一, MySQl 8.0 視窗函式
視窗函式適用場景:
對分組統計結果中的每一條記錄進行計算的場景下, 使用視窗函式更好, 注意, 是每一條!! 因為MySQL的普通聚合函式的結果(如 group by)是每一組只有一條記錄!!!
可以跟Hive的對比著看: 點我, 特么的花了一晚上整理, 沒想到跟Hive 的基本一致, 還不因為好久沒復習博客了, 淦
注意:
mysql 因為沒有array資料結構, 無法像Hive一樣 行列進行轉換;
1.1 視窗函式分類
- MySQL從8.0版本開始支持視窗函式,視窗函式的作用類似于
在查詢中對資料進行分組,不同的是,分組操作會把分組的結果聚合成一條記錄,而視窗函式是將分組的結果置于每一條資料記錄中, - 視窗函式可以分為
靜態視窗函式和動態視窗函式- 靜態視窗函式的視窗大小是固定的, 不會因為記錄的不同而不同;
- 動態視窗函式的視窗大小會隨著記錄的不同而變化;
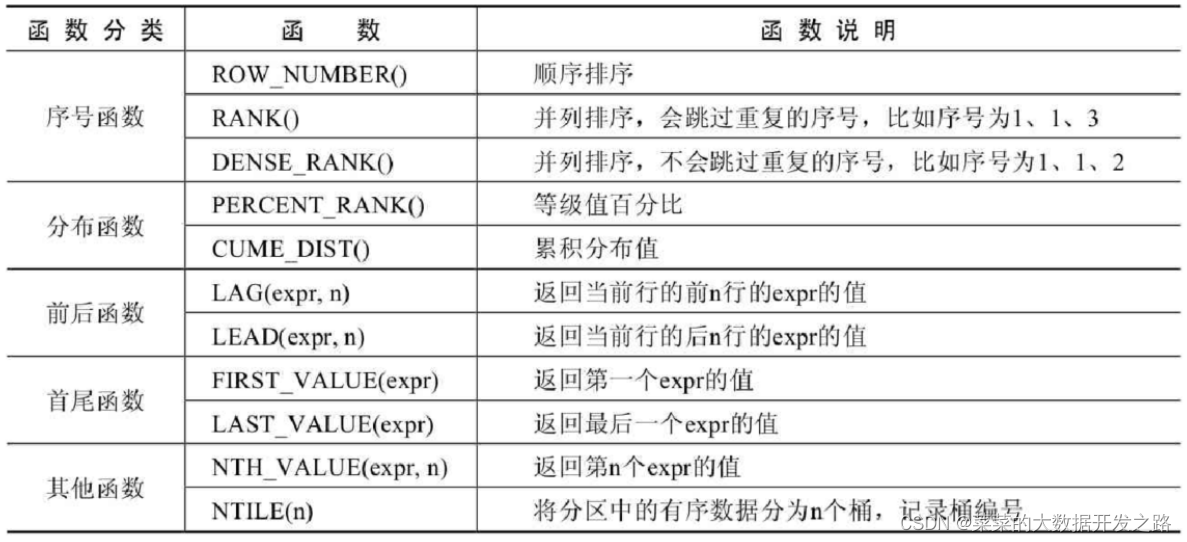
視窗函式總體上可以分為序號函式, 分布函式, 前后函式, 首尾函式和其他函式;
1.2 語法結構
- 視窗函式的語法結構:
- 函式 OVER ([PARTITION BY 欄位名 ORDER BY 欄位名 ASC|DESC])
- 或者是 函式 OVER 視窗名 … WInDOW 視窗名 AS ([PARTITION BY 欄位名 ORDER BY 欄位名 ASC|DESC])
OVER 關鍵字指定視窗的范圍;
- 如果省略后面括號中的內容,則視窗會包含滿足WHERE條件的所有記錄,視窗函式會基于所有滿足WHERE條件的記錄進行計算,
