sparksql將國家統計局csv檔案決議并存盤在hive表
- 目的
- 分析
- 資料下載
- 資料標準化
- 資料存盤
- 開發環境集成
- 實作
- 專案創建
- 依賴
- 資料標準化
- DataFrame 行列轉置
- 資料存盤
- 主程式邏輯
- 驗證
- 啟動
- 本地存盤
- 遠程存盤
- 總結
git地址:https://gitee.com/jyq_18792721831/sparkmaven.git
目的
學習大資料,那么資料從哪來?
國家統計局可以免費下載社會上的各種資料,所以從國家統計局下載資料就是一個不錯的資料來源渠道,當然這種只是適合自己練習或者有針對性的分析資料,一般各個公司都有自己的收集資料的渠道和方式,不用考慮資料的來源,而是更多考慮如何使用資料,
國家統計局下載的資料一般有多種格式,csv,excel,txt,xml等,對于程式來說,最好的可能是csv和txt格式了,
下載的csv資料可以使用文本編輯器打開,或者是excel打開,但是這種只是適合用戶操作,對于少量資料還行,對于多個檔案,大量的資料的話就不合適了,
所以需要把國家統計局下載的csv資料寫到hive中(或者其他資料庫存盤中),
目的就非常的明確了,將國家統計局的csv資料寫入到hive中,
分析
資料下載
從國家統計局下載一個csv檔案,首先需要注冊國家統計局賬號,并查詢需要的資料,以價格指數為例
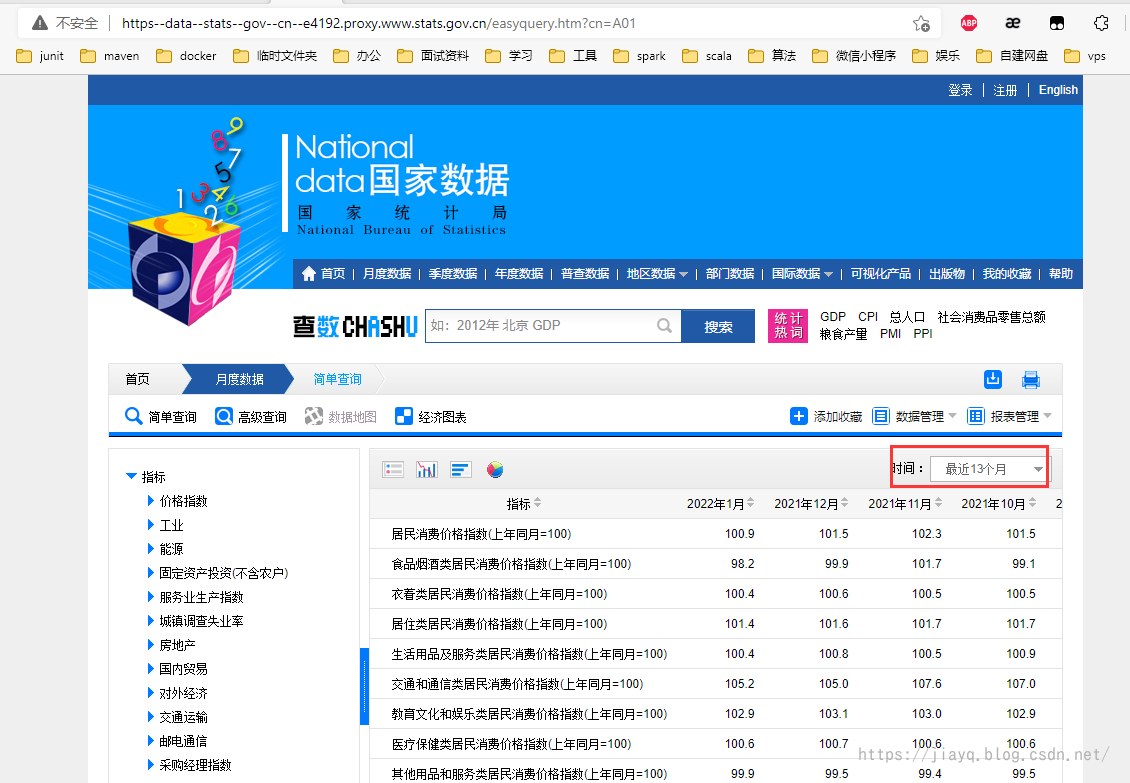
默認查詢最近13個月的資料,從界面上最多可以下載5年的資料,在時間那里輸入201601-確定查詢
然后點擊下載
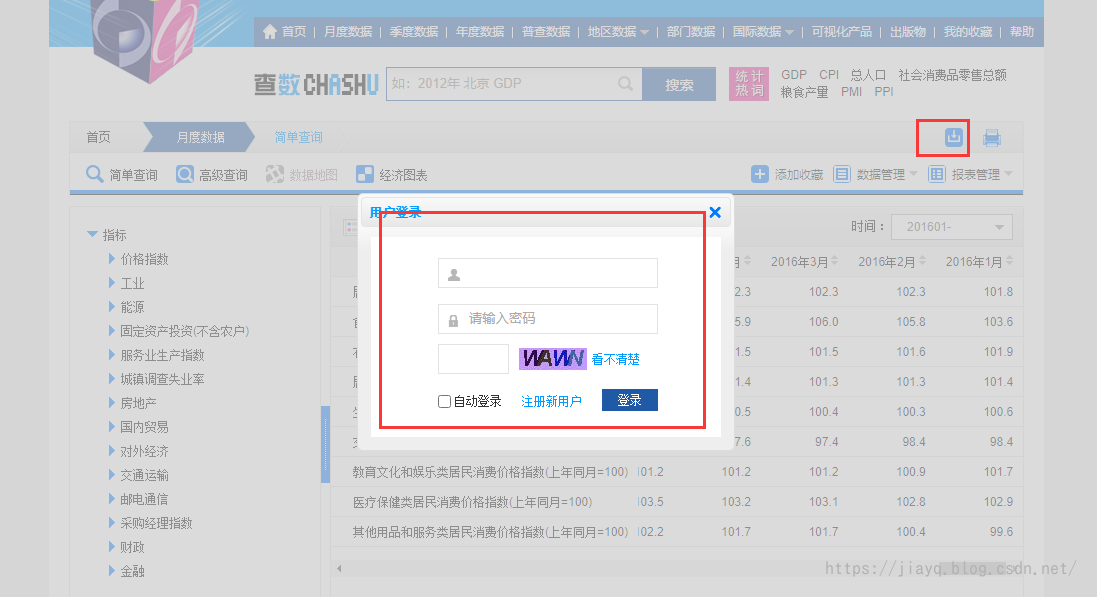
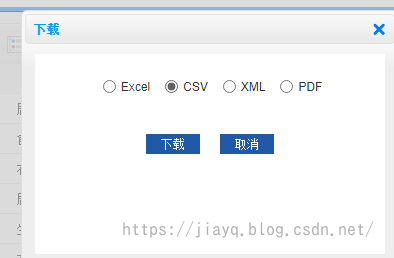
登錄后記得重新指定查詢時間條件,下載csv格式的檔案
資料標準化
下載后用excel打開如下
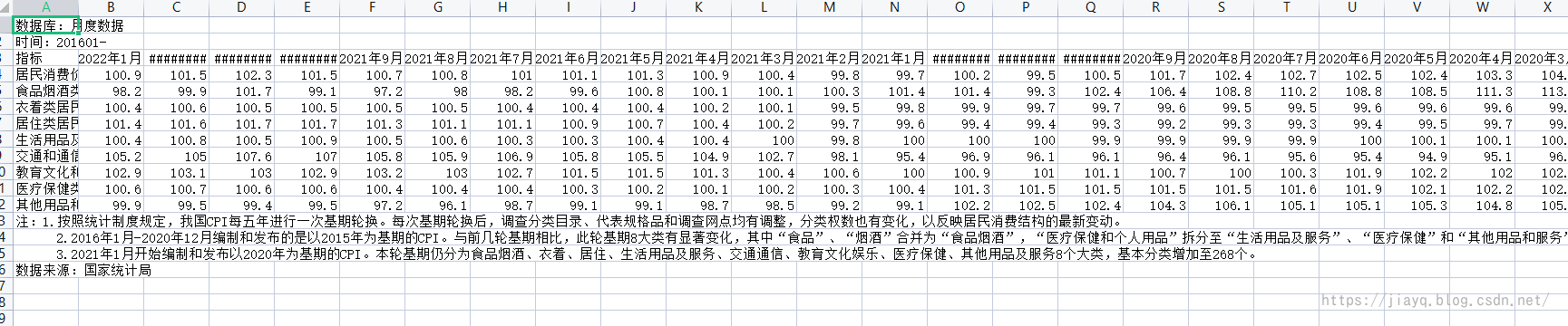
