文章目錄
- 01 引言
- 02 Hadoop概述
- 2.1 Hadoop定義
- 2.2 Hadoop優勢
- 2.3 Hadoop組成
- 2.3.1 HDFS
- 2.3.2 MapReduce
- 2.3.3 YARN
- 2.4 Hadoop作業方式
- 2.4.1 Hadoop的主從作業方式
- 2.4.2 Hadoop的守護行程
- 03 Hadoop的安裝
- 04 Hadoop 高可用
- 4.1 Hadoop高可用的解決方案
- 4.1.1 ZooKeeper quorum
- 4.1.2 ZKFC
- 05 Hadoop 任務調度器
- 5.1 FIFO 調度器
- 5.2 容量調度器(Capacity Scheduler)
- 5.3 公平調度器(Fair Scheduler)
- 06 分布式快取
- 6.1 分布式快取優點
- 6.2 分布式快取的使用
- 6.3 分布式快取的大小
- 07 Hadoop常用命令
- 7.1 常規選項
- 7.2 用戶命令
- 7.2.1 archive(創建一個 hadoop 檔案檔案)
- 7.2.2 distcp(遞回地拷貝檔案或目錄)
- 7.2.3 fs(運行一個常規的檔案系統客戶端)
- 7.2.4 fsck(運行 HDFS 檔案系統檢查工具)
- 7.2.5 jar(運行 jar 檔案)
- 7.2.6 job(與Map Reduce 作業互動和命令)
- 7.2.7 pipes(運行 pipes 作業)
- 7.2.8 version(列印版本資訊)
- 7.2.9 CLASSNAME(呼叫任何類)
- 7.3 管理命令
- 7.3.1 balancer(運行集群平衡工具)
- 7.3.2 daemonlog(獲取或設定每個守護行程的日志級別)
- 7.3.3 datanode(運行一個 HDFS 的 datanode)
- 7.3.4 dfsadmin(運行一個 HDFS 的 dfsadmin 客戶端)
- 7.3.5 jobtracker(運行 MapReduce job Tracker 節點)
- 7.3.6 namenode(運行 namenode)
- 7.3.7 secondarynamenode(運行 HDFS 的 secondary namenode)
- 7.3.8 tasktracker(運行 MapReduce 的 task Tracker 節點)
- 08 文末
01 引言
在學習Hadoop之前,我們看看典型的大資料平臺架構圖:
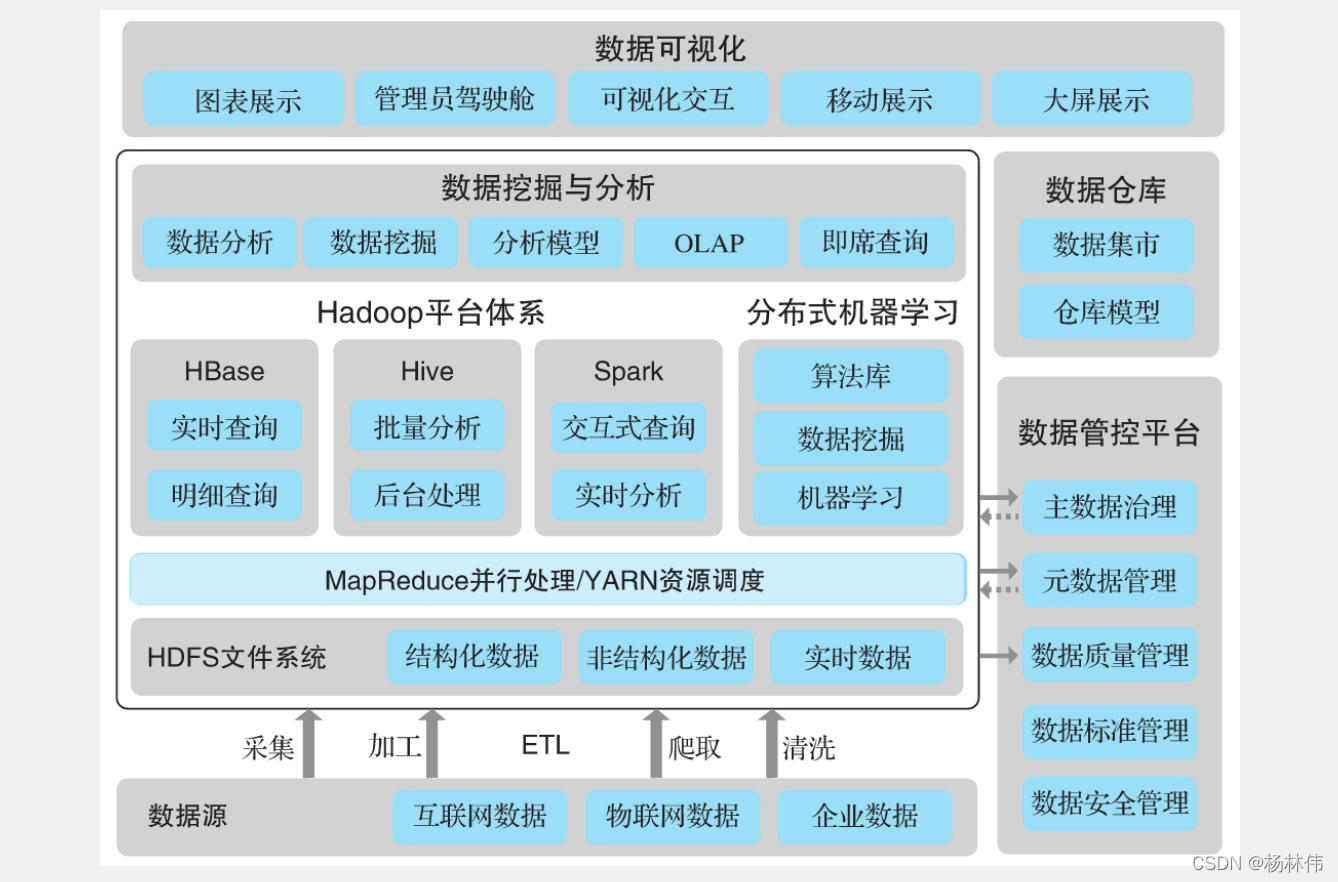
可以看到Hadoop在大資料平臺里處于一個技術核心的地位,本文來講解下,
02 Hadoop概述
2.1 Hadoop定義
Hadoop :是使用 Java 撰寫,允許分布在集群,使用簡單的編程模型的計算機大型資料集處理的Apache 的開源框架,
2.2 Hadoop優勢
Hadoop的優勢:
Hadoop是專為從單一服務器到上千臺機器擴展,每個機器都可以提供本地計算和存盤,Hadoop可以用單節點模式安裝,但是只有多節點集群才能發揮Hadoop的優勢,我們可以把集群擴展到上千個節點,而且擴展程序中不需要先停掉集群,
2.3 Hadoop組成
看看Hadoop由哪些組件組成:
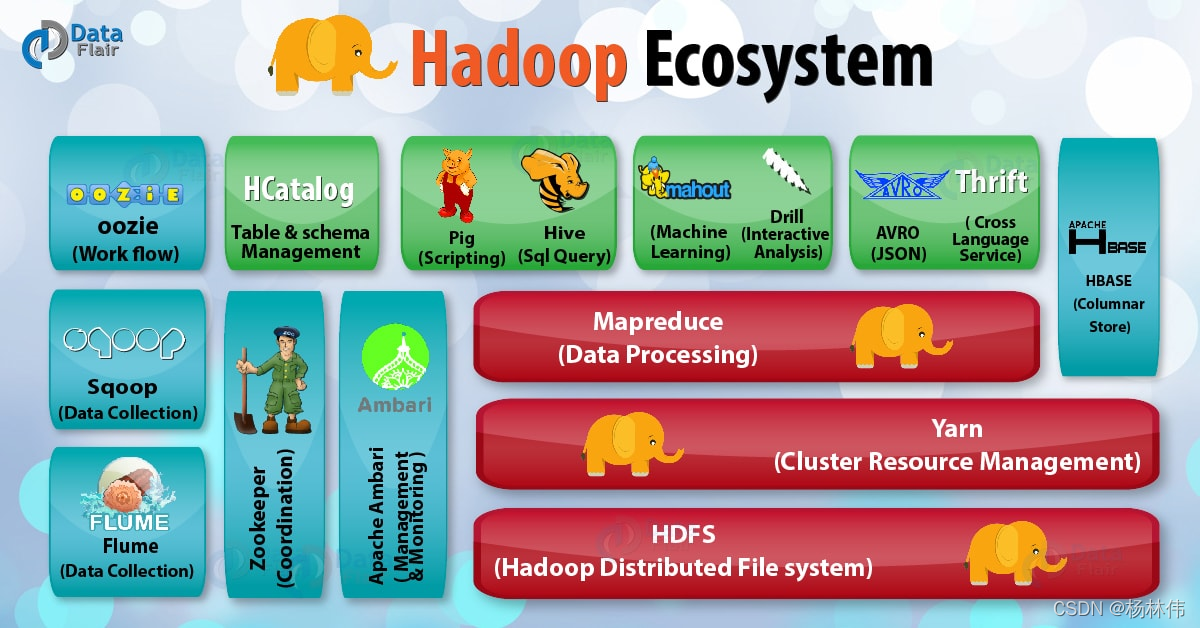
以上的各個組件都是屬于Hadoop的生態系統的,如果想入門大資料,都是需要學習,它們分別是:
- Hadoop HDFS(核心):
Hadoop分布式存盤系統; - Yarn(核心):
Hadoop 2.x版本開始才有的資源管理系統; - MapReduce(核心):并行處理框架;
- HBase:基于
