淘寶分布式檔案系統核心儲存引擎架構總結——TFS系統
- 一.專案介紹
- 1.什么是TFS系統
- 2.采用大檔案儲存資料
- 3.索引檔案
- 4.將索引檔案映射到記憶體
- 二.基本資料結構介紹
- 1.塊檔案資訊結構體
- 2.索引資訊結構體
- 3.小檔案資訊結構體
- 三.記憶體映射類——MMapFile
- 1.主要功能
- 2.基本方法
- 四.檔案操作類——FileOperation
- 1.主要功能
- 2.基本方法
- 3.代碼決議
- 五.檔案記憶體映射操作類——MMapFileOperation
- 1.主要功能
- 2.基本方法
- 六.索引處理類——IndexHandle
- 1.主要功能
- 2.基本方法
- 3.具體函式決議
- 1.hash_find() 方法
- 2.hash_insert() 方法
- 3. write_segment_meta()方法
- 4.read_segment_meta()方法
- 5.int dalete_segment_meta()
- 七.原始碼獲取
一.專案介紹
1.什么是TFS系統
摘自百度百科:
TFS(Taobao File System)是一個高可擴展、高可用、高性能、面向互聯網服務的分布式檔案系統,主要針對海量的非結構化資料,它構筑在普通的Linux機器集群上,可為外部提供高可靠和高并發的存盤訪問,TFS為淘寶提供海量小檔案存盤,通常檔案大小不超過1M,滿足了淘寶對小檔案存盤的需求,被廣泛地應用在淘寶各項應用中,它采用了HA架構和平滑擴容,保證了整個檔案系統的可用性和擴展性,同時扁平化的資料組織結構,可將檔案名映射到檔案的物理地址,簡化了檔案的訪問流程,一定程度上為TFS提供了良好的讀寫性能,
TFS的架構分為很多部分,這篇文章主要介紹 TFS 系統的儲存引擎架構,
2.采用大檔案儲存資料
TFS系統是針對海量非結構化的資料設計的,它不視一個較小的,單獨的資料為一個基本的儲存管理單位,而是將小的資料集合成一個大的資料塊,大的檔案(一般是64MB),簡稱為塊,并將其存放在一個檔案中,
使用大檔案的目的一是為了防止對磁盤的頻繁讀取,提高效率,二是為了防止頻繁讀取產生的記憶體碎片,三是為了減少過多的 Inode 節點對磁盤空間的占用,
每一個主塊檔案都有若干擴展塊(用來儲存溢位的資料),還有一個對應的索引檔案,主塊檔案,擴展檔案與索引檔案在邏輯上可以看成是一個整體,
主塊檔案各自擁有一個唯一的整數編號,它們之間通過整數編號進行區分,
3.索引檔案
每一個主塊檔案都是由很多小檔案組成的,那么怎么在主塊檔案快速中找到這些小檔案呢?