資料表和資料庫中的資料存在不同,比如在資料的上面和下面有說明資訊,然后是資料是橫向排列的,而不是縱向排列的
所以需要去除說明資訊,并且把資料從橫向排列轉置為縱向排列,
資料存盤
資料存盤在hive中,有兩種存盤方式,第一種是把hive當做資料庫使用,以資料庫表的方式存盤,第二種是把hive當做硬碟使用,
因為hive是可以直接查詢檔案,并且和hive表的使用并無不同,所以這兩種存盤方式在使用上并無不同,
開發環境集成
使用idea開發,就需要在idea中連接遠程的hive和遠程的hdfs,并且支持idea中寫入,在其他的hive客戶端中查詢,
實作
專案創建
在idea中創建一個基于maven的spark專案,這部分可以參見 使用maven集成java和scala開發環境_a18792721831的博客-CSDN博客
整個專案結構如下
把資料存盤在根專案的data/gov目錄下
接著創建一個object檔案
依賴
專案是spark專案,就需要增加spark的依賴
先把scala和spark的依賴引入
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-compiler</artifactId>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-reflect</artifactId>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.12</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>${mysql.jdbc.version}</version>
</dependency>
資料標準化
根據資料的展示,知道資料標準化需要做兩步,第一步是檔案編碼的問題,下載的csv檔案不知道是什么編碼格式,當把資料檔案放倒data/gov目錄下后,使用idea打開csv檔案
