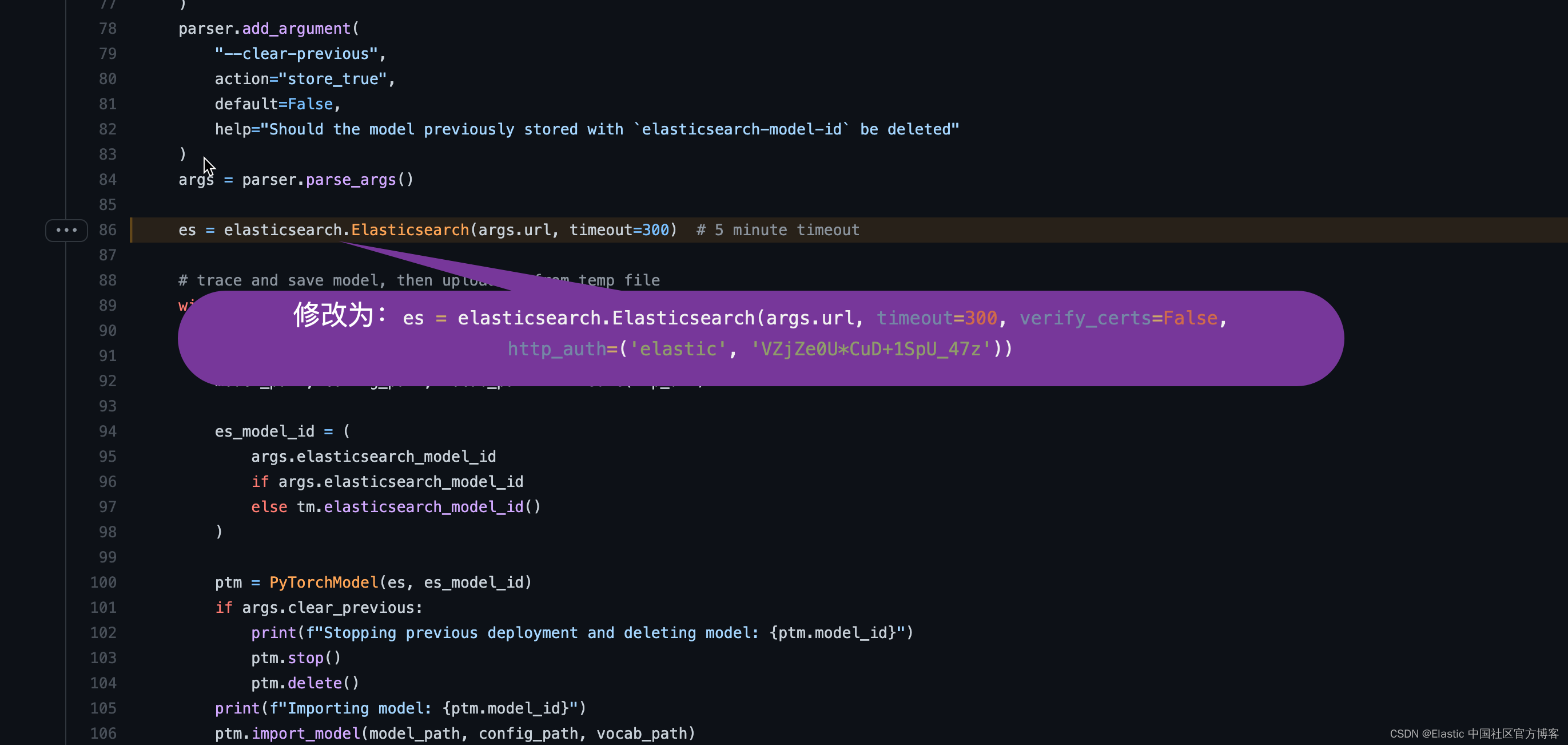
在上面,我們添加 verify_certs 為 False,以及設定 http_auth,在 http_auth 里設定超級用戶 elastic 的用戶名及密碼,
我們使用如下的命令來創建 docker image:
docker build -t elastic/eland .
