目 錄
-
專案實戰——將Hive表的資料直接匯入ElasticSearch
??此篇文章不用寫代碼,簡單粗暴,但是相對沒有那么靈活;底層采用MapReduce計算框架,匯入速度相對較慢! -
專案實戰——Spark將Hive表的資料寫入ElasticSearch(Java版本)
??此篇文章需要Java代碼,實作功能和篇幅類似,直接Java一站式解決Hive內用Spark取數,新建ES索引,灌入資料,并且采用ES別名機制,實作ES資料更新的無縫更新,底層采用Spark計算框架,匯入速度相對文章1的做法較快的多!; -
專案實戰——釘釘報警驗證ElasticSearch和Hive資料倉庫內的資料質量(Java版本)
??此篇文章主要選取關鍵性指標,資料校驗資料源Hive和目標ES內的資料是否一致; -
專案實戰——Spark將Hive表的資料寫入需要用戶名密碼認證的ElasticSearch(Java版本)
??此篇文章主要講述如何通過spark將hive資料寫入帶賬號密碼權限認證的ElasticSearch 內; -
專案實戰(生產環境部署上線)——引數配置化Spark將Hive表的資料寫入需要用戶名密碼認證的ElasticSearch(Java版本))
??此篇文章主要講述如何通過spark將hive資料寫入帶賬號密碼權限認證的ElasticSearch 內,同時而是,spark,es建索引引數配置化,每次新增一張表同步到es只需要新增一個xml組態檔即可,也是博主生產環境運用的java代碼,彌補下很多老鐵吐槽方法4的不足,
??綜述:
??1.如果感覺編碼能力有限,又想用到Hive資料匯入ElasticSearch,可以考慮文章1;
??2.如果有編碼能力,個人建議采用文章2和文章3的組合情況(博主推薦),作為離線或者近線資料從資料倉庫Hive匯入ElasticSearch的架構方案,并且此次分享的Java代碼為博主最早實作的版本1,主要在于易懂,實作功能,學者們可以二次加工,請不要抱怨代碼寫的爛;
??3.如果是elasticsearch是自帶賬號密碼權限認證的,如云產品或者自己設定了賬號密碼認證的,那么辦法,只能用文章4了;
??4.如果部署上線,還是要看文章5,
-
本人Hive版本:2.3.5
-
本人ES版本:7.7.1
-
本人Spark版本:2.3.3
背 景
??將要創建的ES索引資訊和ES的連接資訊引數化,這樣每次新增一張表時,只需要新增一個xml組態檔即可,es服務器遷移,只需要變更一個ES檔案即可,因為是大資料環境嘛,博主選擇把這兩類組態檔放在hdfs上,當然如果沒有hdfs,也可以把組態檔放到ftp,或者某共享檔案夾下,只是不同檔案系統在讀取組態檔的IO流略有不同,讀者根據自己的檔案系統來選擇相應的檔案IO流即可,
