神經網路中的激活函式與損失函式&深入理解softmax交叉熵
前面在深度學習入門筆記1和深度學習入門筆記2中已經介紹了激活函式和損失函式,這里做一些補充,主要是介紹softmax交叉熵損失函式,
激活函式
sigmoid函式
神經網路中經常使用的一個激活函式就是sigmoid函式,
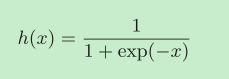
它的影像是:
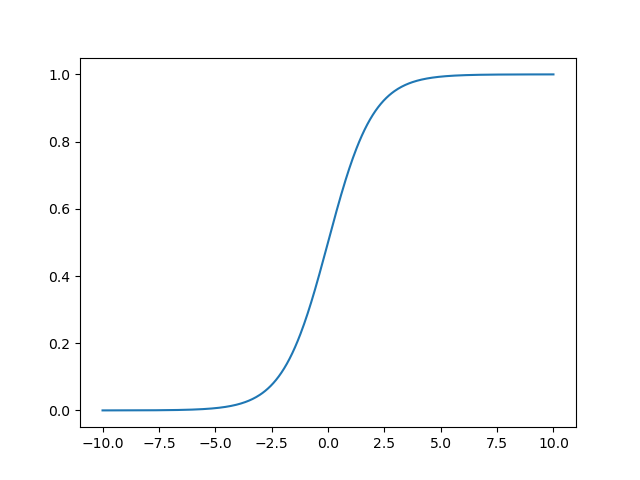
sigmoid函式常用于回歸問題,
softmax函式
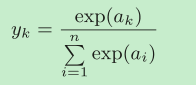
softmax函式的分子是輸入信號ak的指數函式,分母是所有輸入信號的指數函式的和,
softmax函式的輸出是0.0到1.0之間的實數,并且,softmax函式的輸出值的總和是1,這是softmax函式的一個重要性質,正因為有了這個性質,我們才可以把softmax函式的輸出解釋為“概率”,
從softmax的名字來看,就知道應該有一個與之對應的hardmax,其實hardmax就是直接簡單粗暴地選擇一個最大值,而softmax則將所有的結果以概率的形式輸出,
softmax函式的優缺點
優點是它既能產生更陡峭的梯度,又具有一些優雅的數學屬性,
- 這里“更陡峭的梯度”在神經網路的學習中很重要,sigmoid函式在這方面就表現地不是很好:sigmoid函式曲線相對平坦的梯度,sigmoid函式的最大斜率是0.25,所以當把這些梯度向后發送至模型中的上一個運算時,這些梯度最多只能除以4而更糟糕的是,當 sigmoid 函式的輸入小于–2或大于2時,這些輸入所接收的梯度將幾乎為0,這是因為 sigmoid(x) 在 x = –2 或 x = 2 時幾乎是平坦的,這意味著影響這些輸入的任何引數都會收到較小的梯度,因此神經網路的學習速度會很慢(在使用梯度下降法SGD時,修改引數值,然后繼續觀察反向傳播回來的梯度,然而因為sigmoid函式近乎平坦的曲線,反向傳播回來的梯度幾乎沒有什么變化,這就意味著要進行多次的梯度下降才能看到效果)
sigmiod函式的導數影像如下:
