學習資料推薦:
史上最小白之Attention詳解
史上最小白之Transformer詳解
圖解Transformer_夏目的博客-CSDN博客_transformer
圖解Transformer(完整版)_龍心塵-CSDN博客_transformer
圖解Transformer(完整版)!_abcdefg90876的博客-CSDN博客
深度學習:transformer模型_皮皮blog-CSDN博客_深度學習transformer
NLP:Transformer的簡介(優缺點)、架構詳解之詳細攻略_一個處女座的程式猿-CSDN博客
1.前言
本文參考其他優秀博客資料進行總結,推薦閱讀前兩篇文章學習Transformer,僅供個人學習,
Google于2017年6月發布在arxiv上的一篇文章《Attention is all you need》,提出解決sequence to sequence問題的transformer模型,用全attention的結構代替了lstm,拋棄了之前傳統的encoder-decoder模型必須結合cnn或者rnn的固有模式,只用attention,文章的主要目的是在減少計算量和提高并行效率的同時不損害最終的實驗結果( GLUE 上效果排名第一https://gluebenchmark.com/leaderboard),創新之處在于提出了兩個新的Attention機制,分別叫做 Scaled Dot-Product Attention 和 Multi-Head Attention,
考慮到RNN(或者LSTM、GRU等)的計算限制為是順序的,也就是說RNN相關演算法只能從左向右依次計算或者從右向左依次計算,這種機制帶來了兩個問題:
- 時間片t的計算依賴t-1時刻的計算結果,這樣限制了模型的并行能力;
- 順序計算的程序中資訊會丟失,盡管LSTM等門機制的結構一定程度上緩解了長期依賴的問題,但是對于特別長期的依賴現象,LSTM依舊無能為力,
2.Transformer 原理
2.1 Transformer整體結構
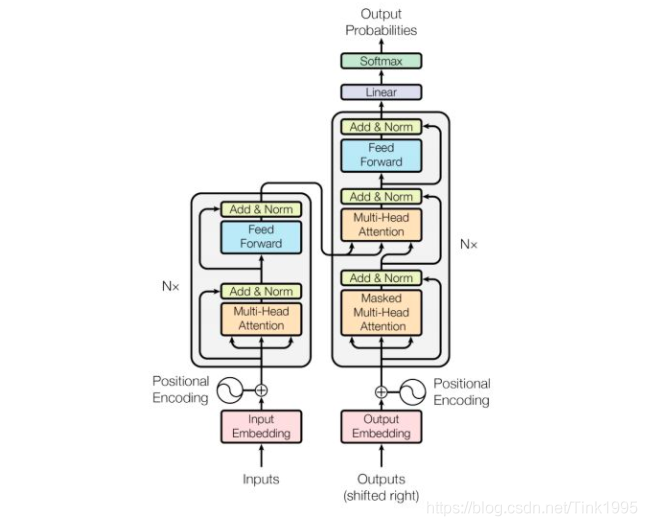
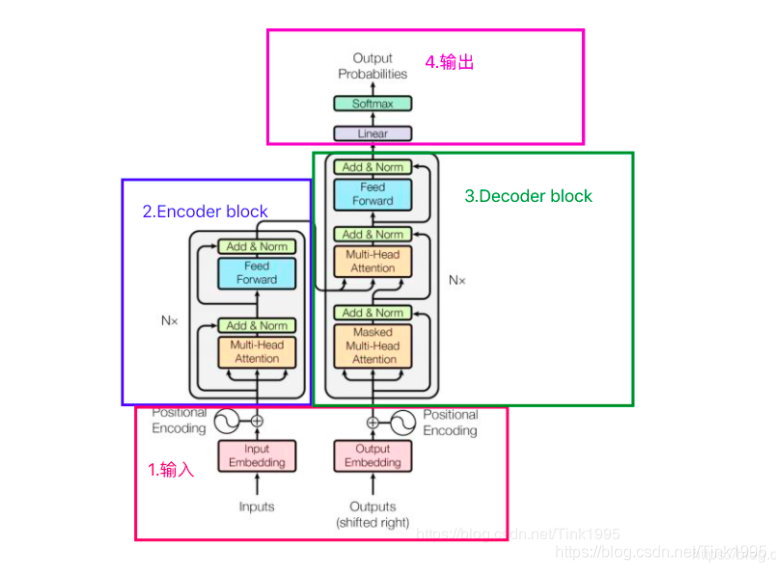
根據上圖進行一步步拆解Transformer:
Transformer的結構圖,拆解開來,主要分為圖上4個部分,其中最重要的就是2和3Encoder-Decoder部分,Transformer是一個基于Encoder-Decoder框架的模型,
接下來我將按照1,2,3,4的順序逐步介紹上圖中Transformer的網路結構,這樣既能夠弄清楚結構原理,又能夠方便理解Transformer模型的作業流程,
2.2 Transformer的inputs 輸入
Transformer輸入是一個序列資料,還是以上篇中提到的"Tom chase Jerry" 翻譯成中文"湯姆追逐杰瑞"為例:
Encoder 的 inputs就是"Tom chase Jerry" 分詞后的詞向量,可以是任意形式的詞向量,如word2vec,GloVe,one-hot編碼,
假設上圖中每一個詞向量都是一個512維的詞向量,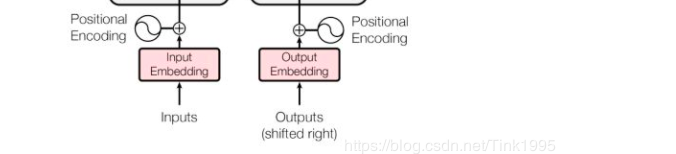
我們注意到,輸入inputs embedding后需要給每個word的詞向量添加位置編碼positional encoding,為什么需要添加位置編碼呢?
首先咱們知道,一句話中同一個詞,如果詞語出現位置不同,意思可能發生翻天覆地的變化,就比如:我欠他100W 和 他欠我100W,這兩句話的意思一個地獄一個天堂,可見獲取詞語出現在句子中的位置資訊是一件很重要的事情,但是咱們的Transformer 的是完全基于self-Attention地,而self-attention是不能獲取詞語位置資訊地,就算打亂一句話中詞語的位置,每個詞還是能與其他詞之間計算attention值,就相當于是一個功能強大的詞袋模型,對結果沒有任何影響,(一會兒在介紹Encoder的時候再詳細說明)所以在我們輸入的時候需要給每一個詞向量添加位置編碼,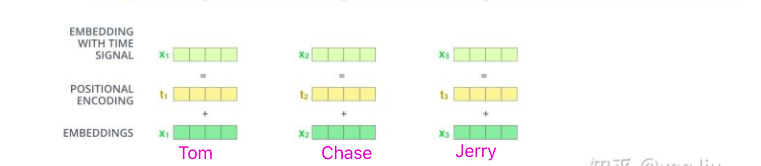
問題又來了,這個positional encoding怎么獲取呢?
1.可以通過資料訓練學習得到positional encoding,類似于訓練學習詞向量,goole在之后的bert中的positional encoding便是由訓練得到地,
2.《Attention Is All You Need》論文中Transformer使用的是正余弦位置編碼,位置編碼通過使用不同頻率的正弦、余弦函式生成,然后和對應的位置的詞向量相加,位置向量維度必須和詞向量的維度一致,程序如上圖,PE(positional encoding)計算公式如下: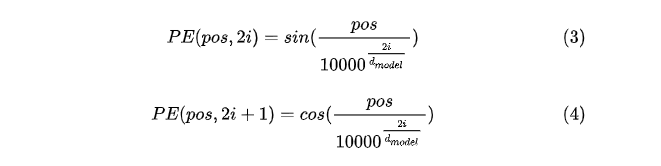
解釋一下上面的公式:
pos表示單詞在句子中的絕對位置,pos=0,1,2…,例如:Jerry在"Tom chase Jerry"中的pos=2;dmodel表示詞向量的維度,在這里dmodel=512;2i和2i+1表示奇偶性,i表示詞向量中的第幾維,例如這里dmodel=512,故i=0,1,2…255,
至于上面這個公式是怎么得來地,其實不重要,因為很有可能是作者根據經驗自己造地,而且公式也不是唯一地,后續goole在bert中的positional encoding也沒有再使用這種方法而是通過訓練PE,說明這種求位置向量的方法還是存在一定問題地,
這里我就不做詳細的介紹了,想要深究的朋友可以參考一下知乎上的這些回答:如何理解Transformer論文中的positional encoding,和三角函式有什么關系?
