文章目錄
- 一、Hadoop是什么
- 二、Hadoop生態系統圖
- 三、Hadoop生態圈常用組件
- (一)Hadoop
- (二)HDFS
- (三)MapReduce
- (四)Hive
- (五)Hbase
- (六)ZooKeeper
- (七)Sqoop
- (八)Pig
- (九)Mahout
- (十)Flume
- (十一)Oozie
- (十二)Hue
- (十三)Nutch
- (十四)Avro
- (十五)Phoenix
- (十六)Storm
- (十七)Flink
- (十八)Spark
- (十九)YARN
- (二十)Kafka
一、Hadoop是什么
- 官網網址:https://hadoop.apache.org/
大資料學習筆記:初探大資料世界
二、Hadoop生態系統圖
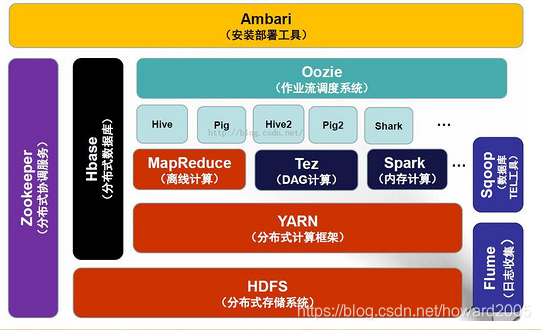
三、Hadoop生態圈常用組件
(一)Hadoop
- Hadoop是一個能夠對大量資料進行分布式處理的軟體框架,具有可靠、高效、可伸縮的特點,Hadoop的核心是HDFS和Mapreduce,hadoop2.0還包括YARN,
- 大資料學習筆記06:偽分布式Hadoop
- 大資料學習筆記11:搭建完全分布式Hadoop
- 大資料學習筆記29:Hadoop壓碩訓制演示
- 大資料學習筆記30:搭建高可用Hadoop集群
- 大資料學習筆記31:Java程式訪問高可用Hadoop集群
(二)HDFS
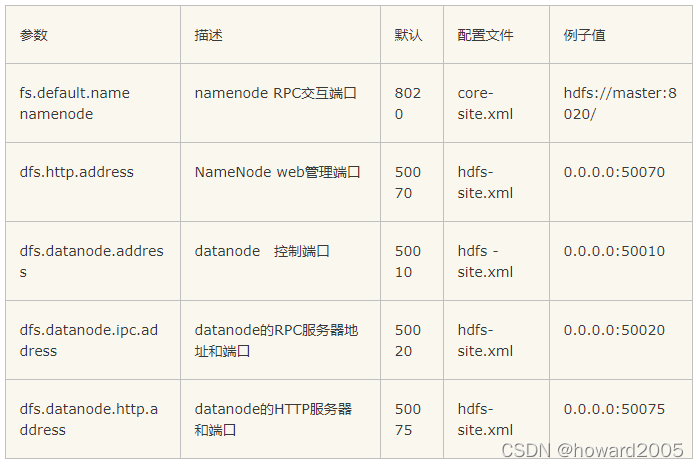
- HDFS是Hadoop的分布式檔案系統,是Hadoop體系中資料存盤管理的基礎,它是一個高度容錯的系統,能檢測和應對硬體故障,用于在低成本的通用硬體上運行,HDFS簡化了檔案的一致性模型,通過流式資料訪問,提供高吞吐量應用程式資料訪問功能,適合帶有大型資料集的應用程式,
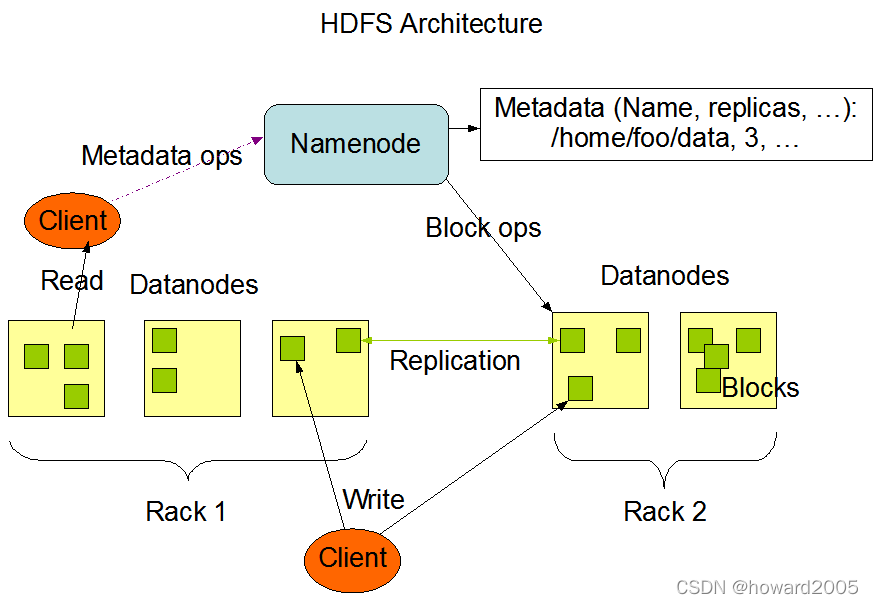
- 大資料學習筆記07:分布式檔案系統HDFS
- 大資料學習筆記08:Java程式訪問HDFS
(三)MapReduce
- MapReduce是一種分布式計算框架,用以進行大資料量的計算,其中Map對資料集上的獨立元素進行指定的操作,生成鍵-值對形式中間結果,Reduce則對中間結果中相同“鍵”的所有“值”進行規約,以得到最終結果,MapReduce這樣的功能劃分,非常適合在大量計算機組成的分布式并行環境里進行資料處理,
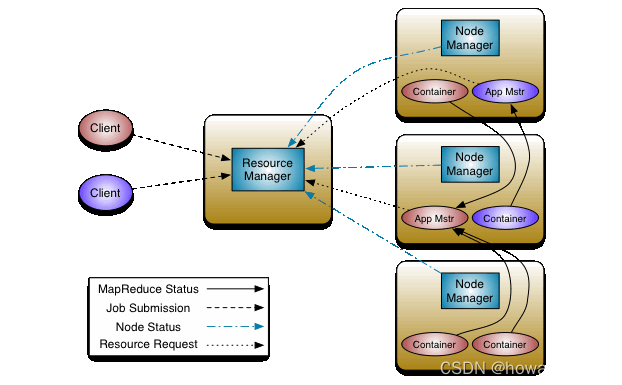
- 大資料學習筆記09:MapReduce概述
- 大資料學習筆記10:MR案例——詞頻統計
- 大資料學習筆記13:MR案例——顯示每年最高溫度
- 大資料學習筆記14:MR案例——招聘資料分析
- 大資料學習筆記15:MR案例——IP地址去重
- 大資料學習筆記16:MR案例——計算學生平均成績
- 大資料學習筆記17:MR案例——磁區統計總利潤與平均利潤
- 大資料學習筆記18:MR案例——磁區匯總流量
- 大資料學習筆記19:MR案例——匯總三科成績表檔案