默認是utf-8編碼打開csv檔案
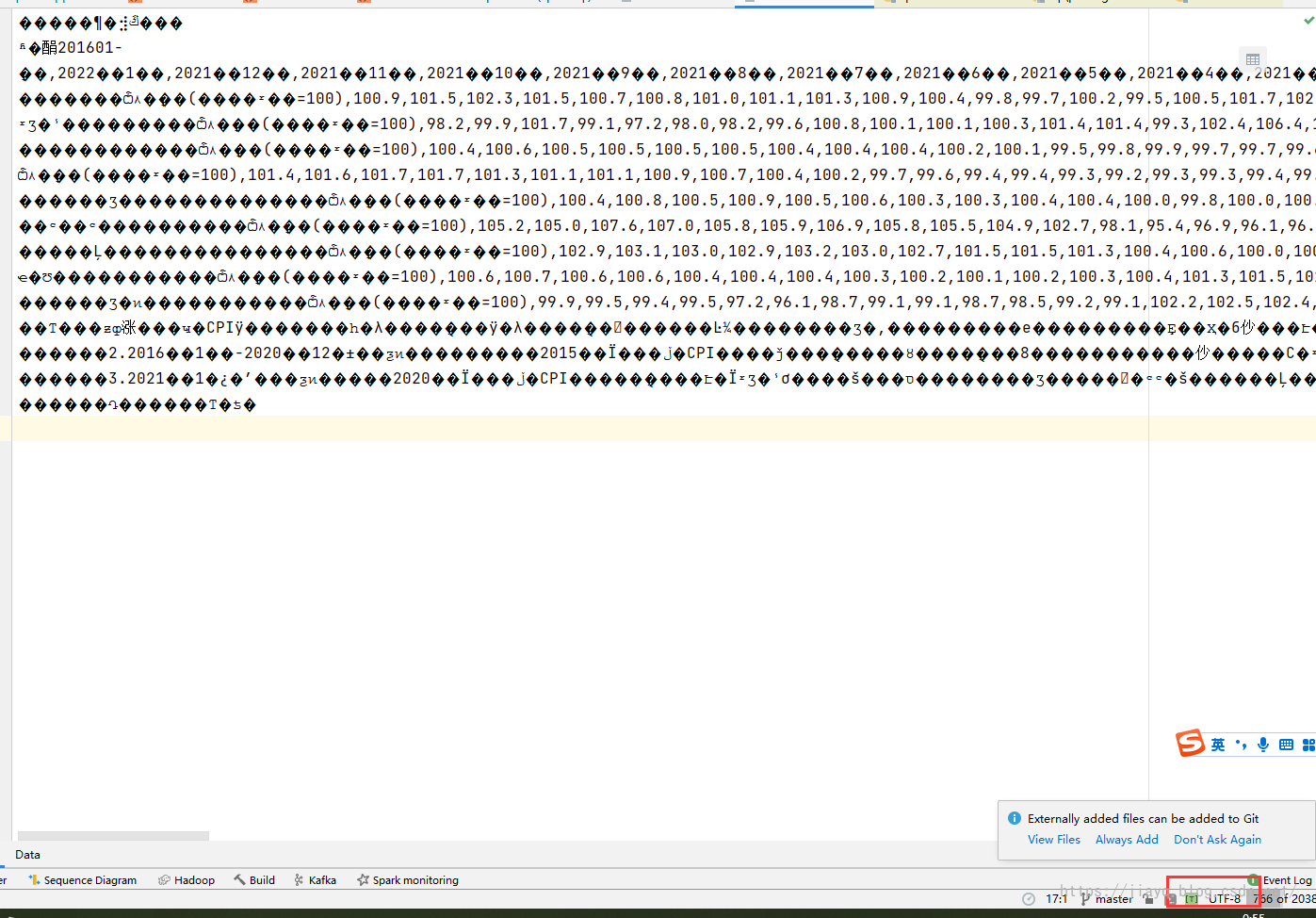
最新的idea中會自動嘗試不同的編碼方式,提示正確的編碼方式,如果沒有提示,可以不斷嘗試不同的常見的中文編碼方式,
國家統計局下載的csv檔案的編碼方式為GB18030
但是在開發中,一般是使用UTF-8編碼方式,而且spark讀取檔案,默認也是UTF-8的檔案編碼方式,所以需要把csv檔案轉為UTF-8格式,
第二步是需要將說明的資訊去除,也就是一行只有一個單元格的行去除,
因為csv檔案一般是以,分割資料單元格,所以可以按行讀取檔案,然后按照,分割行,如果分割后的單元格數量小于2,就是需要去除的行,
資料標準化的方法如下:
/**
* 去除單個單元格一行的資料(以行為單位)
*
* @param path 輸入應該csv檔案的全路徑,以`.csv`結尾
* @param readEncoding 輸入檔案的編碼,默認`GB18030`
* @param writeEncoding 輸出檔案的編碼,默認`UTF-8`
* @param split csv檔案的分隔符,默認`,`
* @return 新的csv檔案的全路徑
*/
def removeExplainCessCsv(path: String, readEncoding: String = "GB18030", writeEncoding: String = "UTF-8", split: Char = ','): String = {
// 1. 構造新csv檔案的全路徑
val outPath = (path substring(0, path.length - 4)) + NO_EXPLAIN
// 如果檔案已經存在,那么直接回傳
if (new File(outPath) exists()) {
log info s"no explain csv file ${outPath} exists."