為什么是將positional encoding與詞向量相加,而不是拼接呢?
拼接相加都可以,只是本身詞向量的維度512維就已經蠻大了,再拼接一個512維的位置向量,變成1024維,這樣訓練起來會相對慢一些,影響效率,兩者的效果是差不多地,既然效果差不多當然是選擇學習習難度較小的相加了,
Transformer 的 Decoder的輸入與Encoder的輸出處理方法步驟是一樣地,一個接受source資料,一個接受target資料,對應到上面例子里面就是:Encoder接受英文"Tom chase Jerry",Decoder接受中文"湯姆追逐杰瑞",只是在有target資料時也就是在進行有監督訓練時才會接受Outputs Embedding,進行預測時則不會接收,
至此,Transformer的第一塊輸入部分已經講解完了,接下來就要進入重點部分Encoder和Decoder了,
2.2 Transformer的Encoder
看上圖第2部分 Encoder block,Encoder block是由6個encoder堆疊而成,Nx=6,上圖2中的灰框部分就是一個encoder的內部結構,從圖中我們可以看出一個encoder由Multi-Head Attention 和 全連接神經網路Feed Forward Network構成,
Multi-Head Attention: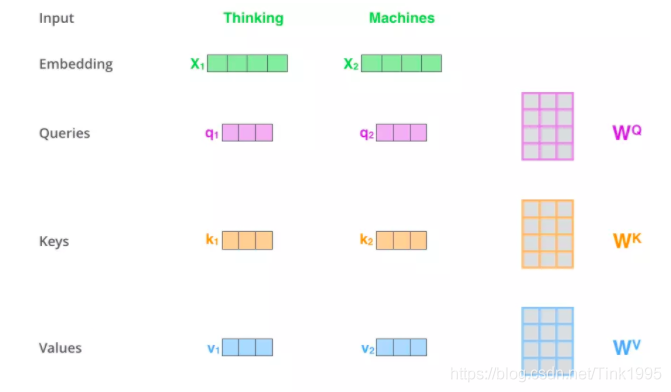
首先回顧一下self-attention,假如輸入序列是"Thinking Machines",x1,x2就是對應地"Thinking"和"Machines"添加過位置編碼之后的詞向量,然后詞向量通過三個權值矩陣W Q , W K , W V W^Q,W^K,W^VWQ,WK,WV,轉變成為計算Attention值所需的Query,Keys,Values向量,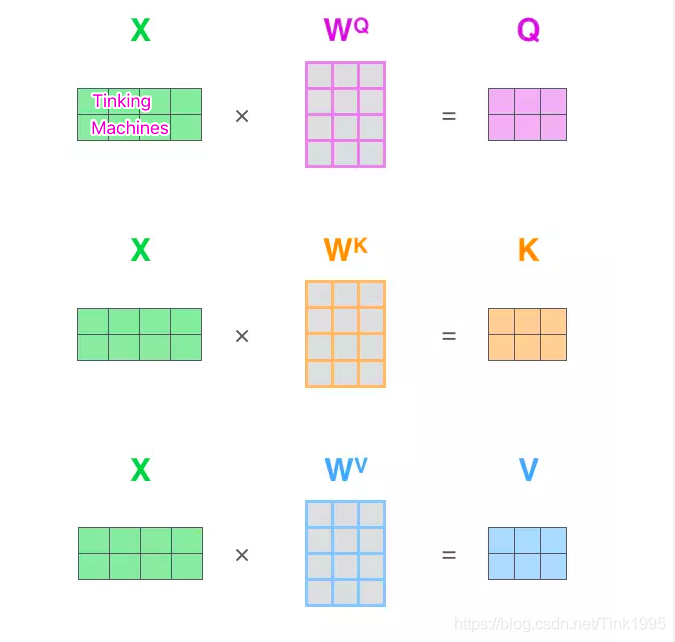
因為咱們再實際使用中,每一個樣本,也就是每一條序列資料都是以矩陣的形式輸入地,故可以看到上圖中,X矩陣是由"Tinking"和"Machines"詞向量組成的矩陣,然后跟過變換得到Q,K,V,假設詞向量是512維,X矩陣的維度是(2,512),W Q , W K , W V W^Q,W^K,W^VWQ,WK,WV均是(512,64)維,得到的Query,Keys,Values就都是(2,64)維,
