文章目錄
- 1. 專案背景
- 1.1 巖石與油氣
- 1.2 日常的小細節
- 1.3 巖石的特性與石油的關系
- 1.4 現有的巖石識別系統
- 1.5 自我感想
- 2. 資料集選取
- 3. PaddleX 安裝
- 3.1 MobileNetV3
- 3.2 MobileNetV3 的其他平臺開源版本
- 3.3 主要內容
- 4. 配置超引數并訓練模型
- 4.1 訓練通用統計資訊
- 4.2 訓練日志欄位
- 5. 測驗模型效果
- 6. 可視化模型效果
- 7. 總結
1. 專案背景
考慮到自己學習的是人工智能和油氣的交叉學科,就想試試能不能從基本的巖石識別來做起,做一個巖石識別的小任務,
本次任務思路來源于AI達人創造營第二期,歡迎有興趣的小伙伴們一起參加飛槳的開發活動!
也算是實作了自己的一個小目標,(人果然是被逼出來的)
1.1 巖石與油氣
巖石的探測與識別是地質調查研究和礦產資源勘查的基礎作業,巖石的精準識別與分類對地質的探測與識別極為重要,一般可通過多種方式進行鑒定,例如重磁、測井、地震、遙感、電磁、地球化學、手標本及薄片分析方法等方法,

1.2 日常的小細節
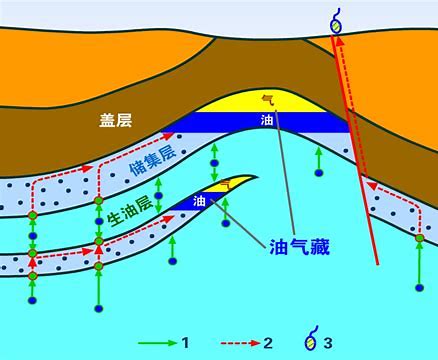
在日常生活中,當我們把少量的水灑到海綿上時,會發現水滲入海綿的孔隙中,且不會流出,與這種現象相似,石油和天然氣是儲存在巖石的孔隙和裂縫中的,儲存油氣的巖石叫儲層,
1.3 巖石的特性與石油的關系
巖石的種類多種多樣,已經被人們認識的有近百種,但能夠形成儲層的巖石必須具備一定的孔隙性和滲透性,孔隙性的好壞直接決定巖層儲存油氣的數量,滲透性的好壞控制了儲集層內所含油氣的產能,我國已發現的儲層型別是多種多樣的,主要有砂巖儲層、碳酸鹽巖儲層、火山巖儲層、結晶巖儲層和泥質巖儲層,
1.4 現有的巖石識別系統
自然資源部中國地質調查局“地質云”礦物、巖石識別系統,是人工智能(AI)技術在地質資訊化中的典型應用,基本原理是——采用人工智能方式,把已確認的礦物、巖石圖片存放于地質云服務器中,建立識別模型,通過計算機深度學習方式,對新采集的礦物、巖石影像進行識別,這個系統是地質專業初學者及非地質作業人員快速了解和識別礦物、巖石的輔助工具,
來源:https://www.cgs.gov.cn/xwl/sp/yangshi/201810/t20181019_469426.html
1.5 自我感想
看到上面這個系統的時候,我就想著能不能自己做一個,他行我也行!我也是大天朝的研究生!我也是學AI的!況且百度飛槳的套件花樣多,能夠玩出花來!
2. 資料集選取
這個資料集其實是百度公開的資料集修改來的
原始資料集是這個:
https://aistudio.baidu.com/aistudio/datasetdetail/85829#/
修改折騰后了好幾版,后來發現之前折騰的資料集被公開了還不能洗掉,,,私下想著,以后會不會有人看了看資料集,發現質量這么差會不會罵死我?
