作者:JanieLiu
公眾號《溜溜筆記說》
本文針對性的講講資料分析整個流程最關鍵的階段: 資料處理與分析階段,該階段我分成了三塊:資料采集、資料處理、資料分析,都圍繞著“資料”進行,對海量或雜亂資料進行處理分析,從中找出痛點,洞察問題,
一、資料采集
該處的資料采集指的是獲取分析所需要的資料,一般可以從內部資料、外部資料兩個方向獲取,
1. 內部資料
- 直接獲取
直接獲取的前提是,公司進行了資料倉庫的建設,已為決策分析提供了所有型別資料支持,該部分內容在之前的文章中也提到過,但是在這里更加細化的做了點補充,
直接獲取就是指資料庫中有現成的表可以直接獲取到所需的資料,不需要分析師再在sql上做復雜的處理,
公司一般會將資料分為ods、dwd、dwb/dws層資料,
① ods層:明細資料,數倉不做任何資料處理,直接原封不動的將資料同步到該庫上,為dw層的資料加作業準備,
②dwd層:明細資料,該層資料已在ods層上對資料做了清洗操作,比如去除空值、臟資料等,
③dwb/dws層:聚合資料,主要對ods/dwd層的資料做些輕度匯總,會涉及較多業務指標資料,如根據ods/dwd層的明細資料計算出七日復購率、周同期對比資料、毛利率等指標供分析師直接查詢使用,
一般情況下,分析可以直接從dwb/dws層調取現成的指標資料進行分析,特殊情況下也可以從dwd層寫復雜sql的方式計算成所需的資料,
- 重新落表獲取