- 如果OVER關鍵字后面的括號不為空,則可以使用如下語法設定視窗,
PARTITION BY 子句: 指定視窗函式按照哪些欄位進行分組,
分組后, 視窗函式可以在每個分組中分別執行;
ORDER BY 子句: 指定視窗函式按照哪些欄位進行排序, 執行排序操作使視窗函式按照排序后的資料記錄的順序進行編號;
FRAME 子句: 為磁區中的某個子集定義規則, 可以用來作為滑動視窗使用;
1.3 視窗函式🌰
準備表和資料:
- 創建表:
CREATE TABLE goods(
id INT PRIMARY KEY AUTO_INCREMENT,
category_id INT,
category VARCHAR(15),
NAME VARCHAR(30),
price DECIMAL(10,2),
stock INT,
upper_time DATETIME
);
- 插入資料:
INSERT INTO goods(category_id,category,NAME,price,stock,upper_time)
VALUES
(1, '女裝/女士精品', 'T恤', 39.90, 1000, '2020-11-10 00:00:00'),
(1, '女裝/女士精品', '連衣裙', 79.90, 2500, '2020-11-10 00:00:00'),
(1, '女裝/女士精品', '衛衣', 89.90, 1500, '2020-11-10 00:00:00'),
(1, '女裝/女士精品', '牛仔褲', 89.90, 3500, '2020-11-10 00:00:00'),
(1, '女裝/女士精品', '百褶裙', 29.90, 500, '2020-11-10 00:00:00'),
