首發CSDN:徐同學呀,原創不易,轉載請注明源鏈接,我是徐同學,用心輸出高質量文章,希望對你有所幫助,
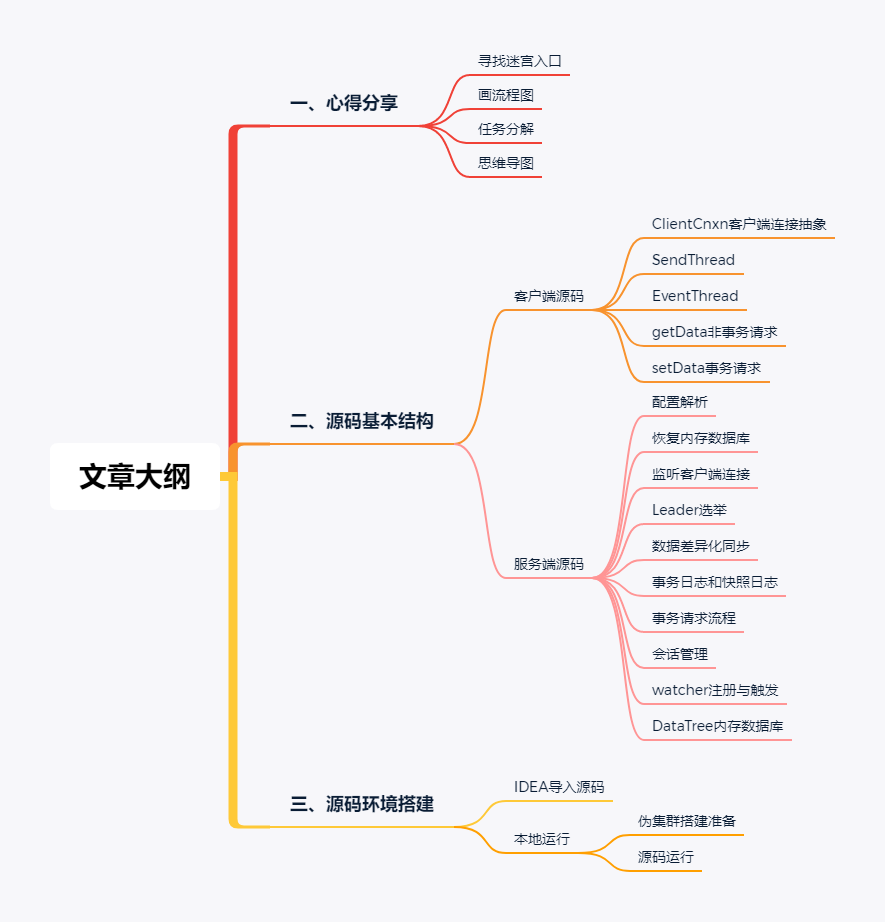
一、心得分享
如何閱讀ZooKeeper原始碼?從哪里開始閱讀?最近把ZooKeeper原始碼看了個大概,有一些心得想和大家分享和探討:
1、尋找迷宮入口
ZooKeeper原始碼的脈絡就像一個迷宮,要想玩這個迷宮游戲,必須找到迷宮的入口,有兩條入口可供選擇:
- 從服務端的啟動流程開始看起,可以了解組態檔
zoo.cfg決議程序和配置項在原始碼中的應用,以及Leader選舉流程等,服務端原始碼比較復雜,在了解服務端啟動和Leader選舉的程序中,又涉及很多其他知識點,包括記憶體資料庫DataTree的原理,日志機制(事務日志和快照日志),資料恢復與同步等,最接近核心,也最難,容易勸退或者舉步維艱, - 從客戶端向服務端建立連接開始看起,可以了解客戶端是如何建立連接、發送請求和處理回應等,相對于服務端,客戶端原始碼要簡單很多,從客戶端開始突破,要順利些,
2、畫流程圖
看原始碼一定要畫流程圖,原始碼走向是錯綜復雜,每個流程、每個走向都畫好流程圖或者時序圖,有助于原理理解,
客戶端原始碼只有兩個執行緒還好說,服務端原始碼有很多執行緒,直接繞暈,比如請求處理,就分為事務請求和非事務請求,事務請求又需要經過兩階段提交,不畫流程圖,根本梳理不清事務請求是如何在Leader和Learner之間流轉的,
3、任務分解
任務拆分,化繁為簡,化整為零,是大家都懂的道理,但是如何拆分并不是一件易事,