return outPath
}
// 2. 構造檔案讀取,寫入
val reader = new FileReader(path, Charset.forName(readEncoding))
val writer = new FileWriter(outPath, Charset.forName(writeEncoding))
// 3. 獲取待緩沖區的讀取,寫入
val buffReader = new BufferedReader(reader)
val buffWriter = new BufferedWriter(writer)
// 4. 讀取一行,根據傳入的分隔符分割
buffReader lines() filter (_.split(split).size > 1) forEach (a => buffWriter.write(s"${a}\n"))
// 5. 資源重繪關閉
buffWriter flush()
buffWriter close()
buffReader close()
reader close()
writer close()
outPath
}
這個方法的作用是讀取csv檔案,然后去除說明行,并進行檔案編碼轉換后的檔案用新的檔案存盤,存盤在源檔案目錄下,需要注意的是如果傳入的是已經標準化的檔案,那么跳過,
方法的回傳值是新csv檔案的全路徑,
DataFrame 行列轉置
讀取新的csv檔案后,此時資料的排列方式還是橫向的,不符合資料庫的排列方式,需要將資料做行列轉置,將資料的排列方式從橫向轉置為縱向,
具體思路:
DataFrame可以查詢某一個列,將某個列轉置為行,將全部的列進行轉置,就實作了行列轉置,
/**
* DF行列轉置,采用每次查詢一列的方式
*
* @param data 需要做行列轉置的DF
* @param header 指定表頭名字,默認為空,為空取 c0,c1...
* @param startCol 開始的列
* @param endCol 結束的列
* @return 行列轉置后的DF
*/
def transposeDS(data: DataFrame, header: Array[String] = Array[String](), startCol: Int = 1, endCol: Int = -1) = {
// 1. 獲取DF的行數,行數做新DS的列數
val rowCount = if (endCol == -1) data count() else if (endCol > data.count()) data count() else endCol
val rowNo = if (startCol < 0) 0 else startCol
// 2. 根據獲取的行數構建schema
var fields = Array[StructField]()
if (header nonEmpty) {
for (h <- header) {
fields = fields :+ StructField(h, StringType, true)
}
} else {
for (i <- Range(0, rowCount toInt)) {
fields = fields :+ StructField(s"c${i}", StringType, true)
}
}
val schema = StructType(StructField("id", StringType, false) +: fields)
// 3. 新的行
var rows = List[Row]()
// 4. 獲取每一行
import data.sparkSession.implicits._
for (i <- Range(rowNo, rowCount toInt)) {
// 獲取列的資料
val line = data select (s"_c${i}") map (_ getString (0)) collect()
rows = rows :+ Row.fromSeq(UUID.randomUUID().toString.replaceAll("-", "").toUpperCase +: line)
}
// 5. 構造新的DF
data.sparkSession createDataFrame(rows asJava, schema)
}
為了區別,在轉置的時候,去除第一列,并新增id列,
在下載的csv檔案中,第一列是表頭,而這個表頭是中文,且比較長,所以需要去除原來的表頭,使用指定的表頭,
為了防止資料重復導致的問題,新增一個唯一的索引列id
資料存盤
在程式中,將轉置后的DataFrame存盤到hive中,首先以表的方式存盤
/**
* 決議一個csv檔案,將檔案內容去除說明單元格并進行行列轉置后,以檔案名創建表存盤在Hive上
*
* @param sparkSession
* @param file
*/
def parseCsvFile2Hive(sparkSession: SparkSession, file: File): Unit = {
// 如果傳入的檔案已經是沒有說明的檔案,表示已經被處理了,直接回傳
if (file.getPath.contains(NO_EXPLAIN)) {
log info s"${file getPath} is no explain file, skip it!"
return
}
// 1. 說明單元格去除,以及檔案編碼的處理
val path = removeExplainCessCsv(file getPath)
log info s"${file getPath} remove explain cell csv success, new file is ${path}"
// 2. 讀取新的csv檔案,并進行行列轉置
val df = transposeDS(sparkSession.read format ("csv") load ("file:\\" + path))
log info s"${path} transpose success!"
// 3. 決議表名
val tableName = path substring(path.lastIndexOf('\\') + 1, path lastIndexOf ('.')) replaceAll(NO_EXPLAIN substring(0, NO_EXPLAIN lastIndexOf '.'), "")
log info s"${path} parse table name is ${tableName}"
// 4. 注冊臨時視圖
df createOrReplaceTempView tableName
// 5. 寫入hive
(sparkSession sql s"select * from ${tableName}" write) mode SaveMode.Overwrite saveAsTable tableName
log info s"${tableName} data with mode ${SaveMode.Overwrite name()} save success!"