HDFS的列式存盤資料庫,它是一種NoSQL資料庫,非常適用于存盤海量的稀疏的資料集; - Hive:
Apache Hive是一個資料倉庫基礎工具,它適用于處理結構化資料,它提供了簡單的 sql 查詢功能,可以將sql陳述句轉換為MapReduce任務進行運行; - Pig:它是一種高級腳本語言,利用它不需要開發
Java代碼就可以寫出復雜的資料處理程式; - Flume:它可以從不同資料源高效實時的收集海量日志資料;
- Sqoop:適用于在
Hadoop和關系資料庫之間抽取資料; - Oozie:這是一種
Java Web系統,用于Hadoop任務的調度,例如設定任務的執行時間和執行頻率等; - Zookeeper:用于管理配置資訊,命名空間,提供分布式同步和組服務;
- Mahout:可擴展的機器學習演算法庫,
其中:HDFS、MapReduce、YARN是核心,
2.3.1 HDFS
已有專欄專門講解,有興趣的同學可以參考《HDFS專欄》
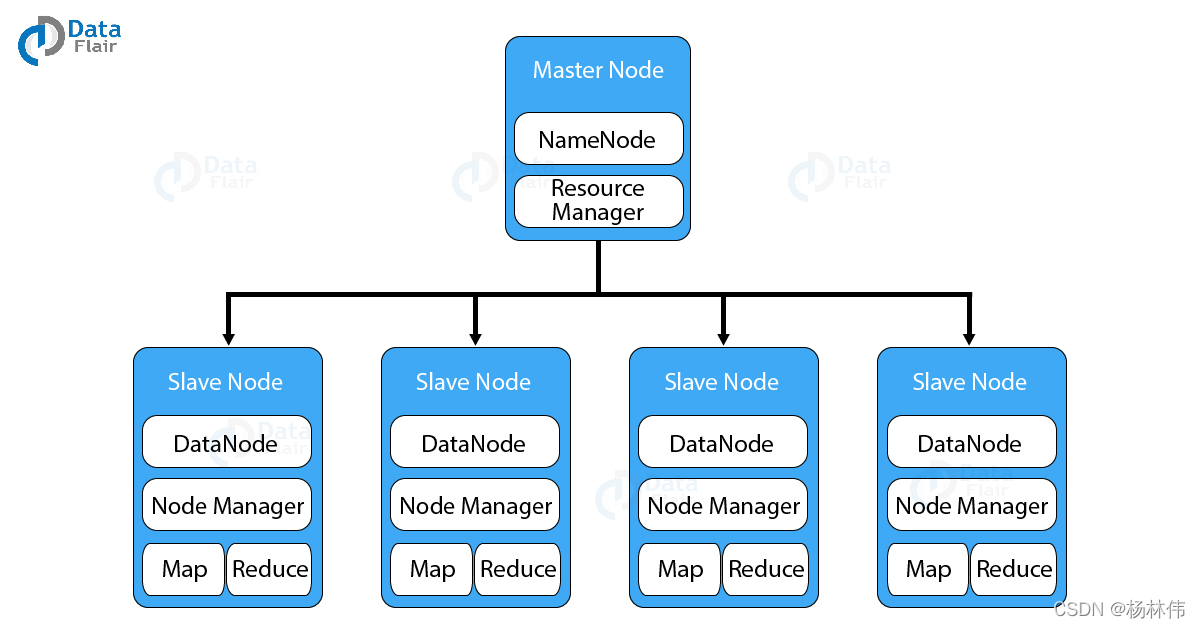
HDFS :即 Hadoop 分布式檔案系統(Hadoop Distribute File System),以分布式存盤的方式存盤資料,
HDFS 也是一種 Master-slave 架構,NameNode 是運行 master 節點的行程,它負責命名空間管理和檔案訪問控制,DataNode 是運行在 slave 節點的行程,它負責存盤實際的業務資料,如下圖:
2.3.2 MapReduce
已有專欄專門講解,有興趣的同學可以參考《MapReduce專欄》
Hadoop MapReduce 是一種編程模型,它是 Hadoop 最重要的組件之一,它用于計算海量資料,并把計算任務分割成許多在集群并行計算的獨立運行的 task,
MapReduce 是 Hadoop的核心,它會把計算任務移動到離資料最近的地方進行執行,因為移動大量資料是非常耗費資源的,
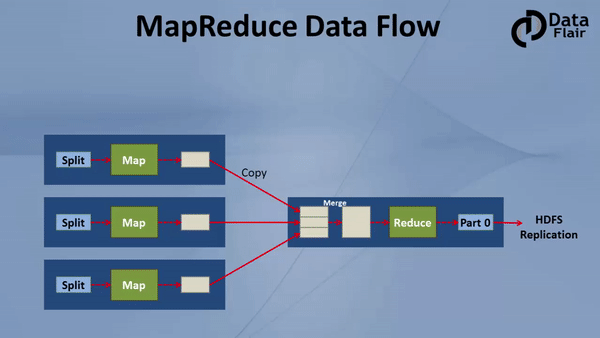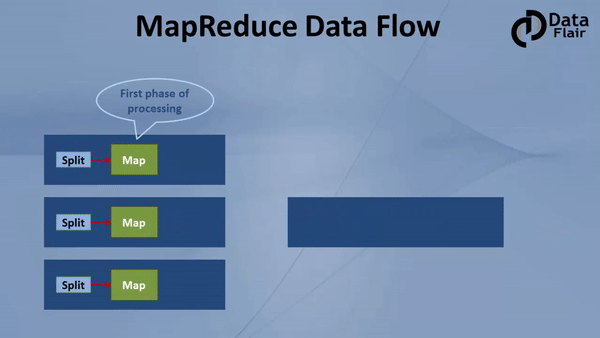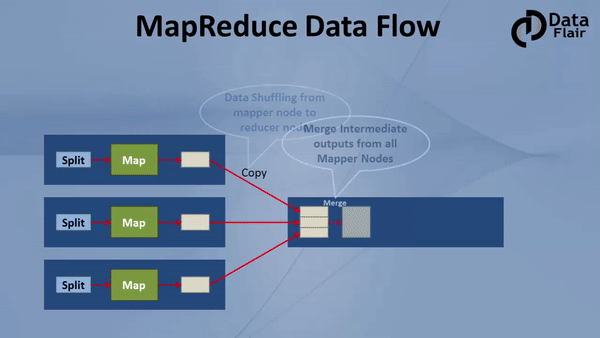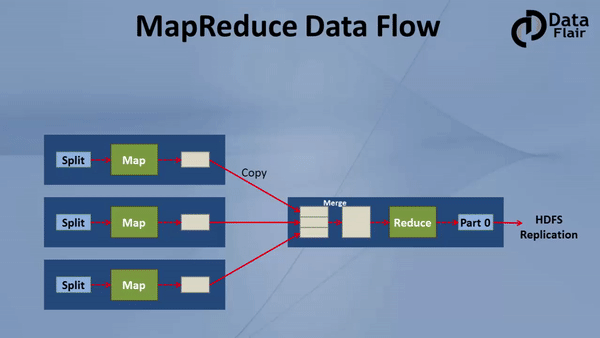
2.3.3 YARN
Yarn :是一個資源管理系統,其作用就是把資源管理和任務調度/監控功分割成不同的行程,Yarn 有一個全域的資源管理器叫 ResourceManager,每個 application 都有一個 ApplicationMaster 行程,一個 application 可能是一個單獨的 job 或者是 job 的 DAG (有向無環圖),
在 Yarn 內部有兩個守護行程:
- ResourceManager :負責給 application 分配資源
- NodeManager :負責監控容器使用資源情況,并把資源使用情況報告給 ResourceManager,這里所說的資源一般是指CPU、記憶體、磁盤、網路等,
ApplicationMaster 負責從 ResourceManager 申請資源,并與 NodeManager 一起對任務做持續監控作業,
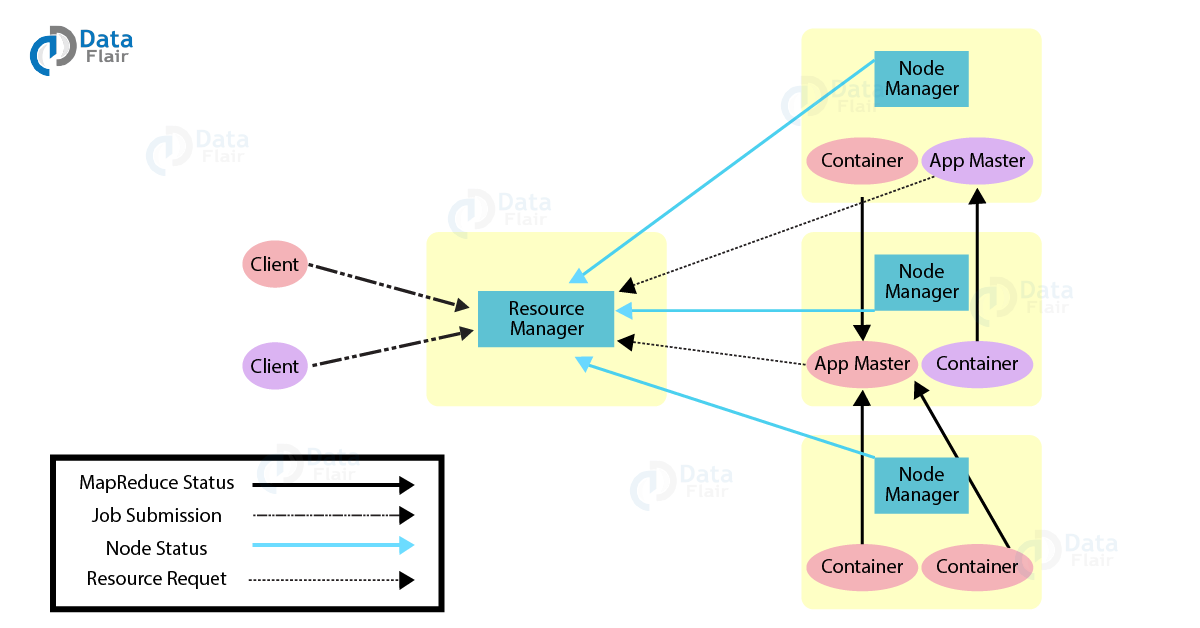
Yarn 具有下面這些特性:
- 多租戶:
Yarn允許在同樣的Hadoop資料集使用多種訪問引擎,這些訪問引擎可能是批處理,實時處理,迭代處理等; - 集群利用率:在資源自動分配的情況下,跟早期的
Hadoop版本相比,Yarn擁有更高的集群利用率; - 可擴展性:
Yarn可以根據實際需求擴展到幾千個節點,多個獨立的集群可以聯結成一個更大的集群; - 兼容性:
Hadoop 1.x的MapReduce應用程式可以不做任何改動運行在Yarn集群上面,
2.4 Hadoop作業方式
2.4.1 Hadoop的主從作業方式
Hadoop 以主從的方式作業(如下圖):
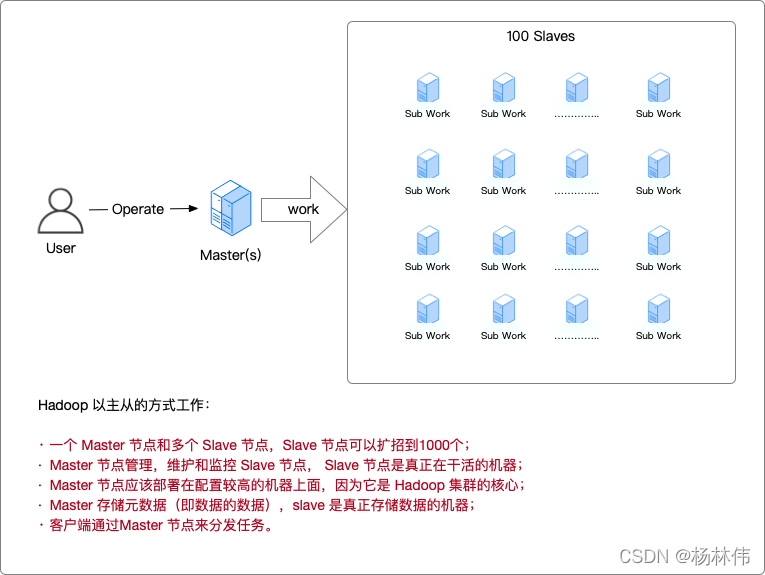
2.4.2 Hadoop的守護行程
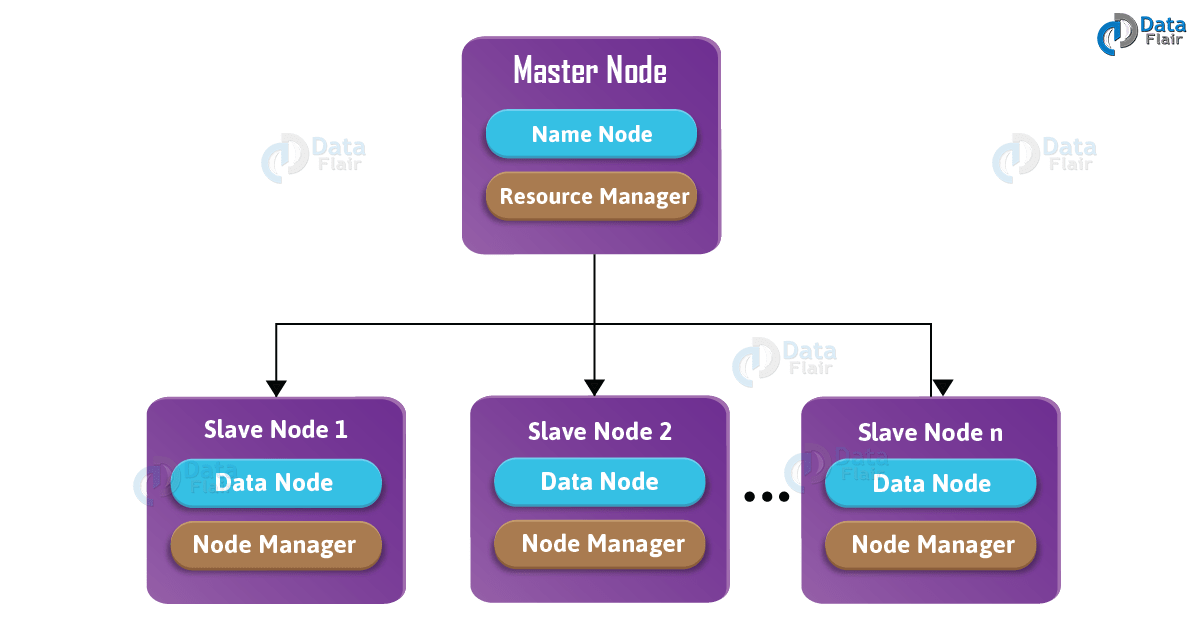
Hadoop 主要有4個守護行程:
- NameNode :它是HDFS運行在Master節點守護行程,
- DataNode:它是 HDFS 運行在Slave節點守護行程,
- ResourceManager:它是 Yarn 運行在 Master 節點守護行程,
- NodeManager:它是 Yarn 運行在 Slave 節點的守護行程,
除了這些,可能還會有 secondary NameNode,standby NameNode,Job HistoryServer 等行程,
03 Hadoop的安裝
之前寫過關于在Mac系統下安裝Hadoop,有興趣的同學可以參考《Mac下安裝Hadoop》
其它系統下不同版本的hadoop安裝參考:
- 《Hadoop Ubuntu 安裝 Hadoop 2.0(偽分布式)》
- 《Ubuntu 安裝 Hadoop 2.0(分布式)》
- 《Ubuntu 安裝 Hadoop 3.0(偽分布式)》
04 Hadoop 高可用
NameNode很容易面臨單點故障風險(SPOF):
- 在
Hadoop 2.0以前的版本,一旦NameNode節點掛了,整個集群就不可用了,而且需要借助輔助NameNode來手工干預重啟集群,這將延長集群的停機時間; Hadoop 2.0版本支持一個備用節點用于自動恢復NameNode故障;Hadoop 3.0則支持多個備用NameNode節點,這使得整個集群變得更加可靠,
為了解決SPOF故障,Hadoop必須制定高可用的解決方案,
4.1 Hadoop高可用的解決方案
Hadoop 實作自動故障切換需要用到下面的組件:
- ZooKeeper quorum
- ZKFailoverController 行程(ZKFC)
4.1.1 ZooKeeper quorum
ZooKeeper quorum 是一種集中式服務,主要為分布式應用提供協調、配置、命名空間等功能,它提供組服務和資料同步服務,它讓客戶端可以實時感知資料的更改,并跟蹤客戶端故障,HDFS故障自動切換的實作依賴下面兩個方面:
- 故障監測:
ZooKeeper維護一個和NameNode之間的會話,如果NameNode發生故障,該會話就會過期,會話一旦失效了,ZooKeeper將通知其他NameNode啟動故障切換行程, - 活動NameNode選舉:
ZooKeeper提供了一種活動節點選舉機制,只要活動的NameNode發生故障失效了,其他NameNode將從ZooKeeper獲取一個排它鎖,并把自身宣告為活動的NameNode,
4.1.2 ZKFC
ZKFC 是 ZooKeeper 的監控和管理 namenode 的一個客戶端,所以每個運行 namenode 的機器上都會有 ZKFC,
那ZKFC具體作用是什么?主要有以下3點:
- 狀態監控:
ZKFC會定期用ping命令監測活動的NameNode,如果NameNode不能及時回應ping命令,那么ZooKeeper就會判斷該活動的NameNode已經發生故障了, - ZooKeeper會話管理:如果
NameNode是正常的,那么它和ZooKeeper會保持一個會話,并持有一個znode鎖,如果會話失效了,那么該鎖將自動釋放, - 基于ZooKeeper的選舉:如果