前提是dwb/dws層沒有現成的資料可以直接獲取,哪怕自己寫代碼可以從dwd層獲取,也需要寫很復雜的代碼,此時,請數倉協助落成聚合表再去調取資料,
重新落表一般會涉及人力資源的協調,需求的溝通,分析師擔當業務方和數倉之間的橋梁,將業務方的需求理清楚之后,自身又作為數倉的需求方對數倉提需求,
2. 外部資料
當分析的內容內部資料無法滿足時,或者不夠全面時,此時需要借助于外部資料來輔助分析,
- 行業報告資料
比如艾瑞網、極光大資料、阿里研究所、199IT互聯網資料中心等都會時不時的發一些行業分析報告,整個行業的資料公司內部是無法獲取的,所以可以從一些行業分析報告入手,
- 問卷采集
比如我們需要獲取用戶的一些①主觀想法:喜歡我們產品的原因是?我們產品最吸引您的點是?您覺得我們產品最應該改進的點是?②對競品的行為:您在xx場景下更愿意使用A產品、B產品還是C產品③用戶習慣的場景:您在什么場景下更愿意使用xx產品?等
通過問卷資料獲取一些產品中無法獲得的資料,輔助分析,
- 宏觀資料
有時候我們分析的某個指標有時候也會受到宏觀政策的影響,比如宏觀上某項指標上調了xx,對我們的業務會產生怎樣的影響,
二、資料處理
對分析師而言,這步需要分析師將資料根據腦中的分析框架處理成所需要的資料,
1. 處理內容
會涉及資料例外值處理、缺失值處理、資料轉換、資料聚合、資料分組歸類以及資料準確性的校驗,為下一步的資料分析奠定好基礎,
井井有條的資料更有利于分析:
- 剔除無效資料,比如例外值、缺失值、重復值等,
- 考慮清楚資料聚合的維度,比如時間上、地域上、用戶上、商品上等按照什么維度聚合,
