目錄
- 1. 正文
- 1.1. 任務劃分
- 1.2. 任務程式
- 2. 相關
1. 正文
1.1. 任務劃分
使用高通量計算第一步就是要針對密集運算任務做任務劃分,將一個海量的、耗時的、耗資源的任務劃分成合適粒度的小任務,需要綜合考慮資源、資料等多方面因素,HTCondor并不參與這方面的作業,任務劃分需要用戶自己實作,
默認情況下,HTCondor會把一個CPU核心當成一個計算資源,最理想的情況,就是計算集群網路內所有的集群主機都是同樣的配置,資料也是易于劃分的,那么可以按照計算機集群內CPU的總核心數,對資料量等分劃分,這樣,因為同樣的資料量同樣的計算機資源,進行分布式計算時理論上會同時完成,也就達到了負載均衡,
這里就準備了這樣的一個任務例子,假設任務已經劃分好,已經放到同一個目錄中: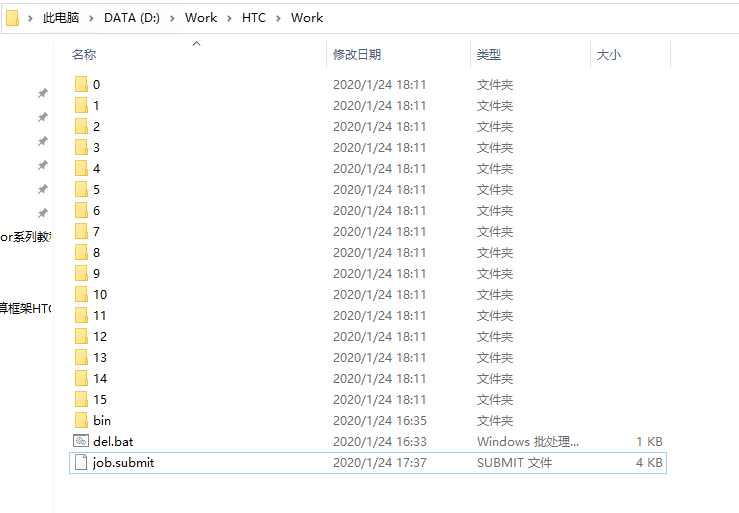
0,1,2,..., 15就是劃分好的16份資料,每個目錄中都存放了資料,所謂計算任務,就是輸入一個資料,處理后形成新的資料,所以,每個檔案夾都放入了一個input.txt檔案,作為計算任務的輸入: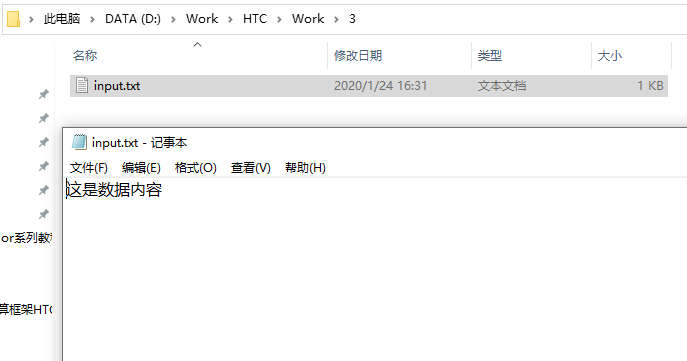
實體目的很簡單,就是將這些劃分好的任務提交到HTCondor,讓HTCondor的計算資源分別處理這些資料,并將新的資料回傳來,
1.2. 任務程式
既然要進行計算任務,那么不可或缺的就是運行的任務程式了,說到底分布式計算的基礎還是單機運算,必須要保證發送的每個任務在單機下就能正確運行,才能談任務調度的問題,
在這里我用的是一個C/C++的任務程式:
#include <iostream>
#include <fstream>
#include <string>
#include <time.h>
using namespace std;
int main()
{
fprintf(stdout, "開始運行\n");
//延時10S
fprintf(stdout, "延時10S\n");
time_t first = time(NULL);
double diff = 0;
while (diff<10)
{
time_t second = time(NULL);
diff = difftime(second, first); //計時
}
ifstream infile("input.txt");
if (!infile)
{
fprintf(stderr, "無法讀取檔案\n");
return 1;
}
string line;
getline(infile, line);
ofstream outfile("output.dat");
if (!outfile)
{
fprintf(stderr, "無法寫出檔案\n");
return 1;
}
outfile << "輸出內容:\n";
outfile << line;
fprintf(stdout, "運行完成\n");
return 0;
}
可以看到這個程式特別簡單,就是延時10秒后,讀取input.txt的內容,寫出到output.dat中,延時10秒是為了方便顯示運行狀態,其實不必非要C/C++的程式,只要是能夠運行的可執行程式即可,條件是每臺機器要有對應的運行環境,否則發送過去的任務會因為無法運行而掛起,
將這個程式編譯的可執行程式放到bin目錄中,保證在單機的情況下,能夠正常運行,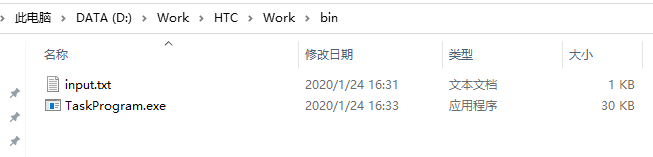
在下一章中,將會介紹如何通過HTCondor框架運行這個實體,
2. 相關
代碼和資料地址
上一篇
目錄
下一篇
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/43557.html
標籤:其他