NameNode是正常的,ZKFC 知道當前沒有其他節點持有znode鎖,那么ZKFC自己會試圖獲取該鎖,如果鎖獲取成功,那么它將贏得選舉,并負責故障切換作業,這里的故障切換程序其實和手動故障切換程序是類似的;先把之前活動的節點進行隔離,然后把ZKFC所在的機器變成活動的節點,
05 Hadoop 任務調度器
Hadoop 是一個可以高效處理大資料量的分布式集群,并且支持多用戶多任務執行,
在Hadoop早期版本是以一種比較簡單的方式對任務進行調度的,即FIFO調度器,它是按任務的提交順序來調度任務的,并且可以使用mapred.job.priority配置或者利用 JobClient的 setJobPriority()方法設定任務調度優先級,
目前Hadoop支持三種調度器:FIFO調度器、公平調度器(Fair Scheduler)、容量調度器(Capacity Scheduler),
5.1 FIFO 調度器
FIFO 調度器也就是平時所說的先進先出(First In First Out)調度器,可以簡單的將其理解為一個 Java 佇列,它的含義在于集群中同時只能有一個作業在運行,
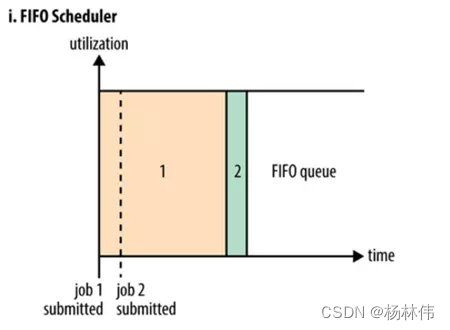
佇列形式會有什么問題?
FIFO調度器以集群資源獨占的方式來運行作業,這樣的好處是一個作業可以充分利用所有的集群資源,但是對于運行時間短,重要性高或者互動式查詢類的MR作業就要等待排在序列前的作業完成才能被執行,這也就導致了如果有一個非常大的Job在運行,那么后面的作業將會被阻塞,
因此,雖然單一的 FIFO調度實作簡單,但是對于很多實際的場景并不能滿足要求,這也就催生了 Capacity 調度器和 Fair調度器的出現,
5.2 容量調度器(Capacity Scheduler)
Capacity 調度器也就是日常說的容器調度器,可以將它理解成一個個的資源佇列,這個資源佇列是用戶自己去分配的:
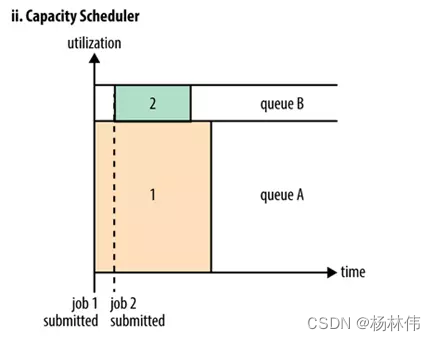
舉例:如上圖,因為作業所需要把整個集群分成了AB兩個佇列,A佇列下面還可以繼續分,比如將A佇列再分為1和2兩個子佇列,那么佇列的分配就可以參考下面的樹形結構:
|___A[60%]
|_____A.1[40%]
|_____A.2[60%]
|___B[40%]
上述的樹形結構可以理解為:
- A佇列占用整個資源的60%,B佇列占用整個資源的40%,
- A佇列里面又分了兩個子佇列,A.1占據40%,A.2占據60%,也就是說此時A.1和A.2分別占用A佇列的40%和60%的資源,
- 雖然此時已經具體分配了集群的資源,但是并不是說A提交了任務之后只能使用它被分配到的60%的資源,而B佇列的40%的資源就處于空閑,只要是其它佇列中的資源處于空閑狀態,那么有任務提交的佇列可以使用空閑佇列所分配到的資源,使用的多少是依據配來決定,
調度器特性特性:
- 層次化的佇列設計:這種層次化的佇列設計保證了子佇列可以使用父佇列設定的全部資源;
- 容量保證:佇列上都會設定一個資源的占比,這樣可以保證每個佇列都不會占用整個集群的資源;
- 安全:每個佇列又嚴格的訪問控制,
- 彈性分配:空閑的資源可以被分配給任何佇列,
- 多租戶租用:通過佇列的容量限制,多個用戶就可以共享同一個集群,同事保證每個佇列分配到自己的容量,提高利用率,
- 操作性:
Yarn支持動態修改調整容量、權限等的分配,可以在運行時直接修改, - 基于資源的調度:協調不同資源需求的應用程式,比如記憶體、
CPU、磁盤等等,
相關引數配置:
| 引數 | 描述 |
|---|---|
capacity | 佇列的資源容量(百分比) |
maximum-capacity | 佇列的資源使用上限(百分比) |
user-limit-factor | 每個用戶最多可使用的資源量(百分比) |