Zookeeper原始碼有很多大知識點,攻克大知識點很花時間,有時候會因為太難,而一拖再拖,舉步維艱,將大知識點拆分為一個個小知識點,一步步攻克,拆分的程序不是一步到位,不要糾結于如何拆分,而是先拆起來,進行的程序中不斷拆分,不知不覺一個大的,難的知識點就被攻克了,
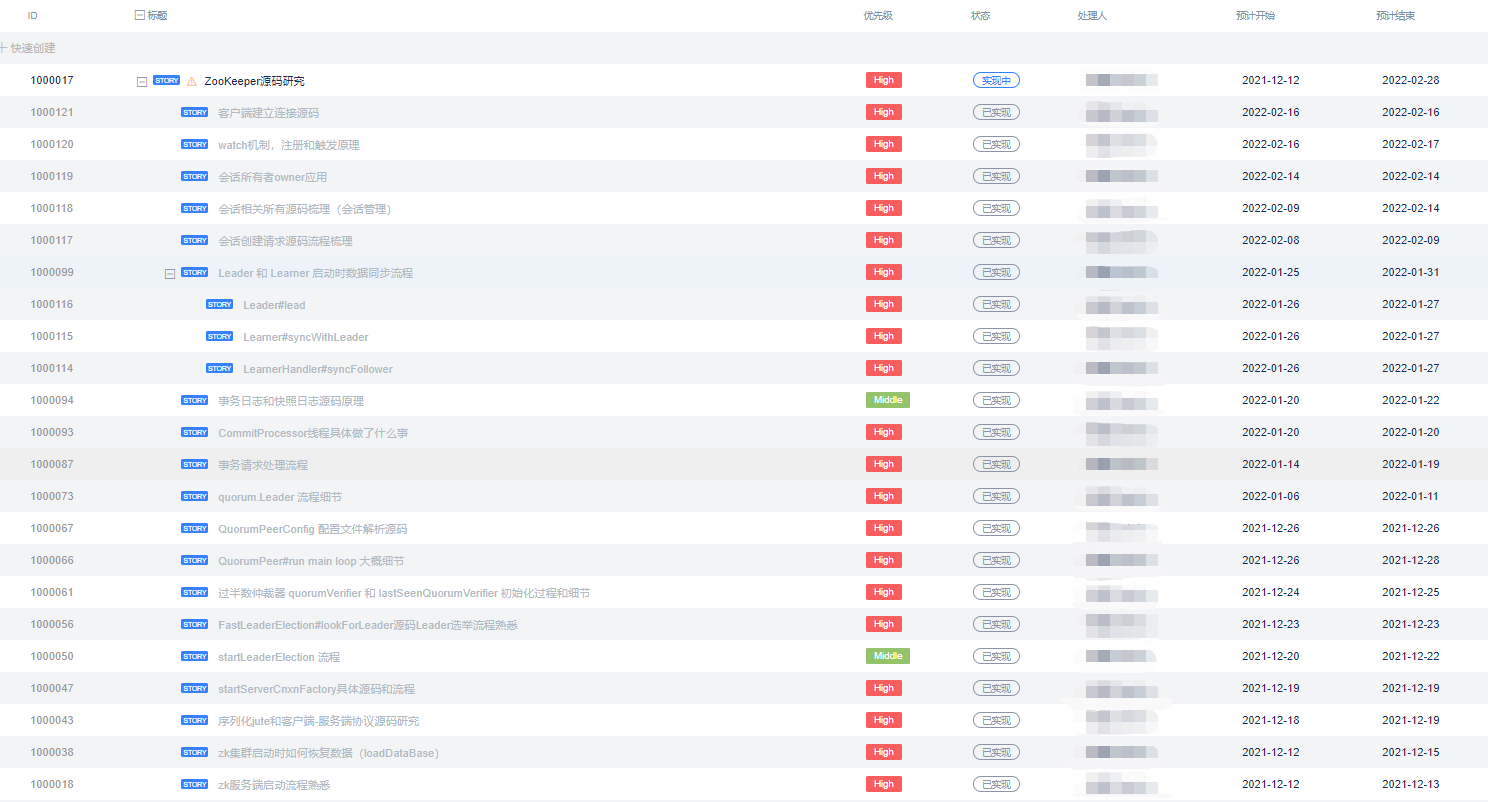
這里推薦一個任務管理的工具TAPD,非常之好用:
4、思維導圖
看完原始碼,總結是非常重要的,將一個知識點擴展成一個思維導圖,每一個分支都是最精華的總結,這樣會更加印象深刻,
二、原始碼基本結構
ZooKeeper原始碼分為客戶端原始碼和服務端原始碼,
1、客戶端原始碼
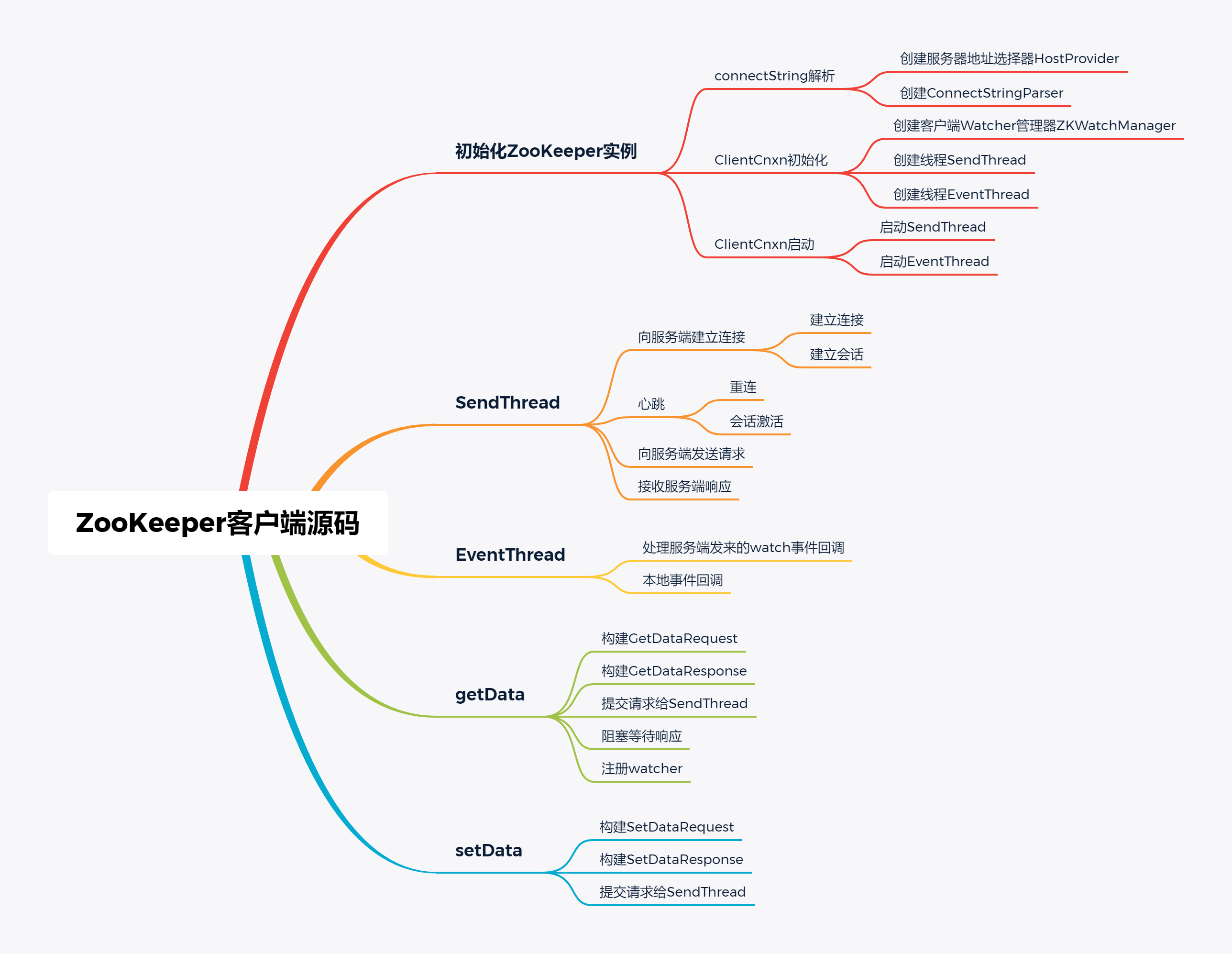
客戶端原始碼從一行初始化代碼開始:
String connectString = "127.0.0.1:2181,127.0.0.1:2182,127.0.0.1:2183";
ZooKeeper zooKeeper = new ZooKeeper(connectString, 20000, null);
初始化一個ZooKeeper實體,初始化程序會決議connectString,并隨機挑選一個服務器地址建立長連接,
(1)ClientCnxn客戶端連接抽象
ClientCnxn是對客戶端連接的抽象和封裝,負責連接管理和watcher管理,有兩個核心執行緒:
- 負責與服務端建立連接和通信的
SendThread執行緒, - 負責處理
watcher遠程回呼和本地事件回呼的EventThread執行緒,
在客戶端實體ZooKeeper初始化時,會初始化并啟動ClientCnxn,啟動ClientCnxn就是啟動SendThread和EventThread兩個執行緒,