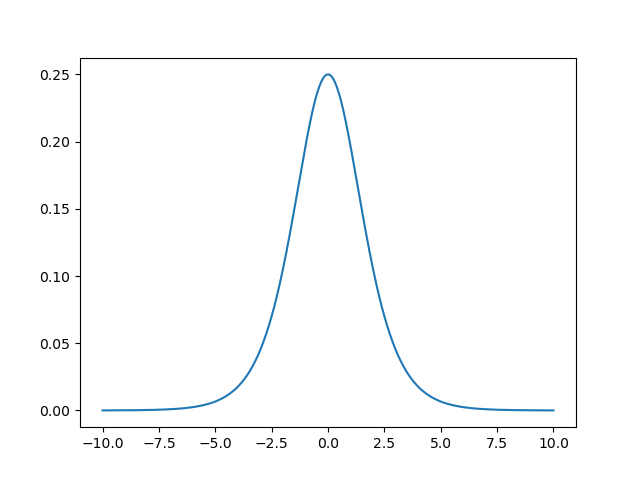
- 這里“優雅的數學屬性”后面結合交叉熵損失函式一起說明,
缺點是溢位問題,softmax函式的實作中要進行指數函式的運算,但是此時指數函式的值很容易變得非常大,比如,e10的值 會超過20000,e100會變成一個后面有40多個0的超大值,e1000的結果會回傳 一個表示無窮大的inf,如果在這些超大值之間進行除法運算,結果會出現“不確定”的情況,
一般情況下我們會采取將所有的輸入值減去輸入值中的最大值,然后再進行運算,
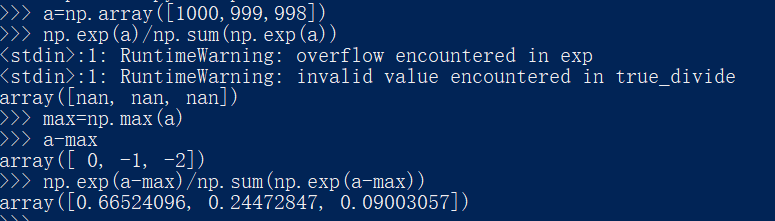
這么做會不會有問題呢?不會的,這是因為在進行softmax的指數函式的運算時,加上(或者減去) 某個常數并不會改變運算的結果,
ReLU函式
ReLU函式非常簡單,如果 x 小于 0,則 ReLU 簡單地定義為 0,否則定義為 x,
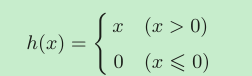
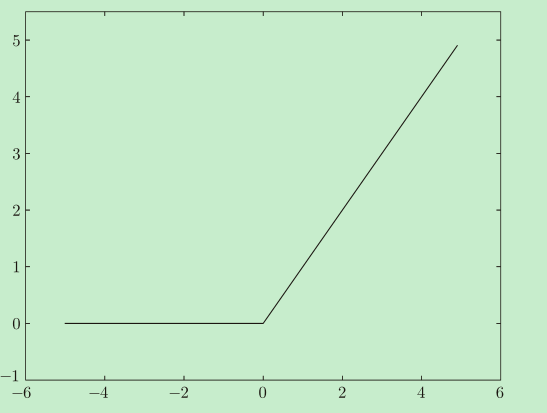
從單調和非線性的角度來看,這是一個“有效”的激活函式,它產生的梯度要比 sigmoid 函式大得多,函式的輸入大于0,則梯度為1,其他情況則為0,平均梯度為0.5,ReLU 激活函式在深度神經網路架構中是非常 流行的選擇,這是因為它的缺點(在小于 0 和大于 0 的值之間形成了過于明顯的差別)可 以通過其他技術來彌補,
ReLU有一些變體:當 ReLU 激活函式的輸入小于 0 時,Leaky ReLU7 激活函式允許略微的負斜率,從而增強 ReLU 激活函式向后發送梯度的能力,不過從簡單和易于計算兩個方面考慮,ReLU足夠應付很多簡單的場景,
Tanh函式
Tanh函式介于sigmoid和ReLU 之間,是一種折中方案,它的形狀與 sigmoid 函式類似,但輸出的取值范圍是 –1 ~ 1,
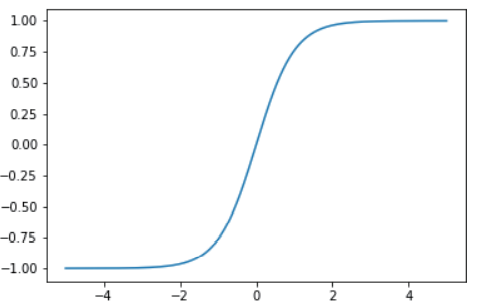
它產生比 sigmoid 曲線更陡峭的梯度:
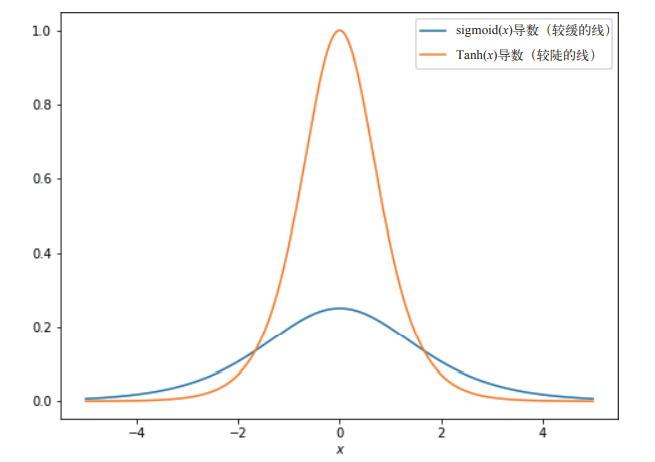