maximum-applications | 集群或者佇列中同時處于等待和運行狀態的應用程式數目上限 |
maximum-am-resource-percent | 集群中用于運行應用程式ApplicationMaster的資源比例上限 |
maximum-am-resource-percent | 設定適合自己的值 |
state | 佇列狀態可以為STOPPED或者RUNNING |
acl_submit_applications | 限定哪些Linux用戶/用戶組可向給定佇列中提交應用程式 |
acl_administer_queue | 為佇列指定一個管理員,該管理員可控制該佇列的所有應用程式,比如殺死任意一個應用程式等 |
5.3 公平調度器(Fair Scheduler)
Fair調度器也就是日常說的公平調度器,Fair調度器是一個佇列資源分配方式,在整個時間線上,所有的Job平均的獲取資源,默認情況下,Fair調度器只是對記憶體資源做公平的調度和分配,
當集群中只有一個任務在運行時,那么此任務會占用整個集群的資源,當其他的任務提交后,那些釋放的資源將會被分配給新的Job,所以每個任務最終都能獲取幾乎一樣多的資源,
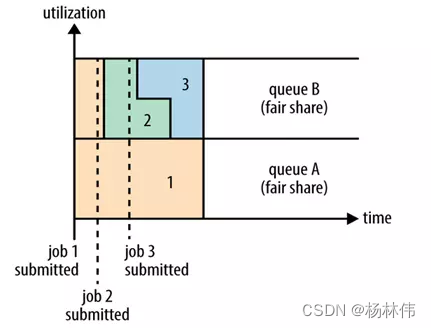
如上圖所示,例如有兩個用戶A和B,他們分別擁有一個佇列:
- 當A啟動一個
Job而B沒有任務提交時,A會獲得全部集群資源;- 當B啟動一個
Job后,A的任務會繼續運行,不過佇列A會慢慢釋放它的一些資源,一會兒之后兩個任務會各自獲得一半的集群資源,- 如果此時B再啟動第二個
Job并且其它任務也還在運行時,那么它將會和B佇列中的的第一個Job共享佇列B的資源,也就是佇列B的兩個Job會分別使用集群四分之一的資源,- 而佇列A的
Job仍然會使用集群一半的資源,結果就是集群的資源最終在兩個用戶之間平等的共享,
相關引數配置:
| 引數 | 描述 |
|---|---|
yarn.scheduler.fair.allocation.file | allocation”檔案是一個用來描述queue以及它們的屬性的組態檔 |
yarn.scheduler.fair.user-as-default-queue | 是否將與allocation有關的username作為默認的queue name |
yarn.scheduler.fair.preemption | 是否使用“preemption”(優先權,搶占),默認為fasle |
yarn.scheduler.fair.assignmultiple | 是在允許在一個心跳中,發送多個container分配資訊 |
yarn.scheduler.fair.max.assign | 如果assignmultuple為true,那么在一次心跳中,最多發送分配container的個數 |
yarn.scheduler.fair.locality.threshold.node | 一個float值,在0~1之間,表示在等待獲取滿足node-local條件的containers時,最多放棄不滿足node-local的container的機會次數,放棄的nodes個數為集群的大小的比例,默認值為-1.0表示不放棄任何調度的機會 |
yarn.scheduler.fair.locality.threashod.rack | 同上,滿足rack-local |
yarn.scheduler.fair.sizebaseweight | 是否根據application的大小(Job的個數)作為權重 |
06 分布式快取
分布式快取:是 Hadoop MapReduce 框架提供的一種資料快取機制,它可以快取只讀文本檔案,壓縮檔案,jar包等檔案,一旦對檔案執行快取操作,那么每個執行 map/reduce 任務的節點都可以使用該快取的檔案,