- 做好資料聚合的處理,比如需要借助開窗函式,是否需要去重計數,是否需要累積計數等;
2. 資料驗證
資料采集到之后,還要做好資料驗證,目的是確保資料準確性,切忌拿到資料立馬動手分析,
- 從驗證人員來看
自身多方驗證:初始先自身驗證一番,與現有報表中已有資料進行對比,觀察是否一致,
與需求方協同驗證:資料調取之后先出一份資料表,提供給需求方共同驗證,不過分析師接了需求,保證資料準確性是基本要素,一般情況下需求方并不會協同驗證,前提是,無現有資料可供對比查驗,可將資料先提供給需求方過一眼,確保資料準確無誤,
- 從驗證方式來看
定性驗證:通過經驗或邏輯推理,主觀判斷該資料是否符合經驗或正常邏輯,比如你取到的某個商品的gmv比整個品類的gmv還要大,就不符合正常邏輯,肯定有誤,
定量驗證:依據統計方式,計算出具體的指標,多方交叉驗證,
三、資料分析-七大分析方法
資料分析方法很多,網上有很多資料,這里就講一下其中比較常用的幾種分析方法,
1.關聯規則分析
關聯規則分析其實就是購物籃分析,就是通過挖掘用戶的消費行為資料,探索用戶的消費習慣,從而合理搭配商品,提升收益,
舉個簡單的例子,近30天共產生了10筆訂單(方便計算只虛構了10筆),1代表訂單中包含該商品,0代表訂單中未包含商品,比如111112訂單,用戶沒有買蘋果,但買了香蕉(是否買了其他商品不考慮),
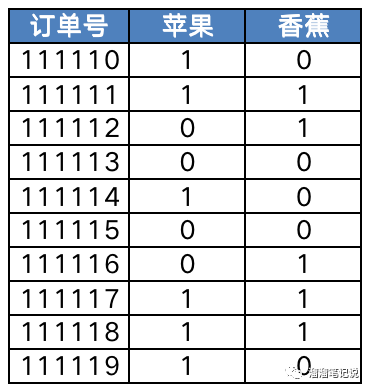