答案是使用索引,索引通過索引檔案實作,索引檔案的結構被定義成了一個由檔案實作的哈希鏈表,它的結構形似一個哈希鏈表,但因為是由檔案實作的,所以在某些地方與由程式實作的哈希鏈表不同,
下圖為一個程式中的哈希鏈表示意圖:
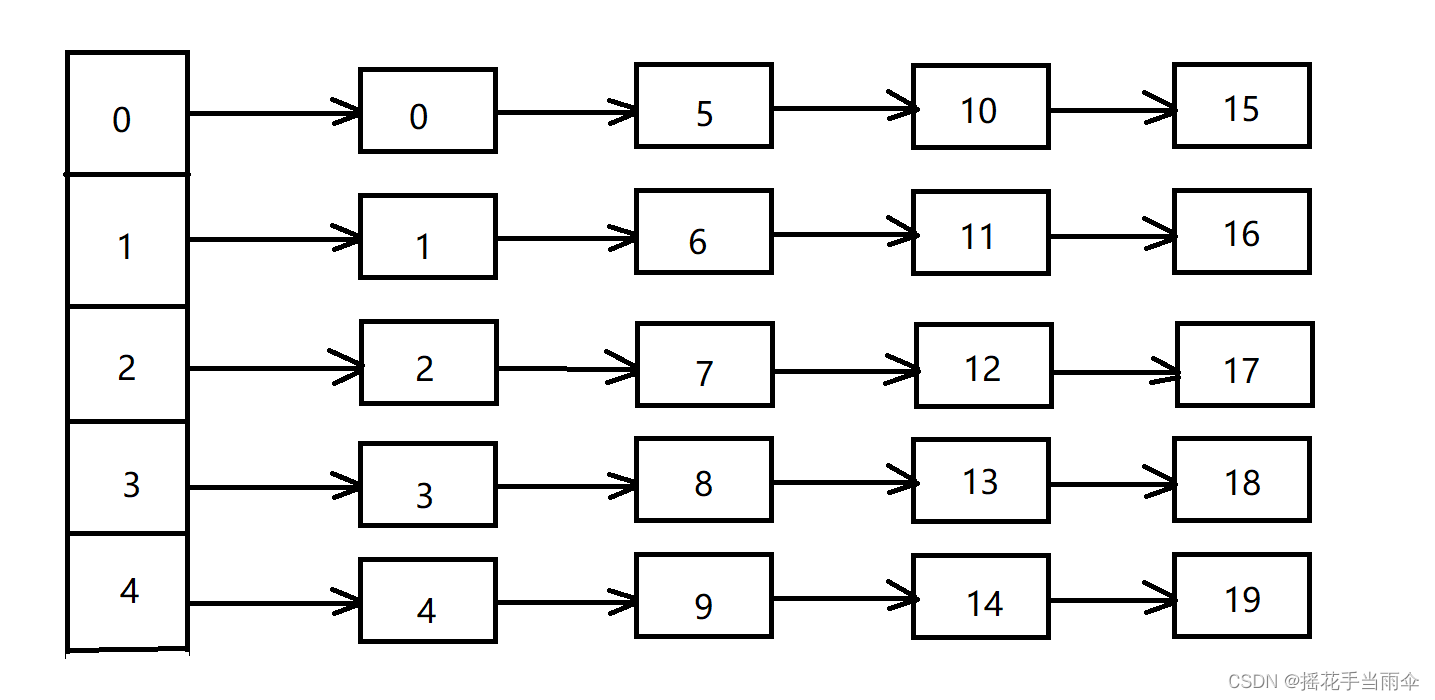
正常的哈希鏈表頭部是一個指標陣列,陣列中存放的是指標,指向該哈希桶的第一個元素,各節點中除了有存放 value 的變數,還有一個 next 指標,指向該桶的下一個元素,
在TFS中,每一個小檔案就相當于哈希鏈表中的一個節點,每個小檔案擁有一個 id 作為它的鍵唯一標識它,采用取余法作為哈希函式,即 鍵 % 哈希桶數量 得到的就是哈希桶的陣列索引,表示它儲存在為該陣列索引的哈希桶內,
特別需要注意的是程式中的哈希鏈表都是通過指標鏈接的,指標中儲存的是地址,而索引檔案實作的哈希鏈表是通過儲存在 int 變數里的檔案偏移來鏈接的,
4.將索引檔案映射到記憶體
對作業系統相關知識熟悉的人應該知道,CPU 訪問記憶體要比訪問磁盤快成千上萬倍,所以為了快速找到小檔案在主塊檔案中的位置,我們可以將索引檔案映射進記憶體,在記憶體中操作索引檔案,以便更快地找到小檔案位置,將資料讀取出來,
我們使用 void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset) 函式進行記憶體映射,
這種思路讓我想到作業系統里的快表,也是將關鍵資訊儲存在更快的,更靠近 CPU 的儲存設備,以提高效率,
二.基本資料結構介紹
1.塊檔案資訊結構體
用來記錄塊檔案資訊,每一個主塊檔案對應一個塊id,對應一個塊檔案資訊結構體,
struct BlockInfo{
int block_id_ = 0; //塊檔案編號
int version_; //版本號
int file_count_; //當前已保存檔案總數
int size_; //當前已保存檔案資料總大小
int del_file_count_; //已洗掉的檔案數量
int del_size_; //已洗掉的檔案資料總大小
int seq_no_; //下一個可分配的檔案編號
};
2.索引資訊結構體
便于索引檔案插入或找到小檔案資訊的結構體,
struct IndexHeade{
BlockInfo block_info_; //塊資訊,儲存主塊的資訊,每一個主塊檔案有且只有一個索引檔案
int bucket_size_ = 0; //哈希桶大小,儲存哈希桶個數
int data_file_offset_; //儲存主塊檔案已使用空間的偏移
int index_file_size_; //儲存索引檔案可用來儲存小塊檔案的起始位置
int free_head_offset_; //儲存可重用的鏈表節點個數
};
3.小檔案資訊結構體
記錄主塊檔案中的小檔案在主塊檔案中的起始偏移的結構體,并且作為哈希鏈表中的鏈表節點使用,
struct MetaInfo{
int fileid_; //塊id
struct{
int inner_offset_; //記錄小檔案在主塊檔案中的起始偏移
int size_; //小檔案大小
} location_;
int next_mate_offset_; //記錄在同一個哈希桶中的下一個小檔案結構體的偏移量,類似于鏈表中的next指標
};