}
在創建hive表存盤的時候,希望使用源csv檔案的檔案名作為資料庫表名,
在寫入的時候,指定寫入模式為Overwrite
使用saveAsTable為寫入資料庫表,使用save則是寫入hdfs,
主程式邏輯
希望在呼叫程式的時候,可以指定csv檔案或者csv檔案的目錄(一次處理多個csv檔案),需要對傳入的路徑做處理
def main(args: Array[String]): Unit = {
// 指定hive存盤資料庫表的所有者,或是hive存盤的用戶名
System.setProperty("HADOOP_USER_NAME", "hive")
val sparkSession = (SparkSession
builder()
master ("local")
appName ("SparksqlDataApp")
// 配置hive的warehouse目錄為遠程的hdfs目錄
config("spark.sql.warehouse.dir", "hdfs://hadoop01:8020/user/hive/warehouse")
// 啟用hive
enableHiveSupport()
getOrCreate())
// 資料的路徑,或者是資料的全路徑
val rootPath = args(0)
if (rootPath isBlank) {
log error "input param should be a path for csv file or csv files directory! not blank."
return
}
// 切換hive的database為hello資料庫
sparkSession sql "use hello"
val rootFile = new File(rootPath)
if (rootFile isDirectory) {
for (file <- rootFile listFiles()) {
parseCsvFile2Hive(sparkSession, file)
}
} else {
parseCsvFile2Hive(sparkSession, rootFile)
}
}
驗證
啟動
第一次啟動會什么都不做,因為需要傳入一個路徑,直接啟動是沒有傳入的,所以什么都不做,直接結束,
第一次啟動后,就可以配置啟動資訊了
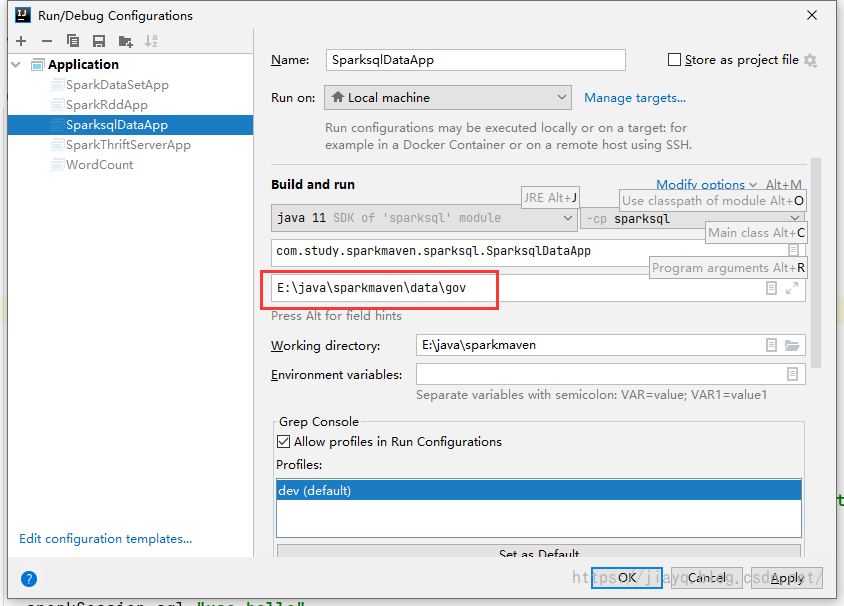
設定啟動引數為資料的目錄,
本地存盤
如果沒有設定warehouse目錄,那么默認是本地的專案根目錄,
直接存盤
直接存盤是使用save方法
這樣保存是在專案根目錄下創建表名目錄,然后將資料寫入這個目錄
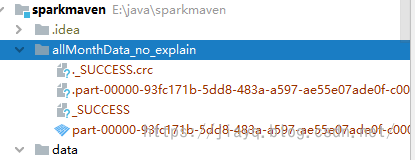
在程式中繼續使用這個表,資料的讀取來源就是這里,
資料庫表存盤
資料存盤是使用saveAsTable方法
會在wareouse目錄下創建指定資料庫的檔案夾,然后存盤,實際資料存盤的格式和直接存盤相同,
遠程存盤
要使用遠程存盤,需要將遠程的hive和遠程的hdfs的組態檔拷貝到專案的resources目錄下
