1、困難
在實際業務場景中,目前現有的框架在很大情況下可能不能滿足現有的需求,用代碼進行二次開發就是最好的選擇,在一開始進行的時候,根本無從下手是一方面,因為原始碼的量特別大,如果是在官方的原始碼中,基本上是沒有注解的,有的一般也是對方法的總體概述以及引數的介紹,往往困難是原始碼中的某一步我們理解不了,導致整個流程無法理解是一方面,另一方面是如何閱讀原始碼,用什么來閱讀原始碼,對于java開發者來說,我們在ide集成開發工具中從maven倉庫中引入的依賴就是一個個jar包,打開jar包我們可以直接看的到原始碼,但是卻不能修改,當然這里有一個辦法就是從官網下載原始碼包然后在原始碼的右上角可以選擇本地jar包這樣便可以修改了,但是實際上修改完之后還是使用的是maven引入的jar包依賴,如果想實作自定義jar包,便只能自己引入第三方jar包,而不是從maven倉庫中下載,
2、解決方案
在Hadoop大家族中,我們有非常多的組件,而Hadoop官方的安裝包中只是集成了其中的一小部分,
1、了解安裝包的目錄
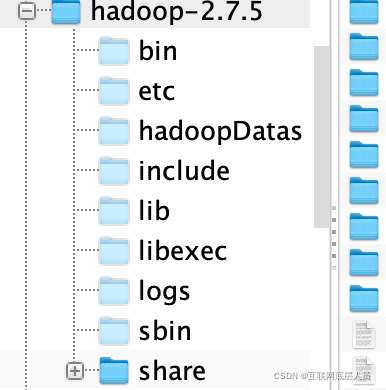
bin:使用hdfs和mapreduce時,常用的Hadoop命令目錄,
sbin:管理員常用命令目錄,主要用于啟動和停止集群,
etc:存放Hadoop的組態檔的目錄
include:C語言寫的一些工具類
lib:存放Hadoop的本地庫檔案(對資料進行壓縮解壓功能)
libexec:存放hadoop配置環境的一些檔案
share:本次的主角,存放Hadoop的依賴jar包,在集群運行時所有的一切都來源于這里,
所以要想對Hadoop進行二次開發,我們就必須要更換share目錄中的jar包,這里可以根據實際需求替換掉相應的jar包,比如Mapreduce中的各種jar包,
2、更換jar包
在博主初期修改jar包時,首先碰到的難題就是jar包是一種壓縮格式,我們可以輕松的把他解壓,但是在打包時會遇到各種壓縮軟體將它打包成zip的格式,查閱了各種資料最多的說就是說可以先打成zip形式,然后改后綴名的格式,當然這種是完全行不通的,只有一種辦法便是不要解壓縮,直接在jar包上進行添加洗掉操作,這里推薦兩種軟體,
- mac版本 betterzip
- Windows版本 winRAR
打開jar包之后我們可以發現,里面都是經過編譯器處理之后的class檔案,這里便碰到了第二個困難,就是如何打開class檔案,當然這里有很多反編譯工具,比如說jdGui,當然我們最常用的還是ide,再者比如說我碰到了一個類,在經過編譯之后形成了4個class檔案,所以如果在相當不熟悉原始碼檔案的時候,不太建議用class檔案進行反編譯,
最推薦的方法還是先經過ide進行原始碼閱讀,然后找到目標的包或者類,將其復制到ide中進行開發,當然其中肯定會報錯,因為少了各種各樣的包,這里可以經過maven引入相關的依賴,
當修改完目標類或者包之后,將其進行編譯,然后找到ide對應的目錄將class檔案取出,經由上述兩款軟體直接進行替換,而不是解壓再壓縮,最后更換至Hadoop目錄下的share檔案夾中便成功達到二次開發目的,
3、總結
當然不僅僅是Hadoop,包括jdk本身都可以這樣進行二次開發,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/434519.html
標籤:其他
上一篇:java操作 elasticsearch8.0 doc檔案<二>
下一篇:Springboot 整合 RabbitMQ【rabbitmq介紹:安裝,下載,創建佇列、交換機,5種作業模式】