首先明確一點,因為索引檔案是要進行記憶體映射的,并且映射記憶體區與索引檔案保存一致,所以各種資料的相對位置在索引檔案中與在映射記憶體區是一樣的,對索引檔案的修改會同步到對應的記憶體中,對記憶體的修改也會同步到索引檔案中,
每當在主塊檔案中儲存一個小檔案時,都應該創建一個MeatInfo結構體標識該小檔案,并且初始化它的各項引數,同時應該將這個結構體插入哈希鏈表中,即儲存在該主塊檔案對應的索引檔案中,索引檔案頭部儲存的是索引資訊結構體,接下來應該儲存哈希桶索引,哈希桶索引之后是小檔案資訊結構體,
舉個例子,如果我要創建一個哈希桶個數為 1000 的哈希鏈表,則在索引檔案頭部儲存完索引資訊結構體之后,還應該分配 1000 * 4 個位元組的空間用作哈希鏈表索引,每四個位元組當作一個 int 型整數,用來儲存該哈希桶的第一個節點在索引檔案中的起始偏移,如果一個小檔案id為 5,則其陣列索引為 5 % 1000 等于 5 ,所以這個小檔案結構體就應該儲存在索引為 5 的哈希桶中,即第五個 int 型整數對應的哈希桶,如果該索引為 0 ,則說明該桶中還不存在元素,所以在儲存完小檔案結構體之后,還應該把該桶的陣列索引置為第一個元素的起始偏移,如果不為 0 ,說明該桶中已存在元素,則找到該桶中的最后一個節點,在儲存完新的小檔案結構體之后將原本的最后一個節點的 next_mate_offset_ 指向新插入節點的偏移,
這樣講可能不夠直觀,看一張圖以便理解:
假設 IndexHeade 結構體占44個位元組,MetaInfo 占 16 個位元組,int 為 4 個位元組,哈希桶數量為5個,
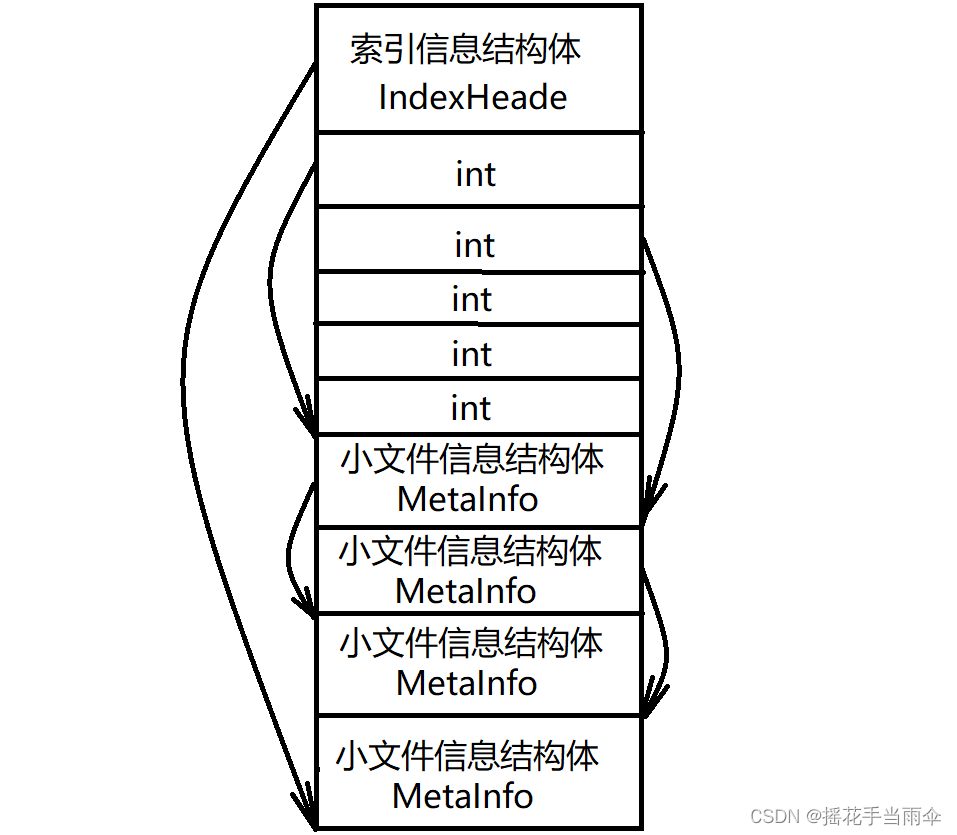
還是上面這張圖,把關鍵資料顯示出來,
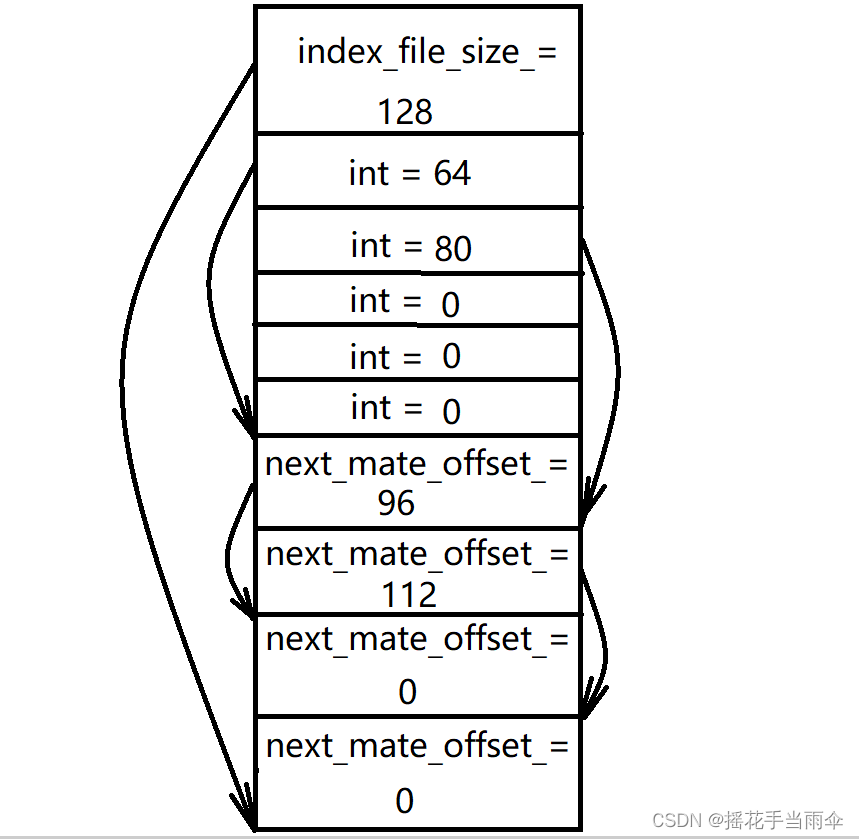
這里還存在一個小問題,我們知道了某個小檔案資訊結構體在索引檔案中的偏移,那么我怎么把它取出來并使用它呢,
這個其實很簡單,只需要創建一個臨時的結構體,再使用 memcpy() 函式將映射記憶體區資料復制到該結構體中就能使用了,
三.記憶體映射類——MMapFile
1.主要功能
實作記憶體映射的相關操作,封裝記憶體映射相關函式,
2.基本方法
- 建構式——MMapFile(),有多個多載,其中一個要傳入兩個引數,第一個引數是一個結構體,該結構體中有進行記憶體映射時的一系列引數,第二個引數是檔案運算子
- 執行記憶體映射——map_file()
- 重新執行記憶體映射(常用來擴容)——remap_file()
- 得到記憶體映射首地址——get_data()
- 得到記憶體映射大小——get_size()
- 解除記憶體映射——munmap_file()
- 將記憶體映射的內容同步到檔案——ensure_file_size()
- 保持磁盤檔案內容與記憶體映射區內容一致——sync_file()
四.檔案操作類——FileOperation
1.主要功能
實作檔案的基本操作,作為檔案映射操作類的基類,
2.基本方法
- 建構式——FileOperation(),傳入兩個引數一個是要打開的檔案名另一個是打開檔案的選項
- 關閉檔案——close_file()
- 打開檔案——open_file()
- 同步記憶體中所有已修改的檔案資料到磁盤——flush_data()
- 讀取檔案中資料——pread_file()
- 將資料寫入檔案中——pwrite_file()
