目錄
- BaseEstimator
- get_params
- set_params
- ClassifierMixin
- RegressorMixin
- 檢查傳入的物件
- 檢查樣本數和權重系數
- 實作$R^2$的計算細節
- TransformerMixin
- 補充
sklearn專案可以看成一棵大樹,各種estimator是果實,而支撐這些估計器的主干,是為數不多的幾個基類,常見的幾個類有BaseEstimator、BaseSGD、ClassifierMixin、RegressorMixin,等等,
官方檔案的API參考頁面列出了主要的API介面,我們看下Base類

本期我們只研究BaseEstimator、ClassifierMixin、RegressorMixin、TransformerMixin,BaseSGD是一個比較大的話題,需要單獨開一期來仔細研究,
BaseEstimator
最底層的就是BaseEstimator類,主要暴露兩個方法:set_params,get_params.
get_params
這個方法旨在獲取物件的引數,回傳物件默認是{引數:引數值}的鍵值對,如果將get_params的引數deep設定為True,還會回傳(如果有的話)子物件(它們是估計器),下面我們來仔細看一下這個方法的實作細節:
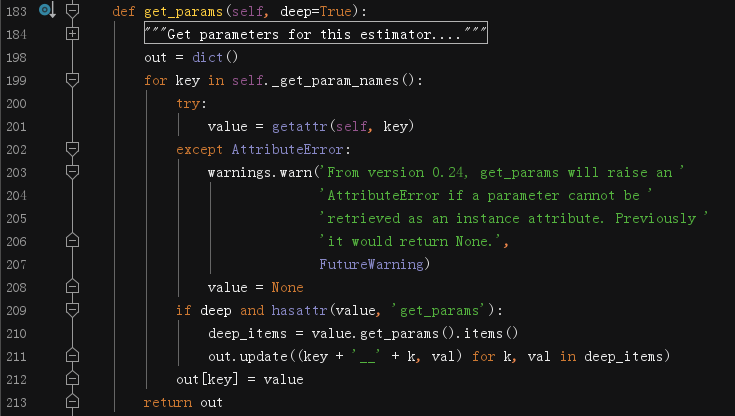
為了節約篇幅,我會將不重要的注釋略去,以后都是這樣處理,不再贅述,除非特殊說明,
(1)
函式體中主要就是getattr方法,語法:getattr(物件,要檢索的屬性[,如果屬性不存在則回傳的值]),Line200~208的任務是判斷self(一般就是估計器的實體)是否含有key這個引數,如果有就回傳它的引數值,否則人為設定為None,
為什么要寫這么復雜呢? 其實可以直接寫作 value = https://www.cnblogs.com/learn-the-hard-way/p/getattr(self, key, None),有點迷~
(2)