其中購買了蘋果的訂單有6筆,購買了香蕉的有5筆,同時購買了蘋果和香蕉的有3筆,
則:
①蘋果和香蕉組合的支持度
=同時購買了蘋果和香蕉的訂單數/總訂單數*100%
=3/10*100%
=30%
含義:同時購買蘋果和香蕉的概率有多大
②蘋果對香蕉的置信度
=同時購買了蘋果和香蕉的訂單數/購買了蘋果的訂單數*100%
=3/6*100%
=50%
含義:購買了蘋果的用戶有多大概率會再買香蕉
③蘋果對香蕉的提升度
=蘋果對香蕉的置信度/購買香蕉的概率
=50%/(5/10)
=1
含義:購買蘋果對購買香蕉會產生正向影響還是負向影響還是無影響
此案例中計算的提升度是1,表示購買蘋果并不會對購買香蕉產生任何影響,
詳細解釋下:
若提升度=1:表示購買蘋果并不會對購買香蕉產生任何影響,因為在購買了蘋果的條件下去買香蕉的概率和直接買香蕉的概率是一樣的;
若提升度>1:表示購買蘋果對購買香蕉產生了正向影響,即購買蘋果很大可能也會買香蕉,因為在購買了蘋果的條件下去買香蕉的概率大于直接買香蕉的概率;
若提升度<1:表示購買蘋果對購買香蕉產生了負向影響,即購買蘋果很大可能就不會買香蕉,因為在購買了蘋果的條件下去買香蕉的概率小于直接買香蕉的概率;
這就是關聯規則分析,一般用以研究探索商品捆綁銷售,比如蘋果是否需要和香蕉在一起捆綁銷售,捆綁銷售收益是否會更大,
2. RFM模型
RFM模型主要用來衡量用戶價值,做用戶分群,比如區分出低價值用戶、高價值用戶、忠誠用戶等用戶群體,