(2)SendThread
SendThread執行緒主要負責與服務端建立長鏈接,后續的 getData、setData 等操作都通過SendThread執行緒與服務端通信,
SendThread的核心知識點有:
-
向服務端建立連接的程序
-
建立會話的程序
-
心跳機制保證長鏈接存活
-
讀寫IO處理
負責底層網路建立連接和I/O處理的是ClientCnxnSocket ,實作類有 ClientCnxnSocketNIO 和 ClientCnxnSocketNetty,
(3)EventThread
SendThread接收到服務端的 watcher 通知后,會交由EventThread執行緒去觸發回呼,注冊watcher的功能只有非事務請求(getData、exists、getChildren)才有,而事務請求,如getData可以注冊本地事件,事務請求回應成功后會觸發本地事件回呼,這里的回呼流程也是在EventThread執行緒中,
(4)getData非事務請求
非事務請求不僅僅有getData,但流程都差不多,
getData可以注冊watcher,但是如何注冊,并且是如何遠程向服務端注冊?其實注冊 watcher 只是向服務端發送一個是否注冊watcher的布林值,具體注冊什么事件不會在注冊時宣告,而是在觸發時判斷,
getData構建好請求體和回應體,并提交給SendThread執行緒進行底層網路的異步發送,此時getData主執行緒會阻塞等待回應,
(5)setData事務請求