修改后的資料集3.0:
https://aistudio.baidu.com/aistudio/datasetdetail/129645
不過后期由于對資料集的認識不夠,自己私下寫了一些批量修改代碼,批量重命名的程式,把圖片都處理了一下,
這個資料集主要是集中基本的巖石類別,主要有“玄武巖”、“花崗巖”、“大理石”、“石英巖”、“煤”、“石灰石”、“砂巖” 共計7類,
每一個類別都是一個檔案夾,推薦使用PaddleX來對這個資料集進行自動劃分,賊方便有木有!
其中一個圖片是這樣子的:很黑吧!

當然黑了,這是煤!
#解壓資料集
!unzip -oq data/data129645/RockData.zip -d data/
#查看資料集目錄樹
!tree data/RockData/
# 引入依賴庫
import cv2
import os
import numpy as np
import matplotlib.pyplot as plt
#圖片抽樣
#讀取資料集中一個檔案夾的路徑
file_dir = '/home/aistudio/data/RockData/Coal/'
#設立串列存盤圖片名
filesum = []
#讀取圖片名
for root, dirs, files in os.walk(file_dir):
filesum.append(files)
filesum = filesum[0]
#列印圖片名看看效果符不符合預期
#print(filesum)
#定義畫布大小
plt.figure(figsize=(8, 8))
#回圈讀取圖片并顯示
for i in range(1,5):
plt.subplot(2,2,i)
plt.title(filesum[i])
image = file_dir+filesum[i]
#print(f">>>{image}")
plt.imshow(cv2.imread(image,1))
plt.tight_layout()
plt.show()
?

?
3. PaddleX 安裝
在這里我使用PaddleX套件,PaddleX套件在處理影像分類的問題上會大量節省開發效率,相關檔案如下:
PaddleX專案官網:
https://www.paddlepaddle.org.cn/paddle/paddlex
PaddleX Github地址:
https://github.com/PaddlePaddle/PaddleX
PaddleX API開發模式快速上手:
https://github.com/PaddlePaddle/PaddleX/blob/develop/docs/quick_start_API.md
PaddleX指標及日志:
https://github.com/PaddlePaddle/PaddleX/blob/develop/docs/appendix/metrics.md
#使用pip安裝方式安裝2.1.0版本:
pip install paddlex==2.1.0 -i https://mirror.baidu.com/pypi/simple
#在模型進行訓練時,我們需要劃分訓練集,驗證集和測驗集
#因此需要對如上資料進行劃分,直接使用paddlex命令即可將資料集隨機劃分成70%訓練集,20%驗證集和10%測驗集
#劃分好的資料集會額外生成labels.txt, train_list.txt, val_list.txt, test_list.txt四個檔案,之后可直接進行訓練,
paddlex --split_dataset --format ImageNet --dataset_dir /home/aistudio/data/RockData --val_value 0.2 --test_value 0.1
3.1 MobileNetV3
模型使用的是MobileNetV3-百度改,是百度基于蒸餾方法得到的MobileNetV3預訓練模型,模型結構與MobileNetV3一致,但精度更高,
3.2 MobileNetV3 的其他平臺開源版本
(1)PyTorch實作1:https://github.com/xiaolai-sqlai/mobilenetv3
(2)PyTorch實作2:https://github.com/kuan-wang/pytorch-mobilenet-v3
(3)PyTorch實作3:https://github.com/leaderj1001/MobileNetV3-Pytorch
(4)Caffe實作:https://github.com/jixing0415/caffe-mobilenet-v3
(5)TensorFLow實作:https://github.com/Bisonai/mobilenetv3-tensorflow
3.3 主要內容
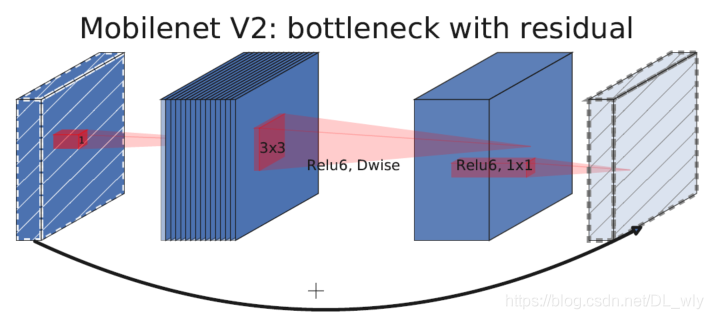
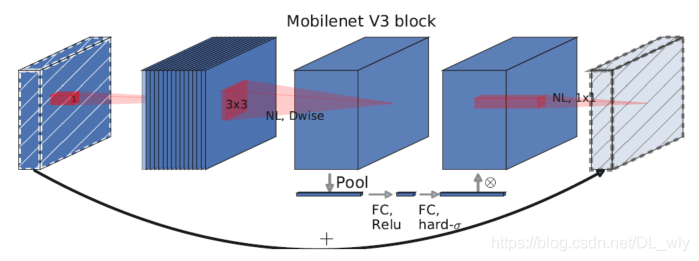