??如圖1,主要資料鏈路架構就是通過呼叫編譯好的jar包讀取hdfs上的組態檔資訊,再通過spark將hive的表同步到Elasticsearch內,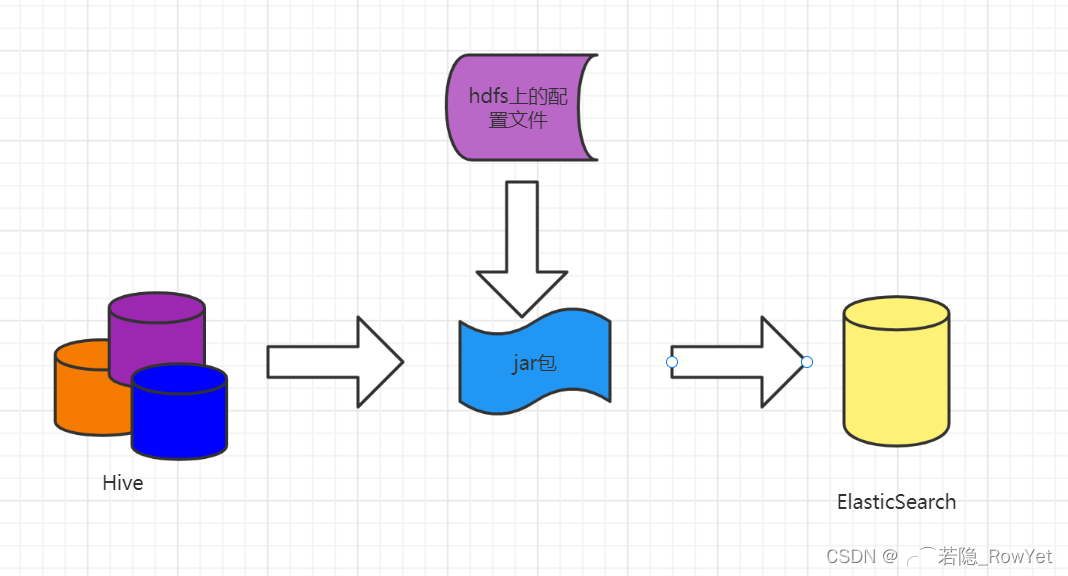
圖1 引數化資料鏈路圖 ??ElasticSearch是可以配置用戶名,密碼認證的,特別是云產品,公司如果買的ElasticSearch的云服務,那必然是帶用戶名密碼認證的,即當你訪問你的ES時,默認一般是9200埠時會彈出如圖2的提示,需要你填寫用戶名密碼;
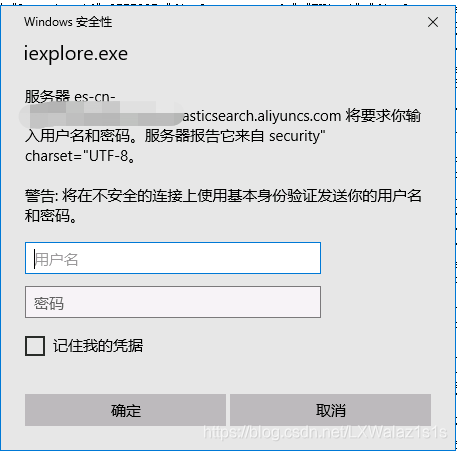
解決方案
ping通ES的機器
??在你要訪問的源機器ping通需要目標端的es機器ip,ping不通,找網管;
telnet通ES的機器的埠
??在你要訪問的源機器telnet通需要目標端的es機器ip和埠,telnet不通,找網管;
拿到用戶名和密碼
??既然是用戶名和密碼認證,當然需要向管理員拿到賬號和密碼,拿到用戶名和密碼后,先去測驗下該用戶名能否登陸es,并且能否讀寫權限,讀寫,創建index(非必要),可以在kibana上驗證,認證訪問,最好在你跑程式的地方,跑一下RESTFul風格的代碼,如下(linux環境shell命令列內直接跑);
# 用戶名密碼有轉移字符,記得前面加\轉移,如abc!123,寫成abc\!123
# 用戶名密碼有轉移字符,記得前面加\轉移,如abc!123,寫成abc\!123
# 用戶名密碼有轉移字符,記得前面加\轉移,如abc!123,寫成abc\!123
curl -k -u user:password -XGET http://es-ip:9200/your_index/_search
??windows cmd下:
# 注意用戶名密碼后面是@符號,用戶名密碼有轉譯字符可不轉譯,別亂搞
# 注意用戶名密碼后面是@符號,用戶名密碼有轉譯字符可不轉譯,別亂搞
# 注意用戶名密碼后面是@符號,用戶名密碼有轉譯字符可不轉譯,別亂搞
curl "http://user:password@es-ip:9200/your_index/_search"
??如果能獲取到資料,說明網路,賬號一切都Ok,加上kibana能讀寫index,說明權限Ok,否則,哪一環出了問題去找到相關的人員解決,準備作業都Ok了,再去寫代碼,不然代碼一直報錯,讓你懷疑人生;
專案樹
??總體專案樹圖譜如圖1所示,編程軟體:IntelliJ IDEA 2019.3 x64,采用Maven架構;
/LXWalaz1s1s/13037253)
feign:連接ES和Spark客戶端相關的Java類;utils:操作ES和Spark相關的Java類;resources:日志log的配置類;pom.xml:Maven組態檔;
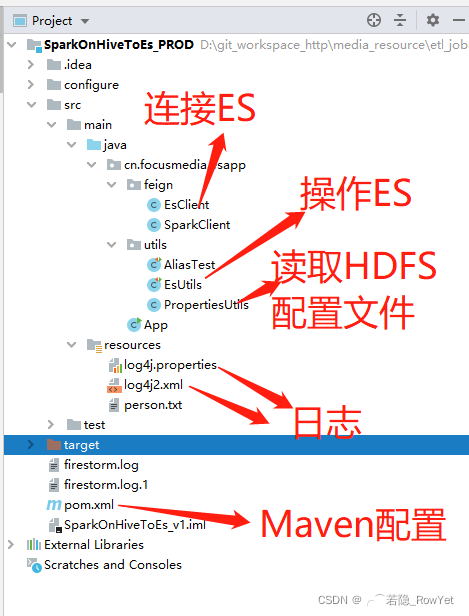
Maven組態檔pox.xml
??該專案使用到的Maven依賴包存在pom.xml上,具體如下所示;.