事務請求也并非只有setData,還有create、delete,但是setData在客戶端回應處理上稍有不同,create、delete和getData一樣會阻塞,要等服務端的回應;而setData不需要阻塞,但是需要按順序處理回應,
2、服務端原始碼
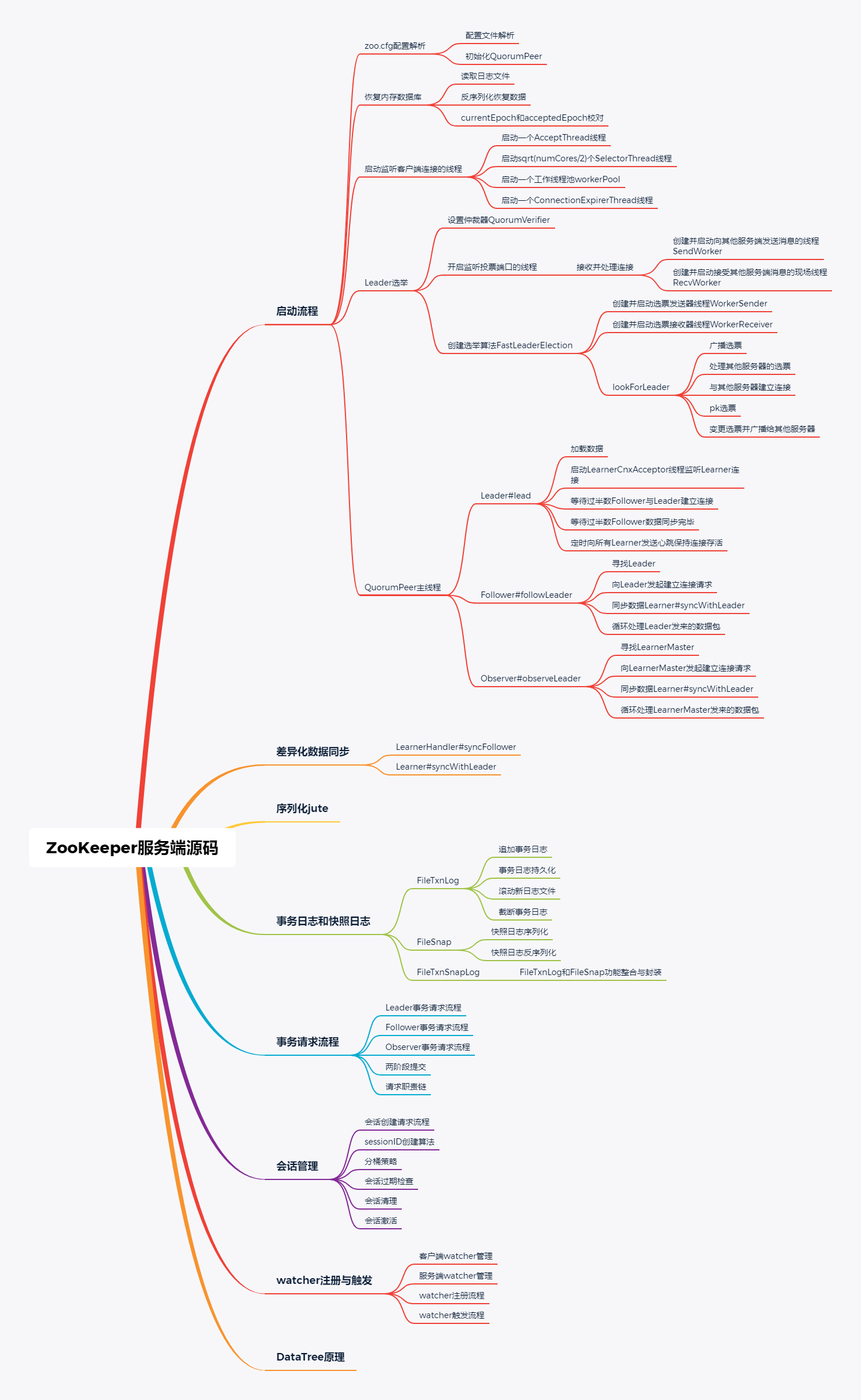
服務端原始碼較為復雜,突破口在啟動流程上,在服務端啟動的程序中,涉及到的知識點:
- 組態檔決議和配置項在原始碼中應用,
- 讀取日志檔案恢復記憶體資料庫,
- 監聽和接收客戶端連接,
- Leader選舉,
- Leader和Learner之間差異化資料同步,
- … …
(1)配置決議
將組態檔zoo.cfg加載為一個java.util.Properties物件,然后決議映射到QuorumPeerConfig物件中,再將QuorumPeerConfig的變數設定給QuorumPeer物件,QuorumPeer就是ZAB協議的具體實作類,
(2)恢復記憶體資料庫
在服務端啟動時,需要通過讀取日志檔案恢復記憶體資料庫,首先讀取快照日志檔案反序列化出一棵DataTree,然后再讀取事務日志檔案修補增量資料,這只是初步恢復,等Leader選舉完成以后,服務節點之間還需要進行差異化資料同步,
(3)監聽客戶端連接
在組態檔zoo.cfg中指定的clientPort就是用來監聽客戶端連接的,客戶端連接監聽是常規的Reactor回應式執行緒模型,一個AcceptThread執行緒監聽連接事件,多個SelectorThread輪詢封裝注冊連接,具體網路IO事件處理交給一個執行緒池,