再來看Line209~212,如果用戶設定了deep=True,并且value物件實作了get_params(說明value物件是一個子物件,即估計器,否則普通的引數是不會再次實作get_params方法的),則提取引數字典的鍵值對,并且寫入字典,整個函式最后回傳的也是字典,
(3)
我們先快速的看一下這個方法具體是怎么使用的,然后再繼續追蹤原始碼的實作,
from sklearn.ensemble import RandomForestClassifier
clf = RandomForestClassifier(random_state=0)
X = [[ 1, 2, 3], # 2 samples, 3 features
[11, 12, 13]]
y = [0, 1] # classes of each sample
clf.fit(X, y)
簡單的實體化一個隨機森林分類器的物件,我們看下對它呼叫get_params會回傳什么:
clf.get_params()
{'bootstrap': True,
'class_weight': None,
'criterion': 'gini',
'max_depth': None,
'max_features': 'auto',
'max_leaf_nodes': None,
'min_impurity_decrease': 0.0,
'min_impurity_split': None,
'min_samples_leaf': 1,
'min_samples_split': 2,
'min_weight_fraction_leaf': 0.0,
'n_estimators': 10,
'n_jobs': None,
'oob_score': False,
'random_state': 0,
'verbose': 0,
'warm_start': False}
很明顯,這就是這個隨機森林分類器的默認引數方案,
(4)
我們注意到Line199這行,使用了另一個方法 for key in self._get_param_names():,現在研究該函式
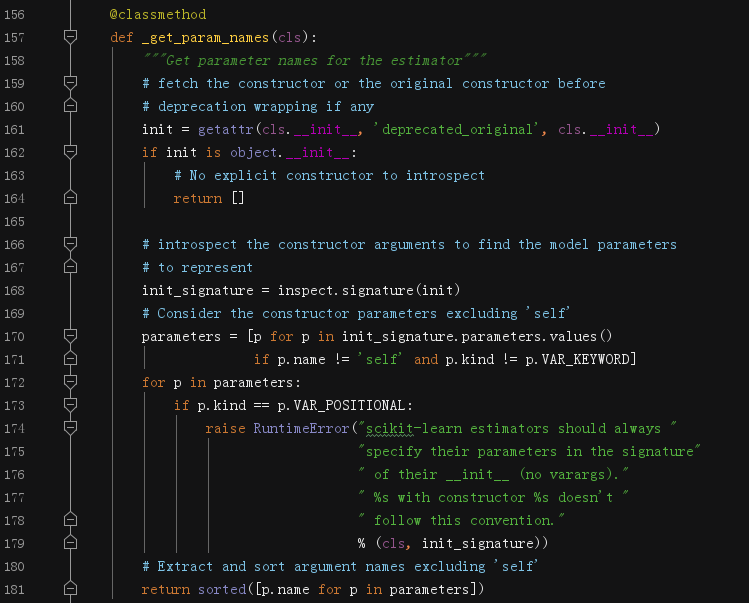