<?xml version="1.0" encoding="UTF-8"?>
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>SparkOnHiveToEs_buildinginfo_v1</artifactId>
<version>1.0-SNAPSHOT</version>
<name>SparkOnHiveToEs_buildinginfo_v1</name>
<!-- FIXME change it to the project's website -->
<url>http://www.example.com</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.7</maven.compiler.source>
<maven.compiler.target>1.7</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/org.elasticsearch/elasticsearch -->
<!--ES本身的依賴-->
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>7.7.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.elasticsearch.client/elasticsearch-rest-high-level-client -->
<!--ES高級API,用來連接ES的Client等操作-->
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.7.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/junit/junit -->
<!--junit,Test測驗使用-->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/org.projectlombok/lombok -->
<!--lombok ,用來自動生成物件類的建構式,get,set屬性等-->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.12</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.testng</groupId>
<artifactId>testng</artifactId>
<version>RELEASE</version>
<scope>compile</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/com.fasterxml.jackson.core/jackson-databind -->
<!--jackson,用來封裝json-->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.11.0</version>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch-hadoop</artifactId>
<version>7.7.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.elasticsearch/elasticsearch-spark-20 -->
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch-spark-20_2.11</artifactId>
<version>7.7.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-core -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.3.3</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.3.3</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.11</artifactId>
<version>2.3.3</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.9.1</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<version>2.9.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/dom4j/dom4j -->
<dependency>
<groupId>dom4j</groupId>
<artifactId>dom4j</artifactId>
<version>1.6.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-common -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.8.5</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.8.5</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.8.5</version>
</dependency>
</dependencies>
<build>
<plugins>
<!-- 在maven專案中既有java又有scala代碼時配置 maven-scala-plugin 插件打包時可以將兩類代碼一起打包 -->
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<version>2.15.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<!-- maven 打jar包需要插件 -->
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<version>2.4</version>
<configuration>
<!-- 設定false后是去掉 MySpark-1.0-SNAPSHOT-jar-with-dependencies.jar 后的 “-jar-with-dependencies” -->
<!--<appendAssemblyId>false</appendAssemblyId>-->
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<mainClass>com.bjsxt.scalaspark.core.examples.ExecuteLinuxShell</mainClass>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>assembly</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
日志組態檔
??最終這個Job是需要給spark-submit呼叫的,所以希望有一些有用關鍵的資訊可以通過日志輸出,而不是采用System,out.println的形式輸出到console端,所以要用到log.info("關鍵內容資訊")方法,所以設定兩個log的配置資訊,如,只輸出bug,不輸出warn等,可以根據自己需求來配置,具體兩個log組態檔內容如下;
??log4j.properties配置如下;
log4j.rootLogger=INFO, stdout, R
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%5p - %m%n
log4j.appender.R=org.apache.log4j.RollingFileAppender
log4j.appender.R.File=firestorm.log
log4j.appender.R.MaxFileSize=100KB
log4j.appender.R.MaxBackupIndex=1
log4j.appender.R.layout=org.apache.log4j.PatternLayout