上面兩張圖是MobileNetV2和MobileNetV3的網路塊結構,
MobileNetV3綜合了以下三種模型的思想:
MobileNetV1的深度可分離卷積(depthwise separable convolutions)
MobileNetV2的具有線性瓶頸的逆殘差結構(the inverted residual with linear bottleneck)
MnasNet的基于squeeze and excitation結構的輕量級注意力模型
詳細的論文請參考:《Searching for MobileNetV3》
這里就不多贅述
4. 配置超引數并訓練模型
#在訓練和驗證程序中,資料的處理
from paddlex import transforms as T
train_transforms = T.Compose([
#圖片自由裁剪
T.RandomCrop(crop_size=224),
T.Normalize()])
eval_transforms = T.Compose([
#圖片大小自定義
T.ResizeByShort(short_size=256),
T.CenterCrop(crop_size=224),
T.Normalize()
])
import paddlex as pdx
#定義資料集,pdx.datasets.ImageNet表示讀取ImageNet格式的分類資料集:
train_dataset = pdx.datasets.ImageNet(
data_dir='/home/aistudio/data/RockData',
file_list='/home/aistudio/data/RockData/train_list.txt',
label_list='/home/aistudio/data/RockData/labels.txt',
transforms=train_transforms,
shuffle=True)
eval_dataset = pdx.datasets.ImageNet(
data_dir='/home/aistudio/data/RockData',
file_list='/home/aistudio/data/RockData/val_list.txt',
label_list='/home/aistudio/data/RockData/labels.txt',
transforms=eval_transforms)
2022-02-27 19:49:23 [INFO] Starting to read file list from dataset...
2022-02-27 19:49:23 [INFO] 1442 samples in file /home/aistudio/data/RockData/train_list.txt
2022-02-27 19:49:23 [INFO] Starting to read file list from dataset...
2022-02-27 19:49:23 [INFO] 408 samples in file /home/aistudio/data/RockData/val_list.txt
4.1 訓練通用統計資訊
以下欄位會在輸出時候顯示,具體含義如下:
| 欄位 | 示例 | 含義 |
|---|---|---|
| Epoch | Epoch=4/20 | [迭代輪數]所有訓練資料會被訓練20輪,當前處于第4輪 |
| Step | Step=62/66 | [迭代步數]所有訓練資料被訓練一輪所需要的迭代步數為66,當前處于第62步 |
| loss | loss=0.007226 | [損失函式值]參與當前迭代步數的訓練樣本的平均損失函式值loss,loss值越低,表明模型在訓練集上擬合的效果越好(如上日志中第1行表示第4個epoch的第62個Batch的loss值為0.007226) |
| lr | lr=0.008215 | [學習率]當前模型迭代程序中的學習率 |
| time_each_step | time_each_step=0.41s | [每步迭代時間]訓練程序計算得到的每步迭代平均用時 |
| eta | eta=0:9:44 | [剩余時間]模型訓練完成所需剩余時間預估為0小時9分鐘44秒 |
4.2 訓練日志欄位
分類任務的訓練日志除了通用統計資訊外,還包括acc1和acc5兩個特有欄位,
注: acck準確率是針對一張圖片進行計算的:把模型在各個類別上的預測得分按從高往低進行排序,取出前k個預測類別,若這k個預測類別包含了真值類,則認為該圖片分類正確,
上圖中第1行中的acc1表示參與當前迭代步數的訓練樣本的平均top1準確率,值越高代表模型越優;acc5表示參與當前迭代步數的訓練樣本的平均top5(若類別數n少于5,則為topn)準確率,值越高代表模型越優,
例如:
[TRAIN] Epoch=1/10, Step=20/22, loss=1.064334, acc1=0.671875, acc5=0.968750, lr=0.025000, time_each_step=0.15s, eta=0:0:31