這里贅述一下,在sklearn這種大型的Python專案中,很多暴露出去的方法,其實質只是一個殼子,你可以理解為它是在搬運別人做的東西,只是美化包裝一下交給呼叫者,例如get_params方法,它并沒有真的獲取到估計器實體的引數,因為_get_param_names在幫它干這個活兒,
@classmethod這個裝飾器直接告訴我們,該方法的適用物件是類自身,而非實體物件,
這個函式有很多檢查事項,真正獲取引數的是 inspect.signature(init).parameters.values(),最后獲取串列中每個物件的name屬性,
set_params
這個方法作用是設定引數,正常來說,我們在初始化估計器的時候定制化引數,但是也有臨時修改引數的需求,這時可以手工呼叫set_params方法,但是更多的還是由繼承BaseEstimator的類來呼叫這個方法,
具體地,我們看下實作細節:
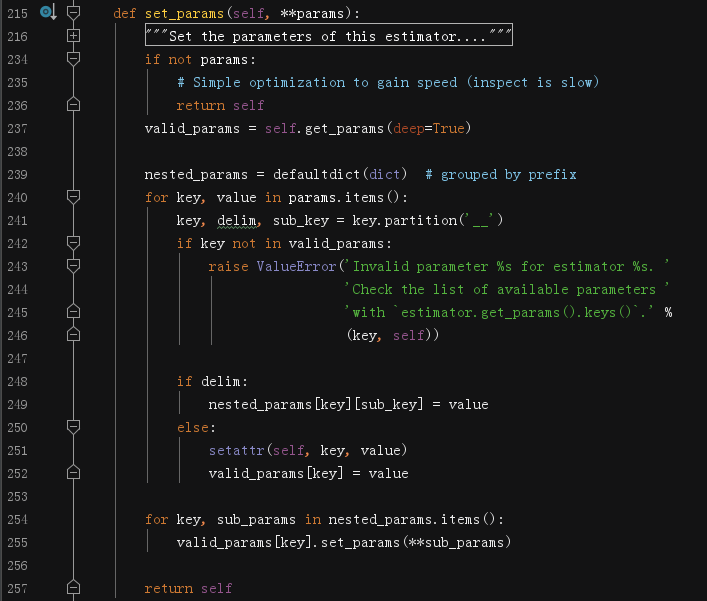
這個方案支持處理嵌套字典,但是我們不去糾纏這么瑣碎,直接看到L251,setattr(self, key, value),對估計器的key屬性設定一個新的值,
應用的實體:

ClassifierMixin
Mixin表示混入類,可以簡單地理解為給其他的類增加一些額外的方法,Sklearn的分類、回歸混入類只實作了score方法,任何繼承它們的類需要自己去實作fit、predict等其他方法,
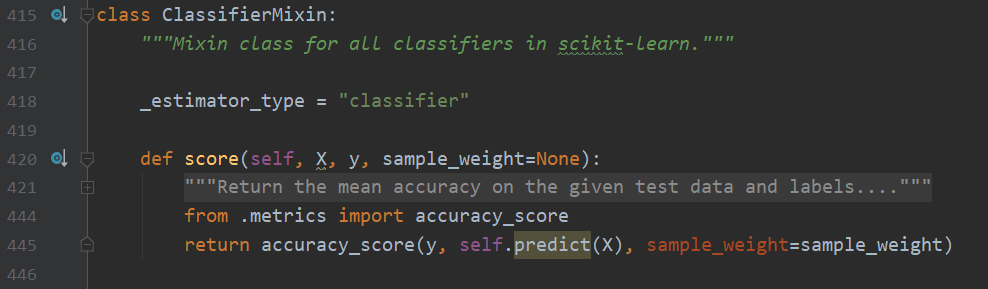
關于混入類,簡單的說就是一個父類,但是和普通的類有點不同,它需要指明元物件,_estimator_type,這里不再展開論述,感興趣的讀者請閱讀這篇討論 What is a mixin, and why are they useful?
可以看到,這個混入類的實作非常簡單,求預測值和真實值的準確率,回傳值是一個浮點數,注意預測值來自self.predict(),所以繼承混入類的類必須自己實作predict方法,否則引發錯誤,后面不再重復強調該細節,
再次的,分類任務的混入類又是在搬運其它函式的勞動成果,那我們就來研究一下accuracy_score的實作細節