hdfs組態檔hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>name</name>
<value>hadoop01</value>
</property>
<!-- 配置 hdfs 的 web 的訪問埠和限制,如果域名寫定,那么只能允許指定域名訪問 -->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop01:9870</value>
</property>
<!-- 配置 hdfs 的 nameNode 的資料存盤目錄 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/hadoop/dfs/name</value>
</property>
<!-- 配置 hdfs 的dataNode 的資料存盤目錄 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/hadoop/dfs/data</value>
</property>
<!-- 配置 hdfs 中資料的副本數量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!-- 配置 hdfs 中資料塊的大小 -->
<property>
<name>dfs.blocksize</name>
<value>2097152</value>
</property>
<!-- 配置哪些節點是 hdfs 的 dataNode -->
<!-- 允許 hadoop01 上啟動 dataNode ,也就是允許在hadoop01上存盤資料 -->
<property>
<name>dfs.hosts</name>
<value>/hadoop/etc/hadoop/slaves</value>
</property>
<!-- 配置哪些節點不是 hdfs 的 dataNode -->
<!-- 不允許 hadoop01 上啟動 dataNode , 也就是不允許在hadoop01上存盤資料 -->
<property>
<name>dfs.hosts.exclude</name>
<value>/hadoop/etc/hadoop/masters</value>
</property>
</configuration>
hadoop的core-site.xml配置
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 配置 hdfs 的地址,統一通信地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop01:8020</value>
</property>
<!-- 配置 hadoop 的臨時目錄 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/hadoop/tmp</value>
</property>
<!-- 配置讀寫快取大小 -->