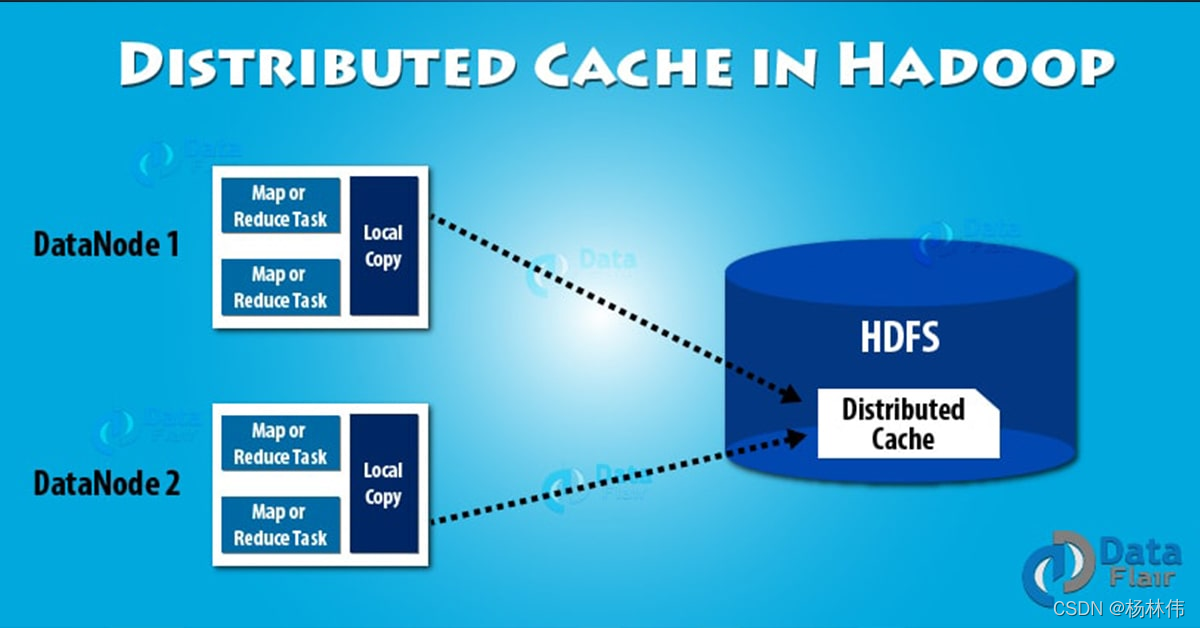
6.1 分布式快取優點
-
存盤復雜的資料:它分發了簡單、只讀的文本檔案和復雜型別的檔案,如jar包、壓縮包,這些壓縮包將在各個slave節點解壓,
-
資料一致性:Hadoop分布式快取追蹤了快取檔案的修改時間戳,然后當job在執行時,它也會通知這些檔案不能被修改,使用hash 演算法,快取引擎可以始終確定特定鍵值對在哪個節點上,所以,快取cluster只有一個狀態,它永遠不會是不一致的,
-
單點失敗:分布式快取作為一個跨越多個節點獨立運行的行程,因此單個節點失敗,不會導致整個快取失敗,
6.2 分布式快取的使用
舊版本的 DistributedCache已經被注解為過時,以下為 Hadoop-2.2.0以上的新API介面,
Job job = Job.getInstance(conf);
//將hdfs上的檔案加入分布式快取
job.addCacheFile(new URI("hdfs://url:port/filename#symlink"));
由于新版 API 中已經默認創建符號連接,所以不需要再呼叫 setSymlink(true)方法了,可以下面代碼來查看是否開啟了創建符號連接,
System.out.println(context.getSymlink());
之后在 map/reduce 函式中可以通過 context 來訪問到快取的檔案,一般是重寫 setup 方法來進行初始化:
@Override
protected void setup(Context context) throws IOException, InterruptedException {
super.setup(context);
if (context.getCacheFiles() != null && context.getCacheFiles().length > 0) {
String path = context.getLocalCacheFiles()[0].getName();
File itermOccurrenceMatrix = new File(path);
FileReader fileReader = new FileReader(itermOccurrenceMatrix);
BufferedReader bufferedReader = new BufferedReader(fileReader);
String s;
while ((s = bufferedReader.readLine()) != null) {
//TODO:讀取每行內容進行相關的操作
}
bufferedReader.close();
fileReader.close();
}
}
得到的path為本地檔案系統上的路徑,
這里的
getLocalCacheFiles方法也被注解為過時了,只能使用context.getCacheFiles方法,和getLocalCacheFiles不同的是,getCacheFiles得到的路徑是HDFS上的檔案路徑,如果使用這個方法,那么程式中讀取的就不再試快取在各個節點上的資料了,相當于共同訪問HDFS上的同一個檔案 ,可以直接通過符號連接來跳過getLocalCacheFiles獲得本地的檔案,
6.3 分布式快取的大小
可以在檔案
mapred-site.xml中設定,默認為10GB,
注意事項:
- 需要分發的檔案必須是存盤在
HDFS上了; - 檔案只讀;
- 不快取太大的檔案,執行
task之前對檔案進行分發,影響task的啟動速度,
07 Hadoop常用命令