- 得到檔案資料大小——get_file_size()
- 改變檔案指標位置——seek_file()
- 得到檔案運算子——get_fd()
3.代碼決議
分析下面一段代碼,雖然大部分是防御性編程,看起來似乎是有很多不必要的代碼,但生產環境中的實戰代碼與我們平時寫的代碼是不一樣的,在生產環境中,尤其是服務器端的代碼,很多在平時編程中不會出現的情況在生產環境中都有可能出現,所以應該盡可能周全的考慮到所有可能的情況,并設定足夠多的輸出資訊,確保任務日志足夠完善,這樣在出錯時便于我們排查出錯誤,
下面函式的功能是讀取檔案中的資料并保存在引數buf中,nbytes是要讀取資料的位元組大小,offset是檔案起始的偏移量,這個函式可以看成是了結合生產環境具體情況后對 pread64 函式的封裝,
int FileOperation::pread_file(char* buf, const int32_t nbytes, const int64_t offset)
{
int32_t left = nbytes;
int64_t read_offset = offset;
int32_t read_len = 0;
char* p_tmp = buf;
int i = 0;
while (left > 0) //設定循化是因為可能不能一次全部讀完,如果要分多次,每讀取一部分資料就讓left減去讀取的資料,直至left等于0則表示全部讀取完成
{
++i; //每讀取一次計數加一,防止重復讀取
if (i >= MAX_DISK_TIMES) //如果失敗多次,停止讀取,防止任務阻塞,如果因為硬體設備或其它原因導致讀取不可能成功而又不設定結束條件的話,則會造成多任務阻塞,一直占用資源,這在資源緊張的服務器環境下是不能被接受的
{
break;
}
if (check_file() < 0) //檢查檔案是否存在
return -errno;
if ((read_len = ::pread64(fd_, p_tmp, left, read_offset)) < 0) //讀取檔案中資料,存放在p_tmp中
{
read_len = -errno; //保存errno,防止被其他執行緒修改
if (EINTR == -read_len || EAGAIN == -read_len) //如果是這倆種錯誤,則重新讀取
{
continue; /* call pread64() again */
}
else if (EBADF == -read_len) //重新讀取
{
fd_ = -1;
continue;
}
else //回傳錯誤編號
{
return read_len;
}
}
else if (0 == read_len) //讀取到全部資料,跳出回圈
{
break; //reach end
}
left -= read_len; //讀取到部分資料,再次讀取
p_tmp += read_len;
read_offset += read_len;
}
if (0 != left) //讀取錯誤,回傳錯誤編號
{
return EXIT_DISK_OPER_INCOMPLETE;
}
return TFS_SUCCESS; //宏,表示成功
}
五.檔案記憶體映射操作類——MMapFileOperation
1.主要功能
檔案記憶體映射操作類繼承自檔案操作類,所以它擁有檔案操作類的基本方法,并且持有一個記憶體映射類指標,用來進行記憶體映射,