log4j.appender.R.layout.ConversionPattern=%p %t %c - %m%n
log4j.logger.com.codefutures=INFO
??log4j2.xml配置如下;
<?xml version="1.0" encoding="UTF-8"?>
<Configuration status="warn">
<Appenders>
<Console name="Console" target="SYSTEM_OUT">
<PatternLayout pattern="%m%n" />
</Console>
</Appenders>
<Loggers>
<Root level="INFO">
<AppenderRef ref="Console" />
</Root>
</Loggers>
</Configuration>
讀取hdfs組態檔
??注意配置是存在hdfs上的,當然讀者也可以根據自己需求存在不同的檔案系統內,因為存在hdfs檔案系統,所以要遵循hdfs檔案系統的IO流,具體參看一下PropertiesUtils.java
package cn.focusmedia.esapp.utils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
import java.io.*;
import java.util.Iterator;
import java.util.Properties;
public class PropertiesUtils {
public static String getProperties(String filePath,String key)
{
// //本地檔案系統
// Properties prop =new Properties();
// try {
// InputStream inputStream=new BufferedInputStream(new FileInputStream(new File(filePath)));
// prop.load(inputStream);
//
// } catch (Exception e) {
// e.printStackTrace();
// }
// return prop.getProperty(key);
//hdfs檔案系統
Configuration conf = new Configuration();
FileSystem fs=null;
Properties prop =new Properties();
try {
fs= FileSystem.get(conf);
} catch (IOException e) {
e.printStackTrace();
}
Path path = new Path(filePath);
FSDataInputStream inputStream=null;
try {
inputStream = fs.open(path);
prop.load(inputStream);
} catch (IOException e) {
e.printStackTrace();
}
return prop.getProperty(key);
}
//解xml
public static String getXML(String filePath,String key)
{
Configuration conf = new Configuration();
FileSystem fs=null;
try {
fs= FileSystem.get(conf);
} catch (IOException e) {
e.printStackTrace();
}
Path path = new Path(filePath);
FSDataInputStream inputStream=null;
try {
inputStream = fs.open(path);
} catch (IOException e) {
e.printStackTrace();
}
File file=new File(filePath);
SAXReader reader=new SAXReader();
String myValue = null;
try {
Document doc=reader.read(inputStream);
// Document doc=reader.read(file);
Element root = doc.getRootElement();
Element foo;
for (Iterator i = root.elementIterator("VALUE"); i.hasNext();) {
foo = (Element) i.next();
myValue= foo.elementText(key);
}
} catch (DocumentException e) {
e.printStackTrace();
}
return myValue;
}
}
連接Spark的客戶端
??程式最終選擇在yarn上跑,所以這一塊可以選擇忽略,
連接ElasticSearch的客戶端
??將ES的連接資訊組態檔存在hdfs的/app/hive_to_es/configure/prod_es_connection.properties,內容如下,用戶名密碼可以配進去,但是沒必要,因為畢竟hdfs檔案系統,安全性不高,博主用戶名密碼是寫死在程式內,
#ElasticSearch Connection
node_num=3
node1=10.218.10.22
node2=10.218.10.21
node3=10.218.10.20
port=9200
??要想操作ES,首先需要配置連接ES的客戶端,具體代碼如下的EsClient.java檔案;
package cn.focusmedia.esapp.feign;
import cn.focusmedia.esapp.utils.PropertiesUtils;
import org.apache.http.HttpHost;
import lombok.extern.slf4j.Slf4j;
import org.apache.http.auth.AuthScope;
import org.apache.http.auth.UsernamePasswordCredentials;
import org.apache.http.client.CredentialsProvider;
import org.apache.http.impl.client.BasicCredentialsProvider;
import org.apache.http.impl.nio.client.HttpAsyncClientBuilder;
import org.elasticsearch.action.get.GetRequest;
import org.elasticsearch.action.get.GetResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestClientBuilder;
import org.elasticsearch.client.RestHighLevelClient;
import org.junit.Test;
import java.io.IOException;
@Slf4j
public class EsClient
{
public static RestHighLevelClient getClient()
{
int num=Integer.parseInt(PropertiesUtils.getProperties("/app/hive_to_es/configure/prod_es_connection.properties", "node_num"));
int port=Integer.parseInt(PropertiesUtils.getProperties("/app/hive_to_es/configure/prod_es_connection.properties","port"));
// int num=Integer.parseInt(PropertiesUtils.getProperties("configure/prod_es_connection.properties", "node_num"));