得到Q,K,V之后,接下來就是計算Attention值了,
步驟1: 輸入序列中每個單詞之間的相關性得分,上篇中說過計算相關性得分可以使用點積法,就是用Q中每一個向量與K中每一個向量計算點積,具體到矩陣的形式:s c o r e = Q ? K T score = Q\cdot K^Tscore=Q?KT,socre是一個(2,2)的矩陣
步驟2: 對于輸入序列中每個單詞之間的相關性得分進行歸一化,歸一化的目的主要是為了訓練時梯度能夠穩定,s c o r e = s c o r e / d k score = score/\sqrt{d_k}score=score/dk??,dk就是K的維度,以上面假設為例,dk=64
步驟3: 通過softmax函式,將每個單詞之間的得分向量轉換成[0,1]之間的概率分布,同時更加凸顯單詞之間的關系,經過softmax后,score轉換成一個值分布在[0,1]之間的(2,2)α概率分布矩陣
步驟4: 根據每個單詞之間的概率分布,然后乘上對應的Values值,α與V進行點積,Z = s o f t m a x ( s c o r e ) ? V Z = softmax(score)\cdot VZ=softmax(score)?V,V的為維度是(2,64),(2,2)x(2,64)最后得到的Z是(2,64)維的矩陣
整體的計算圖如下: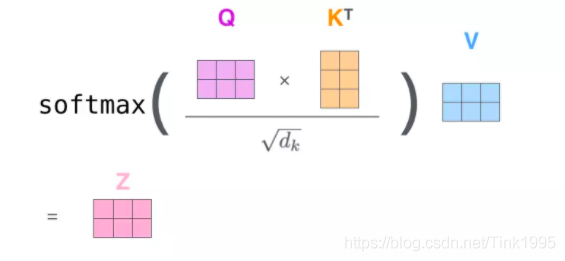
說了這么多好像都只是在說self-attention,那么Multi-Head Attention呢?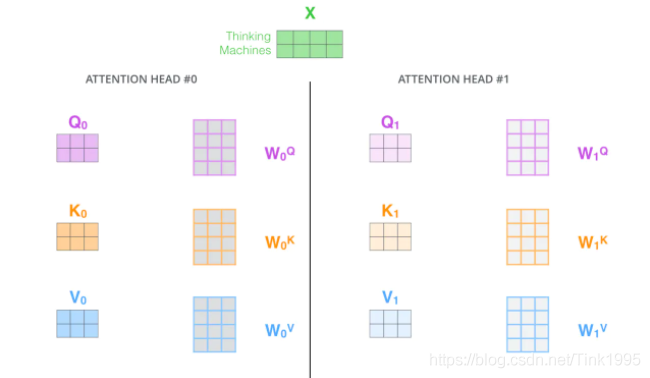
Multi-Head Attention 很簡單,就是在self-attention的基礎上,對于輸入的embedding矩陣,self-attention只使用了一組W Q , W K , W V W^Q,W^K,W^VWQ,WK,WV來進行變換得到Query,Keys,Values,而Multi-Head Attention使用多組W Q , W K , W V W^Q,W^K,W^VWQ,WK,WV得到多組Query,Keys,Values,然后每組分別計算得到一個Z矩陣,最后將得到的多個Z矩陣進行拼接,Transformer里面是使用了8組不同的W Q , W K , W V W^Q,W^K,W^VWQ,WK,WV,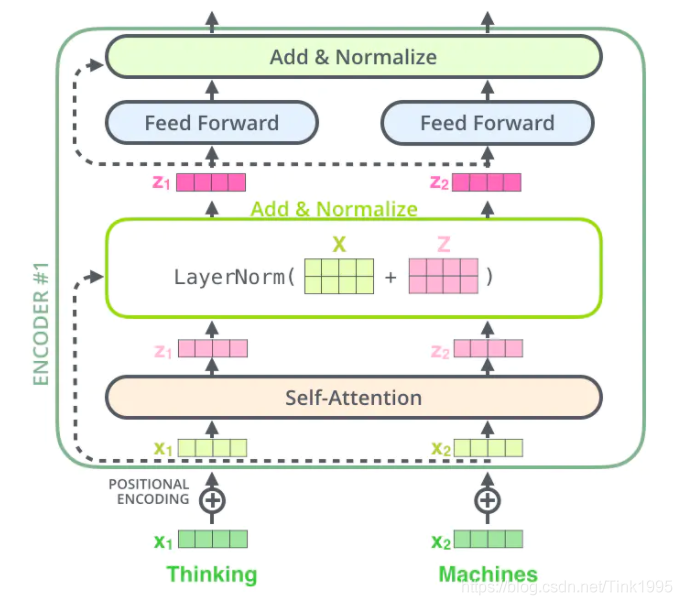
