SQL寫得好,作業隨便找
本篇博客講的是關于Spark SQL中對于列的操作,在SQL中對列的操作有起別名,轉化型別等在Spark SQL中同樣也支持,下面來看一看把
Spark withColumn()語法和用法
withColumn用于操作DataFrame上所有行或選定行的列值
withCplumn執行之后,會產生一個新的DataFrame
tips:
如果用withColumn同時更新多個列的情況下,可能會有性能問題甚至StackOverflowException為避免這種情況,可以把該dataFrame注冊為臨時表,注冊完之后進行SQL上面的更新,這樣不會有性能問題
創建元資料
import org.apache.spark.sql.{Row, SparkSession}
import org.apache.spark.sql.types.{StringType, StructType}
//創建元資料,里面有嵌套資料
//("Janmes","","Smith")是嵌套欄位
val data = Seq(Row(Row("James;","","Smith"),"36636","M","3000"), Row(Row("Michael","Rose",""),"40288","M","4000"), Row(Row("Robert","","Williams"),"42114","M","4000"), Row(Row("Maria","Anne","Jones"),"39192","F","4000"), Row(Row("Jen","Mary","Brown"),"","F","-1") )
//創建StructType物件,并且添加欄位名
val schema = new StructType()
.add("name",new StructType()
.add("firstname",StringType)
.add("middlename",StringType)
.add("lastname",StringType))
.add("dob",StringType)
.add("gender",StringType)
.add("salary",StringType)
//創建DataFrame
val df = spark.createDataFrame(spark.sparkContext.parallelize(data),schema)向DataFrame添加一個新列
要創建新列,請將所需的列名傳遞給withColumn()函式的第一個引數,第一個引數中的新的列名不能出現在原本的欄位名當中,如果出現,會更新該列的值,使用lit()函式可以將常量值加到DataFrame,
df.withColumns("Country",lit("USA")).show()
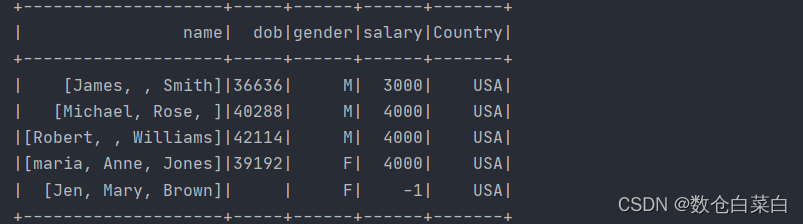
這個操作如果用SQL的話,就是
select name,dob,gender,salary,"USA" as Country from table_name
更改現有列的值
將現有的列名作為第一個引數,并將要分配的值作為第二個引數傳遞
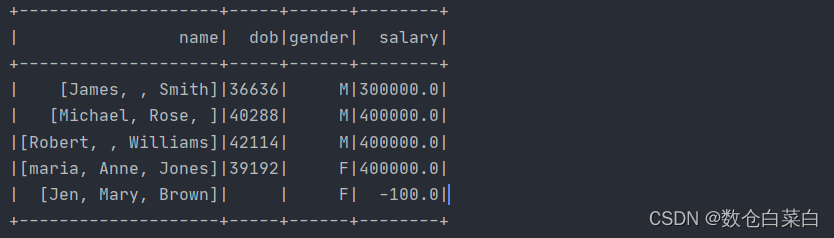
df.withColumn("salary",df("salary") * 100).show()
此代碼將“salary”欄位的值擴大一百倍,
換作SQL陳述句就是
select salary * 100 as salary from table_name
從現有列派生新列
要創建新列,第一個引數就是新的列名,第二個引數就是通過現有的列進行操作分配
df.withColumn("CopiedColumn",df("salary) * -1).show()
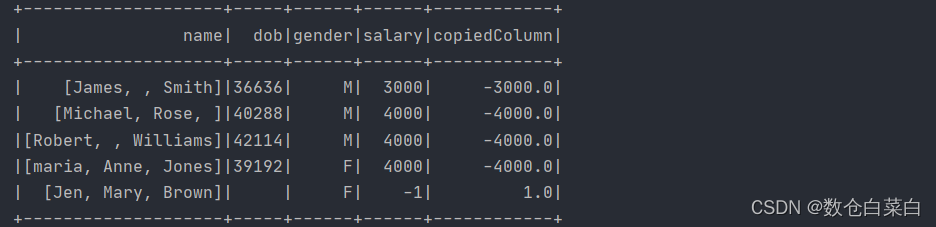
換做SQL陳述句就是
select salary,salary*-1 as "copieldColumn" from table_name
更改列資料型別
通過cast進行轉化型別
df.withColumn("salary",df("salary").cast("Integer")).show
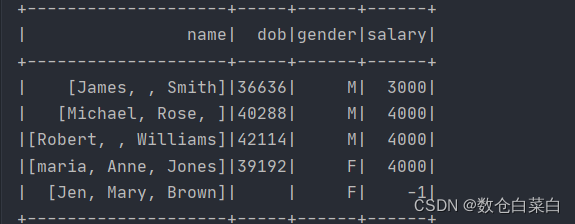
'換做SQL陳述句
select name,cast(salary as Int) as salary from table_name
添加,替換或更新多個列
使用withColumn增加多個列的時候,不建議使用該函式,因為可能會造成性能下降,不過可以創建成視圖,通過SQL陳述句進行操作
df.createOrReplaceTempView("Person")