它的主要功能是可以借助記憶體映射指標完成指定檔案的記憶體映射,并且能使用繼承自父類的方法讀取檔案內資料與往檔案內寫入資料,
2.基本方法
- 建構式——MMapFileOperation(),需要傳入兩個引數,一個是要打開操作的檔案名,另一個是打開檔案時的引數
- 讀取檔案中資料——pread_file()(虛函式)
- 將資料寫入檔案中——pwrite_file()(虛函式)
- 執行記憶體映射——mmap_file()
- 解除記憶體映射——munmap_file()
- 得到記憶體映射首地址—— void* get_map_data() const
- 保持磁盤檔案與共享記憶體區內容一致——flush_file()
- 以及從檔案操作類繼承的一些方法,不一一列舉了
解釋一下檔案記憶體映射操作類的基本用法,首先實體化一個物件,它的建構式需傳入檔案名與打開檔案時的選項,如果帶上O_CREAT選項則表示若此檔案不存在則創建它,然后呼叫mmap_file()函式,該函式會對檔案運算子fd_進行檢測,如果它不是一個合法的值,則重新打開檔案,給fd_賦值,確保fd_是一個合法值,然后該函式會檢測實體化的物件持有的記憶體映射類指標是否是一個合法值,如果不是則實體化一個記憶體映射類物件并進行記憶體映射,如果是合法值則回傳,
完成了檔案的記憶體映射后,就可以讀取檔案資料或者往檔案中寫入資料,因為進行記憶體映射時設定的引數是保持檔案與記憶體映射記憶體區的同步,所以對檔案的修改會同步到對應的記憶體中,對記憶體的修改也會同步到檔案中,
六.索引處理類——IndexHandle
1.主要功能
持有檔案記憶體映射操作類指標,用來進行檔案的記憶體映射,檔案讀寫等功能,
實際上我們生成索引檔案所需要的所有操作都只需要一個索引處理類物件就能完成,
下圖表示上述四個類之間的關系:
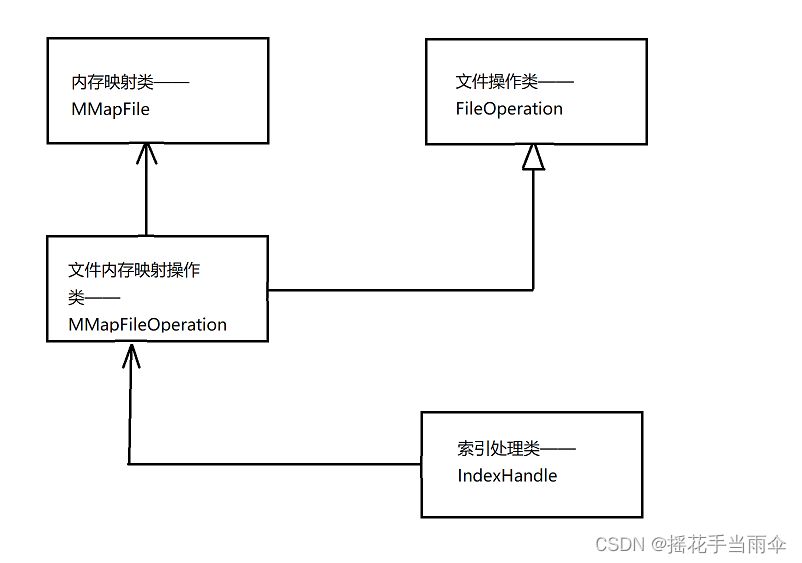
其中

代表持有某個類物件或該類物件指標(顯然持有指標更節省空間),

表示繼承自某個類,
2.基本方法
- create()——初始化 IndexHeader 結構體的各種屬性,并把它加載到索引檔案中,
- load()——檢測各項屬性是否正確,進行記憶體映射,
- hash_find()——哈希查找,在索引檔案中找到鍵值為 key(key 作為形參在函式呼叫時傳入) 的節點
- hash_insert()——在索引檔案中插入鍵值為 key 的節點,
- hash_compare()——比較 key 值是否與當前結構體 key 值一樣(該函式第一個引數為 key 值,第二個引數為 MetaInfo 結構體),
- write_segment_meta()——將節點寫入索引檔案,
- read_segment_meta()——從索引檔案中找到節點,
- dalete_segment_meta()——洗掉索引檔案中節點,
- update_block_info()——更新 BlockInfo 結構體資訊,
- 以及其它一些獲取 IndexHandle 結構體各種屬性的方法,
3.具體函式決議
下面決議的幾個函式,都是這個儲存引擎的重點,可以這么說,理解了下面幾個函式的原理及實作也就理解了這整個儲存引擎的原理,
1.hash_find() 方法
int hash_find(const int key, int& current_offset, int& previous_offset);