代表:
Epoch=1/10[迭代輪數]所有訓練資料會被訓練10輪,當前處于第1輪;
Step=20/22[迭代步數]所有訓練資料被訓練一輪所需要的迭代步數為22,當前處于第20步;
loss=1.064334[損失函式值]loss值為1.064334;
acc1=0.671875 acc1表示整個驗證集的平均top1準確率為0.671875;
acc5=0.968750 acc5表示整個驗證集的平均top5準確率為0.968750;
lr=0.025000[學習率]當前模型迭代程序中的學習率;
time_each_step=0.15s[每步迭代時間]訓練程序計算得到的每步迭代平均用時;
eta=0:0:31[剩余時間]模型訓練完成所需剩余時間預估為0小時9分鐘44秒;
#使用百度基于蒸餾方法得到的MobileNetV3預訓練模型,模型結構與MobileNetV3一致,但精度更高,
num_classes = len(train_dataset.labels)
model = pdx.cls.MobileNetV3_small(num_classes=num_classes)
model.train(num_epochs=10,
train_dataset=train_dataset,
train_batch_size=64,
eval_dataset=eval_dataset,
lr_decay_epochs=[4, 6, 8],
save_dir='output/mobilenetv3_small',
#訓練的輸出保存在output/mobilenetv3_small
use_vdl=True)
#use_vdl=True表示可以啟動visualdl并查看可視化的指標變化情況,
2022-02-27 20:04:02 [INFO] Loading pretrained model from output/mobilenetv3_small/pretrain/MobileNetV3_small_x1_0_pretrained.pdparams
2022-02-27 20:04:03 [WARNING] [SKIP] Shape of pretrained params fc.weight doesn't match.(Pretrained: (1280, 1000), Actual: [1280, 7])
2022-02-27 20:04:03 [WARNING] [SKIP] Shape of pretrained params fc.bias doesn't match.(Pretrained: (1000,), Actual: [7])
......
poch=7, acc1=0.740327, acc5=0.979911 .
2022-02-27 20:04:42 [INFO] Current evaluated best model on eval_dataset is epoch_6, acc1=0.7425594925880432
2022-02-27 20:04:42 [INFO] Model saved in output/mobilenetv3_small/epoch_7.
2022-02-27 20:04:44 [INFO] [TRAIN] Epoch=8/10, Step=6/22, loss=0.568543, acc1=0.781250, acc5=0.984375, lr=0.000250, time_each_step=0.19s, eta=0:0:14
2022-02-27 20:04:45 [INFO] [TRAIN] Epoch=8/10, Step=16/22, loss=0.609234, acc1=0.796875, acc5=1.000000, lr=0.000250, time_each_step=0.15s, eta=0:0:10
2022-02-27 20:04:46 [INFO] [TRAIN] Epoch 8 finished, loss=0.5681447, acc1=0.79545456, acc5=0.99502844 .
2022-02-27 20:04:46 [INFO] Start to evaluate(total_samples=408, total_steps=7)...
2022-02-27 20:04:48 [INFO] [EVAL] Finished, Epoch=8, acc1=0.732143, acc5=0.982143 .
2022-02-27 20:04:48 [INFO] Current evaluated best model on eval_dataset is epoch_6, acc1=0.7425594925880432
2022-02-27 20:04:48 [INFO] Model saved in output/mobilenetv3_small/epoch_8.