從上圖中可以看到,在經過Multi-Head Attention得到矩陣Z之后,并沒有直接傳入全連接神經網路FNN,而是經過了一步:Add&Normalize,
Add&Normalize:
Add
Add,就是在Z的基礎上加了一個殘差塊X,加入殘差塊X的目的是為了防止在深度神經網路訓練中發生退化問題,退化的意思就是深度神經網路通過增加網路的層數,Loss逐漸減小,然后趨于穩定達到飽和,然后再繼續增加網路層數,Loss反而增大,可能看到這里,小朋友你一定有很多問號???為什么深度神經網路會發生退化,為什么添加殘差塊能夠防止退化問題,殘差塊又是什么?這就牽扯到ResNet殘差神經網路的知識了,既然是史上最小白系列,堅決不做標題黨,一定把每個問題都解釋清楚!
ResNet 殘差神經網路:
首先解答第一個問題,為什么深度神經網路會發生退化?
舉個例子:假如某個神經網路的最優網路層數是18層,但是我們在設計的時候并不知道到底多少層是最優解,本著層數越深越好的理念,我們設計了32層,那么32層神經網路中有14層其實是多余地,我們要想達到18層神經網路的最優效果,必須保證這多出來的14層網路必須進行恒等映射,恒等映射的意思就是說,輸入什么,輸出就是什么,可以理解成F(x)=x這樣的函式,因為只有進行了這樣的恒等映射咱們才能保證這多出來的14層神經網路不會影響我們最優的效果,
但現實是神經網路的引數都是訓練出來地,要想保證訓練出來地引數能夠很精確的完成F(x)=x的恒等映射其實是很困難地,多余的層數較少還好,對效果不會有很大影響,但多余的層數一多,可能結果就不是很理想了,這個時候大神們就提出了ResNet 殘差神經網路來解決神經網路退化的問題,
殘差塊是什么?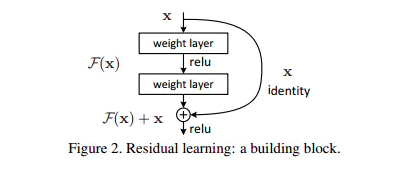
上圖就是構造的一個殘差塊,可以看到X是這一層殘差塊的輸入,也稱作F(X)為殘差,X為輸入值,F(X)是經過第一層線性變化并激活后的輸出,該圖表示在殘差網路中,第二層進行線性變化之后激活之前,F(X)加入了這一層輸入值X,然后再進行激活后輸出,在第二層輸出值激活前加入X,這條路徑稱作shortcut連接,
為什么添加了殘差塊能防止神經網路退化問題呢?
