決策樹是如何作業的:
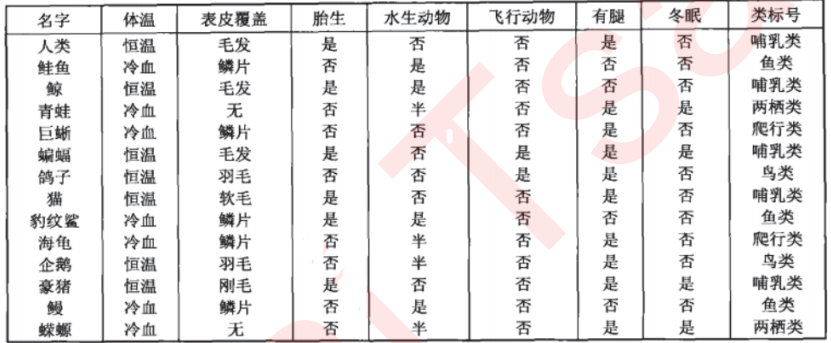
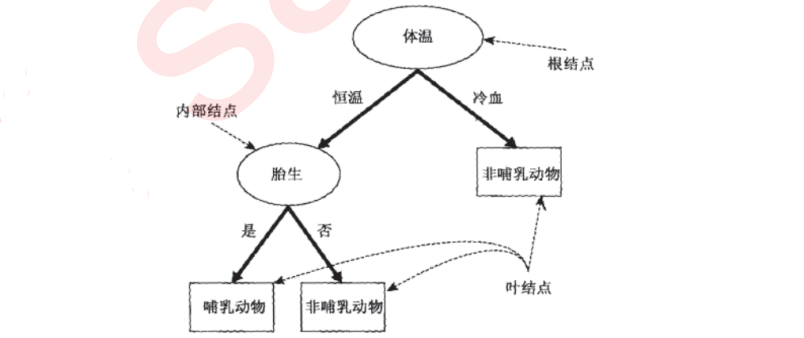
圖一 圖二
將資料根據特征分析,可以分成:根節點(初始節點)、中間節點、葉節點(無再可分節點),
注:其實根據表格我們可以分析出來三個維度(表頭、資料、標簽),資料用來描述表頭,表頭用來反映標簽,
微信群:回復K 進群

決策樹演算法的核心是要解決兩個問題:
1)如何從資料表中找出最佳節點和最佳分枝?
2)如何讓決策樹停止生長,防止過擬合?
sklearn建模流程:
1)實體化演算法物件 ——》 2)通過模型訓練模型 ——》3)通過模型介面獲取資訊
代碼如下:
from sklearn import tree #匯入需要的模塊 clf = tree.DecisionTreeClassifier() #實體化演算法物件,需要使用引數 clf = clf.fit(X_train,y_train) #用訓練集資料訓練模型 result = clf.score(X_test,y_test) #打分,匯入測驗集,從介面中呼叫需要的資訊
DecisionTreeClassifier() 函式:
class sklearn.tree.DecisionTreeClassifier (criterion=’gini’, splitter=’best’, max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=None, random_state=None, max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, class_weight=None, presort=False)
引數解釋:
criterion
為了要將資料轉化為一棵樹,決策樹需要找出最佳節點和最佳的分枝方法,對分類樹來說,衡量這個“最佳”的指標叫做“不純度”,通常來說不純度越低,決策樹對訓練集的擬合越好,現在使用的決策樹演算法在分枝方法上的核心大多是圍繞在對某個不純度相關指標的最優化上, 不純度基于節點來計算,樹中的每個節點都會有一個不純度,并且子節點的不純度一定是低于父節點的,也就是說,在同一棵決策樹上,葉子節點的不純度一定是最低的, criterion這個引數正是用來決定不純度的計算方法的,sklearn提供了兩種選擇:
criterion='entropy' #資訊熵(Entropy) criterion='gini’#基尼系數(Gini Impurity)
比起基尼系數,資訊熵對不純度更加敏感,對不純度的懲罰最強,資訊熵的計算比基尼系數緩慢一些,因為基尼系數的計算不涉及對數,所以推薦建議使用基尼系數,但也不是不是絕對,不填默認基尼系數,
random_state
設定分枝中的隨機模式的引數,默認None,在高維度時隨機性會表現更明顯,低維度的資料 隨機性幾乎不會顯現,輸入任意整數,會一直長出同一棵樹,讓模型穩定下來,
splitter
控制決策樹中的隨機選項的,有兩種輸入值,輸入“best”,決策樹在分枝時雖然隨機,但是還是會 優先選擇更重要的特征進行分枝(重要性可以通過屬性feature_importances_查看),輸入“random",決策樹在分枝時會更加隨機,樹會因為含有更多的不必要資訊而更深更大,并因這些不必要資訊而降低對訓練集的擬合,這也是防止過擬合的一種方式,當你預測到你的模型會過擬合,用這兩個引數來幫助你降低樹建成之后過擬合的可能性,當然,樹一旦建成,我們依然是使用剪枝引數來防止過擬合,
代碼練習:
#1.引入庫檔案 from sklearn import tree from sklearn.datasets import load_wine from sklearn.model_selection import train_test_split #2.獲取sklearn自動紅酒資料集 wine = load_wine() wine.data.shape wine.target #如果wine是一張表,應該長這樣: import pandas as pd pd.concat([pd.DataFrame(wine.data),pd.DataFrame(wine.target)],axis=1) wine.feature_names wine.target_names #3. 分訓練集和測驗集 Xtrain, Xtest, Ytrain, Ytest = train_test_split(wine.data,wine.target,test_size=0.3) Xtrain.shape Xtest.shape #4. 建立模型 clf = tree.DecisionTreeClassifier(criterion="gini") clf = clf.fit(Xtrain, Ytrain) #apply回傳每個測驗樣本所在的葉子節點的索引 print(clf.apply(Xtest)) #predict回傳每個測驗樣本的分類/回歸結果 print(clf.predict(Xtest)) score = clf.score(Xtest, Ytest) #回傳預測的準確度 score #5.決策樹 feature_name = ['酒精','蘋果酸','灰','灰的堿性','鎂','總酚','類黃酮','非黃烷類酚類','花青素','顏色強度','色調','od280/od315稀釋葡萄酒','脯氨酸'] import graphviz dot_data = tree.export_graphviz(clf,out_file = None,feature_names= feature_name,class_names=["琴酒","雪莉","貝爾摩德"],filled=True,rounded=True) graph = graphviz.Source(dot_data) graph.save()#保存決策樹 #特征重要性 clf.feature_importances_ [*zip(feature_name,clf.feature_importances_)] #我們的樹對訓練集的擬合程度如何? score_train = clf.score(Xtrain, Ytrain) score_train
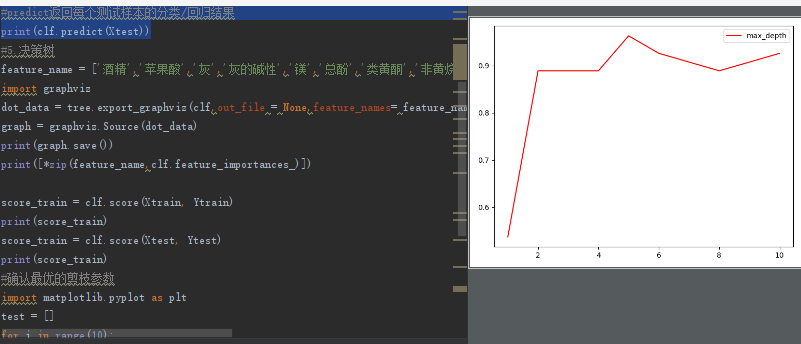
那具體怎么來確定每個引數填寫什么值呢?這時候,我們就要使用確定超引數的曲線來進行判斷了,
import matplotlib.pyplot as plt test = [] for i in range(10): clf = tree.DecisionTreeClassifier(max_depth=i+1 ,criterion="entropy" ,random_state=30 ,splitter="random" ) clf = clf.fit(Xtrain, Ytrain) score = clf.score(Xtest, Ytest) test.append(score) plt.plot(range(1,11),test,color="red",label="max_depth") plt.legend() plt.show()
可以根據顯示圖形確定引數選擇:
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/43603.html
標籤:其他