所有的 Hadoop 命令均由 bin/hadoop 腳本引發,不指定引數運行hadoop腳本會列印所有命令的描述,
用法:
hadoop [--config confdir] [COMMAND] [GENERIC_OPTIONS] [COMMAND_OPTIONS]
Hadoop 有一個選項決議框架用于決議一般的選項和運行類,
| 命令選項 | 描述 |
|---|---|
--config confdir | 覆寫預設配置目錄,預設是${HADOOP_HOME}/conf, |
GENERIC_OPTIONS | 多個命令都支持的通用選項, |
COMMAND 命令選項 | 各種各樣的命令和它們的選項會在下面提到,這些命令被分為用戶命令和管理命令兩組, |
7.1 常規選項
| GENERIC_OPTION | 描述 |
|---|---|
| -conf | 指定應用程式的組態檔, |
| -D | 為指定property指定值value, |
| -fs | 指定namenode, |
| -jt | 指定job tracker,只適用于job, |
| -files <逗號分隔的檔案串列> | 指定要拷貝到map reduce集群的檔案的逗號分隔的串列, 只適用于job, |
| -libjars <逗號分隔的jar串列> | 指定要包含到classpath中的jar檔案的逗號分隔的串列, 只適用于job, |
| -archives <逗號分隔的archive串列> | 指定要被解壓到計算節點上的檔案檔案的逗號分割的串列, 只適用于job, |
7.2 用戶命令
7.2.1 archive(創建一個 hadoop 檔案檔案)
用法:
hadoop archive -archiveName NAME <src>* <dest>
| 命令選項 | 描述 |
|---|---|
| -archiveName NAME | 要創建的檔案的名字 |
| src | 檔案系統的路徑名,和通常含正則表達的一樣 |
| dest | 保存檔案檔案的目標目錄 |
7.2.2 distcp(遞回地拷貝檔案或目錄)
用法:
hadoop distcp <srcurl> <desturl>
| 命令選項 | 描述 |
|---|---|
| srcurl | 源Url |
| desturl | 目標Url |
7.2.3 fs(運行一個常規的檔案系統客戶端)
用法:
hadoop fs [GENERIC_OPTIONS] [COMMAND_OPTIONS]
| 命令選項 | 描述 |
|---|---|
| srcurl | 源Url |
| desturl | 目標Url |
具體的 GENERIC_OPTIONS 可以參考官方檔案
各種命令選項可以參考HDFS Shell指南,
7.2.4 fsck(運行 HDFS 檔案系統檢查工具)
用法:
hadoop fsck [GENERIC_OPTIONS] <path> [-move | -delete | -openforwrite] [-files [-blocks [-locations | -racks]]]
| 命令選項 | 描述 |
|---|---|
| path | 檢查的起始目錄 |
| -move | 移動受損檔案到/lost+found |
| -delete | 洗掉受損檔案 |
| -openforwrite | 列印出寫打開的檔案 |
| -files | 列印出正被檢查的檔案 |
| -blocks | 列印出塊資訊報告 |
| -locations | 列印出每個塊的位置資訊 |
| -racks | 列印出data-node的網路拓撲結構 |
7.2.5 jar(運行 jar 檔案)
用法:
hadoop jar <jar> [mainClass] args...