咱們再來看看添加了殘差塊后,咱們之前說的要完成恒等映射的函式變成什么樣子了,是不是就變成h(X)=F(X)+X,我們要讓h(X)=X,那么是不是相當于只需要讓F(X)=0就可以了,這里就巧妙了!神經網路通過訓練變成0是比變成X容易很多地,因為大家都知道咱們一般初始化神經網路的引數的時候就是設定的[0,1]之間的亂數嘛,所以經過網路變換后很容易接近于0,舉個例子: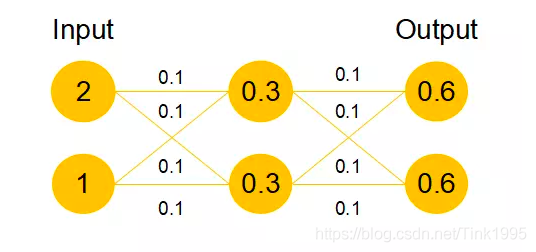
假設該網路只經過線性變換,沒有bias也沒有激活函式,我們發現因為隨機初始化權重一般偏向于0,那么經過該網路的輸出值為[0.6 0.6],很明顯會更接近與[0 0],而不是[2 1],相比與學習h(x)=x,模型要更快到學習F(x)=0,
并且ReLU能夠將負數激活為0,過濾了負數的線性變化,也能夠更快的使得F(x)=0,這樣當網路自己決定哪些網路層為冗余層時,使用ResNet的網路很大程度上解決了學習恒等映射的問題,用學習殘差F(x)=0更新該冗余層的引數來代替學習h(x)=x更新冗余層的引數,
這樣當網路自行決定了哪些層為冗余層后,通過學習殘差F(x)=0來讓該層網路恒等映射上一層的輸入,使得有了這些冗余層的網路效果與沒有這些冗余層的網路效果相同,這樣很大程度上解決了網路的退化問題,
到這里,關于Add中為什么需要加上一個X,要進行殘差網路中的shortcut你清楚了嗎?Transformer中加上的X也就是Multi-Head Attention的輸入,X矩陣,
Normalize
為什么要進行Normalize呢?
在神經網路進行訓練之前,都需要對于輸入資料進行Normalize歸一化,目的有二:1,能夠加快訓練的速度,2.提高訓練的穩定性,
為什么使用Layer Normalization(LN)而不使用Batch Normalization(BN)呢?
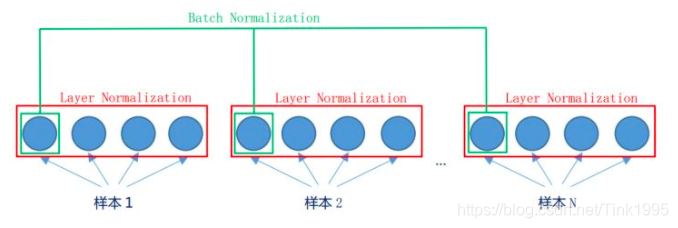
先看圖,LN是在同一個樣本中不同神經元之間進行歸一化,而BN是在同一個batch中不同樣本之間的同一位置的神經元之間進行歸一化,
BN是對于相同的維度進行歸一化,但是咱們NLP中輸入的都是詞向量,一個300維的詞向量,單獨去分析它的每一維是沒有意義地,在每一維上進行歸一化也是適合地,因此這里選用的是LN,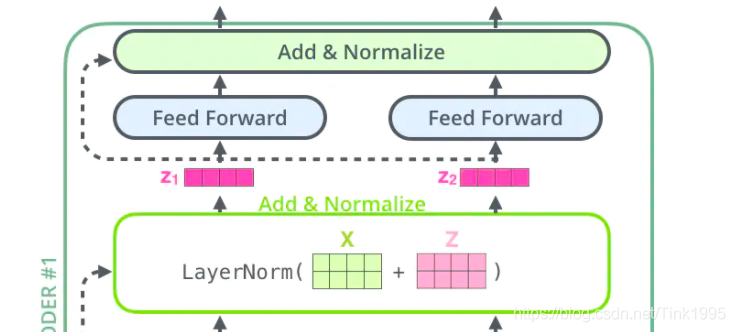
Feed-Forward Networks
全連接層公式如下:
F F N ( x ) = m a x ( 0 , x W 1 + b 1 ) W 2 + b 2 FFN(x)=max(0,xW_1+b_1)W_2+b_2FFN(x)=max(0,xW1?+b1?)W2?+b2?