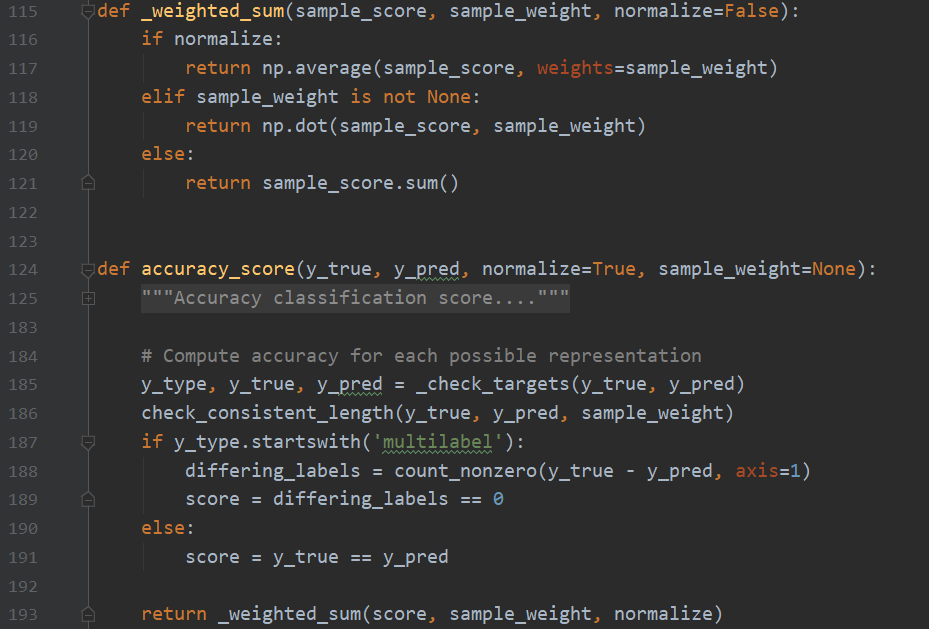
為簡潔起見,我們先忽略L185~189之間的代碼,后面會有專門研究分類任務的度量方法的文章,在那里我們再仔細研究它,直接看L191,y_ture == y_pred,這是一個簡單的寫法,精妙在于避免了for回圈,快速的檢查兩個物件之間每一個元素是否相等并且回傳True/False,L193對score結果做一層包裝,
- L116:如果設定了
normalize引數為True,則對score串列取平均值,就是預測正確的樣本個數/總體個數=預測準確率 - L118:如果有權重,則按照權重對各個樣本的得分進行加權,作為最終的預測準確率
- L121:如果沒有上述兩種設定,則直接回傳預測正確的樣本的個數,注意:sklearn默認的
score方法回傳預測準確率,而非預測正確的樣本個數,
RegressorMixin
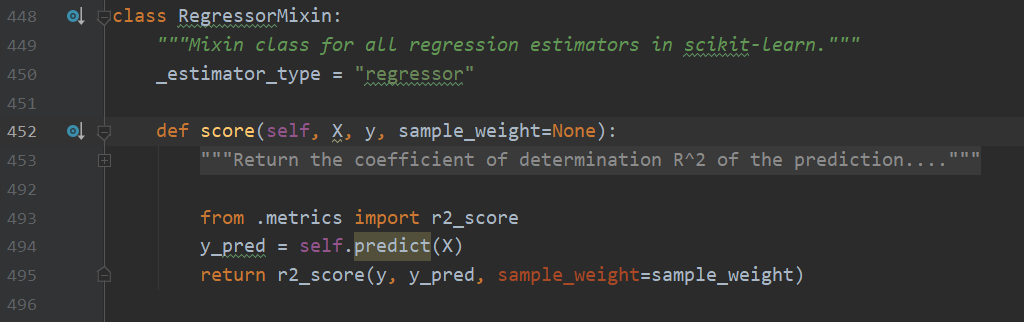
毫不意外地,回歸任務的混入類只實作了score方法,核心數學原理是 \(R^2\) 值,公式是 1-((y_true - y_pred)2)/((y_true - y_true_mean)2),直觀上看,這個值是衡量預測值與真實值的偏離度與真實值自身偏離度的一個比值, \(R^2\)最大為1,表示預測完全準確,值為0時表示模型沒有任何預測能力,
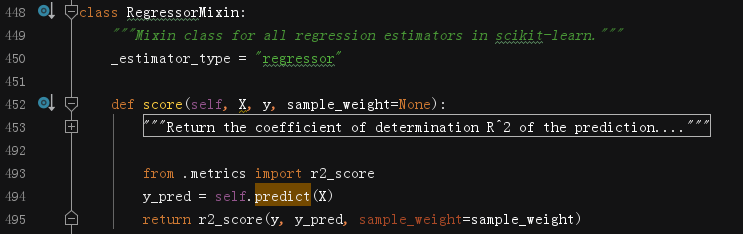
score方法呼叫了metrics模塊的r2_score方法,回傳值是浮點數,我們來研究下r2_score,這個函式是目前為止我們看過的最復雜的一個,因此,我們一塊一塊來研究,
檢查傳入的物件

(1)檢查傳入物件的長度
L577呼叫check_consistent_length檢查輸入標簽、輸出標簽、權重是不是有相同的長度,檢查的方法也很簡單,對每個物件計算長度,然后取不同的長度值有多少個,如果超過1個,說明幾個物件之間的長度不一,則引發一個錯誤來警告,

(2)檢查傳入的引數是否合法