主要用于在哈希鏈表中查找節點,它接收三個引數,第一個是要查找節點的 key 值,第二個是儲存要查找的節點在索引檔案中的偏移,第三個是儲存要查找節點的上一個節點在索引檔案中的偏移(因為我們操作的是哈希鏈表,所以獲得要操作的節點的上一個節點是很有必要的),
//根據key值找到索引節點,設定它當前的檔案偏移與上一個節點的檔案偏移
int IndexHandle::hash_find(const int key, int& current_offset, int& previous_offset)
{
// find bucket slot
int slot = static_cast<int> (key) % bucket_size(); //計算哈希索引
previous_offset = 0;
MetaInfo meta_info;
int ret = TFS_SUCCESS;
// find in the list
int tmp = bucket_slot()[slot];
//bucket_slot()[slot]
for (int pos = bucket_slot()[slot]; pos != 0;) //for 循化,遍歷鏈表節點,找到節點
{
ret = file_op_->pread_file(reinterpret_cast<char*> (&meta_info), sizeof(MetaInfo), pos); //將資料讀入meta_info
if (TFS_SUCCESS != ret)
return ret;
if (hash_compare(key, meta_info.get_key())) //如果找到當前key,則當前元素存在,不用再插入
{
current_offset = pos; //用current_offset儲存要查找節點的偏移
return TFS_SUCCESS; //查找成功,回傳
}
previous_offset = pos; //保存當前節點的上一個節點的檔案偏移
pos = meta_info.get_next_meta_offset(); //如果未找到,則繼續找,類似與 next = pointer->next
}
return EXIT_META_NOT_FOUND_ERROR; //查找失敗,回傳
}
2.hash_insert() 方法
int hash_insert(const int slot, const int previous_offset, const MetaInfo& meta);
如果要插入一個節點,首先會先查找該節點是否存在在哈希鏈表內,如果存在則不用再次插入,如果不存在則插入,所以在執行 hash_insert() 方法之前會先呼叫 hash_find() 方法進行查找,然后根據hash_find() 方法的回傳值決定怎么繼續執行,
hash_find() 方法與hash_insert() 方法結合起來使用可以實作將新的小檔案資訊結構體寫入索引檔案,
這個函式接收三個引數,第一個是哈希索引,第二個在是執行 hash_find() 方法后儲存在 previous_offset 中的要查找節點的上一個節點的值,如果它為零則證明當前哈希桶沒有元素,不為零則可以用來鏈接節點,第三個引數接收要插入的小檔案資訊結構體,