R:用戶最近一次消費距今時間(Recency)
F:用戶在最近時間段內的消費頻次(Frequency)
M:用戶在最近時間段內的消費金額(Monetary)
這里用一個比較簡單的例子講下:
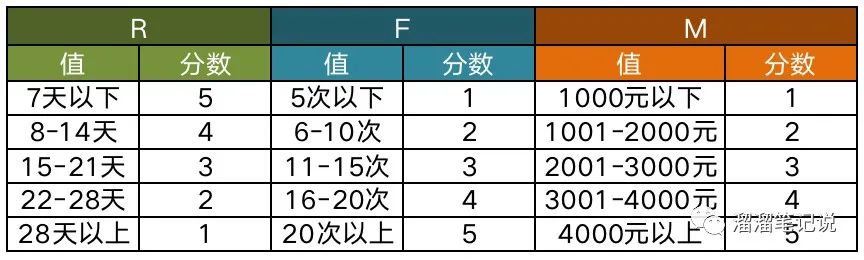
先對R、F、M三個值進行分層并賦予權重(以下資料純屬虛構,分層時根據實際情況),
比如用戶最近一次消費距今時間7天以下的打為5分,8-14天的打為4分……以此類推,分數高的表示價值性比較高,分數低的表示價值性比較低,
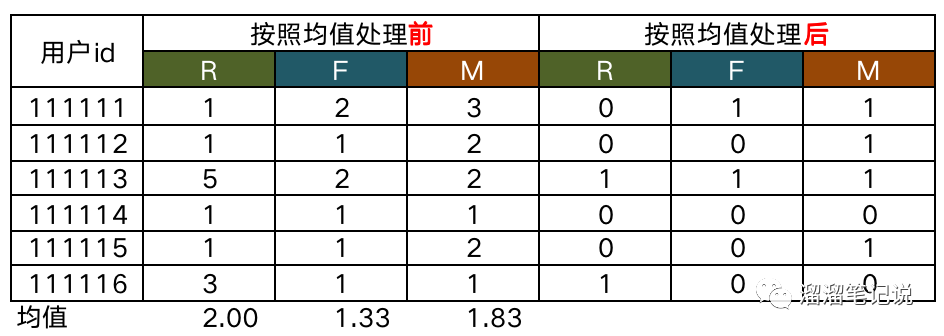
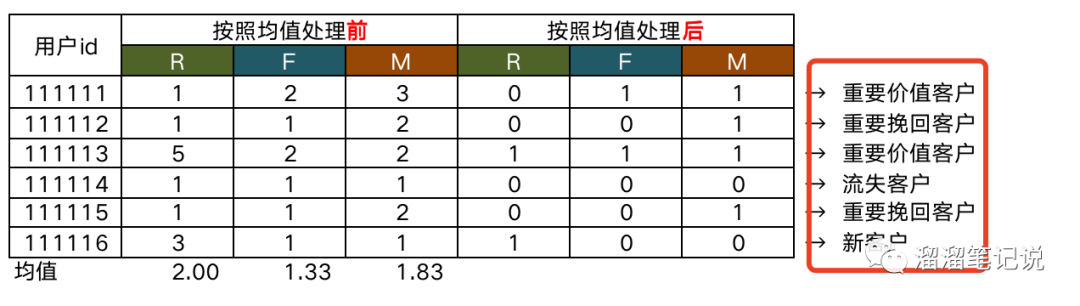
然后調取出每個用戶R、F、M值,填入“按照均值處理前”列中,
比如下圖中,用戶“111113”最近一次消費距今時間在7天以下,則R為5,在最近時間段內的消費頻次在6-10之間,則F為2,在最近時間段內的消費金額在1001-2000之間,則M為2,
再將每個用戶的R、F、M值與均值對比,大于均值填充1,小于均值填充0,填充于”按照均值處理后“列中,
最后將“按照均值處理后”的資料參照下圖模型表(下圖不是計算出來的,是比較常用的標準),匹配出用戶型別,
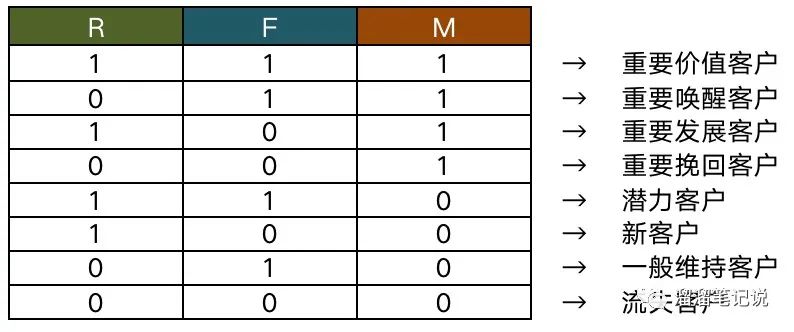
給用戶匹配之后的用戶價值型別如下
3.帕累托分析
帕累托分析就是“二八法則”,
