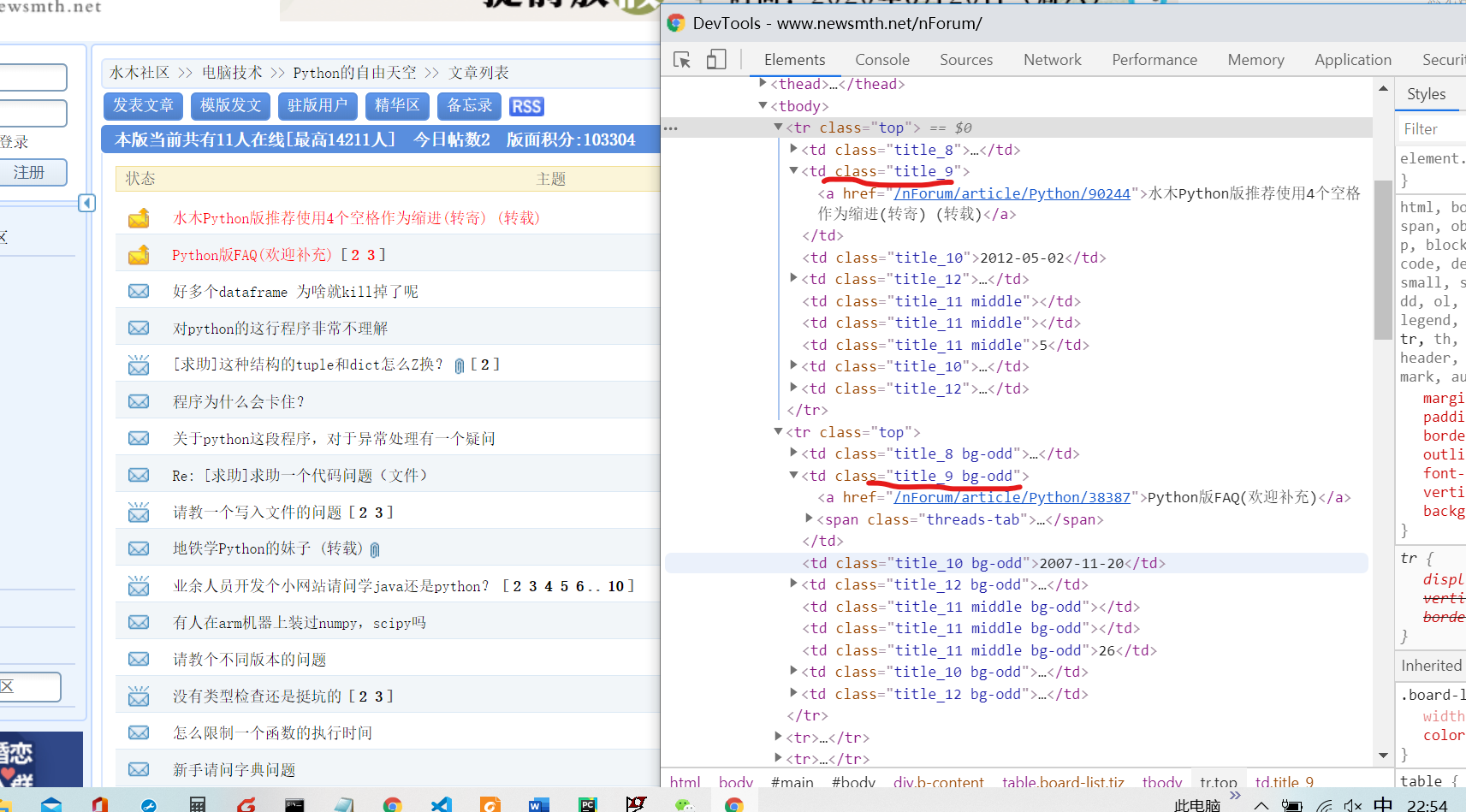
我用python寫了一個爬取水木社區(http://www.newsmth.net/nForum/#!board/Python?p=1)的爬蟲,來爬取這一頁的每個帖子的鏈接,我用瀏覽器查看了每個帖子的鏈接放在<td class='title_9'> <td>和<td class='title_9 bg-odd'> <td>這樣的標簽里。我使用td=tbody.find_all('td',class_='title_9')可以回傳所有class='title_9'和class='title_9 bg-odd'的所有帖子,為什么class='title_9 bg-odd'的帖子也能找到? 我使用td=tbody.find_all('td',class_='title_9 bg-odd')時,卻回傳空,一個帖子也找不到。然后我print(tbody)把tbody的內容列印出來,發現列印出來的所有帖子都在<td class='title_9'> <td>里面,所有的class='title_9 bg-odd'都變成了class='title_9'了,為什么會這樣呢?為什么程式列印出來的tbody的內容和在瀏覽器上看到的不一樣?求大神幫忙解答一下,謝謝啦。
瀏覽器看到的:
程式輸出的:
uj5u.com熱心網友回復:
前端中<td class='title_9 bg-odd'> <td> ,這是兩個class他,“title_9”和“bg-odd”
后端中td=tbody.find_all('td',class_='title_9 bg-odd') 這是一個class,“title_9 bg-odd”,中間的是空格,所以沒有匹配的。
uj5u.com熱心網友回復:
參考 1 樓 糊里糊涂的一鍋粥 的回復: 前端中<td class='title_9 bg-odd'> <td> ,這是兩個class他,“title_9”和“bg-odd”
“title_9”和“bg-odd”不是在一個引號里面嗎?為什么是兩個class呢?