2022-02-27 20:04:49 [INFO] [TRAIN] Epoch=9/10, Step=4/22, loss=0.511275, acc1=0.812500, acc5=1.000000, lr=0.000025, time_each_step=0.19s, eta=0:0:9
2022-02-27 20:04:50 [INFO] [TRAIN] Epoch=9/10, Step=14/22, loss=0.546328, acc1=0.796875, acc5=1.000000, lr=0.000025, time_each_step=0.15s, eta=0:0:6
2022-02-27 20:04:52 [INFO] [TRAIN] Epoch 9 finished, loss=0.5753054, acc1=0.8004261, acc5=0.9957386 .
2022-02-27 20:04:52 [INFO] Start to evaluate(total_samples=408, total_steps=7)...
2022-02-27 20:04:53 [INFO] [EVAL] Finished, Epoch=9, acc1=0.741071, acc5=0.982143 .
2022-02-27 20:04:53 [INFO] Current evaluated best model on eval_dataset is epoch_6, acc1=0.7425594925880432
2022-02-27 20:04:53 [INFO] Model saved in output/mobilenetv3_small/epoch_9.
2022-02-27 20:04:54 [INFO] [TRAIN] Epoch=10/10, Step=2/22, loss=0.833730, acc1=0.718750, acc5=1.000000, lr=0.000025, time_each_step=0.19s, eta=0:0:3
2022-02-27 20:04:56 [INFO] [TRAIN] Epoch=10/10, Step=12/22, loss=0.838117, acc1=0.750000, acc5=1.000000, lr=0.000025, time_each_step=0.15s, eta=0:0:1
2022-02-27 20:04:57 [INFO] [TRAIN] Epoch=10/10, Step=22/22, loss=0.532285, acc1=0.781250, acc5=1.000000, lr=0.000025, time_each_step=0.15s, eta=0:0:0
2022-02-27 20:04:57 [INFO] [TRAIN] Epoch 10 finished, loss=0.5774534, acc1=0.79616475, acc5=0.9957386 .