我們接著使用如下的方法來上傳模型:
docker run -it --rm --network host \
elastic/eland \
eland_import_hub_model \
--url https://liuxg.com:9200/ \
--hub-model-id elastic/distilbert-base-cased-finetuned-conll03-english \
--task-type ner \
--start在這里,請注意我們必須使用當前電腦的 hostname,否則我們將建立不起來連接,在我的電腦上:
$ ping liuxg.com
PING liuxg.com (192.168.0.3): 56 data bytes
64 bytes from 192.168.0.3: icmp_seq=0 ttl=64 time=0.076 ms
64 bytes from 192.168.0.3: icmp_seq=1 ttl=64 time=0.268 ms我們需要在 /etc/hosts 里進行設定,
運行上面的命令:
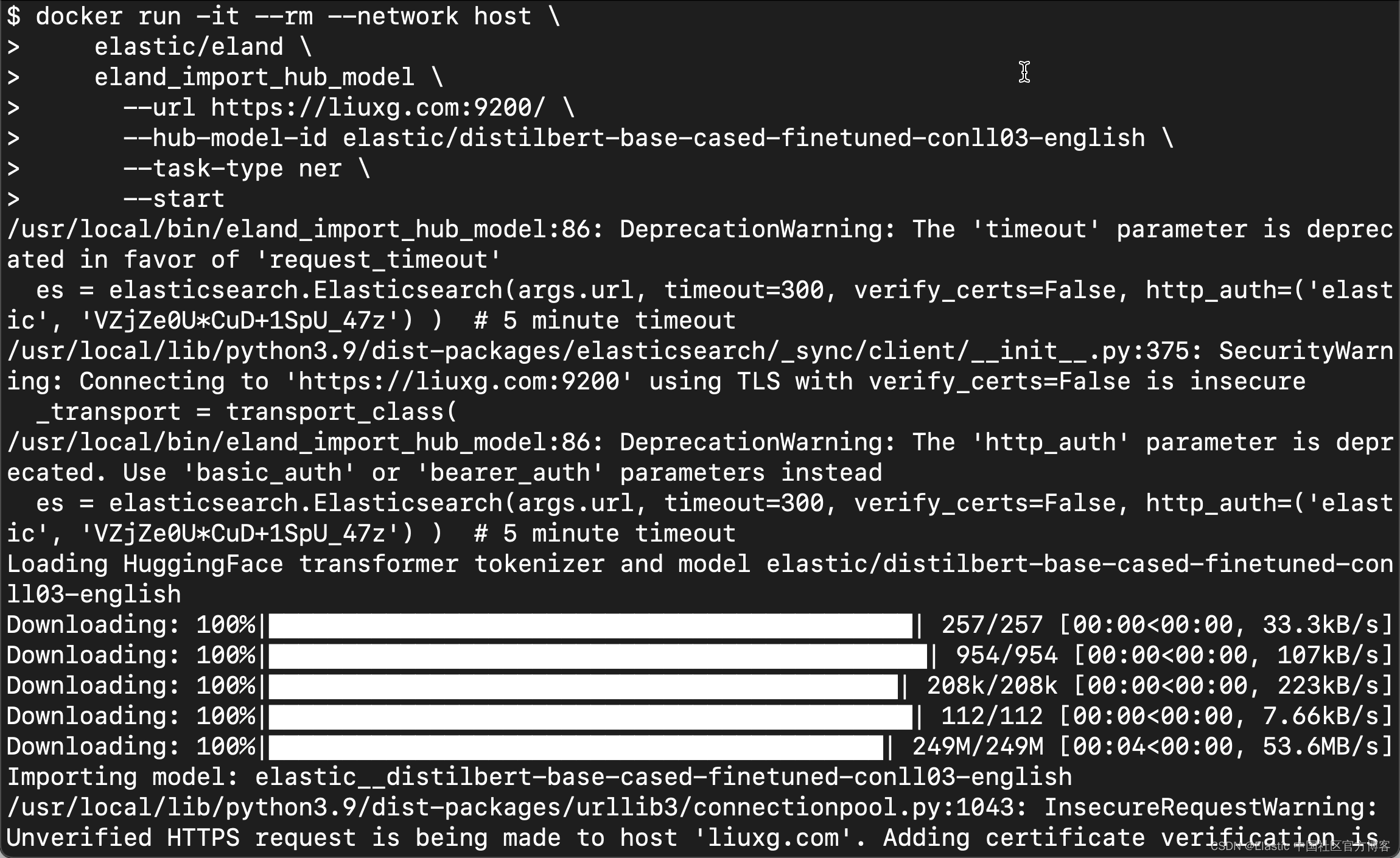