同一個網頁,我print(soup.find('table', class_='board-list tiz'))可以找到對應的內容啊,class內容也是有空格的。
uj5u.com熱心網友回復:
前端中<td class='title_9 bg-odd'> <td> ,這是兩個class屬性,find_all查一下這個方法的引數具體的資訊,我感覺怎么寫了兩個是個模糊查詢
uj5u.com熱心網友回復:
參考 3 樓 糊里糊涂的一鍋粥 的回復: 前端中<td class='title_9 bg-odd'> <td> ,這是兩個class屬性,find_all查一下這個方法的引數具體的資訊,我感覺怎么寫了兩個是個模糊查詢
那為啥class_='board-list tiz'就不是兩個class屬性呢?
uj5u.com熱心網友回復:
參考 4 樓 FoxFiled 的回復:
python中引號內的是字串,
我使用td=tbody.find_all('td',class_='title_9 bg-odd')時,卻回傳空, 這是你原帖子上的一句換,我用手機版CSDN看的時候發現 title_9和bg-odd之間有好多空格,所以沒有匹配到時空的,
下面的這個demo可以觀察分析一下
from bs4 import BeautifulSoup
uj5u.com熱心網友回復:
參考 5 樓 糊里糊涂的一鍋粥 的回復: Quote: 參考 4 樓 FoxFiled 的回復: 我使用td=tbody.find_all('td',class_='title_9 bg-odd')時,卻回傳空, 這是你原帖子上的一句換,我用手機版CSDN看的時候發現 title_9和bg-odd之間有好多空格,所以沒有匹配到時空的,from bs4 import BeautifulSoup
是的,td2 = soup.find_all('td', {'class': 'title_9'})確實能夠回傳title_9和title_9 bg-odd這兩個class的資料。有一點不太明白的是,使用print(tbody),列印出來的資料中,前端看到的class='title_9 bg-odd'都變成了class='title_9'了,這是怎么回事?
uj5u.com熱心網友回復:
Quote: 參考 6 樓 FoxFiled 的回復: /quote]你的print(tbody) ,tbody是什么
uj5u.com熱心網友回復:
這個:uj5u.com熱心網友回復:
參考 7 樓 糊里糊涂的一鍋粥 的回復: Quote: 參考 6 樓 FoxFiled 的回復: /quote]你的print(tbody) ,tbody是什么 uj5u.com熱心網友回復:
參考 8 樓 FoxFiled 的回復: uj5u.com熱心網友回復:
參考 10 樓 糊里糊涂的一鍋粥 的回復: Quote: 參考 8 樓 FoxFiled 的回復: uj5u.com熱心網友回復:
參考 11 樓 FoxFiled 的回復: uj5u.com熱心網友回復:
參考 12 樓 糊里糊涂的一鍋粥 的回復: Quote: 參考 11 樓 FoxFiled 的回復: uj5u.com熱心網友回復:
參考 13 樓 FoxFiled的回復: Quote: 參考 12 樓 糊里糊涂的一鍋粥 的回復: Quote: 參考 11 樓 FoxFiled 的回復: uj5u.com熱心網友回復:
參考 14 樓 糊里糊涂的一鍋粥 的回復: Quote: 參考 13 樓 FoxFiled的回復: Quote: 參考 12 樓 糊里糊涂的一鍋粥 的回復: Quote: 參考 11 樓 FoxFiled 的回復: uj5u.com熱心網友回復:
參考 15 樓 FoxFiled的回復: Quote: 參考 14 樓 糊里糊涂的一鍋粥 的回復: Quote: 參考 13 樓 FoxFiled的回復: Quote: 參考 12 樓 糊里糊涂的一鍋粥 的回復: Quote: 參考 11 樓 FoxFiled 的回復:
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/43401.html
標籤:腳本語言(Perl/Python)
上一篇:深入理解計算機系統大作業——程式人生P2P
下一篇:Python第三方庫安裝