這里的全連接層是一個兩層的神經網路,先線性變換,然后ReLU非線性,再線性變換,
這里的x就是我們Multi-Head Attention的輸出Z,還是參考上面的例子,那么Z是(2,64)維的矩陣,假設W1是(64,1024),其中W2與W1維度相反(1024,64),那么按照上面的公式:
FFN(Z)=(2,64)x(64,1024)x(1024,64)=(2,64),我們發現維度沒有發生變化,這兩層網路就是為了將輸入的Z映射到更加高維的空間中(2,64)x(64,1024)=(2,1024),然后通過非線性函式ReLU進行篩選,篩選完后再變回原來的維度,
然后經過Add&Normalize,輸入下一個encoder中,經過6個encoder后輸入到decoder中,至此Transformer的Encoder部分就全部介紹完了,搞懂了Encoder那么Decoder就so easy啦,基本上結構和Encoder差不多,接下來咱們就進入Decoder部分吧~
2.3 Transformer的Decoder
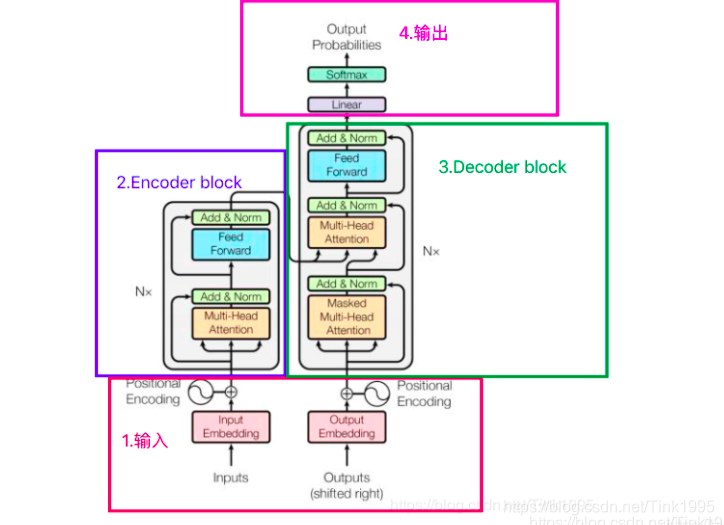
看上圖第3部分 Decoder block,Decoder block也是由6個decoder堆疊而成,Nx=6,上圖3中的灰框部分就是一個decoder的內部結構,從圖中我們可以看出一個decoder由Masked Multi-Head Attention,Multi-Head Attention 和 全連接神經網路FNN構成,比Encoder多了一個Masked Multi-Head Attention,其他的結構與encoder相同,那么咱們就先來看看這個Masked Multi-Head Attention,
Transformer Decoder的輸入
Decoder的輸入分為兩類:
一種是訓練時的輸入,一種是預測時的輸入,
訓練時的輸入就是已經對準備好對應的target資料,例如翻譯任務,Encoder輸入"Tom chase Jerry",Decoder輸入"湯姆追逐杰瑞",
預測時的輸入,一開始輸入的是起始符,然后每次輸入是上一時刻Transformer的輸出,例如,輸入"",輸出"湯姆",輸入"湯姆",輸出"湯姆追逐",輸入"湯姆追逐",輸出"湯姆追逐杰瑞",輸入"湯姆追逐杰瑞",輸出"湯姆追逐杰瑞"結束,
Masked Multi-Head Attention
與Encoder的Multi-Head Attention計算原理一樣,只是多加了一個mask碼,mask 表示掩碼,它對某些值進行掩蓋,使其在引數更新時不產生效果,Transformer 模型里面涉及兩種 mask,分別是 padding mask 和 sequence mask,為什么需要添加這兩種mask碼呢?