int IndexHandle::hash_insert(const int slot, const int previous_offset, const MetaInfo& meta)
{
int ret = TFS_SUCCESS;
MetaInfo tmp_meta_info;
//memset(reinterpret_cast<MetaInfo*>(&tmp_meta_info), 0, sizeof(MetaInfo));
int current_offset = 0;
// get insert offset
// reuse the node in the free list
if (0 != index_header()->free_head_offset_) //如果有可重用的鏈表節點
{
ret = file_op_->pread_file(reinterpret_cast<char*> (&tmp_meta_info), META_INFO_SIZE,
index_header()->free_head_offset_);
if (TFS_SUCCESS != ret)
return ret;
current_offset = index_header()->free_head_offset_;
index_header()->free_head_offset_ = tmp_meta_info.get_next_meta_offset();
}
else // expand index file
{
current_offset = index_header()->index_file_size_;
index_header()->index_file_size_ += META_INFO_SIZE; //因為要插入節點,所以索引檔案當前偏移要假一個 MetaInfo 節點大小
}
MetaInfo meta_info(meta);
ret = file_op_->pwrite_file(reinterpret_cast<const char*> (&meta_info), META_INFO_SIZE, current_offset); //插入要插入節點
if (TFS_SUCCESS != ret)
return ret;
// previous_offset the last elem in the list, modify node
if (0 != previous_offset) //如果哈希桶的第一個元素不為空,則串聯起哈希鏈表
{
ret = file_op_->pread_file(reinterpret_cast<char*> (&tmp_meta_info), META_INFO_SIZE, previous_offset);
if (TFS_SUCCESS != ret)
return ret;
tmp_meta_info.get_next_meta_offset() = current_offset;
ret = file_op_->pwrite_file(reinterpret_cast<const char*> (&tmp_meta_info), META_INFO_SIZE, previous_offset); //因為修改了上一個節點,所以將它重新寫入索引檔案
if (TFS_SUCCESS != ret)
return ret;
}
else //如果該桶中不存在元素,則哈希桶索引應指向該桶內第一個元素,即現在插入的元素
{