- 大資料學習筆記20:MR案例——按電影熱度值排序
- 大資料學習筆記21:MR案例——磁區全排序
- 大資料學習筆記22:MR案例——雙MR統計總利潤并排序
- 大資料學習筆記23:MR案例——采用Combiner做詞頻統計
- 大資料學習筆記24:利用MR改造Zebra專案
- 大資料學習筆記25:MR案例——自定義輸入輸出格式處理個人成績
- 大資料學習筆記26:MR案例——雙重排序(先按月份升序,再按利潤降序)
- 大資料學習筆記27:MR案例——多輸入源處理成績
- 大資料學習筆記28:MR案例——多輸出源處理成績
(四)Hive
- Hive是基于Hadoop的資料倉庫,定義了一種類似SQL的查詢語言(HQL),將SQL轉化為MapReduce任務在Hadoop上執行,Hive并不能夠在大規模資料集上實作低延遲快速的查詢,Hive并不適合那些需要低延遲的應用,Hive并非為聯機事務處理處理而設計,Hive并不提供實時的查詢和基于行級的資料更新操作,Hive的最佳使用場合是大資料集的批處理作業,比如網站日志分析,
- 大資料學習筆記32:Hive - 下載、安裝與配置
- 大資料學習筆記34:Hive - 資料庫與表操作
- 大資料學習筆記35:Hive - 內部表與外部表
- 大資料學習筆記36:Hive - 磁區表
- 大資料學習筆記37:Hive - 復雜資料型別
- 大資料學習筆記38:Hive - 內置函式(1)
- 大資料學習筆記39:Hive - 內置函式(2)
- 大資料學習筆記40:Hive - 內置函式(3)
- 大資料學習筆記42:Hive - 分桶表
- 大資料學習筆記43:Hive - JDBC編程
(五)Hbase
- HBase是一個針對結構化資料的可伸縮、高可靠、高性能、分布式和面向列的動態模式資料庫,和傳統關系資料庫不同,HBase采用了BigTable的資料模型:增強的稀疏排序映射表(Key/Value),其中,鍵由行關鍵字、列關鍵字和時間戳構成,HBase提供了對大規模資料的隨機、實時讀寫訪問,同時,HBase中保存的資料可以使用MapReduce來處理,它將資料存盤和并行計算完美地結合在一起,
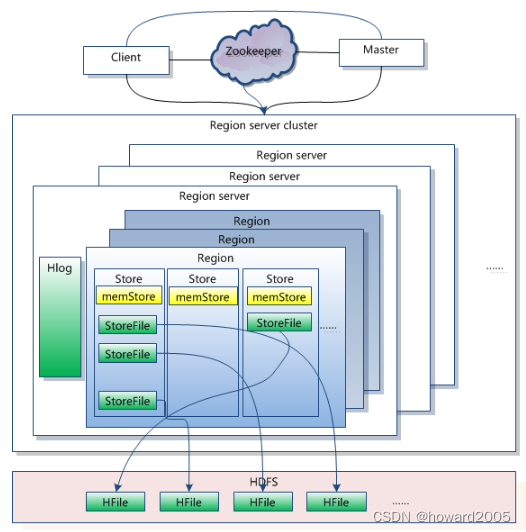
- 大資料學習筆記54:HBase概述
- 大資料學習筆記55:搭建HBase環境
- 大資料學習筆記56:HBase Shell操作
- 大資料學習筆記57:Java代碼操作HBase
(六)ZooKeeper
- 分布式協作服務Zookeeper解決分布式環境下的資料管理問題:統一命名,狀態同步,集群管理,配置同步等,
- 大資料學習筆記04:單機模式使用ZooKeeper
- 大資料學習筆記05:ZooKeeper集群
(七)Sqoop
- 資料同步工具Sqoop是SQL-to-Hadoop的縮寫,主要用于傳統資料庫和Hadoop之前傳輸資料,資料的匯入和匯出本質上是Mapreduce程式,充分利用了MR的并行化和容錯性,
- 大資料學習筆記45:Sqoop - 資料遷移工具
(八)Pig