2022-02-27 20:04:58 [INFO] Start to evaluate(total_samples=408, total_steps=7)...
2022-02-27 20:04:59 [INFO] [EVAL] Finished, Epoch=10, acc1=0.745536, acc5=0.982143 .
2022-02-27 20:04:59 [INFO] Model saved in output/mobilenetv3_small/best_model.
2022-02-27 20:04:59 [INFO] Current evaluated best model on eval_dataset is epoch_10, acc1=0.7455357313156128
2022-02-27 20:04:59 [INFO] Model saved in output/mobilenetv3_small/epoch_10.
5. 測驗模型效果
#模型在訓練程序中,會每間隔一定輪數保存一次模型
#在驗證集上評估效果最好的一輪會保存在save_dir目錄下的best_model檔案夾
#加載模型,進行預測:
import paddlex as pdx
model = pdx.load_model('output/mobilenetv3_small/best_model')
result = model.predict('/home/aistudio/data/RockData/Coal/Coal271.jpg')
#設定預測結果為標題
plt.title(result[0]['category'])
#顯示預測的影像
plt.imshow(cv2.imread('/home/aistudio/data/RockData/Coal/Coal271.jpg',1))
#列印預測的結果
print("Predict Result: ", result)

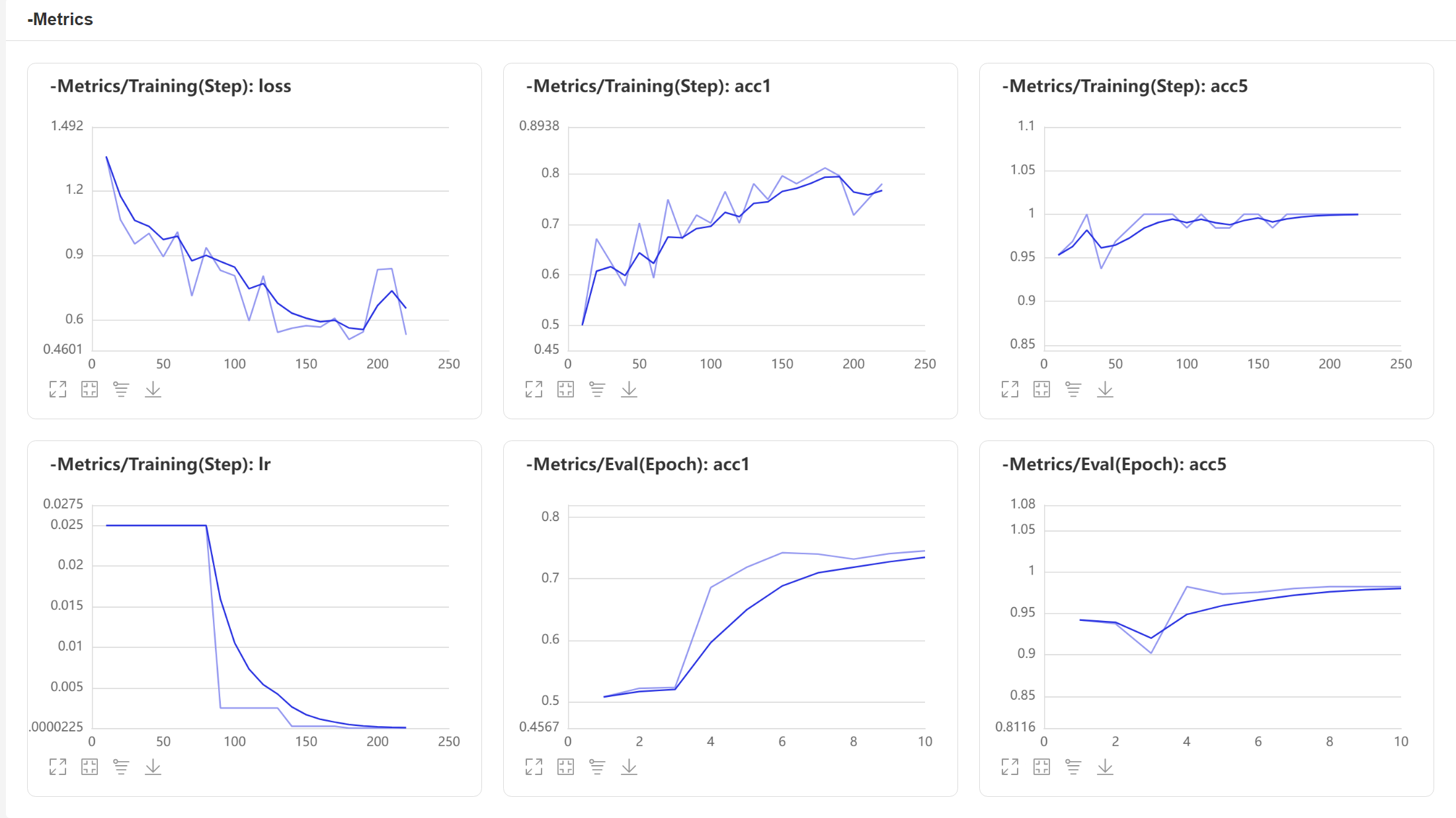
6. 可視化模型效果
點擊AIstudio左側工具列倒數第五個:【資料模型可視化】
設定logdir為【!cat output/mobilenetv3_small/vdl_log/】
點擊【啟動VisualDL服務】
7. 總結
少年的心總是喜歡折騰的,要不然這個世界的歷史就不會驚起波瀾,后期打算自己組網實作這個任務,更深入了解AI訓練程序中的點點滴滴,不過囿于現在的菜雞本菜的水平,還是一步一步踏踏實實多多訓練引數,多多看大佬們的專案來汲取養分,成長自己,
最重要的是,人真的是被逼出來的!不逼自己一把,你根本不會知道自己有多么厲害!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/435436.html
標籤:AI
下一篇:python 資料可視化01