文章目錄
- DataX簡介
- DataX 商業版本
- DataX的特點
- DataX同步Hive資料丟失
- DataX的Hive資料源HdfsReader插件
DataX簡介
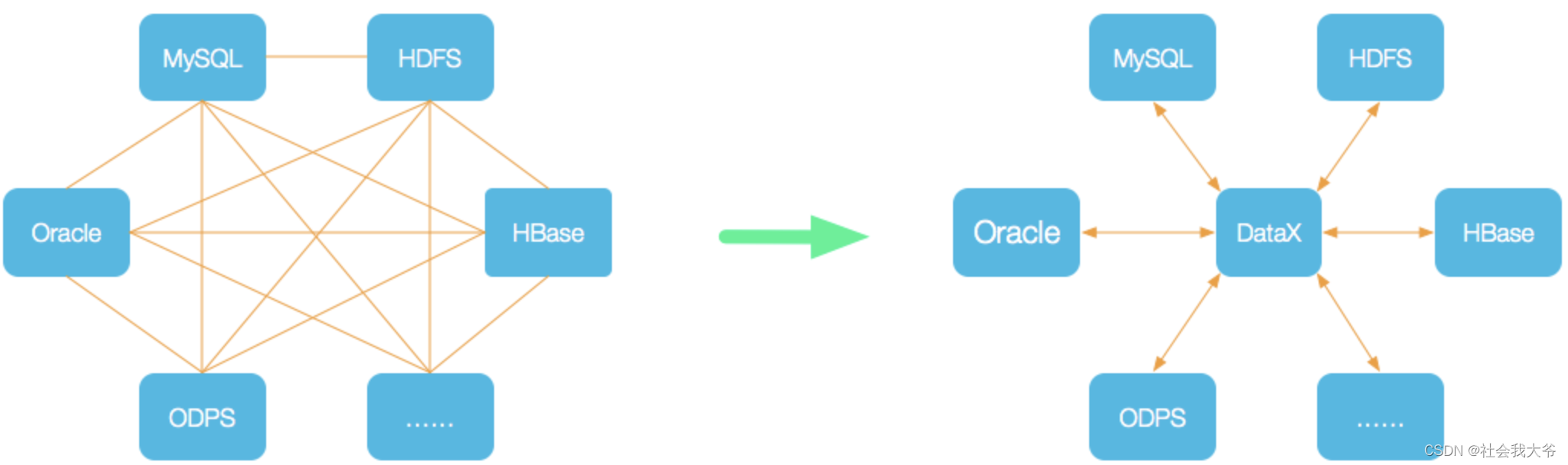
DataX 是阿里云 DataWorks資料集成 的開源版本,在阿里巴巴集團內被廣泛使用的離線資料同步工具/平臺,DataX 實作了包括 MySQL、Oracle、OceanBase、SqlServer、Postgre、HDFS、Hive、ADS、HBase、TableStore(OTS)、MaxCompute(ODPS)、Hologres、DRDS 等各種異構資料源之間高效的資料同步功能,
DataX 商業版本
阿里云DataWorks資料集成是DataX團隊在阿里云上的商業化產品,致力于提供復雜網路環境下、豐富的異構資料源之間高速穩定的資料移動能力,以及繁雜業務背景下的資料同步解決方案,目前已經支持云上近3000家客戶,單日同步資料超過3萬億條,DataWorks資料集成目前支持離線50+種資料源,可以進行整庫遷移、批量上云、增量同步、分庫分表等各類同步解決方案,2020年更新實時同步能力,2020年更新實時同步能力,支持10+種資料源的讀寫任意組合,提供MySQL,Oracle等多種資料源到阿里云MaxCompute,Hologres等大資料引擎的一鍵全增量同步解決方案,
商業版本參見: https://www.aliyun.com/product/bigdata/ide
DataX的特點
DataX本身作為資料同步框架,將不同資料源的同步抽象為從源頭資料源讀取資料的Reader插件,以及向目標端寫入資料的Writer插件,理論上DataX框架可以支持任意資料源型別的資料同步作業,同時DataX插件體系作為一套生態系統, 每接入一套新資料源該新加入的資料源即可實作和現有的資料源互通,
DataX同步Hive資料丟失
使用Datax進行兩個集群間的資料同步,在讀取HDFS大檔案資料時,存在出現資料丟失問題,從上文我們知道DataX的資料同步原理,就是將不同資料源的同步抽象為從源頭資料源讀取資料的Reader插件,以及向目標端寫入資料的Writer插件,為了適配各種異構的資料存盤介質,DataX原始碼在設計的時候針對不同的資料源撰寫了相應的Reader插件和Writer插件,既然問題是在資料源讀取就存在資料丟失的問題,我們不妨看看DataX得原始碼實作,
DataX的Hive資料源HdfsReader插件
HdfsReader實作了從Hadoop分布式檔案系統Hdfs中讀取檔案資料并轉為DataX協議的功能,textfile是Hive建表時默認使用的存盤格式,資料不做壓縮,本質上textfile就是以文本的形式將資料存放在hdfs中,對于DataX而言,HdfsReader實作上類比TxtFileReader,有諸多相似之處,orcfile,它的全名是Optimized Row Columnar file,是對RCFile做了優化,據官方檔案介紹,這種檔案格式可以提供一種高效的方法來存盤Hive資料,HdfsReader利用Hive提供的OrcSerde類,讀取決議orcfile檔案的資料,目前HdfsReader支持的功能如下:
- 支持textfile、orcfile、rcfile、sequence file和csv格式的檔案,且要求檔案內容存放的是一張邏輯意義上的二維表,
- 支持多種型別資料讀取(使用String表示),支持列裁剪,支持列常量
- 支持遞回讀取、支持正則運算式("*“和”?"),
- 支持orcfile資料壓縮,目前支持SNAPPY,ZLIB兩種壓縮方式,
- 多個File可以支持并發讀取,
- 支持sequence file資料壓縮,目前支持lzo壓縮方式,
- csv型別支持壓縮格式有:gzip、bz2、zip、lzo、lzo_deflate、snappy,
- 目前插件中Hive版本為1.1.1,Hadoop版本為2.7.1(Apache[為適配JDK1.7],在Hadoop 2.5.0, Hadoop 2.6.0 和Hive 1.2.0測驗環境中寫入正常;其它版本需后期進一步測驗;
- 支持kerberos認證(注意:如果用戶需要進行kerberos認證,那么用戶使用的Hadoop集群版本需要和hdfsreader的Hadoop版本保持一致,如果高于hdfsreader的Hadoop版本,不保證kerberos認證有效)
原始碼暫時未實作的點:
- 單個File支持多執行緒并發讀取,這里涉及到單個File內部切分演算法,二期考慮支持,
- 目前還不支持hdfs HA;
HdfsReader核心實作DFSUtil原始碼讀取orc格式的檔案方法 :
public void orcFileStartRead(String sourceOrcFilePath, Configuration readerSliceConfig,
RecordSender recordSender, TaskPluginCollector taskPluginCollector) {
LOG.info(String.format("Start Read orcfile [%s].", sourceOrcFilePath));
List<ColumnEntry> column = UnstructuredStorageReaderUtil
.getListColumnEntry(readerSliceConfig, com.alibaba.datax.plugin.unstructuredstorage.reader.Key.COLUMN);
String nullFormat = readerSliceConfig.getString(com.alibaba.datax.plugin.unstructuredstorage.reader.Key.NULL_FORMAT);
StringBuilder allColumns = new StringBuilder();
StringBuilder allColumnTypes = new StringBuilder();
boolean isReadAllColumns = false;
int columnIndexMax = -1;