(1, '女裝/女士精品', '呢絨外套', 399.90, 1200, '2020-11-10 00:00:00'),
(2, '戶外運動', '自行車', 399.90, 1000, '2020-11-10 00:00:00'),
(2, '戶外運動', '山地自行車', 1399.90, 2500, '2020-11-10 00:00:00'),
(2, '戶外運動', '登山杖', 59.90, 1500, '2020-11-10 00:00:00'),
(2, '戶外運動', '騎行裝備', 399.90, 3500, '2020-11-10 00:00:00'),
(2, '戶外運動', '運動外套', 799.90, 500, '2020-11-10 00:00:00'),
(2, '戶外運動', '滑板', 499.90, 1200, '2020-11-10 00:00:00');
下面針對goods表中的資料來驗證每個視窗函式的功能,
1. 序號函式
序號函式是按照一定的分組規則對每一組的資料排序并創建一個序號列
1.1 row_number() - 單純的對每一組資料編號
| 函式 | 功能 |
|---|---|
| row_number() | 對資料中的序號進行順序顯示 |
[案例]
1.1 查詢 goods 資料表中每個商品分類下價格降序排列的各個商品資訊,
SELECT
*,
ROW_NUMBER() OVER (PARTITION BY category ORDER BY price DESC) AS row_num
FROM goods;