f=sigmoid(x)和f=Tanh(x)都有著方便計算的導數: f`=sigmoid(x)*(1-sigmoid(x)) 和 f`=1-Tanh2(x) ,
損失函式
神經網路的學習需要通過某個指標表示現在模型的狀態,然后以這個指標為基準,尋找最優權重引數,這個指標稱為損失函式(loss function),這個損失函式可以使用任意函式,但一般用均方誤差和交叉熵誤差等,
之前的文章中提到了為什么不適用“準確率”這樣簡單的指標,因為“準確率”是離散的,不連續的,沒有辦法使用梯度來尋找最優權重引數,
損失函式是表示神經網路性能的“惡劣程度”的指標,即當前的神經網路對監督資料在多大程度上不擬合,在多大程度上不一致,
MSE均方誤差
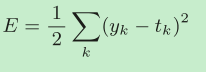
yk是表示神經網路的輸出,tk表示監督資料,k表示資料的維數,
交叉熵誤差
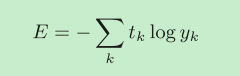
yk是神經網路的輸出,tk是正確解標簽,并且,tk中只有正確解標簽的索引為1,其他均為0,也就是進行了獨熱編碼(one-hot encoding),
softmax交叉熵
交叉熵函式和softmax激活函式常常合在一起使用,稱為Softmax-with-Loss,
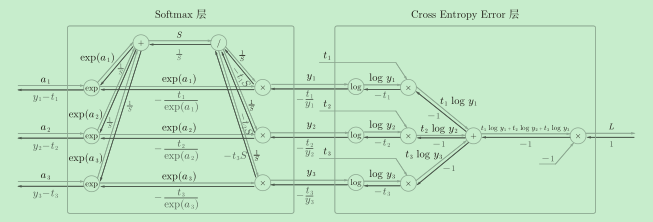
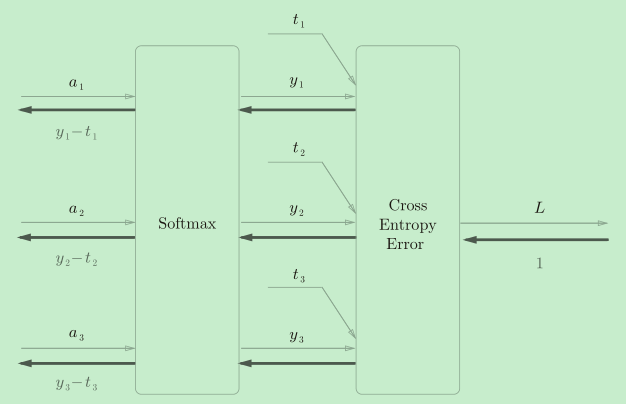
二者一旦結合,就會出現“魔術”般的效果:可以看到,Softmax層的反向傳播得到了(y1?t1, y2?t2, y3?t3)這樣“漂亮”的結果,這也是softmax函式所謂的“優雅的數學屬性”,在tensorflow庫中,一般也推薦使用統一的介面,而不是單獨使用Softmax函式與交叉熵損失函式,
softmax交叉熵的計算圖推導程序
](https://img.uj5u.com/2022/02/28/3021852807203614.png)
softmax交叉熵的計算圖推導程序

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/433372.html
標籤:AI