// int port=Integer.parseInt(PropertiesUtils.getProperties("configure/prod_es_connection.properties","port"));
HttpHost[] myHttpHost = new HttpHost[num];
for(int i=1;i<=num;i++)
{
myHttpHost[i-1]=new HttpHost(PropertiesUtils.getProperties("/app/hive_to_es/configure/prod_es_connection.properties","node"+i),port);
// myHttpHost[i-1]=new HttpHost(PropertiesUtils.getProperties("configure/prod_es_connection.properties","node"+i),port);
}
final CredentialsProvider credentialsProvider = new BasicCredentialsProvider();
credentialsProvider.setCredentials(AuthScope.ANY,
new UsernamePasswordCredentials("test", "test1234")); //es賬號密碼
RestClientBuilder builder = RestClient.builder(
myHttpHost)
.setHttpClientConfigCallback(new RestClientBuilder.HttpClientConfigCallback() {
@Override
public HttpAsyncClientBuilder customizeHttpClient(
HttpAsyncClientBuilder httpClientBuilder) {
httpClientBuilder.disableAuthCaching();
return httpClientBuilder
.setDefaultCredentialsProvider(credentialsProvider);
}
});
//創建RestHighLevelClient物件
RestHighLevelClient myclient=new RestHighLevelClient(builder);
log.info("RestClientUtil intfo create rest high level client successful!");
return myclient;
}
}
Spark將Hive表的資料寫入ElasticSearch工具類實作
??Spark將Hive表的資料寫入ElasticSearch工具類實作主要在utils/EsUtils.java檔案下,我這里比較偷懶,將所有的實作方法都放在這個檔案下,大家覺得不爽的話可以自己按需拆分,具體設計的內容如下;
package cn.focusmedia.esapp.utils;
import cn.focusmedia.esapp.feign.EsClient;
import lombok.extern.slf4j.Slf4j;
import org.apache.spark.SparkConf;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
import org.elasticsearch.action.admin.indices.alias.IndicesAliasesRequest;
import org.elasticsearch.action.admin.indices.alias.get.GetAliasesRequest;
import org.elasticsearch.action.admin.indices.delete.DeleteIndexRequest;
import org.elasticsearch.action.admin.indices.flush.FlushRequest;
import org.elasticsearch.action.admin.indices.flush.FlushResponse;
import org.elasticsearch.action.support.master.AcknowledgedResponse;
import org.elasticsearch.client.GetAliasesResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.client.indices.CreateIndexRequest;
import org.elasticsearch.client.indices.CreateIndexResponse;
import org.elasticsearch.client.indices.DeleteAliasRequest;
import org.elasticsearch.client.indices.GetIndexRequest;
import org.elasticsearch.common.xcontent.XContentType;
import org.elasticsearch.spark.sql.api.java.JavaEsSparkSQL;
import org.junit.Test;
import java.io.IOException;
@Slf4j
public class EsUtils
{
static RestHighLevelClient myClient= EsClient.getClient(); //獲取操作ES的
//查詢索引是否存在
@Test
public static boolean exsitsIndex(String index) throws IOException
{
//準備request物件
GetIndexRequest myrequest=new GetIndexRequest(index);
//通過client去操作
boolean myresult = myClient.indices().exists(myrequest, RequestOptions.DEFAULT);
//輸出結果
log.info("The index:"+index+" is exist? :"+myresult);
return myresult;
}
//創建索引
@Test
public static CreateIndexResponse creatIndex(String index,String index_mapping) throws IOException
{
log.info("The index name will be created : "+index);
//將準備好的setting和mapping封裝到一個request物件內
CreateIndexRequest myrequest = new CreateIndexRequest(index).source(index_mapping, XContentType.JSON);
//通過client物件去連接ES并執行創建索引
CreateIndexResponse myCreateIndexResponse=myClient.indices().create(myrequest, RequestOptions.DEFAULT);
//輸出結果
log.info("The index : "+index+" was created response is "+ myCreateIndexResponse.isAcknowledged());
return myCreateIndexResponse;
}
//洗掉索引
@Test
public static AcknowledgedResponse deleteIndex(String index) throws IOException {
//準備request物件
DeleteIndexRequest myDeleteIndexRequest = new DeleteIndexRequest();
myDeleteIndexRequest.indices(index);
//通過client物件執行
AcknowledgedResponse myAcknowledgedResponse = myClient.indices().delete(myDeleteIndexRequest,RequestOptions.DEFAULT);