等上述的命令完成后,我們在 Kinana 中進行查看:
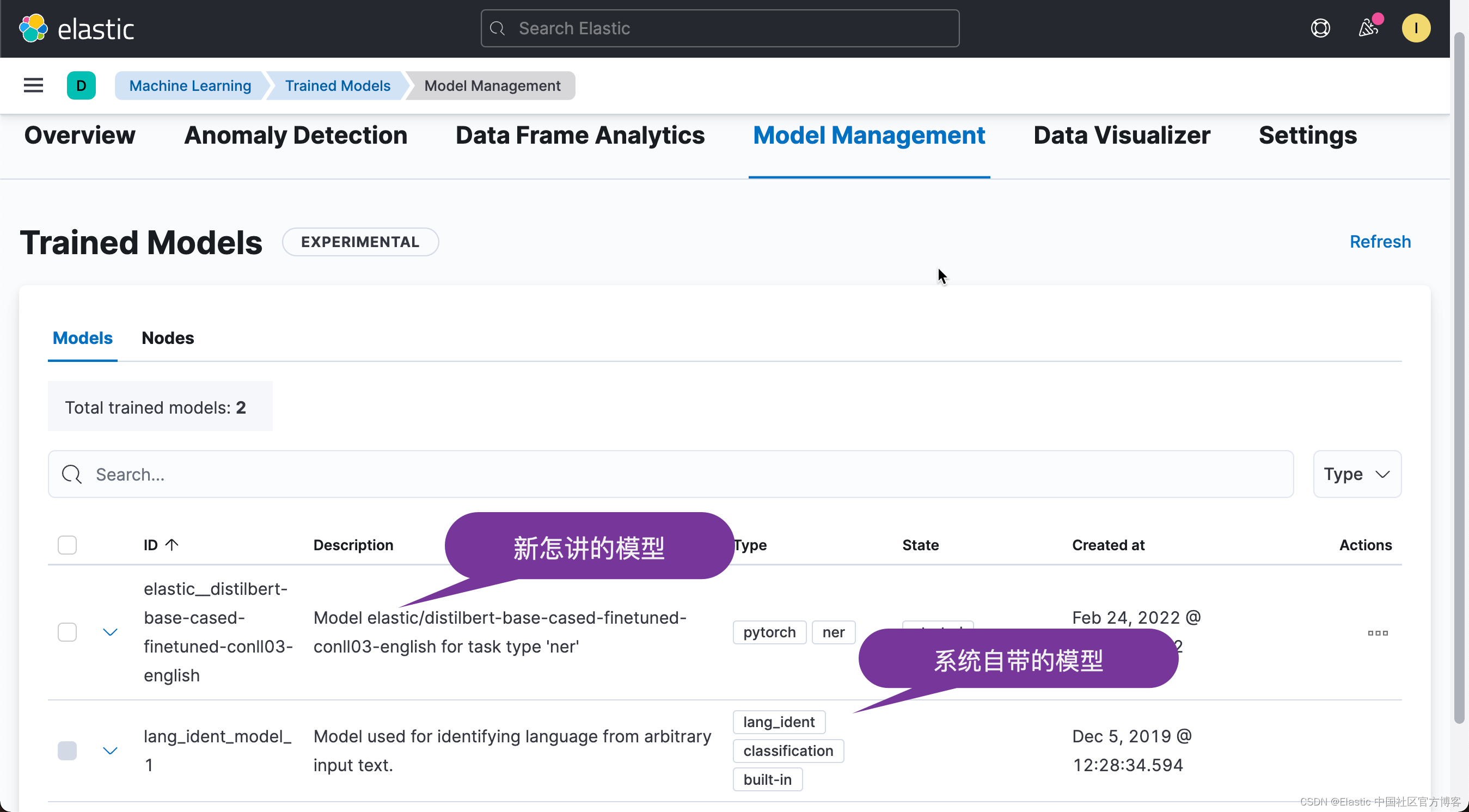
從上面的界面中,我們可以看出一個新怎講的模型,現在我們已經成功地把模型上傳到 Elasticsearch 中,
測驗模型
當模型部署在集群中的至少一個節點上時,你就可以開始執行推理了, 推理是一種機器學習功能,可讓你使用經過訓練的模型對傳入資料執行 NLP 任務(例如文本提取、分類或嵌入),
針對新資料測驗模型的最簡單方法是使用推理訓練模型部署 API,還記得我們之前在啟動 docker 時有一個選項為 ner,也即命名物體識別, 例如,要嘗試命名物體識別任務,請提供一些示例文本:
POST /_ml/trained_models/elastic__distilbert-base-cased-finetuned-conll03-english/deployment/_infer
{
"docs": {
"text_field": "Sasha bought 300 shares of Acme Corp in 2022."
