初學NLP,嘗試word2vec模型
第一次學這種,查閱了很多的博客,克服了些些問題,記錄一下第一次探索的歷程和相關代碼,文中借鑒多篇優秀的文章,連接會在文章中給出,
1.實驗樣本
在我最開始尋找實驗頭緒的時候,了解做這個需要實驗樣本,但是大部分博主沒有提供他的實驗樣本,所以我在網路上下載了《倚天屠龍記》的文本,
在下面這篇博客中我了解到可以運用文本進行分割自己生成詞的實驗樣本,以及如何運用jieba的包,
借鑒的博客1
運用jieba包切割詞的相關代碼:
import jieba.analyse
import codecs
f=codecs.open('D:/NLP/A.txt','r',encoding="utf8")
target = codecs.open("D:/NLP/B.txt", 'w',encoding="utf8")
print('open files')
line_num=1
line = f.readline()
#回圈遍歷每一行,并對這一行進行分詞操作
#如果下一行沒有內容的話,就會readline會回傳-1,則while -1就會跳出回圈
while line:
print('---- processing ', line_num, ' article----------------')
line_seg = " ".join(jieba.cut(line))
target.writelines(line_seg)
line_num = line_num + 1
line = f.readline()
#關閉兩個檔案流,并退出程式
f.close()
target.close()
exit()
將下載好的檔案A切割后保存在檔案B中,
前后對比

上面博客最后有一張詞語相似度的截圖,讓我也很想試試,但是作者沒有附加代碼,所以我有一段時間一直以為可以直接print出模型的相似度,直到后來我看到下面這篇文章
借鑒的博客2
但是,該博客發布日期有點早,現在的一些方法已經更新不能用了,所以我在大佬的代碼下做了一些些修改
model.similarity ---->model.wv.similarity
model.most_similar ---->model.wv.most_similar