“二八法則”認為80%的財富掌握在20%的人手里,應用到業務中就是,80%的營收在20%的產品里,同理,我們應該花80%的時間內在這20%的產品上,也就是說,寶貴的時間與資源應該用在刀刃上,
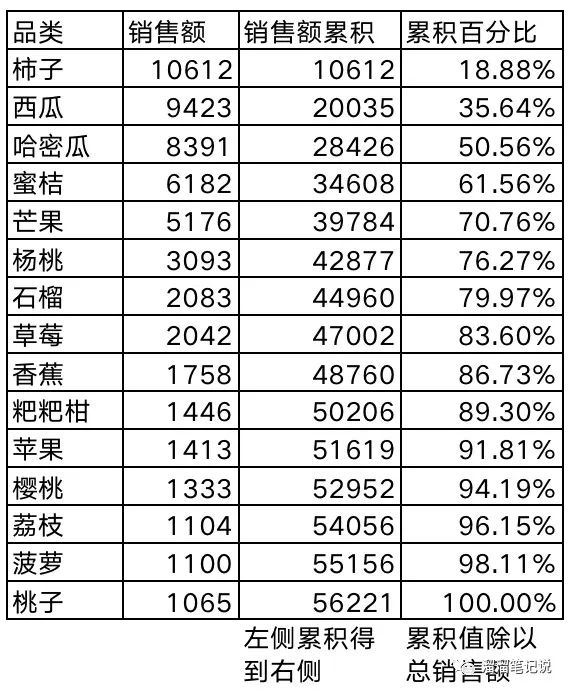
如下圖:展示了每個品類的銷售額,通過銷售額計算出銷售額累積值,進而算出累積百分比,
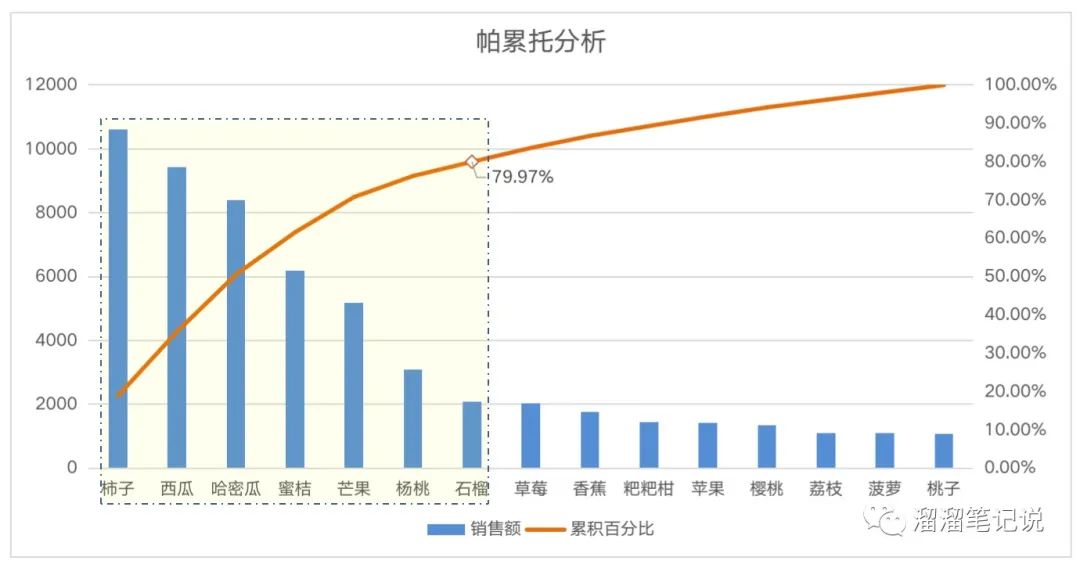
再通過銷售額和累積百分比畫出帕累托圖,如下,
共15種品類,其中7個品類貢獻了80%的銷售額,占比46.67%,也就是說46.67%的商品為公司帶來了80%的銷售額,并不符合二八定律,該公司并沒有強勢產品,
4. 用戶生命周期價值分析
用戶生命周期總價值,主要用于衡量用戶對產品產生的價值,
以一個案例講解如下:
下圖是一張留存率圖
以2021.12.01——2021.12.07之間的七天留存率來預估14日留存、30日留存等,
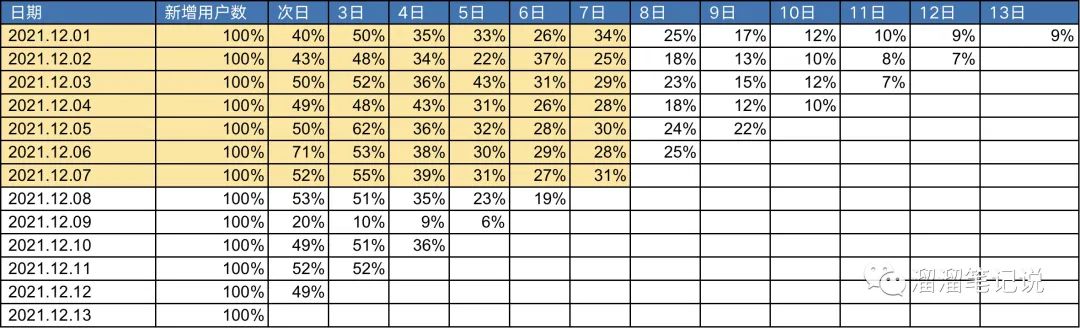
先將黃色部分的七天的留存率取均值,得到圖上最下方的留存平均值,
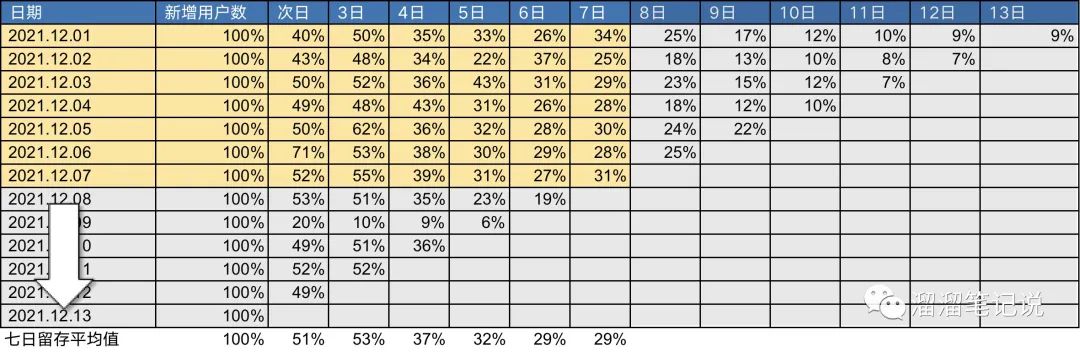
然后按照留存率的均值做擬合,擬合后的結果如下圖所示,
選擇冪函式擬合,因為冪函式擬合的R方接近于1,擬合效果較好,
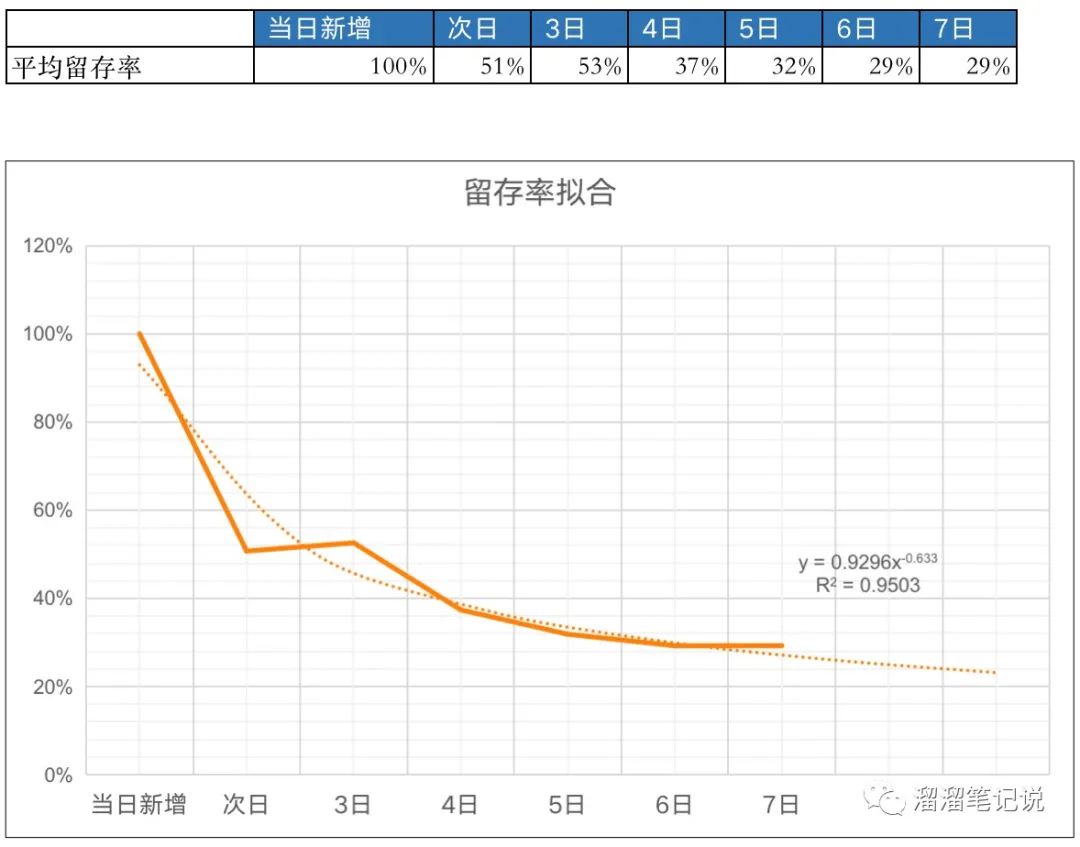