}
}上面的命令回傳的結果為:
{
"predicted_value" : "[Sasha](PER&Sasha) bought 300 shares of [Acme Corp](ORG&Acme+Corp) in 2022.",
"entities" : [
{
"entity" : "Sasha",
"class_name" : "PER",
"class_probability" : 0.9953193610539933,
"start_pos" : 0,
"end_pos" : 5
},
{
"entity" : "Acme Corp",
"class_name" : "ORG",
"class_probability" : 0.9996392196076958,
"start_pos" : 27,
"end_pos" : 36
}
]
}從上面的回傳結果中,我們可以看出來有 99.5% 的可能性判定 Sasha 是一個人名,而有 99.96% 的可能性判定 Acme Corp 為一個 ORG,即一個公司或組織,
我們來嘗試另外一個例子:
POST /_ml/trained_models/elastic__distilbert-base-cased-finetuned-conll03-english/deployment/_infer
{
"docs": {
"text_field": "Xiaoguo said that Elastic was a great company in the world"
}
}上面回傳的結果為:
{
"predicted_value" : "[Xiaoguo](PER&Xiaoguo) said that [Elastic](ORG&Elastic) was a great company in the world",
"entities" : [
{
"entity" : "Xiaoguo",
"class_name" : "PER",
"class_probability" : 0.9977009282482645,
"start_pos" : 0,