再根據我的文本修改,形成的以下的代碼
from gensim.models import word2vec
import logging
# 主程式
logging.basicConfig(format='%(asctime)s:%(levelname)s: %(message)s', level=logging.INFO)
sentences = word2vec.Text8Corpus(u"D:/NLP/B.txt") # 加載語料
model = word2vec.Word2Vec(sentences, size=200) # 訓練skip-gram模型,默認window=5
print(model)
# 計算兩個詞的相似度/相關程度
try:
y1 = model.wv.similarity(u"張無忌", u"趙敏")
except KeyError:
y1 = 0
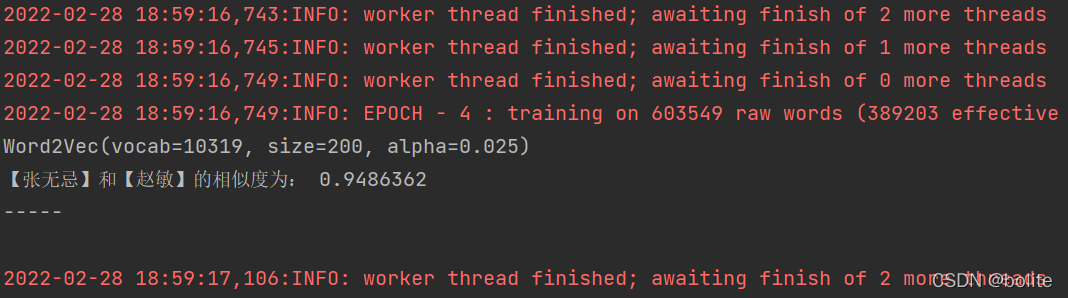
print(u"【張無忌】和【趙敏】的相似度為:", y1)
print("-----\n")
#
# 計算某個詞的相關詞串列
y2 = model.wv.most_similar(u"張無忌", topn=20) # 20個最相關的
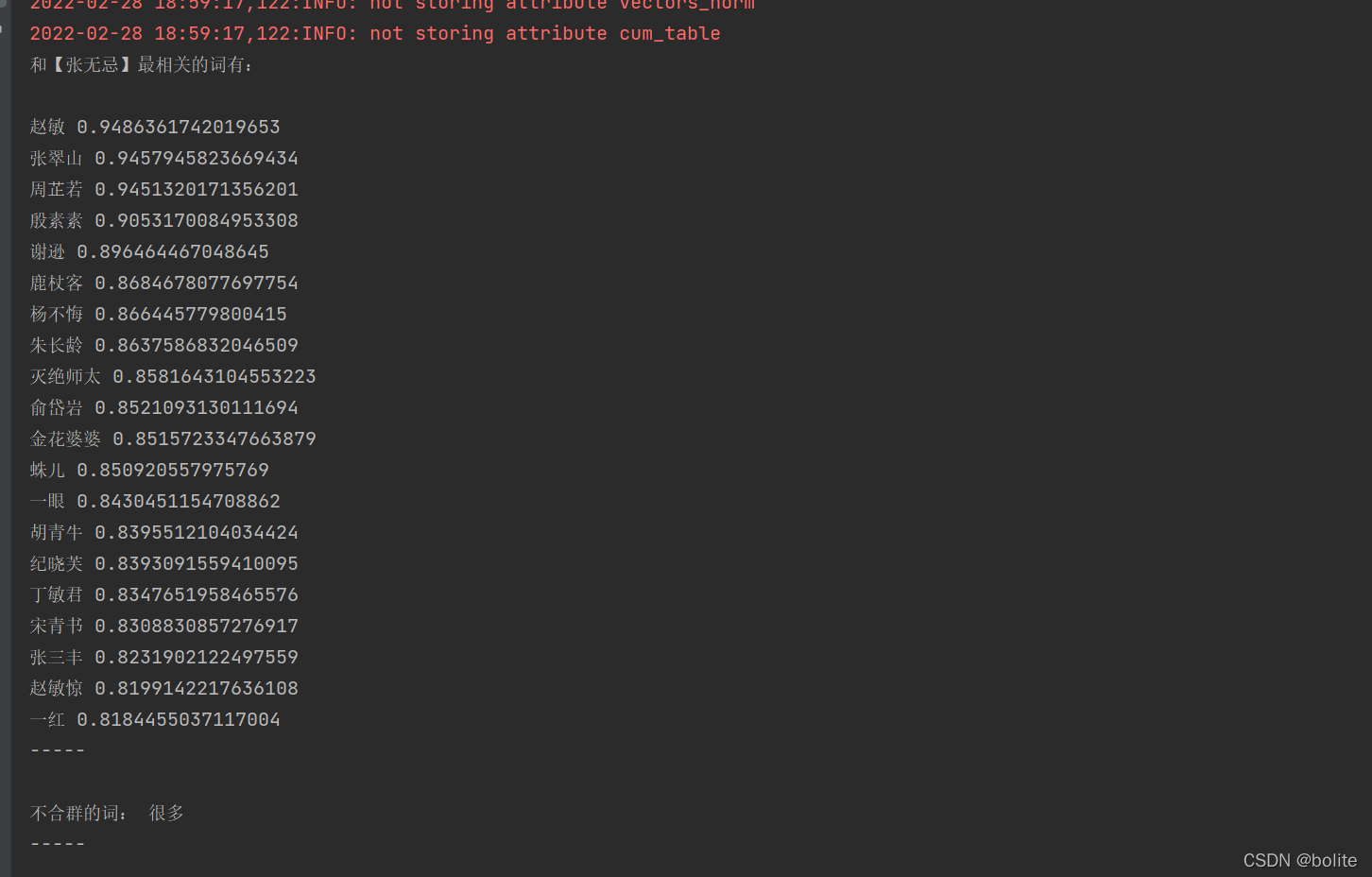
print(u"和【張無忌】最相關的詞有:\n")
for item in y2:
print(item[0], item[1])
print("-----\n")
# 尋找不合群的詞
y4 = model.wv.doesnt_match(u"很多 張無忌 趙敏 周芷若".split())
print(u"不合群的詞:", y4)
print("-----\n")
# 保存模型,以便重用
model.save(u"神雕俠侶.model")
最后在控制臺輸出,并保存了模型
第一次用自然語言處理的模型,記錄一下,也很感謝學習程序中看到的一些大佬的文章,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/434545.html
標籤:AI
上一篇:OpenCV學習(53)
下一篇:動手學深度學習——卷積層