則LT14=100%+51%+53%+37%+32%+29%+29%+25%+23%+22%+20%+19%+18%+17%
=4.75天

LT已經算出來了,那么下一步就是計算ARPU了,ARPU值直接取日均值就可以了,假如ARPU日均值是¥60,則LTV=4.75*12=285
即用戶14天的平均生命周期是4.75天,用戶在該生命周期內能帶來的總價值為¥285
延伸下,如果想知道花費在這批用戶身上的成本需要多久才可以回本,怎么計算呢?這就涉及到了回本周期預估,
比如在前面已經預估了LTV14為¥285,假如已知該渠道的CAC是¥30,
則預估的回本周期是=285/30=9.5天
即投入在該群用戶身上的成本需要9.5天方可回本,
5. 漏斗分析
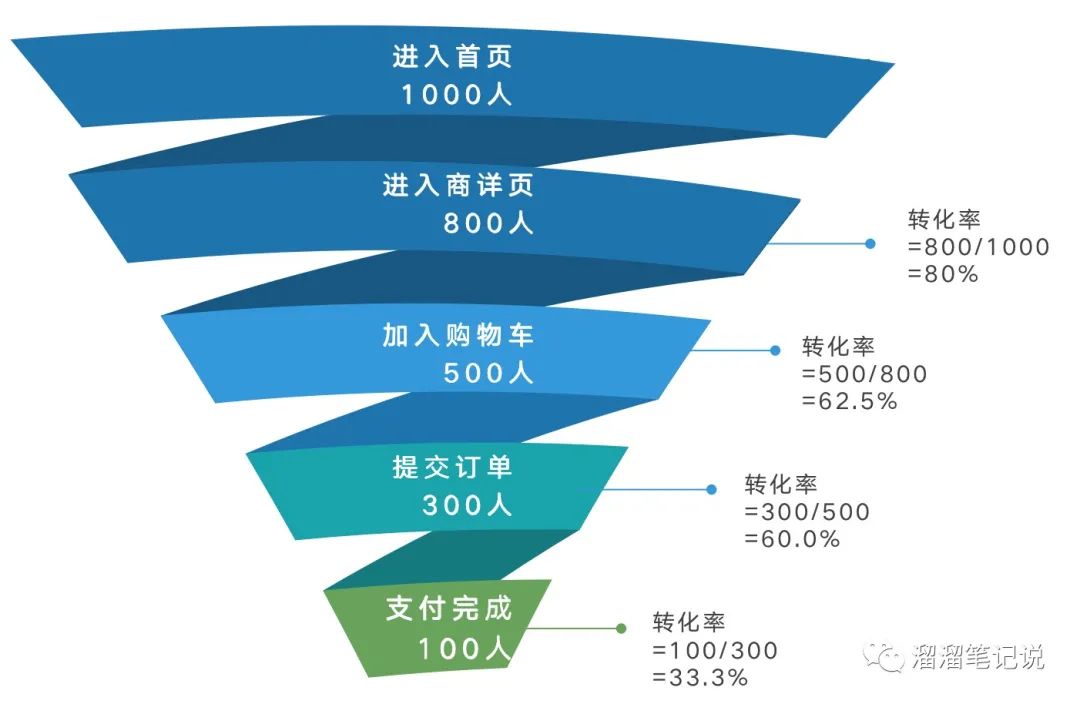
漏斗分析是資料分析中比較常見的分析模型,采取漏斗的方式直觀的表示業務從起點到終點的各個環節的轉化情況,以便找出有問題的環節,針對性的優化,
如下圖,展示了用戶支付場景的轉化率:用戶從打開app到完成支付的程序,分為進入首頁→進入商詳頁→加入購物車→提交訂單→支付完成,直觀分析每個重要環節的轉化率,以最直觀最簡單的方式反映出每個關鍵環節的轉化率,洞察主要問題所在,
6.波士頓矩陣
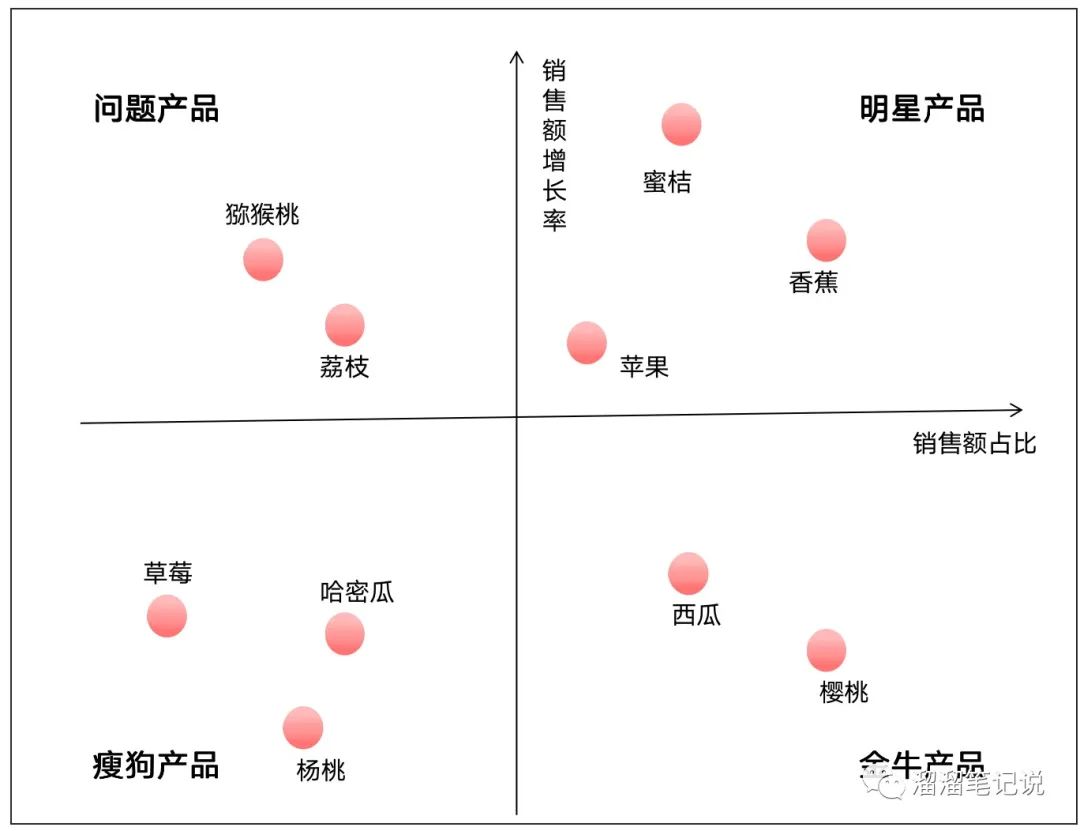
波士頓矩陣不少人在大學期間學過,作業中也是比較實用的,可通過波士頓矩陣分析公司的產品結構,發現痛點,為是否需要及時調整戰略目標,以及判斷產品的資源分配是否合理提供了資料支持,