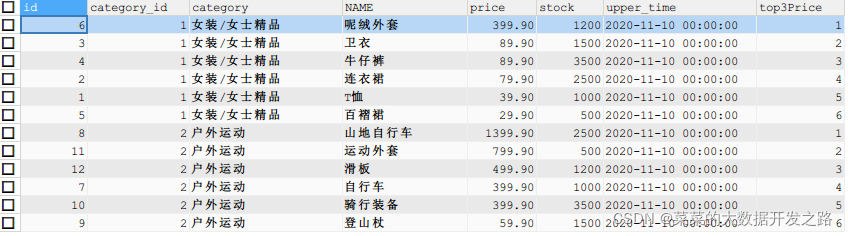
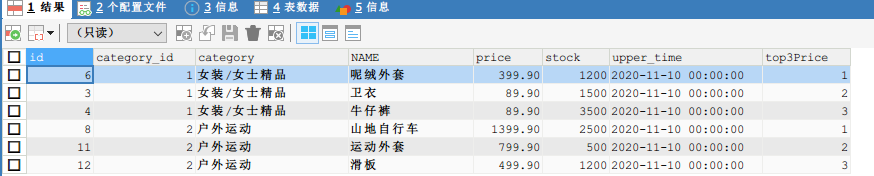
1.2 查詢 goods 資料表中每個商品分類下價格最高的3種商品資訊,
SELECT
*
FROM
(
SELECT
*,
ROW_NUMBER() OVER (PARTITION BY category ORDER BY price DESC) AS top3Price
FROM goods
) AS t
WHERE
top3Price <= 3
在名稱為“女裝/女士精品”的商品類別中,有兩款商品的價格為89.90元,分別是衛衣和牛仔褲,兩款商品的序號都應該為2,而不是一個為2,另一個為3,此時,可以使用RANK()函式和DENSE_RANK()函式解決;
1.2 rank() - 排序每一組的某一欄位, 同等級同序號前后不連續
| 函式 | 功能 |
|---|---|
| rank() | 對序號進行并列排序, 指定欄位數值相同(同一等級),則會產生相同序號記錄,且產生序號間隙, |
| 如, 1,1,3,4 而不會是 1,2,3,4(row_number的結果), 也不是 1,1,2,3,4 (dense_rank的結果) | |
rank函式沒有引數,但需要指定按照那個欄位進行排名,所以使用rank函式必須用order by引數,order by的排序欄位就是排名欄位 |
1.3
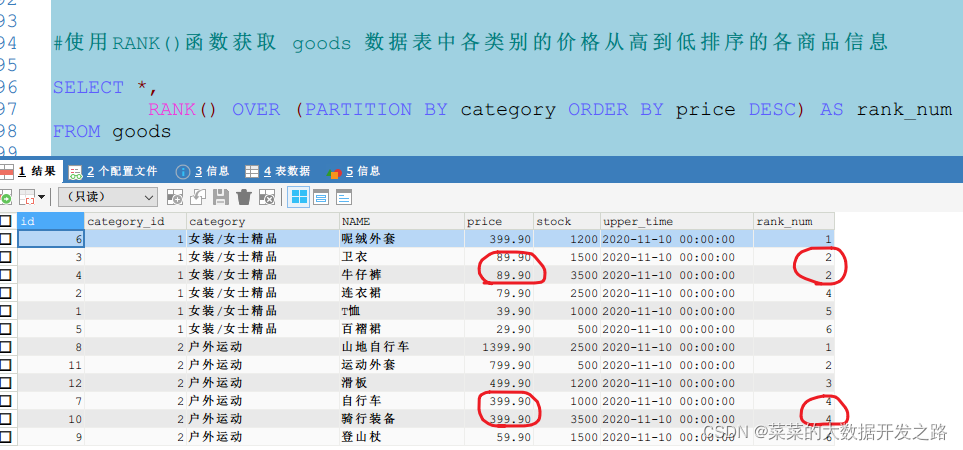
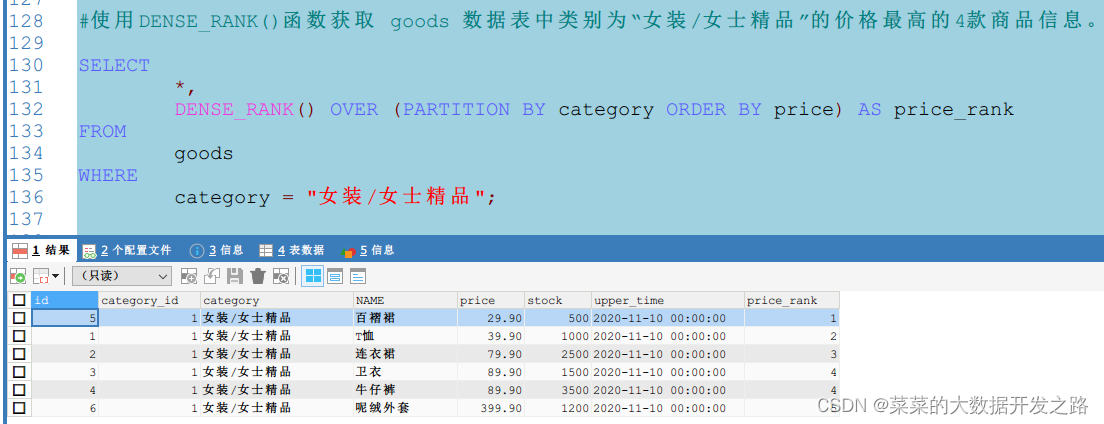