AcceptThread執行緒接收到來自客戶端連接后,輪詢選擇一個SelectorThread來處理連接;每一個客戶端連接在服務端都被抽象化成一個ServerCnxn物件,默認實作類為NIOServerCnxn,負責底層網路IO處理;具體的IO讀寫事件處理抽象成一個IOWorkRequest任務物件交給執行緒池workerPool異步處理,
無論是事務請求還是非事務請求從底層網路讀取完資料并構建好請求體后,都會提交給一個節流閥執行緒RequestThrottler,RequestThrottler控制請求量,并將請求提交給一個包含多個處理器RequestProcessor的職責鏈處理,

(4)Leader選舉
在組態檔中,有幾行這樣格式的配置:
server.A=B:C:D
- A是一個數字,表示每個zk實體的
myid檔案中的編號,即SID, - B是ip地址,每個zk實體所在機器ip,
- C是集群中
Leader和Learner通信的埠, - D是集群中用于
Leader選舉同步票據的埠,
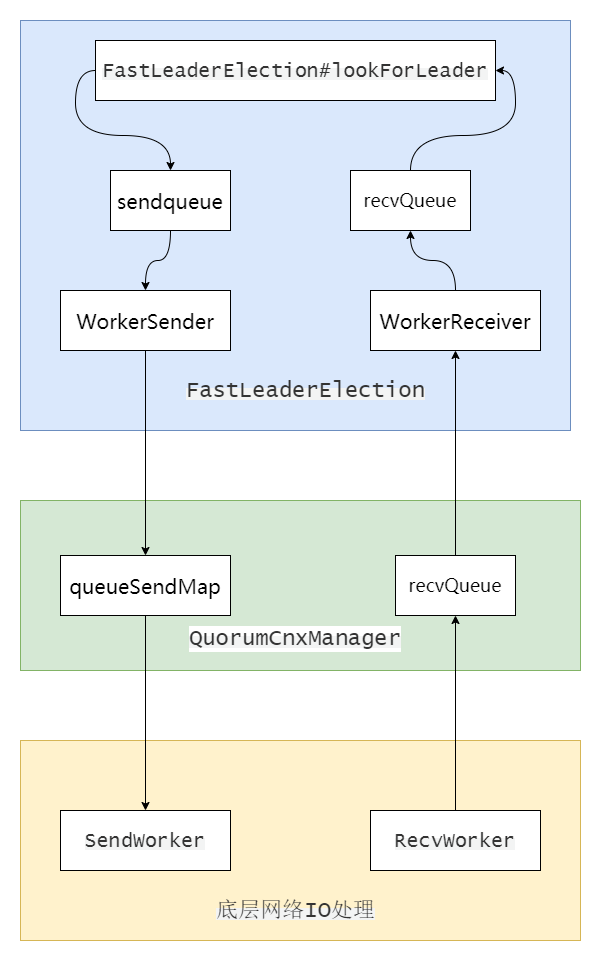
首先創建一個或者一組執行緒用于監聽投票埠,然后創建一個快速選舉Leader演算法FastLeaderElection,并啟動兩個執行緒WorkerSender和WorkerReceiver分別用于選票發送和選票接收,
在交換選票前,服務節點間互相建立連接,為避免連接重復建立,只有SID較大的服務器才可以主動向其他服務器發起建立連接請求,建立連接后,會為每個連接創建兩個執行緒SendWorker和RecvWorker分別用于網路底層的IO事件處理,
FastLeaderElection#lookForLeader是Leader選舉的核心實作,包括將選票廣播給所有其他服務,處理其他服務同步過來的選票,選票PK,最終選出Leader,完成選票,