//獲取回傳結果
log.info("The index :"+index+"create response is "+myAcknowledgedResponse.isAcknowledged());
return myAcknowledgedResponse;
//System.out.println(myAcknowledgedResponse.isAcknowledged());
}
//資料寫入ES
public static void tableToEs(String index,String index_auto_create,String es_mapping_id,String table_name,String es_nodes)
{
SparkConf conf=new SparkConf().setMaster("yarn").setAppName("SparkToES");
conf.set("es.nodes",es_nodes);
conf.set("es.net.http.auth.user" ,"test");
conf.set("es.net.http.auth.pass","test1234");
conf.set("es.nodes.wan.only","true");
conf.set("es.nodes.discovery","false");
conf.set("es.index.auto.create",index_auto_create);
conf.set("es.resource",index);
conf.set("es_mapping_id",es_mapping_id);
SparkSession spark = SparkSession
.builder()
.config(conf)
.appName("SparkToES")
.enableHiveSupport()
.config("spark.sql.hive.convertMetastoreParquet", false)
.getOrCreate();
Dataset<Row> table = spark.sql(""+table_name+"").repartition(60);
JavaEsSparkSQL.saveToEs(table,index);
// JavaEsSparkSQL.saveToEs(table,index, ImmutableMap.of("es.index.auto.create", index_auto_create,"es.resource", index, "es.mapping.id"
// ,es_mapping_id,"es.nodes" ,es_nodes,"es.nodes.wan.only",wan_only));
// "es.net.http.auth.pass" , "aib9qua!gh3Y" "es.net.http.auth.pass" , "aib9qua!gh3Y"
log.info("Spark data from hive to ES index: "+index+" is over,go to alias index! ");
spark.stop();
}
//資料寫入ES,無指定的mapping_id
public static void tableToEs(String index,String index_auto_create,String table_name,String es_nodes)
{
SparkConf conf=new SparkConf().setMaster("yarn").setAppName("SparkToES");
conf.set("es.nodes",es_nodes);
conf.set("es.net.http.auth.user" ,"test");
conf.set("es.net.http.auth.pass","test1234");
conf.set("es.nodes.wan.only","true");
conf.set("es.nodes.discovery","false");
conf.set("es.index.auto.create",index_auto_create);
conf.set("es.resource",index);
SparkSession spark = SparkSession
.builder()
.config(conf)
.appName("SparkToES")
.enableHiveSupport()
.config("spark.sql.hive.convertMetastoreParquet", false)
.getOrCreate();
Dataset<Row> table = spark.sql(""+table_name+"").repartition(60);
JavaEsSparkSQL.saveToEs(table,index);
// JavaEsSparkSQL.saveToEs(table,index, ImmutableMap.of("es.index.auto.create", index_auto_create,"es.resource", index, "es.mapping.id"
// ,es_mapping_id,"es.nodes" ,es_nodes,"es.nodes.wan.only",wan_only));
// "es.net.http.auth.pass" , "aib9qua!gh3Y" "es.net.http.auth.pass" , "aib9qua!gh3Y"
log.info("Spark data from hive to ES index: "+index+" is over,go to alias index! ");
spark.stop();
}
//flush下新的index資料
public static void flushIndex(String index) throws IOException
{
FlushRequest myFlushRequest =new FlushRequest(index);
FlushResponse myFlushResponse=myClient.indices().flush(myFlushRequest,RequestOptions.DEFAULT);
int totalShards =myFlushResponse.getTotalShards();
log.info("index: "+index+" has"+ totalShards +"flush over! ");
}
//別名操作,無縫連接
//獲取別名
public static String getAlias(String alias) throws Exception
{
GetAliasesRequest requestWithAlias = new GetAliasesRequest(alias);
GetAliasesResponse response = myClient.indices().getAlias(requestWithAlias, RequestOptions.DEFAULT);
String AliasesString = response.getAliases().toString();
String alias_index_name = null;
try
{
alias_index_name = AliasesString.substring(AliasesString.indexOf("{") + 1, AliasesString.indexOf("="));
}
catch (Exception e)
{
throw new Exception("your index do not has alias,please create a alias for you index!");
}
return alias_index_name;
}
//更新別名
public static void indexUpdateAlias(String index,String index_alias) throws Exception
{
String old_index_name=EsUtils.getAlias(index_alias);