- Pig是基于Hadoop的資料流系統,由yahoo!開源,設計動機是提供一種基于MapReduce的ad-hoc(計算在query時發生)資料分析工具,定義了一種資料流語言—Pig Latin,將腳本轉換為MapReduce任務在Hadoop上執行,通常用于進行離線分析,
(九)Mahout
- 資料挖掘演算法庫Mahout的主要目標是創建一些可擴展的機器學習領域經典演算法的實作,旨在幫助開發人員更加方便快捷地創建智能應用程式,Mahout現在已經包含了聚類、分類、推薦引擎(協同過濾)和頻繁集挖掘等廣泛使用的資料挖掘方法,除了演算法,Mahout還包含資料的輸入/輸出工具、與其他存盤系統(如資料庫、MongoDB 或Cassandra)集成等資料挖掘支持架構,
(十)Flume
- Flume是Cloudera開源的日志收集系統,具有分布式、高可靠、高容錯、易于定制和擴展的特點,它將資料從產生、傳輸、處理并最終寫入目標的路徑的程序抽象為資料流,在具體的資料流中,資料源支持在Flume中定制資料發送方,從而支持收集各種不同協議資料,同時,Flume資料流提供對日志資料進行簡單處理的能力,如過濾、格式轉換等,此外,Flume還具有能夠將日志寫往各種資料目標(可定制)的能力,總的來說,Flume是一個可擴展、適合復雜環境的海量日志收集系統,
- 大資料學習筆記46:初識日志收集系統Flume
- 大資料學習筆記47:Flume - 下載、安裝與配置
- 大資料學習筆記48:Flume Sources(Flume源)
- 大資料學習筆記49:Flume Sinks(Flume接收器)
- 大資料學習筆記50:Flume Channels(Flume通道)
- 大資料學習筆記51:Flume Channel Selectors(Flume通道選擇器)
(十一)Oozie
- 作業流調度引擎Oozie是一個基于作業流引擎的服務器,可以在上面運行Hadoop的Map Reduce和Pig任務,它其實就是一個運行在Java Servlet容器(比如Tomcat)中的Javas Web應用,
(十二)Hue
- Hue是Hadoop自己的監控管理工具,Hue是一個可快速開發和除錯Hadoop生態系統各種應用的一個基于瀏覽器的圖形化用戶介面,
(十三)Nutch
- Nutch 是一個開源Java實作的搜索引擎,它提供了我們運行自己的搜索引擎所需的全部工具,包括全文搜索和Web爬蟲,
(十四)Avro
- 資料序列化工具Avro是一個資料序列化系統,設計用于支持大批量資料交換的應用,它的主要特點有:支持二進制序列化方式,可以便捷,快速地處理大量資料;動態語言友好,Avro提供的機制使動態語言可以方便地處理Avro資料,
(十五)Phoenix
- 可以把Phoenix只看成一種代替HBase的語法的一個工具,雖然可以用java可以用jdbc來連接phoenix,然后操作HBase,但是在生產環境中,不可以用在OLTP(在線事務處理)中,在線事務處理的環境中,需要低延遲,而Phoenix在查詢HBase時,雖然做了一些優化,但延遲還是不小,所以依然是用在OLAP(聯機分析處理)中,再將結果回傳存盤下來,
(十六)Storm