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<!-- 設定超級代理 hive - jdbc -->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
</configuration>
hive的配置hive-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- hive 的元資料存盤路徑,使用mysql存盤 -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop01:3306/hive?createDatabaseIfNotExist=true</value>
</property>
<!-- 資料庫驅動 -->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
</property>
<!-- 資料庫用戶名 -->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!-- 資料庫密碼 -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<!-- 是否進行版本校驗 -->
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<!-- 權限處理 -->
<property>
<name>hive.server2.enable.doAs</name>
<value>false</value>
</property>
<!-- 最小作業執行緒,默認5 -->
<property>
<name>hive.server2.thrift.min.worker.threads</name>
<value>2</value>
</property>
<!-- 最大作業執行緒,默認500 -->
<property>
<name>hive.server2.thrift.max.worker.threads</name>
<value>5</value>
</property>
<!-- 系結埠,默認10000 -->
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
<!-- 系結地址,默認0.0.0.0 -->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>0.0.0.0</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
</configuration>
需要注意遠程的mysql需要支持遠程訪問,可以參考Hive 安裝、配置、資料匯入和使用_a18792721831的博客-CSDN博客
直接存盤
此時啟動如果是直接存盤,會在hdfs中存盤和直接存盤類似的資料
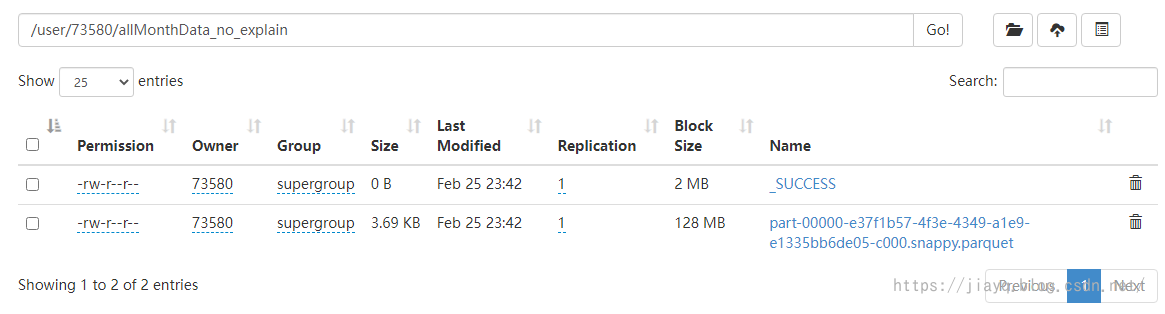