log.info(index_alias+ " old index is "+old_index_name);
//洗掉別名映射的老的index
DeleteAliasRequest myDeleteAliasRequest = new DeleteAliasRequest(old_index_name, index_alias);
org.elasticsearch.client.core.AcknowledgedResponse myDeleteResponse=myClient.indices().deleteAlias(myDeleteAliasRequest, RequestOptions.DEFAULT);
boolean deletealisaacknowledged = myDeleteResponse.isAcknowledged();
log.info("delete index successfully? " + deletealisaacknowledged);
//新建新的index別名
IndicesAliasesRequest request = new IndicesAliasesRequest();
IndicesAliasesRequest.AliasActions aliasAction = new IndicesAliasesRequest.AliasActions(IndicesAliasesRequest.AliasActions.Type.ADD).index(index).alias(index_alias);
request.addAliasAction(aliasAction);
org.elasticsearch.action.support.master.AcknowledgedResponse indicesAliasesResponse = myClient.indices().updateAliases(request, RequestOptions.DEFAULT);
boolean createaliasacknowledged = indicesAliasesResponse.isAcknowledged();
log.info("create index successfully? "+createaliasacknowledged);
String now_index=EsUtils.getAlias(index_alias);
log.info(index_alias+ " now index is "+now_index);
if(now_index.equals(index))
{
log.info("index: "+index+ " alias update successfully!");
}
}
//更新別名
public static void indexUAddAlias(String index,String index_alias) throws Exception
{
//新建新的index別名
IndicesAliasesRequest request = new IndicesAliasesRequest();
IndicesAliasesRequest.AliasActions aliasAction = new IndicesAliasesRequest.AliasActions(IndicesAliasesRequest.AliasActions.Type.ADD).index(index).alias(index_alias);
request.addAliasAction(aliasAction);
org.elasticsearch.action.support.master.AcknowledgedResponse indicesAliasesResponse = myClient.indices().updateAliases(request, RequestOptions.DEFAULT);
boolean createaliasacknowledged = indicesAliasesResponse.isAcknowledged();
log.info("create index alias successfully? "+createaliasacknowledged);
String now_index=EsUtils.getAlias(index_alias);
log.info(index_alias+ " now index is "+now_index);
if(now_index.equals(index))
{
log.info("index: "+index+ " alias create successfully!");
}
}
}
主函式呼叫工具類實作整體功能
??主函式的實作的 功能順序下所示;
- 創建索引
- spark匯入資料
- flush下新的index資料
- 獲取目前的索引別名對應的索引名字,該索引名馬上要失效
- 替換最新資料別名
- 確認別名成功切換后清除老的索引
- 如果4步失敗,說明是因為還沒有建立起indexalias導致的,需要重建indexalias,
??注意,這里抽取Hive的哪張表,在ES建索引的名稱,別名,index表結構要求等等做成xml存入hdfs,博主存在/app/hive_to_es/configure下,組態檔舉例如dw_ads_resource_amap_city_district.xml;
index:你要建ES的索引名;
index_alias:你要建ES的索引別名;
index_auto_create:ES主鍵_id是否自動生成,如果寫true表示自動生成,如果是false,則還需要補一個hive表內的唯一鍵作為es的主鍵_id,如下的客戶表
<index_auto_create>false</index_auto_create>
<es_mapping_id>custom_id</es_mapping_id>
sql_script:spark取數陳述句;
index_mapping:ES的index結構,類似建表陳述句要求,
<configurations>
<VALUE>
<index>dw_sat_rs_amap_city_district</index>
<index_alias>dw_sat_rs_amap_city_district_v0</index_alias>
<index_auto_create>true</index_auto_create>
<sql_script>select * from ads.ads_resource_amap_city_district_d</sql_script>
<index_mapping>
{
"settings":{
"number_of_replicas":2,
"number_of_shards":1,
"max_result_window":1000000
},
"mappings":{
"properties":{
"amap_province_code":{
"type":"keyword"
},
"amap_province_name":{
"type":"keyword"
},
"amap_city_code":{
"type":"keyword"
},
"amap_city_name":{
"type":"keyword"
},
"amap_district_code":{
"type":"keyword"
},
"amap_district_name":{
"type":"keyword"
},
"dept_type_name":{
"type":"keyword"
},
"shops":{
"type":"integer"
},
"event_day":{
"type":"keyword"
}
}
}
}
</index_mapping>
</VALUE>
</configurations>
??注意:以上組態檔的hdfs全路徑,作為以下主函式jar包的引數,具體呼叫還是回到主函式內,代碼如下的app.java檔案;
package cn.focusmedia.esapp;
import cn.focusmedia.esapp.utils.EsUtils;
import cn.focusmedia.esapp.utils.PropertiesUtils;
import lombok.extern.slf4j.Slf4j;
import java.io.IOException;
/**
* Hello world!