L575呼叫_check_reg_targets方法,旨在檢查傳入引數是否合法,
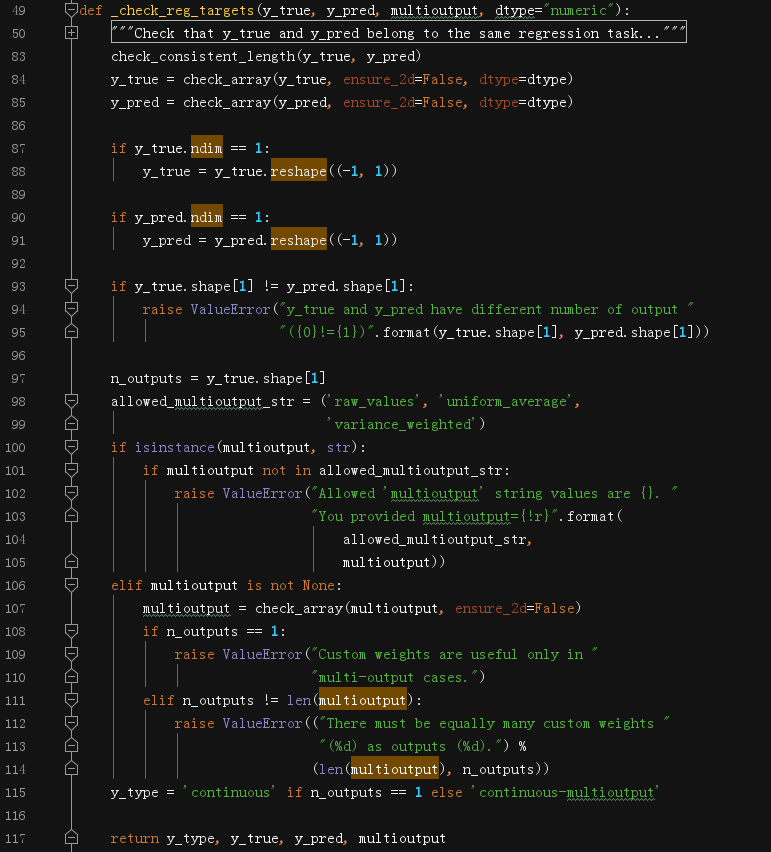
這個函式略長,但是大致做了以下幾件事:
- L83~95都是在做檢查和格式轉換,
- L97~114檢查輸入
multioutput和y_true是否吻合,即真實的標簽陣列的維度如果是1的話,顯然設定multioutput這個引數非None是不合法的,并且當真實標簽陣列的維度大于1的時候,若其維度和multioutput不同時也會引發錯誤以告警, - L115根據
y_true的維度決定標簽是哪種型別,分為:連續型和多類輸出的連續型,
注意:multioutput可以是字串,也可以是一個陣列,還可以是None值(考慮到向下兼容),因此這個引數非常靈活,后面研究具體演算法時遇到了會再次提及,此處不作過多糾纏,
檢查樣本數和權重系數
繼續看r2_score的實作:
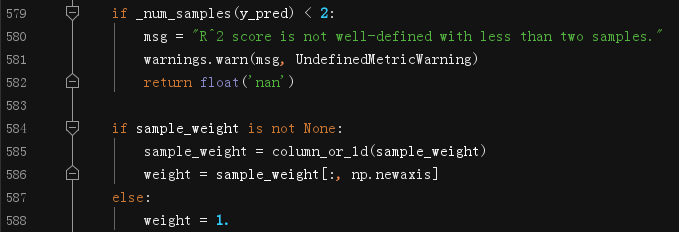
(3)L597~582檢查預測值的樣本數
如果預測值的樣本數不足2個,則引發錯誤告警,因為決定系數(即\(R^2\))要求至少要有2個樣本
(4)L584~588處理權重系數
- L585呼叫
np.ravel(),把權重陣列拉平到一維 - L586對
sample_weights擴維,將一維擴充為二維,二維擴充為三維,以此類推,值得注意的是,np.newaxis放置的位置不同,擴充的方向是不同的,具體看下面這個小例子:
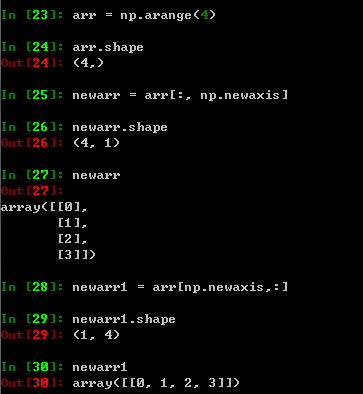
- L588,如果沒有傳入權重系數,則默認設定為1
實作\(R^2\)的計算細節
(5)構造分子和分母

(6)計算每個樣本的得分

- L595~596 記錄分母和分子的陣列中不為0的索引值(就是非0值所在的位置)
- L597 記錄分子、分母同時不為0的樣本的索引值,如果對這個寫法不熟悉,這里有個小例子幫助理解:
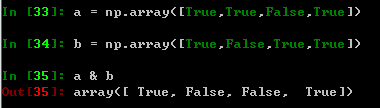