sparkSession.sql("SELECT salary*100 as salary, salary*-1 as CopiedColumn,
'USA' as country FROM PERSON").show()將列拆分成多列
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Spark SQL")
val sparkSession = SparkSession.builder().config(sparkConf).getOrCreate()
import sparkSession.implicits._
//欄位名
val seq = Seq("name", "address")
//資料集合
val data = Seq(("Robert,Smith", "1 Main st,Newark,NJ,92537")
, ("maria,Garcia", "3456 Walnut st,newWark,NJ,94732"))
//創建dataFrame
val dataFrame = sparkSession.createDataFrame(data).toDF(seq: _*)
dataFrame.printSchema()關于將列拆分成多列,這個案例是這樣的,
首先是兩個欄位 name address
資料中name欄位為"Robert,Smith" address欄位為("1 Main st,Newark,NJ,92537")
現在的需求就是將元資料拆開,分裂成多個資料,同理元資料分裂了,欄位如果還是原來的兩個欄位名,就不行了,因此也需要增加新的欄位,
將name欄位按照逗號進行切分,address欄位根據逗號進行切分,
切分完之后就是
Robert Smith 1 Main st Newark NJ 92537
將拆分完后的資料轉換為dataFrame,并且創建欄位名
val value1 = dataFrame.map(f => {
//對name欄位進行切分
val value = f.getAs[String](0).split(",")
//對address欄位進行拆分
val strings = f.getAs[String](1).split(",")
(value(0), value(1), strings(0), strings(1), strings(2), strings(3)) })
//轉換為dataframe并且填充欄位名
val dataFrame1 = value1.toDF("First Name", "Last Name",
"Address Linel", "City", "State", "ZipCode")
dataFrame1.printSchema() dataFrame1.show()看一下轉化完成后的資料,

使用withColumnRenamed -重命名DataFrame列名
df.withColumnRenamed("dob","DateOfBirth")
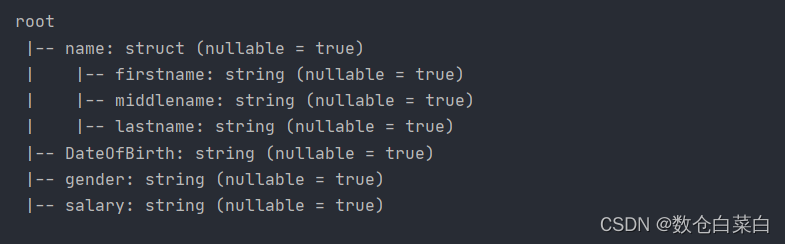
可以看到schema已經發生了變化,其實經過這種轉化函式之后,就會變成新的dataframe,原來的datafrmae并沒有發生改變,
使用withColumnRenamed--重命名多個列
val df2 = df.withColumnRenamed("dob","DateOfBirth") .withColumnRenamed("salary","salary_amount") df2.printSchema()重命名嵌套列
首先創建一個新的StructType,里面是新的嵌套列
val schema2 = new StructType()
.add("fname",StringType)
.add("middlename",StringType)
.add("lname",StringType)對嵌套欄位進行更改列名
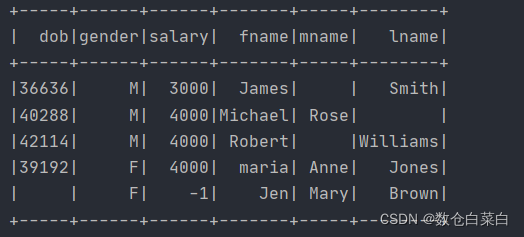
df.select(col("name").cast(schema2), col("dob"), col("gender"), col("salary")) .printSchema()
這個cast是轉化型別的,將嵌套欄位name轉換成schema這個StructType型別,
看一下結果把
總結:
為什么會寫這部分內容呢?
因為就在前天,本來是在做專案的,結果專案中關于StructType并不清楚怎么做,當時導包也總出現錯誤,現在學習了這一片段的知識,明天就可以開始更新電影分析的專案了,
明天的電影分析專案更加精彩
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/435462.html
標籤:其他
上一篇:HBase架構——詳解
下一篇:RabbitMQ搭建