*
*/
@Slf4j
public class App
{
public static void main( String[] args ) throws Exception
{
// 新的index名稱 ,組態檔的hdfs路徑作為jar呼叫的引數,每次采用時間戳后綴,防止重名
String index=PropertiesUtils.getXML(args[0],"index")+ System.currentTimeMillis();
//String index="dw_"+PropertiesUtils.getXML(args[0],"index")+"_v"+ System.currentTimeMillis();
log.info("index:"+index);
//es別名
String index_alias=PropertiesUtils.getXML(args[0],"index_alias");
log.info("index_alias:"+index_alias);
//es index的mapping結構
String index_mapping=PropertiesUtils.getXML(args[0],"index_mapping");
log.info("index_mapping:"+index_mapping);
//是否根據Hive表結構自動創建索引,一般寫false,怕結構變形,可以通過根據mapping來創建規范的索引
String index_auto_create=PropertiesUtils.getXML(args[0],"index_auto_create");
log.info("index_auto_create:"+index_auto_create);
//指定es index的id
String es_mapping_id =PropertiesUtils.getXML(args[0],"es_mapping_id");
log.info("es_mapping_id:"+es_mapping_id);
//Hive內的表結構
String table_name=null;
table_name=PropertiesUtils.getXML(args[0],"sql_script");
table_name=table_name.replaceAll("[\\t\\n\\r]"," ");
log.info("table_name:"+table_name);
// es集群節點集合
// int num=Integer.parseInt(PropertiesUtils.getProperties("configure/prod_es_connection.properties", "node_num"));
// int port=Integer.parseInt(PropertiesUtils.getProperties("configure/prod_es_connection.properties","port"));
int num=Integer.parseInt(PropertiesUtils.getProperties("/app/hive_to_es/configure/prod_es_connection.properties", "node_num"));
int port=Integer.parseInt(PropertiesUtils.getProperties("/app/hive_to_es/configure/prod_es_connection.properties","port"));
StringBuilder my_es_nodes=new StringBuilder("");
for(int i=1;i<=num;i++)
{
//my_es_nodes.append(PropertiesUtils.getProperties("configure/prod_es_connection.properties","node"+i)+":"+port+",");
my_es_nodes.append(PropertiesUtils.getProperties("/app/hive_to_es/configure/prod_es_connection.properties","node"+i)+":"+port+",");
}
// 去掉最后一位逗號
String es_nodes= my_es_nodes.substring(0,my_es_nodes.length()-1);
log.info("es_nodes:"+es_nodes);
// 創建索引
if(EsUtils.exsitsIndex(index))
EsUtils.deleteIndex(index);
EsUtils.creatIndex(index,index_mapping);
//spark匯入資料
//tableToEs(String index,String index_auto_create,String es_mapping_id,String table_name,String es_nodes)
if(!Boolean.parseBoolean(index_auto_create))
{
EsUtils.tableToEs(index,index_auto_create,es_mapping_id,table_name,es_nodes);
}else
{
EsUtils.tableToEs(index,index_auto_create,table_name,es_nodes);
}
//flush下新的index資料
EsUtils.flushIndex(index);
//獲取目前的索引別名對應的索引名字,該索引名馬上要失效
try {
String old_index=EsUtils.getAlias(index_alias);
//替換最新資料別名
EsUtils.indexUpdateAlias(index,index_alias);
//確認別名成功切換后清除老的索引
EsUtils.deleteIndex(old_index);
}
catch (Exception e)
{
e.printStackTrace();
log.info("no old index alias,create new index alias");
EsUtils.indexUAddAlias(index,index_alias);
}
}
}
打成Jar包并部署
??將除錯無誤的專案打成Jar包,如果還不會打Jar包,可以參考博客IntelliJ IDEA將代碼打成Jar包的方式,這里我打成的Jar包名字為SparkOnHiveToEs_PROD.jar;
??將SparkOnHiveToEs_PROD.jar上傳到hdfs的/app/hive_to_es/etl_jar/SparkOnHiveToEs_PROD.jar路徑下,然后寫一個spark-submit呼叫的shell腳本spark_on_hive_and_es.sh,具體如下:
#!/bin/bash
cur_dir=`pwd`
spark-submit --master yarn --deploy-mode cluster --executor-memory 8G --executor-cores 5 --num-executors 4 --queue etl --conf spark.kryoserializer.buffer.max=256m --conf spark.kryoserializer.buffer=64m --class cn.focusmedia.esapp.App hdfs://my-cluster/app/hive_to_es/etl_jar/SparkOnHiveToEs_PROD.jar hdfs://my-cluster/app/hive_to_es/configure/dw_ads_resource_amap_city_district.xml
dq_check_flag=$?
if [ $dq_check_flag -eq 0 ];then
echo "city and district frome hive to es has successed!"
else
echo "city and district frome hive to es has failed!"
# cd ${cur_dir}/../src/ding_talk_warning_report_py/main/
# python3 ding_talk_with_agency.py 411 此處為報錯后釘釘報警,可以參考博主python欄的釘釘報警的實作
exit 3
fi
調度shell腳本
??最后就是將這個spark_on_hive_and_es.sh腳本調度起來,如用Azkaban調度,設定自己需求的調度頻率;
總 結
??采用Spark將Hive表的資料寫入ElasticSearch,速度較快,可以作為離線資料從資料倉庫Hive寫入ElasticSearch的首席參考方案,穩定,無縫連接,且快速;至于丟失的一環,如何校驗Hive的資料是否準確的通過Spark寫入了ES,請參考本文的目錄的文章3;
??如此一來,新增一張表,只需要填寫一個xml檔案,非常方便,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/437987.html
標籤:其他
上一篇:Flink HA模式環境搭建