- Storm是Twitter開源的分布式實時大資料處理框架,最早開源于github,從0.9.1版本之后,歸于Apache社區,被業界稱為實時版Hadoop,隨著越來越多的場景對Hadoop的MapReduce高延遲無法容忍,比如網站統計、推薦系統、預警系統、金融系統(高頻交易、股票)等等,大資料實時處理解決方案(流計算)的應用日趨廣泛,目前已是分布式技術領域最新爆發點,而Storm更是流計算技術中的佼佼者和主流,
- Storm案例:統計單詞個數
(十七)Flink
- Flink是一個針對流資料和批資料的分布式處理引擎,其所要處理的主要場景就是流資料,批資料只是流資料的一個極限特例而已,再換句話說,Flink 會把所有任務當成流來處理,這也是其最大的特點,Flink 可以支持本地的快速迭代,以及一些環形的迭代任務,并且 Flink 可以定制化記憶體管理,在這點,如果要對比 Flink 和 Spark 的話,Flink 并沒有將記憶體完全交給應用層,這也是為什么 Spark 相對于 Flink,更容易出現 OOM 的原因(out of memory),
(十八)Spark
- Spark是一個新興的大資料處理通用引擎,提供了分布式的記憶體抽象,Spark 正如其名,最大的特點就是快(Lightning-fast),可比 Hadoop MapReduce 的處理速度快 100 倍,此外,Spark 提供了簡單易用的 API,幾行代碼就能實作 WordCount,本教程主要參考官網快速入門教程,介紹了 Spark 的安裝,Spark shell 、RDD、Spark SQL、Spark Streaming 等的基本使用,
- Spark基礎學習筆記01:初步了解Spark
- Spark基礎學習筆記02:搭建Spark環境
(十九)YARN
- YARN(Yet Another Resource Negotiator,另一種資源協調者)是一種新的 Hadoop 資源管理器,它是一個通用資源管理系統,可為上層應用提供統一的資源管理和調度,它的引入為集群在利用率、資源統一管理和資料共享等方面帶來了巨大好處,
(二十)Kafka
- Kafka是一種高吞吐量的分布式發布訂閱訊息系統,它可以處理消費者規模的網站中的所有動作流資料, 這種動作(網頁瀏覽,搜索和其他用戶的行動)是在現代網路上的許多社會功能的一個關鍵因素, 這些資料通常是由于吞吐量的要求而通過處理日志和日志聚合來解決, 對于像Hadoop的一樣的日志資料和離線分析系統,但又要求實時處理的限制,這是一個可行的解決方案,Kafka的目的是通過Hadoop的并行加載機制來統一線上和離線的訊息處理,也是為了通過集群來提供實時的消費,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/433397.html
標籤:其他
上一篇:Spark雜談(map和flatmap的區別 怎樣把rdd的結果存盤)
下一篇:R語言為dataframe添加新的資料列(橫向拼接、Appending columns,Unioning columns):使用R原生方法、data.table、dplyr等方案