streaming 作業是通過這個命令執行的,參考Streaming examples中的例子,
Word count 例子也是通過jar命令運行的,參考Wordcount example,
7.2.6 job(與Map Reduce 作業互動和命令)
用法:
hadoop job [GENERIC_OPTIONS] [-submit <job-file>] | [-status <job-id>] | [-counter <job-id> <group-name> <counter-name>] | [-kill <job-id>] | [-events <job-id> <from-event-#> <#-of-events>] | [-history [all] <jobOutputDir>] | [-list [all]] | [-kill-task <task-id>] | [-fail-task <task-id>]
| 命令選項 | 描述 |
|---|---|
| -submit | 提交作業 |
| -status | 列印map和reduce完成百分比和所有計數器 |
| -counter | 列印計數器的值 |
| -kill | 殺死指定作業 |
| -events <#-of-events> | 列印給定范圍內jobtracker接收到的事件細節 |
| -history [all] -history | 列印作業的細節、失敗及被殺死原因的細節,更多的關于一個作業的細節比如成功的任務,做過的任務嘗試等資訊可以通過指定[all]選項查看 |
| -list [all] | -list all顯示所有作業,-list只顯示將要完成的作業 |
| -kill-task | 殺死任務,被殺死的任務不會不利于失敗嘗試, |
| -fail-task | 使任務失敗,被失敗的任務會對失敗嘗試不利, |
7.2.7 pipes(運行 pipes 作業)
用法:
hadoop pipes [-conf <path>] [-jobconf <key=value>, <key=value>, ...] [-input <path>] [-output <path>] [-jar <jar file>] [-inputformat <class>] [-map <class>] [-partitioner <class>] [-reduce <class>] [-writer <class>] [-program <executable>] [-reduces <num>]
| 命令選項 | 描述 |
|---|---|
| -conf | 作業的配置 |
| -jobconf | 增加/覆寫作業的配置項 |
| -input | 輸入目錄 |
| -output | 輸出目錄 |
| -jar | Jar檔案名 |
| -inputformat | InputFormat類 |
| -map | Java Map類 |
| -partitioner | Java Partitioner |
| -reduce | Java Reduce類 |
| -writer | Java RecordWriter |
| -program | 可執行程式的URI |
| -reduces | reduce個數 |
7.2.8 version(列印版本資訊)
用法:
hadoop version
7.2.9 CLASSNAME(呼叫任何類)
用法:
hadoop CLASSNAME
運行名字為 CLASSNAME的類,
7.3 管理命令
hadoop 集群管理員常用的命令,
7.3.1 balancer(運行集群平衡工具)
用法:
hadoop balancer [-threshold <threshold>]
| 命令選項 | 描述 |
|---|---|
| -threshold | 磁盤容量的百分比,這會覆寫預設的閥值, |
管理員可以簡單的按 Ctrl+C 來停止平衡程序,參考 Rebalancer 了解更多,
7.3.2 daemonlog(獲取或設定每個守護行程的日志級別)
用法:
hadoop daemonlog -getlevel <host:port> <name>
hadoop daemonlog -setlevel <host:port> <name> <level>
| 命令選項 | 描述 |
|---|---|
| -getlevel | 列印運行在的守護行程的日志級別,這個命令內部會連接 http:///logLevel?log= |
| -setlevel | 設定運行在的守護行程的日志級別,這個命令內部會連接 http:///logLevel?log= |
7.3.3 datanode(運行一個 HDFS 的 datanode)
用法:
hadoop datanode [-rollback]
| 命令選項 | 描述 |
|---|---|
| -rollback | 將datanode回滾到前一個版本,這需要在停止datanode,分發老的hadoop版本之后使用, |
7.3.4 dfsadmin(運行一個 HDFS 的 dfsadmin 客戶端)
用法:
hadoop dfsadmin [GENERIC_OPTIONS] [-report] [-safemode enter | leave | get | wait] [-refreshNodes] [-finalizeUpgrade] [-upgradeProgress status | details | force] [-metasave filename] [-setQuota <quota> <dirname>...<dirname>] [-clrQuota <dirname>...<dirname>] [-help [cmd]]
| 命令選項 | 描述 |
|---|---|
| -report | 報告檔案系統的基本資訊和統計資訊 |
| -safemode [enter / leave / get / wait] | 安全模式維護命令,安全模式是Namenode的一個狀態,這種狀態下,Namenode 1. 不接受對名字空間的更改(只讀)2. 不復制或洗掉塊Namenode會在啟動時自動進入安全模式,當配置的塊最小百分比數滿足最小的副本數條件時,會自動離開安全模式,安全模式可以手動進入,但是這樣的話也必須手動關閉安全模式, |
| -refreshNodes | 重新讀取hosts和exclude檔案,更新允許連到Namenode的或那些需要退出或入編的Datanode的集合, |
| -finalizeUpgrade | 終結HDFS的升級操作,Datanode洗掉前一個版本的作業目錄,之后Namenode也這樣做,這個操作完結整個升級程序, |
| -upgradeProgress [status / details / force] | 請求當前系統的升級狀態,狀態的細節,或者強制升級操作進行, |
| -metasave filename | 保存Namenode的主要資料結構到hadoop.log.dir屬性指定的目錄下的檔案,對于下面的每一項,中都會一行內容與之對應1. Namenode收到的Datanode的心跳信號2. 等待被復制的塊3. 正在被復制的塊4. 等待被洗掉的塊 |
| -setQuota … | 為每個目錄 設定配額,目錄配額是一個長整型整數,強制限定了目錄樹下的名字個數,命令會在這個目錄上作業良好,以下情況會報錯:1. N不是一個正整數,或者2. 用戶不是管理員,或者3. 這個目錄不存在或是檔案,或者4. 目錄會馬上超出新設定的配額, |
| -clrQuota … | 為每一個目錄清除配額設定,命令會在這個目錄上作業良好,以下情況會報錯:1. 這個目錄不存在或是檔案,或者2. 用戶不是管理員,如果目錄原來沒有配額不會報錯, |
| -help [cmd] | 顯示給定命令的幫助資訊,如果沒有給定命令,則顯示所有命令的幫助資訊, |
7.3.5 jobtracker(運行 MapReduce job Tracker 節點)
用法:
hadoop jobtracker
7.3.6 namenode(運行 namenode)
用法:
hadoop namenode [-format] | [-upgrade] | [-rollback] | [-finalize] | [-importCheckpoint]
| 命令選項 | 描述 |
|---|---|
| -format | 格式化namenode,它啟動namenode,格式化namenode,之后關閉namenode, |
| -upgrade | 分發新版本的hadoop后,namenode應以upgrade選項啟動, |
| -rollback | 將namenode回滾到前一版本,這個選項要在停止集群,分發老的hadoop版本后使用, |
| -finalize | finalize會洗掉檔案系統的前一狀態,最近的升級會被持久化,rollback選項將再不可用,升級終結操作之后,它會停掉namenode, |
| -importCheckpoint | 從檢查點目錄裝載鏡像并保存到當前檢查點目錄,檢查點目錄由fs.checkpoint.dir指定, |
7.3.7 secondarynamenode(運行 HDFS 的 secondary namenode)
用法:
hadoop secondarynamenode [-checkpoint [force]] | [-geteditsize]
| 命令選項 | 描述 |
|---|---|
| -checkpoint [force] | 如果EditLog的大小 >= fs.checkpoint.size,啟動Secondary namenode的檢查點程序, 如果使用了-force,將不考慮EditLog的大小, |
| -geteditsize | 列印EditLog大小, |
7.3.8 tasktracker(運行 MapReduce 的 task Tracker 節點)
用法:
hadoop tasktracker
08 文末
參考文獻:
- https://www.hadoopdoc.com/hadoop/hadoop-intro
本文主要講了Hadoop的入門知識,謝謝大家的閱讀,本文完!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/435470.html
標籤:其他