"end_pos" : 7
},
{
"entity" : "Elastic",
"class_name" : "ORG",
"class_probability" : 0.9954152045770668,
"start_pos" : 18,
"end_pos" : 25
}
]
}按照同樣的方法,我們嘗試 fill_mask:
docker run -it --rm --network host \
elastic/eland \
eland_import_hub_model \
--url https://liuxg.com:9200/ \
--hub-model-id bert-base-uncased \
--task-type fill_mask \
--start 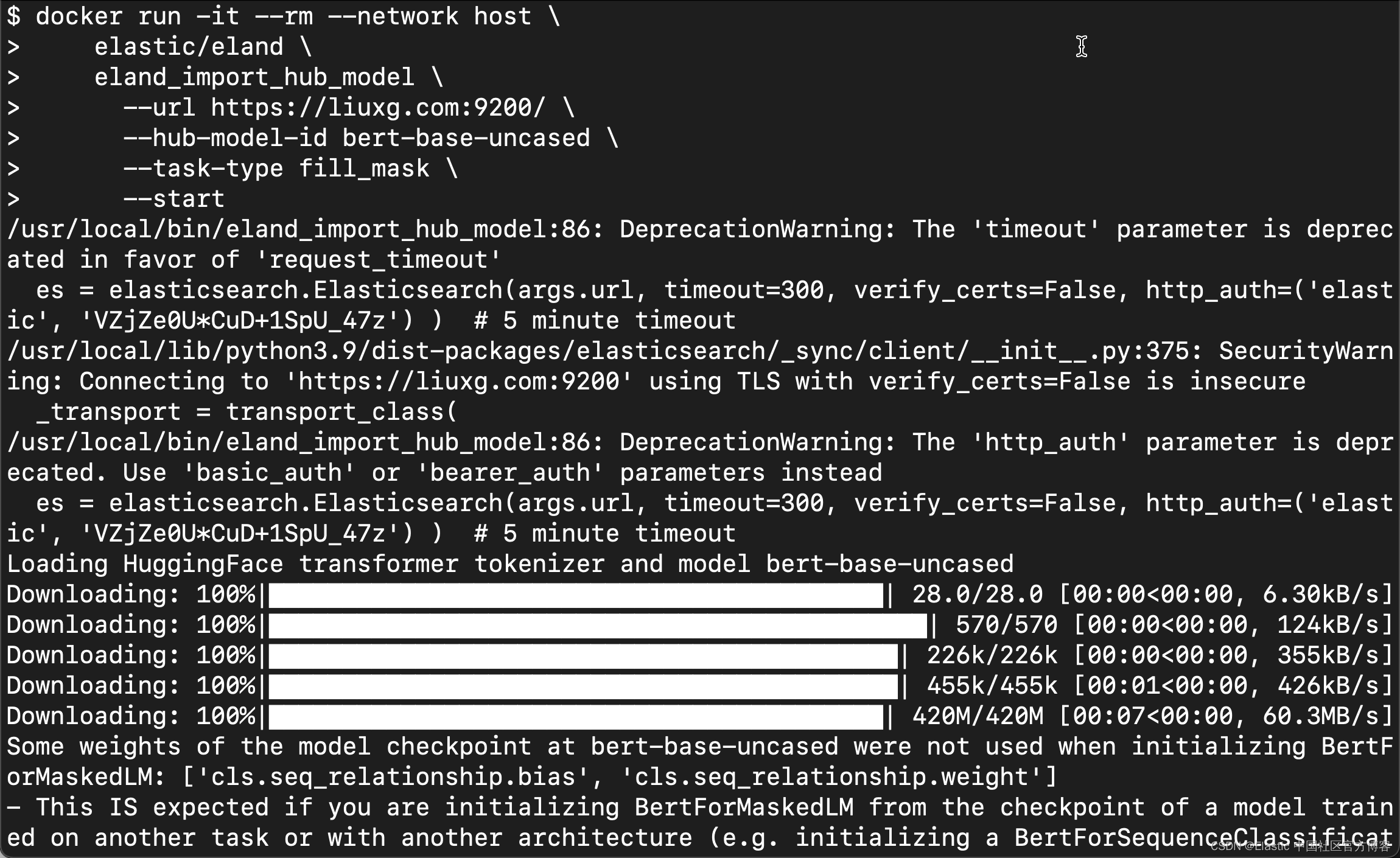
我們在機器學習的界面看到:
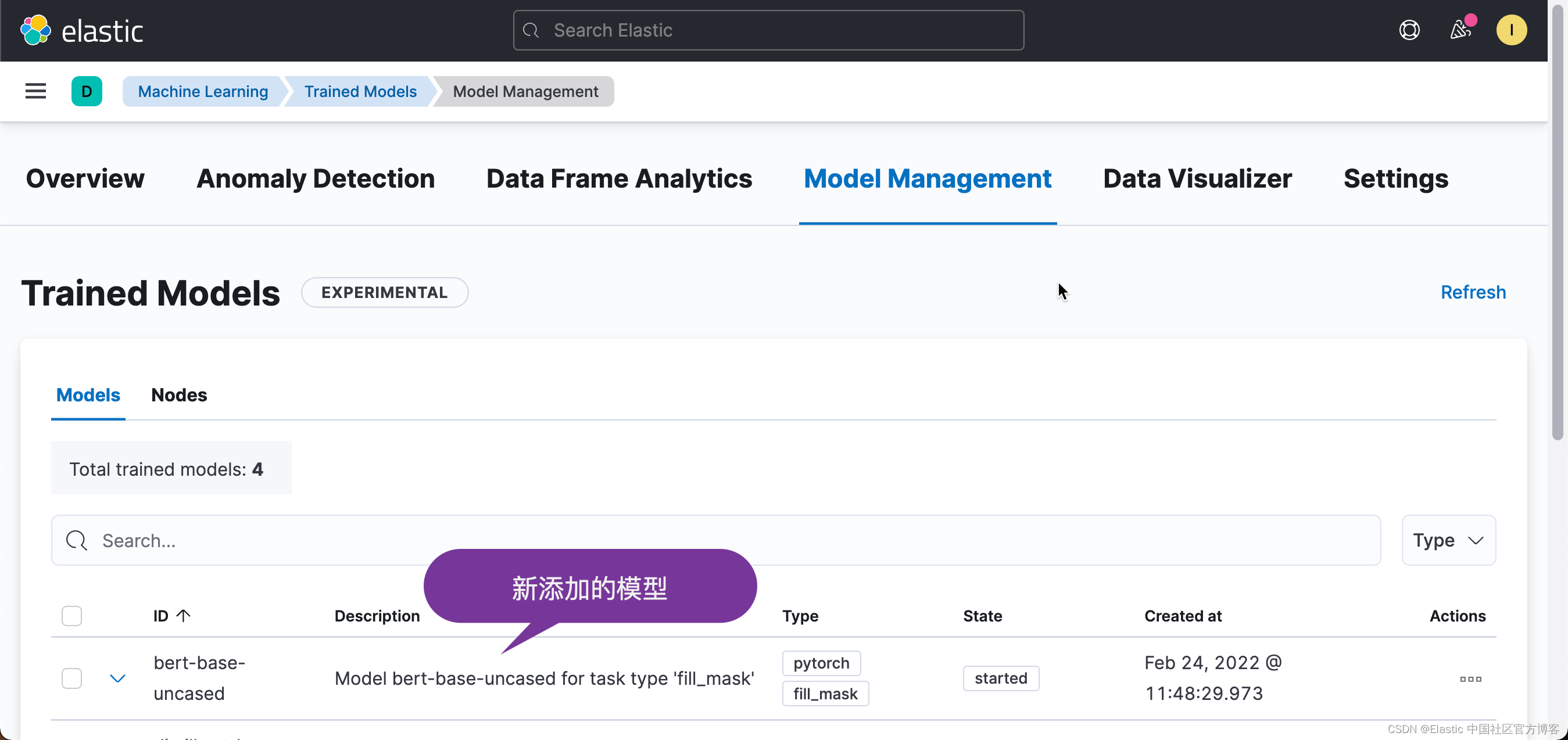
我們在 Kibana 中使用如下的測驗:
POST /_ml/trained_models/bert-base-uncased/deployment/_infer
{
"docs": {
"text_field": "Paris is the [MASK] of France"
}
}上面的查詢回傳結果:
{
"predicted_value" : "capital",
"prediction_probability" : 0.9975749159388136,
"predicted_value_sequence" : "Paris is the capital of France"
}我們再做一個測驗:
POST /_ml/trained_models/bert-base-uncased/deployment/_infer
{
"docs": {
"text_field": "Amsterdam is a city in the [MASK]"
}
}上面的查詢回傳的結果為:
POST /_ml/trained_models/bert-base-uncased/deployment/_infer
{
"docs": {
"text_field": "Beijing is the [MASK] of China"
}
}{
"predicted_value" : "capital",
"prediction_probability" : 0.9989096738963879,
"predicted_value_sequence" : "Beijing is the capital of China"
}POST /_ml/trained_models/bert-base-uncased/deployment/_infer
{
"docs": {
"text_field": "Beijing is the capital of [MASK]."
}
}回傳:
{
"predicted_value" : "china",
"prediction_probability" : 0.9913708584213007,
"predicted_value_sequence" : "Beijing is the capital of china."
}請注意 [MASK] 后面的那個點,它非常重要,否則你可能得不到你想要的結果,
POST /_ml/trained_models/bert-base-uncased/deployment/_infer
{
"docs": {
"text_field": "Amsterdam is a city in the [MASK]."
}
}{
"predicted_value" : "netherlands",
"prediction_probability" : 0.9997222917917266,
"predicted_value_sequence" : "Amsterdam is a city in the netherlands."
}轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/433244.html
標籤:其他
上一篇:大資料集群資源監控