如果沒有指定HADOOP_USER_NAME則會以當前登錄的windows用戶名作為用戶名的目錄下以表名的目錄存盤
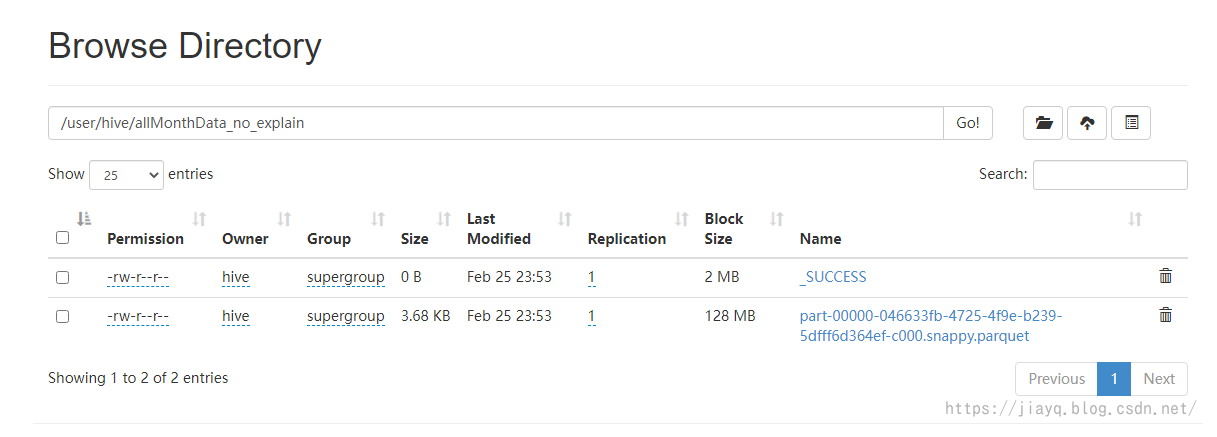
資料庫表存盤
如果你的hive的元資料不是使用mysql存盤,那么會在hdfs上的用戶名中以database創建目錄,以表名再次創建目錄,然后存盤
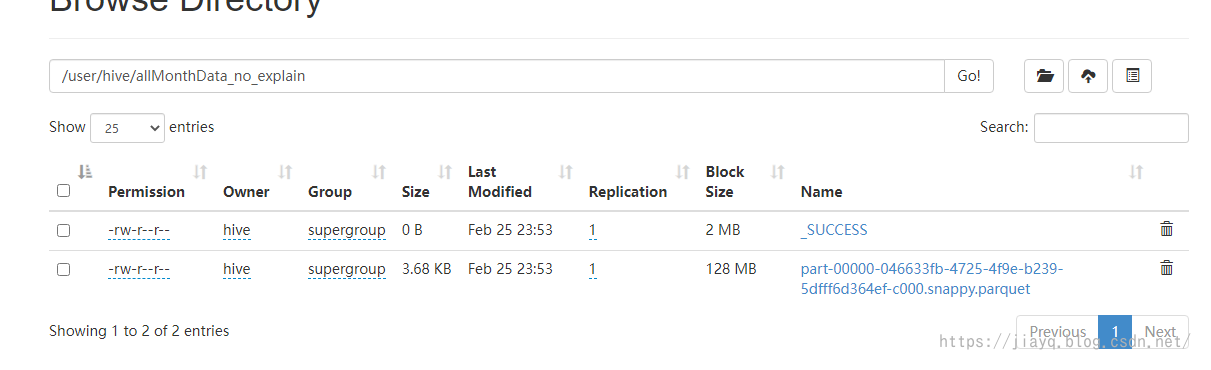
如果是用mysql存盤hive的元資料,則會在mysql中存盤資料庫表的元資料
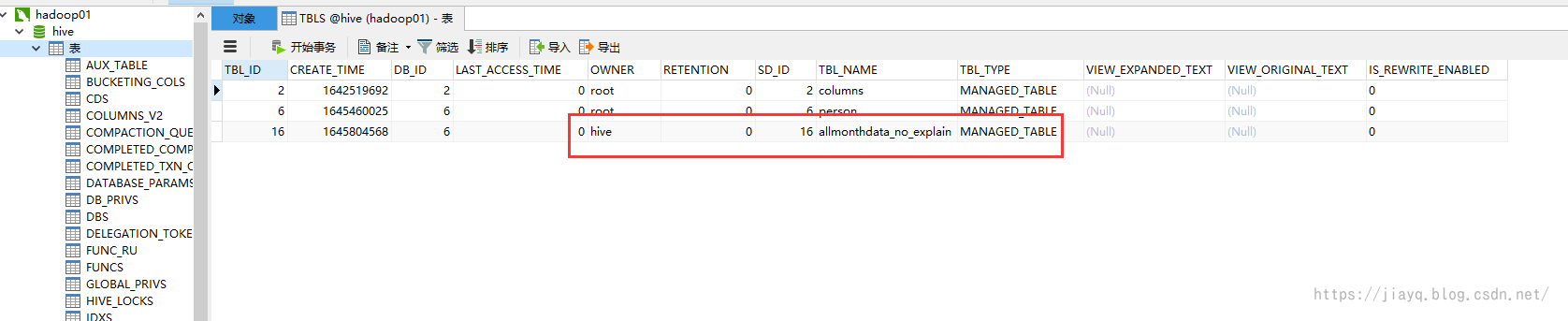
真正的資料存盤在warehouse目錄下
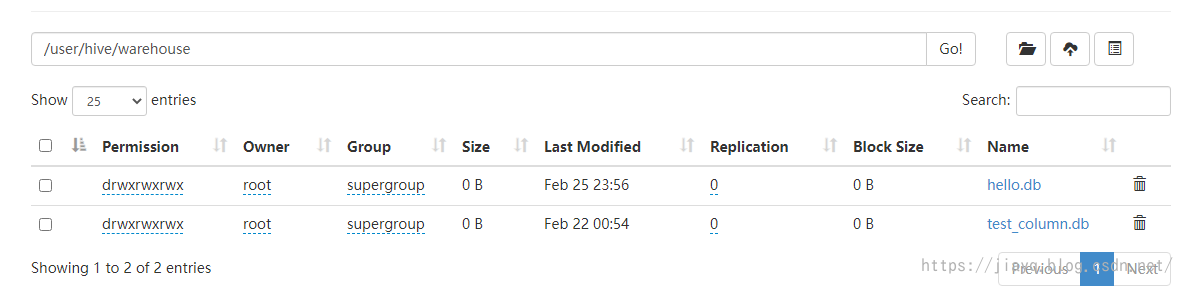
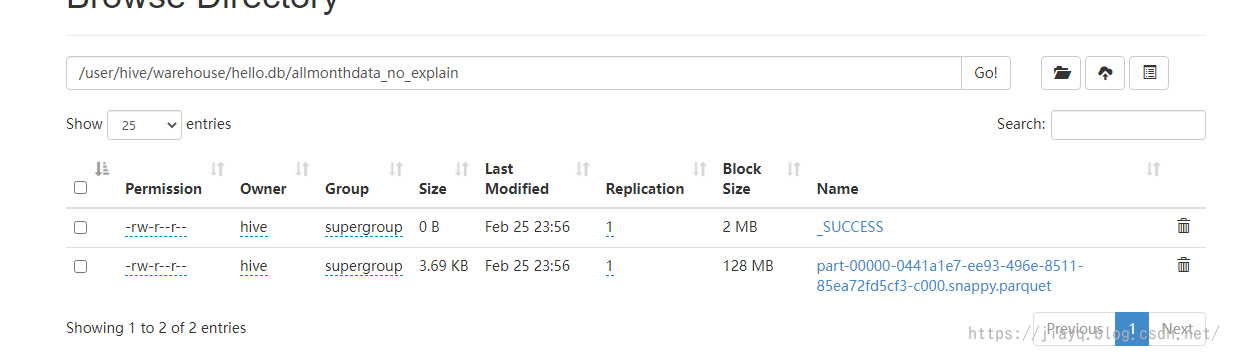
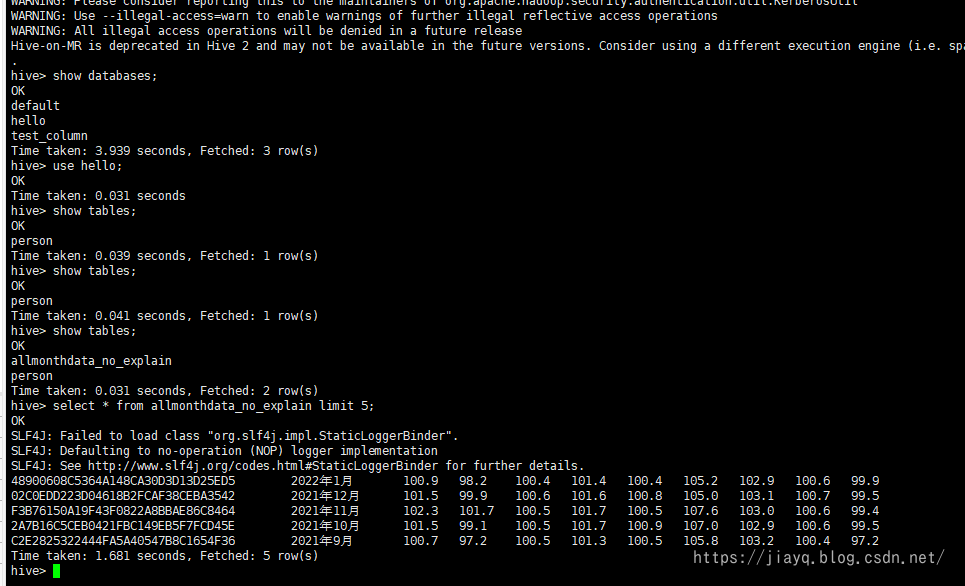
存盤為資料庫表就可以在hive的客戶端中查詢了
總結
在實作這個專案的時候,有些難點,
首先是資料如何讀取到程式中,因為無法確定檔案編碼,導致讀取的中文總是亂碼,后面慢慢嘗試,終于找到了正確的編碼方式,為了后面處理更加方便,直接使用程式進行轉碼,將GB18030轉為更常用的UTF-8編碼,
第二個難點是對說明資訊的去除,以及新的csv檔案的寫入,剛開始完全不知道該如何處理,后來想到scala和java是無縫使用的,那么就直接用java的類進行處理不就好了嗎,
第三個難點是DataFrame的行列轉置,網上的很多資料都是使用透視實作,可惜我不會使用,好在前面學習了Rdd和DataFrame的相關處理spark sql 創建rdd以及DataFrame和DataSet互轉_a18792721831的博客-CSDN博客,就使用最基本的方式處理行列轉置,
第四個難點是開發環境集成遠程的hdfs和遠程的hive,因為剛開始一直是存盤在本地,無法存盤到集群中,后面根據網上的資料,終于實作了開發環境存盤到遠程集群中,
雖然難點不少,但是卻也是一個不錯的例子,
未實作的功能:
首先是只能處理本地檔案系統中的資料,無法處理hdfs檔案系統中的檔案,這塊涉及到hdfs檔案系統在編碼中的使用,暫時還未接觸到,所以沒有實作,
其次是這應該是個工具類,應該打包放倒集群服務器上,這樣就直接使用jar的方式使用,打包操作還未實作,
最后是資料清洗不夠徹底,應該把時間中的中文去掉,因為暫時還未想好如何使用這些資料,所以未實作,
原本是打算把資料用可視化的方式展示出來,這部分涉及到資料可視化,還未實作,
不過不用擔心,上面這些知識點,比如打包,之前就研究過,只是在這個例子中不是重點,所以沒有實作,其他的后面應該會逐漸用到把,
總的來說,實際上做了資料的存盤,也就是數倉功能,將資料做簡單處理后存盤到hive中,提供給其他功能使用,
像類似的框架有Sqoop,后面有機會研究研究,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/433395.html
標籤:其他