緒論
資料結構的基本概念
資料:資料是資訊的載體,計算機程式加工的原料
資料元素:資料的基本單位,若干資料項組成,資料項是資料元素的不可分割的最小單位
資料物件:具有相同性質的資料元素的集合,資料的子集
資料型別
原子型別:其值不可再分的資料型別
結構型別:可以再分解為若干成分的資料型別
抽象資料型別:抽象資料組織及與之相關的操作
資料結構:相互之間存在一種或多種特定關系的資料元素的集合
資料結構三要素
【1】資料的邏輯結構:資料之間的邏輯關系,分為線性結構和非線性結構
【2】資料的存盤結構
| 順序存盤 |
邏輯上相鄰的元素存盤在物理位置上也相鄰的存盤單元中 |
|
優點:實作隨機存取,每個元素占用最少的存盤空間 |
|
|
缺點:只能使用相鄰的一整塊存盤單元,可能產生較多的外部碎片 |
|
| 鏈式存盤 |
借助指示元素存盤地址的指標來表示元素之間的邏輯關系 |
|
優點:不會出現碎片現象,充分利用所有存盤單元 |
|
|
缺點:占用額外的存盤空間,且只能實作順序存盤 |
|
| 索引存盤 |
存盤資訊的同時,建立附加的索引表,索引表中的每項稱為索引項 |
|
優點:檢索速度快 |
|
|
缺點:索引表占用了額外的存盤空間,增加洗掉資料要修改索引表,花費較多的時間 |
|
| 散列存盤 |
根據元素的關鍵字直接計算元素存盤地址 |
|
優點:檢索、增加洗掉節點操作快 |
|
|
缺點:散列函式要求較高,容易出現存盤單元沖突 |
【3】資料的運算:施加在資料上的運算包括運算的定義和實作
演算法和演算法評價
演算法的基本概念
|
概念 |
對特定問題求解步驟的一種描述 |
| 特性 |
有窮性:一個演算法必須總在執行有窮步之后結束,且每一 步 都可在有窮時間內完成 |
|
確定性:演算法中每條指令必須有確切的含義,對于相同的輸入只能得出相同的輸出, |
|
|
可行性:演算法中描述的操作都可以通過已經實作的基本運算執行有限次來實作, |
|
|
輸入:一個演算法有零個或多個輸入,這些輸入取自于某個特定的物件的集合, |
|
|
輸出:一個演算法有一個或多個輸出,這些輸出是與輸入有著某種特定關系的量, |
|
| 評價標準 |
正確性,演算法應能夠正確地解決求解問題, |
|
可讀性,演算法應具有良好的可讀性,以幫助人們理解, |
|
|
健壯性,輸入非法資料時,演算法能適當地做出反應或進行處理,而不會產生莫名其妙的輸出結果, |
|
|
效率與低存盤量需求,效率是指演算法執行的時間,存盤量需求是指演算法執行程序中所需要的最大存盤空間,這兩者都與問題的規模有關, |
演算法效率的度量
|
時間復雜度 |
一個陳述句的頻度是指該陳述句在演算法中被重復執行的次數 所有陳述句的頻度只和記為T(n)
演算法中基本運算【最深層循壞內的陳述句】的頻度與T(n)同數量級
演算法中基本運算的頻度f(n)來分析演算法的時間復雜度
演算法的時間復雜度不僅依賴于問題的規模,也取決于待輸入資料的性質
最壞時間復雜度是指在最壞情況下,演算法的時間復雜度, 平均時間復雜度是指所有可能輸入實體在等概率出現的情況下,演算法的期望運行時間, 最好時間復雜度是指在最好情況下,演算法的時間復雜度, 一般總是考慮在最壞情況下的時間復雜度,以保證演算法的運行時間不會比它更長,
|
|
空間復雜度 |
S(n)演算法所耗費的存盤空間 一個程式在執行時除需要存盤空間來存放本身所用的指令、常數、變數和輸入資料外 還需要一些對資料進行操作的作業單元和資料一些為實作計算所需資訊的輔助空間 |
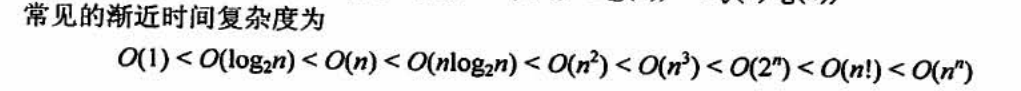
線性表
線性表的定義和基本操作
| 定義 | |
| 特點 | |
| 基本操作 |
線性表的順序表示
線性表的鏈式表示
堆疊和佇列
堆疊
佇列
堆疊和佇列的應用
特殊矩陣的壓縮存盤
串
串的定義的實作
串的模式匹配
樹與二叉樹
樹的基本概念
二叉樹的概念
二叉樹的遍歷和線索二叉樹
樹、森林
樹與二叉樹的應用
圖
圖的基本概念
圖的存盤及基本操作
圖的遍歷
圖的應用
查找
查找的基本概念
順序查找和折半查找
B樹和B+樹
散串列
排序
排序的基本概念
插入排序
交換排序
選擇排序
歸并排序和基數排序
各種內部排序演算法的比較及
外部排序
在黑夜里夢想著光,心中覆寫悲傷,在悲傷里忍受孤獨,空守一絲溫暖, 我的淚水是無底深海,對你的愛已無言,相信無盡的力量,那是真愛永在, 我的信仰是無底深海,澎湃著心中火焰,燃燒無盡的力量,那是忠誠永在轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/438021.html
標籤:其他
上一篇:計算機網路復習筆記(部分)
下一篇:python選擇排序