bucket_slot()[slot] = current_offset;
}
return TFS_SUCCESS;
}
3. write_segment_meta()方法
int write_segment_meta(const int key, const MetaInfo& meta);
將小檔案資訊結構體寫入索引檔案,其實就是實作了 hash_find() 與hash_insert() 兩個方法的整合,
int IndexHandle::write_segment_meta(const int key, const MetaInfo& meta) //將小檔案資訊寫入索引檔案
{
int current_offset = 0, previous_offset = 0;
int ret = hash_find(key, current_offset, previous_offset); //先進行查找
if (TFS_SUCCESS == ret) // check not exists
{
return EXIT_META_UNEXPECT_FOUND_ERROR;
}
else if (EXIT_META_NOT_FOUND_ERROR != ret)
{
return ret;
}
int slot = static_cast<int> (key) % bucket_size();
return hash_insert(slot, previous_offset, meta); //插入節點
}
4.read_segment_meta()方法
int IndexHandle::read_segment_meta(const int key, MetaInfo& meta);
該函式的功能是讀出指定節點,通過 hash_find() 方法可以很容易實作,
int IndexHandle::read_segment_meta(const int key, MetaInfo& meta)
{
int current_offset = 0, previous_offset = 0;
// find meta
int ret = hash_find(key, current_offset, previous_offset);
if (TFS_SUCCESS == ret) //exist
{
ret = file_op_->pread_file(reinterpret_cast<char*> (&meta), META_INFO_SIZE, current_offset); //找到該節點,讀入 meta 結構體
if (TFS_SUCCESS != ret)
return ret;
}
else
{
return ret;
}
return TFS_SUCCESS;
}
5.int dalete_segment_meta()
int dalete_segment_meta(const int key);
洗掉指定節點的函式,如果理解了上面函式的實作原理,這個函式可以自己實作出來,也算是一個小檢測吧,檢測一下自己是否真正掌握了上文的內容,
七.原始碼獲取
TFS——檔案儲存引擎原始碼
完結撒花,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/437985.html
標籤:其他
上一篇:車間數字孿生解決方案(二)
下一篇:Flink HA模式環境搭建