// 判斷是否讀取所有列
if (null == column || column.size() == 0) {
int allColumnsCount = getAllColumnsCount(sourceOrcFilePath);
columnIndexMax = allColumnsCount - 1;
isReadAllColumns = true;
} else {
columnIndexMax = getMaxIndex(column);
}
for (int i = 0; i <= columnIndexMax; i++) {
allColumns.append("col");
allColumnTypes.append("string");
if (i != columnIndexMax) {
allColumns.append(",");
allColumnTypes.append(":");
}
}
if (columnIndexMax >= 0) {
JobConf conf = new JobConf(hadoopConf);
Path orcFilePath = new Path(sourceOrcFilePath);
Properties p = new Properties();
p.setProperty("columns", allColumns.toString());
p.setProperty("columns.types", allColumnTypes.toString());
try {
OrcSerde serde = new OrcSerde();
serde.initialize(conf, p);
StructObjectInspector inspector = (StructObjectInspector) serde.getObjectInspector();
InputFormat<?, ?> in = new OrcInputFormat();
FileInputFormat.setInputPaths(conf, orcFilePath.toString());
//If the network disconnected, will retry 45 times, each time the retry interval for 20 seconds
//Each file as a split
//TODO multy threads
InputSplit[] splits = in.getSplits(conf, 1);
RecordReader reader = in.getRecordReader(splits[0], conf, Reporter.NULL);
Object key = reader.createKey();
Object value = reader.createValue();
// 獲取列資訊
List<? extends StructField> fields = inspector.getAllStructFieldRefs();
List<Object> recordFields;
while (reader.next(key, value)) {
recordFields = new ArrayList<Object>();
for (int i = 0; i <= columnIndexMax; i++) {
Object field = inspector.getStructFieldData(value, fields.get(i));
recordFields.add(field);
}
transportOneRecord(column, recordFields, recordSender,
taskPluginCollector, isReadAllColumns, nullFormat);
}
reader.close();
} catch (Exception e) {
String message = String.format("從orcfile檔案路徑[%s]中讀取資料發生例外,請聯系系統管理員,"
, sourceOrcFilePath);
LOG.error(message);
throw DataXException.asDataXException(HdfsReaderErrorCode.READ_FILE_ERROR, message);
}
} else {
String message = String.format("請確認您所讀取的列配置正確!columnIndexMax 小于0,column:%s", JSON.toJSONString(column));
throw DataXException.asDataXException(HdfsReaderErrorCode.BAD_CONFIG_VALUE, message);
}
}
對于Hdfs大檔案在讀取資料的時候會對大檔案進行分片/區塊的讀取,正如上述代碼片段:
//Each file as a split
//TODO multy threads
InputSplit[] splits = in.getSplits(conf, 1);
RecordReader reader = in.getRecordReader(splits[0], conf, Reporter.NULL);
從代碼實作可以很容易發現在讀取檔案的時候只取了分片后的第一個區塊的資料,也尚未開啟多執行緒消費多分片的資料,這樣就會導致在大檔案讀取時,存在多分片情況丟失資料的現象,
問題發現后對上述代碼進行完善,完善后的代碼如下:
public void orcFileStartRead(String sourceOrcFilePath, Configuration readerSliceConfig,
RecordSender recordSender, TaskPluginCollector taskPluginCollector) {
LOG.info(String.format("Start Read orcfile [%s].", sourceOrcFilePath));
List<ColumnEntry> column = UnstructuredStorageReaderUtil