1.padding mask
什么是 padding mask 呢?因為每個批次輸入序列長度是不一樣的也就是說,我們要對輸入序列進行對齊,具體來說,就是給在較短的序列后面填充 0,但是如果輸入的序列太長,則是截取左邊的內容,把多余的直接舍棄,因為這些填充的位置,其實是沒什么意義的,所以我們的attention機制不應該把注意力放在這些位置上,所以我們需要進行一些處理,
具體的做法是,把這些位置的值加上一個非常大的負數(負無窮),這樣的話,經過 softmax,這些位置的概率就會接近0!
2.sequence mask
sequence mask 是為了使得 decoder 不能看見未來的資訊,對于一個序列,在 time_step 為 t 的時刻,我們的解碼輸出應該只能依賴于 t 時刻之前的輸出,而不能依賴 t 之后的輸出,因此我們需要想一個辦法,把 t 之后的資訊給隱藏起來,這在訓練的時候有效,因為訓練的時候每次我們是將target資料完整輸入進decoder中地,預測時不需要,預測的時候我們只能得到前一時刻預測出的輸出,
那么具體怎么做呢?也很簡單:產生一個上三角矩陣,上三角的值全為0,把這個矩陣作用在每一個序列上,就可以達到我們的目的,
上面可能忘記說了,在Encoder中的Multi-Head Attention也是需要進行mask地,只不過Encoder中只需要padding mask即可,而Decoder中需要padding mask和sequence mask,OK除了這點mask不一樣以外,其他的部分均與Encoder一樣啦~
Add&Normalize也與Encoder中一樣,接下來就到了Decoder中第二個Multi-Head Attention,這個Multi-Head Attention又與Encoder中有一點點不一樣,
基于Encoder-Decoder 的Multi-Head Attention
Encoder中的Multi-Head Attention是基于Self-Attention地,Decoder中的第二個Multi-Head Attention就只是基于Attention,它的輸入Quer來自于Masked Multi-Head Attention的輸出,Keys和Values來自于Encoder中最后一層的輸出,
跟我一樣的牛角尖型選手可能又要發問啦,為啥Decoder中要搞兩個Multi-Head Attention呢?
我個人理解是第一個Masked Multi-Head Attention是為了得到之前已經預測輸出的資訊,相當于記錄當前時刻的輸入之間的資訊的意思,第二個Multi-Head Attention是為了通過當前輸入的資訊得到下一時刻的資訊,也就是輸出的資訊,是為了表示當前的輸入與經過encoder提取過的特征向量之間的關系來預測輸出,
經過了第二個Multi-Head Attention之后的Feed Forward Network與Encoder中一樣,然后就是輸出進入下一個decoder,如此經過6層decoder之后到達最后的輸出層,
2.4 Transformer的輸出
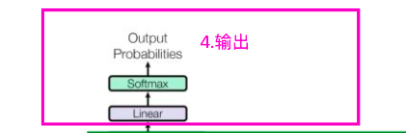
Output如圖中所示,首先經過一次線性變換,然后Softmax得到輸出的概率分布,然后通過詞典,輸出概率最大的對應的單詞作為我們的預測輸出,
2.5 結構總結
好啦,以上就是Transformer的全部結構原理啦,Transformer真的不愧是近幾年來最火的模型,很多細節都很巧妙,真的想要搞懂還是需要花點心思地,不知道看到這里,小伙伴們對于Transformer的結構有沒有清晰一些呢?
3.Transformer優缺點
Transformer雖然好,但它也不是萬能地,還是存在著一些不足之處,接下來就來介紹一下它的優缺點:
優點:
1.效果好
2.可以并行訓練,速度快
3.很好地解決了長距離依賴的問題
缺點:
1.完全基于self-attention,對于詞語位置之間的資訊有一定的丟失,雖然加入了positional encoding來解決這個問題,但也還存在著可以優化的地方,
參考
史上最小白之Transformer詳解
詳解Transformer (Attention Is All You Need)
碎碎念:Transformer的細枝末節
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/434540.html
標籤:AI