前言
- elasticsearch是分布式的,但是對于我們開發者來說并沒有過多的參與其中,我們只需啟動對應數量的節點,并給他們分配相同的cluster.name讓他們歸屬于同一個集群,創建索引的時候只需要指定索引主分片數量和副分片數量就行,其他的都交給了ES內部自己實作
- 這和資料庫的分布式和同源的solr實作分布式都是由區別的,資料庫要做集群分布式,比如分庫分表需要我們指定路由規則和資料庫同步策略,包括讀寫分離,主從同步登,solr的分布式也依賴zookeeper,但是elasticsearch完全屏蔽了這些,
- 雖然elasticsearch天生就是分布式的,并且在設計時屏蔽了分布式的復雜性,但我還得知道它內部的原理
節點互動原理
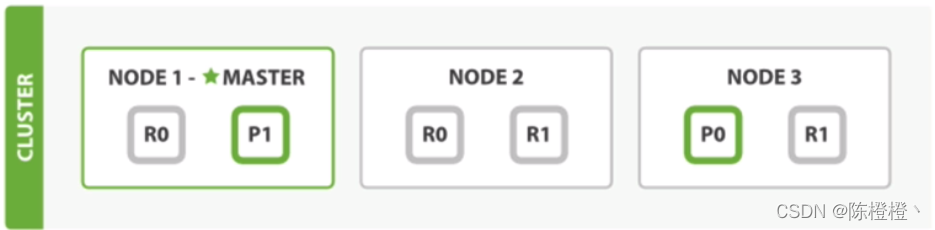
- es和其他中間件一樣,比如mysql,redis有master-slave模式,es集群也會選舉一個節點作為master節點
- –
- master節點它的職責是維護全集群狀態,在節點加入或離開集群的時候重新分配分片
- –
- 所有檔案級別的寫操作不會與master節點通信,master節點并不需要涉及到檔案級別的變更和搜索登操作,es分布式不太像mysql的master-slave模式,mysql是寫在主庫,然后在同步資料到從庫,而es檔案寫操作是分片上而不是節點上,先寫在主分片,主分片在同步給副分片,因為主分片可以分布在不同的節點上,所以當集群只有一個master節點的情況下,即使流量的增加它也不會成為瓶頸,就算它掛了,任何節點都會有機會成為主節點
- –
- 讀寫可以請求任意節點,節點在通過轉發請求到目的節點,比如一個檔案的新增,檔案通過路由演算法分片到某個主分片,然后找到對應的節點,將資料寫入到主分片上,然后在同步到副分片上,
- –
寫入檔案
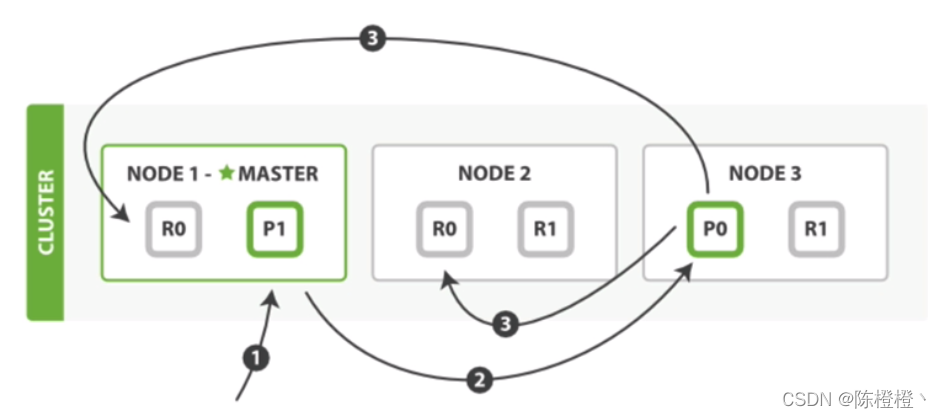
- 新增檔案
1、客戶端向node-1發送新增檔案請求
2、節點通過檔案的路由演算法確定該檔案屬于主分片-P0.因為主分片-P0在node-3,所以請求會轉發到node-3
3、檔案在node-3主分片-P0新增,新增成功后,將請求轉發到node-1和node-2對應的副分片-R0上,一旦所有的副本片都向node-1報告成功,node-1向客戶端報告成功,
- 讀取檔案
1、客戶端向node-1發送檔案請求
2、在處理讀取請求時,node-1在每次請求的時候會通過輪詢所有的副本分片來達到負載均衡,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/437978.html
標籤:其他