1.4 使用RANK()函式獲取 goods 資料表中類別為“女裝/女士精品”的價格最高的4款商品資訊,
// 常規思路
SELECT *
FROM goods
WHERE category = '女裝/女士精品'
ORDER BY price DESC
LIMIT 4
#視窗函式rank: 并列
SELECT
*,
RANK() OVER (PARTITION BY category ORDER BY price DESC) AS top4Price
FROM
goods
WHERE
category = '女裝/女士精品'
LIMIT 4;

1.3 dense_rank() - 排序每一組的某一欄位, 同等級同序號前后也連續
| 函式 | 功能 |
|---|---|
| dense_rank() | 對序號進行并列排序, 指定欄位數值相同(同一等級),則會產生相同序號記錄,且產生序號間隙, |
1.5
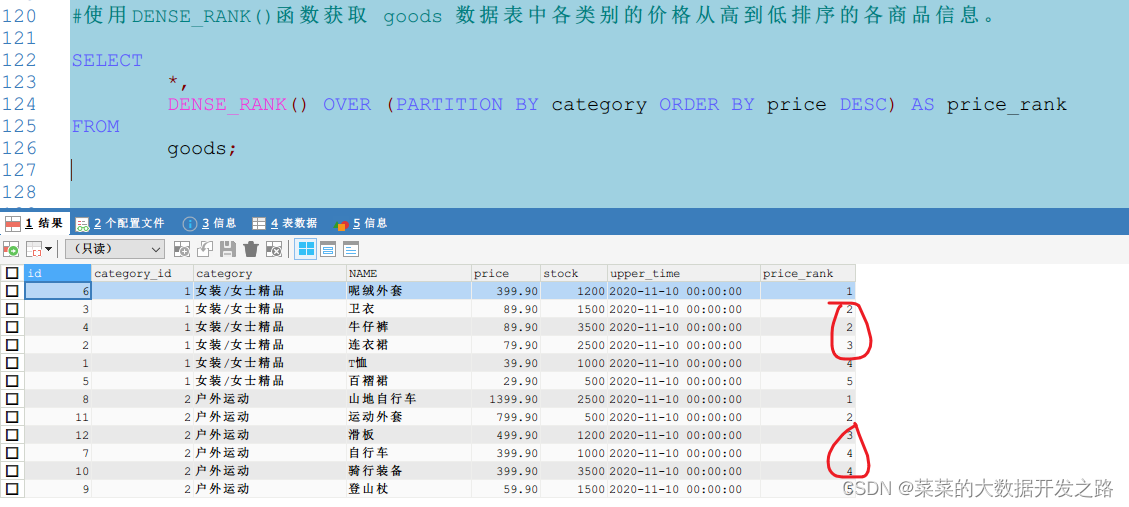
1.6
可以看到,使用DENSE_RANK()函式得出的行號為1、2、2、3,相同價格的商品序號相同,且后面的商品序號是連續的
2. 分布函式
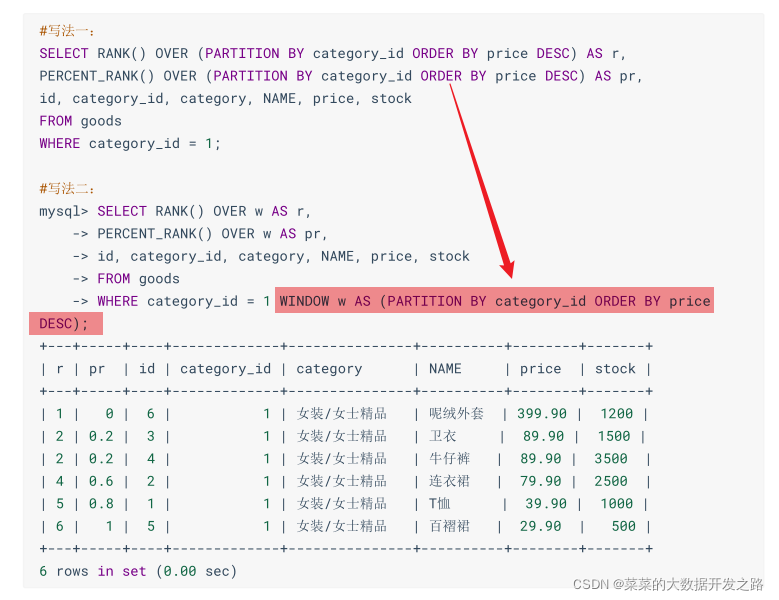
2.1 percent_rank() - 等級值百分比, (rank - 1)/ (rows - 1)
| 函式 | 功能 |
|---|---|
| percent_rank() | 計算磁區或結果集中行的百分位數排名 |
每行按照公式(rank-1)/ (rows-1)進行計算,其中,rank為RANK()函式產生的序號,rows為當前視窗(當前組)的總行數 |