波士頓矩陣有以下4種結構型別:
明星產品:成長期,該產品在市場上占有比較大的份額,且處于高速增長階段,未來發展為金牛產品的可能性比較大,此時抓住機會擴大投資,提升競爭優勢,如圖中的蜜桔、香蕉、蘋果,
金牛產品:成熟期,產品已較為成熟,增長前景有限,穩定發展,盡量維持好當前市場份額,如圖中的西瓜、櫻桃,
問題產品:匯入期,高速增長卻市場份額并不高,說明此產品雖然高速增長,但并未及時開拓市場,營銷存在問題,如圖中的獼猴桃、荔枝,
瘦狗產品:衰退期,既市場份額不高,又增速緩慢,基本可以淘汰,將此資源轉而投資給其他更有利的產品,如圖中的草莓、楊桃、哈密瓜,
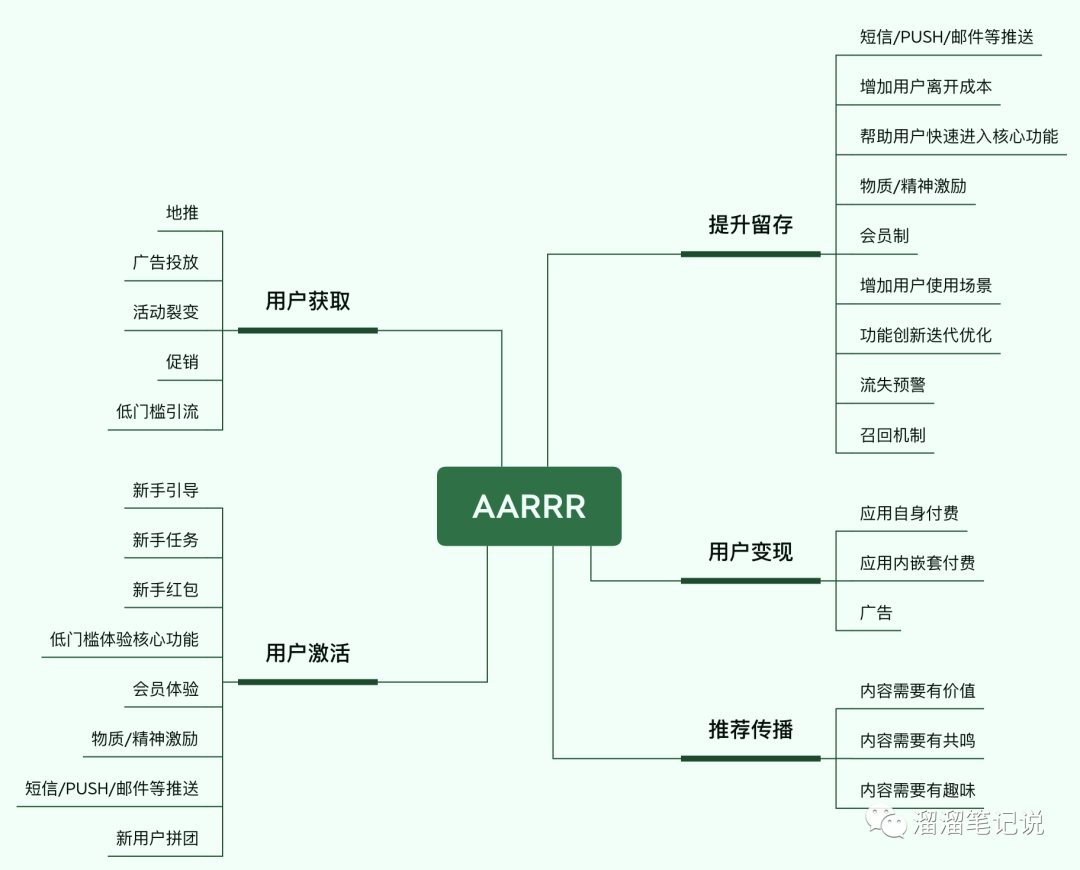
7.AARRR模型
AARRR模型是探索用戶增長的模型,分別對應用戶生命周期的5個環節:用戶獲取、用戶激活、用戶留存、用戶變現、推薦傳播,
結語:
以上就是圍繞著“資料”進行的采集、處理與分析的程序,這個程序起著承上(需求確認)啟下(資料展現)的作用,重要性不言而喻,
資料分析的知識點很廣闊,我寫的這些也只是其中的非常小的一小部分,但經驗與專業性就是從小起步的,一點點積累,一點點成長,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/439233.html
標籤:其他
上一篇:后端開發學習路線
下一篇:zookeeper偽分布環境搭建