- L598~599 創建一個和真實標簽相同長度的全1陣列,然后對合法的索引位置計算真實的\(R^2\)值,
- L603 將分母為0的索引位置的值設定為0,這里設為其他常數也是可以的,對于同一個回歸任務的評價沒有影響,
(7)根據multioutput引數來決定各樣本所得分數的權重
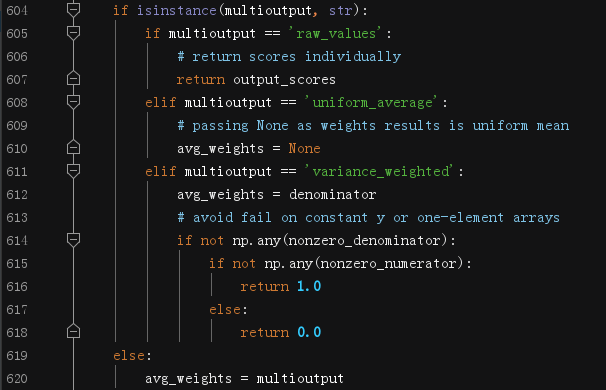
- L605~607 如果指明
raw_values,則輸出每個樣本的分數 - L608~610 如果指明
uniform_average,則avg_weights設定為None,其實就是均勻分布權重 - L611~612 如果指明
variance_weighted,則直接用分母作權重 - L614~618 處理常量y值或一維陣列的情形,如果分母全是0,則:若分子有非0,直接回傳1;否則回傳0
- L620 如果
multioutput不是字串,則直接把它作為最后的權重系數
(8)回傳得分
return np.average(output_scores, weights=avg_weights)
剛剛說到,指明uniform_average,則avg_weights設定為None,在numpy.average這個方法里,如果權重是None,計算均值就是簡單的mean()函式,
TransformerMixin
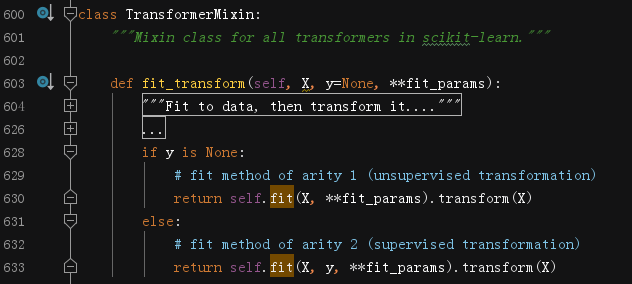
這個混入類的實作比較簡單,完全依靠使用它的類自己實作的fit方法和transform方法,但是它會根據是否有標簽,決定是有監督任務還是無監督任務,等后面遇到再具體討論,
補充
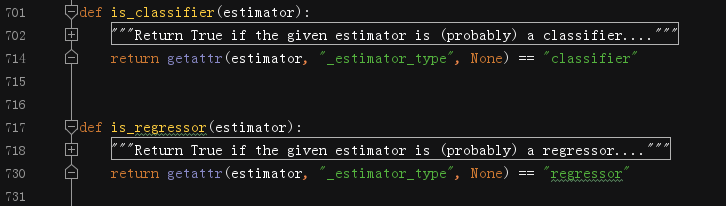
我們在研究分類混入類和回歸混入類的時候,都發現有_estimator_type這個變數,它的具體作用就是這里看到的,判斷一個估計器是用于分類任務還是回歸任務的,
如果有任何紕漏差錯,歡迎評論互動,

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/43591.html
標籤:其他
上一篇:自然語言處理中預訓練模型一覽