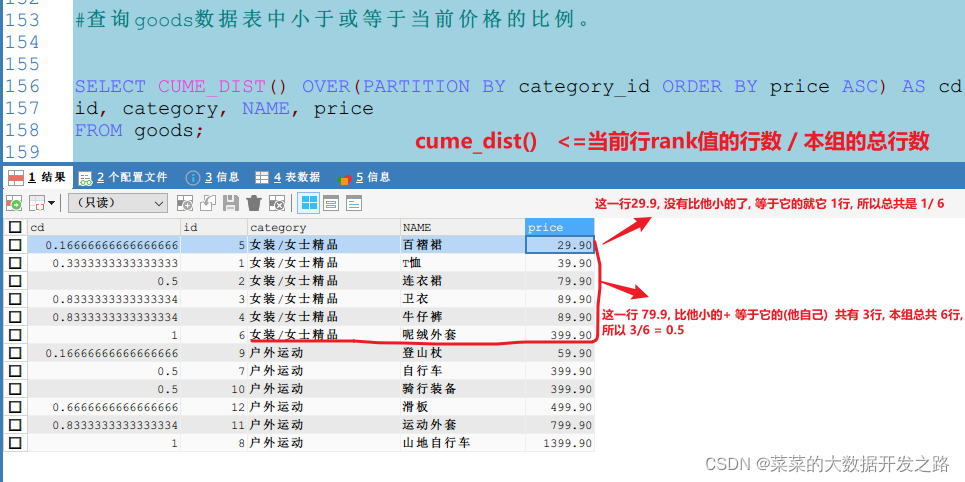
2.2 cume_dist() - 累積分布值, <=當前rank值的行數 / 分組內總行數
| 函式 | 功能 |
|---|---|
| cume_dist() | 分組內<=當前rank值的行數 / 分組內總行數 |
3. 前后函式
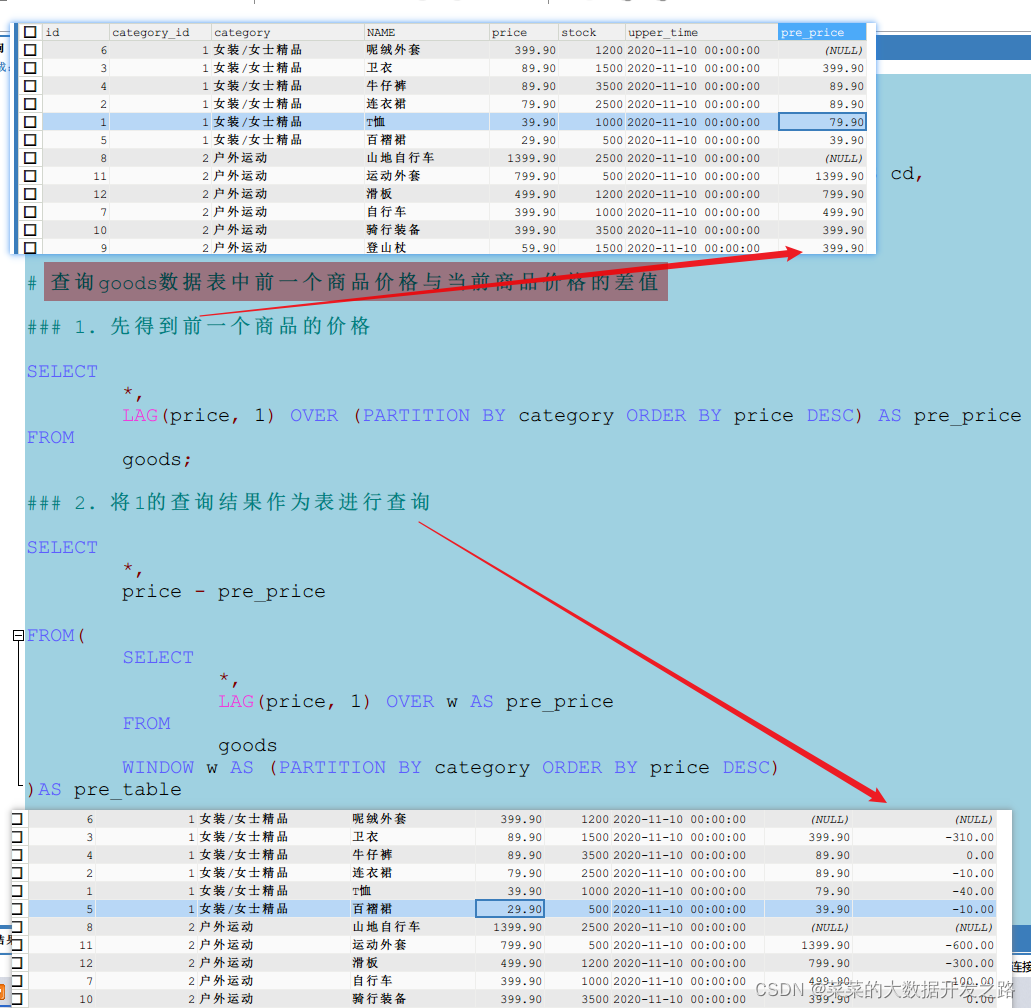
3.1 LAG(expr, n) - 回傳當前行的前n行(本組內)的expr值
| 函式 | 功能 |
|---|---|
| LAG(expr, n) | 回傳當前行的前n行(本組)的expr值 |
| lag允許你在每一個分組內, 從當前行向前看n行資料 | |
| n(也叫offset)是從當前行偏移的行數,以獲取值,offset必須是一個非負整數,如果offset為零,則LAG()函式計算當前行的值,如果省略 offset,則LAG()函式默認使用n=1, 向前看一個資料, |
3.2 LEAD(expr, n)
| 函式 | 功能 |
|---|---|
| LEAD(expr, n) | 回傳當前行的后n行(本組)的expr值 |

4. 首位函式
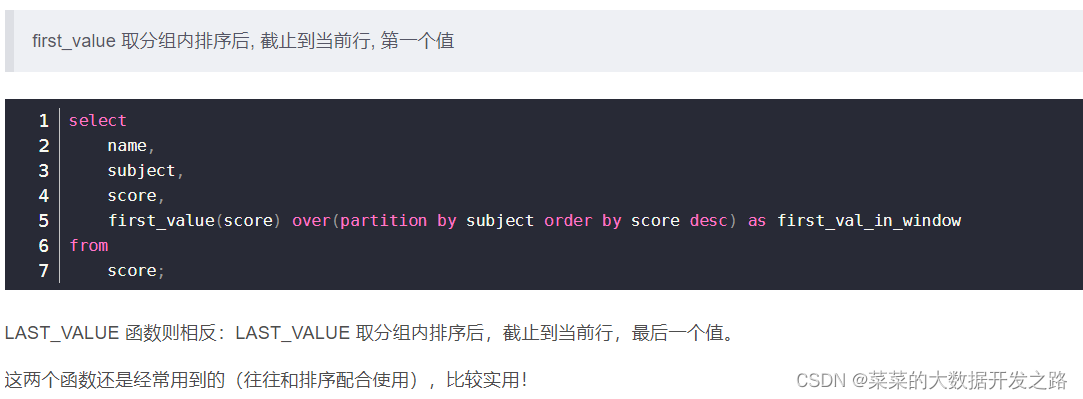
4.1 first_value(expr) , last_value(expr)
5. 其他函式
5.1 nth_value(expr, n)

5.2 ntile(n)

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/438091.html
標籤:其他