.getListColumnEntry(readerSliceConfig, com.alibaba.datax.plugin.unstructuredstorage.reader.Key.COLUMN);
String nullFormat = readerSliceConfig.getString(com.alibaba.datax.plugin.unstructuredstorage.reader.Key.NULL_FORMAT);
StringBuilder allColumns = new StringBuilder();
StringBuilder allColumnTypes = new StringBuilder();
boolean isReadAllColumns = false;
int columnIndexMax = -1;
// 判斷是否讀取所有列
if (null == column || column.size() == 0) {
int allColumnsCount = getAllColumnsCount(sourceOrcFilePath);
columnIndexMax = allColumnsCount - 1;
isReadAllColumns = true;
} else {
columnIndexMax = getMaxIndex(column);
}
for (int i = 0; i <= columnIndexMax; i++) {
allColumns.append("col");
allColumnTypes.append("string");
if (i != columnIndexMax) {
allColumns.append(",");
allColumnTypes.append(":");
}
}
if (columnIndexMax >= 0) {
JobConf conf = new JobConf(hadoopConf);
Path orcFilePath = new Path(sourceOrcFilePath);
Properties p = new Properties();
p.setProperty("columns", allColumns.toString());
p.setProperty("columns.types", allColumnTypes.toString());
try {
OrcSerde serde = new OrcSerde();
serde.initialize(conf, p);
StructObjectInspector inspector = (StructObjectInspector) serde.getObjectInspector();
InputFormat<?, ?> in = new OrcInputFormat();
FileInputFormat.setInputPaths(conf, orcFilePath.toString());
//If the network disconnected, will retry 45 times, each time the retry interval for 20 seconds
//Each file as a split
//TODO multy threads
InputSplit[] splits = in.getSplits(conf, 1);
RecordReader reader = in.getRecordReader(splits[0], conf, Reporter.NULL);
Object key = reader.createKey();
Object value = reader.createValue();
// 獲取列資訊
List<? extends StructField> fields = inspector.getAllStructFieldRefs();
List<Object> recordFields;
while (reader.next(key, value)) {
recordFields = new ArrayList<Object>();
for (int i = 0; i <= columnIndexMax; i++) {
Object field = inspector.getStructFieldData(value, fields.get(i));
recordFields.add(field);
}
transportOneRecord(column, recordFields, recordSender,
taskPluginCollector, isReadAllColumns, nullFormat);
}
reader.close();
} catch (Exception e) {
String message = String.format("從orcfile檔案路徑[%s]中讀取資料發生例外,請聯系系統管理員,"
, sourceOrcFilePath);
LOG.error(message);
throw DataXException.asDataXException(HdfsReaderErrorCode.READ_FILE_ERROR, message);
}
} else {
String message = String.format("請確認您所讀取的列配置正確!columnIndexMax 小于0,column:%s", JSON.toJSONString(column));
throw DataXException.asDataXException(HdfsReaderErrorCode.BAD_CONFIG_VALUE, message);
}
}
在對原始DataX原始碼進行調整后,重新對HdfsReader工程模塊進行打jar,并覆寫DataX部署的libs目錄下的HdfsReader的jar,重啟DataX應用后問題得到解決,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/433392.html
標籤:其他
下一篇:零拷貝機制在檔案傳輸中的使用手法