(5)資料差異化同步
資料差異化同步發生在Leader選舉完成之后,Learner服務器(Follower和Observer)需要向Leader服務器發起建立連接請求,Leader啟動LearnerCnxAcceptor執行緒監聽Learner的連接請求,每一個建立的連接會被抽象成一個LearnerHandler物件,
Leader檢測到有過半數的Follower(Observer不參與過半數決策)建立連接后,就開始校對Learner的資料與自己的資料有哪些差異:
- 如果
Learner少了資料,Leader就會發送缺少的資料給Learner; - 如果
Learner多出資料,Leader就會讓Learner回滾到指定位置; - 實在差異太大,就全量同步,
(6)事務日志和快照日志
在服務器正常運行的程序,查詢資料都是直接從記憶體資料庫中獲取,所以回應速度很快,但是為了服務重啟后資料還在,才有了將資料持久化到磁盤日志檔案中,
每條事務請求都會先落地到事務日志檔案,再提交到記憶體資料庫中,經過一定事務請求次數,還會將整個記憶體資料庫持久化成一個快照日志檔案,一個快照日志檔案和其后生成的事務日志檔案共同組成全域資料,
FileTxnLog是事務日志檔案持久化實作類,主要封裝對磁盤檔案的追加、讀取、截斷、滾動等操作,
FileSnap是快照日志檔案持久化實作類,主要封裝兩個操作:將DataTree和會話串列序列化到磁盤檔案和讀取磁盤檔案反序列化出DataTree和會話串列,
FileTxnSnapLog是對FileTxnLog和FileSnap整合,方便呼叫,
(7)事務請求流程
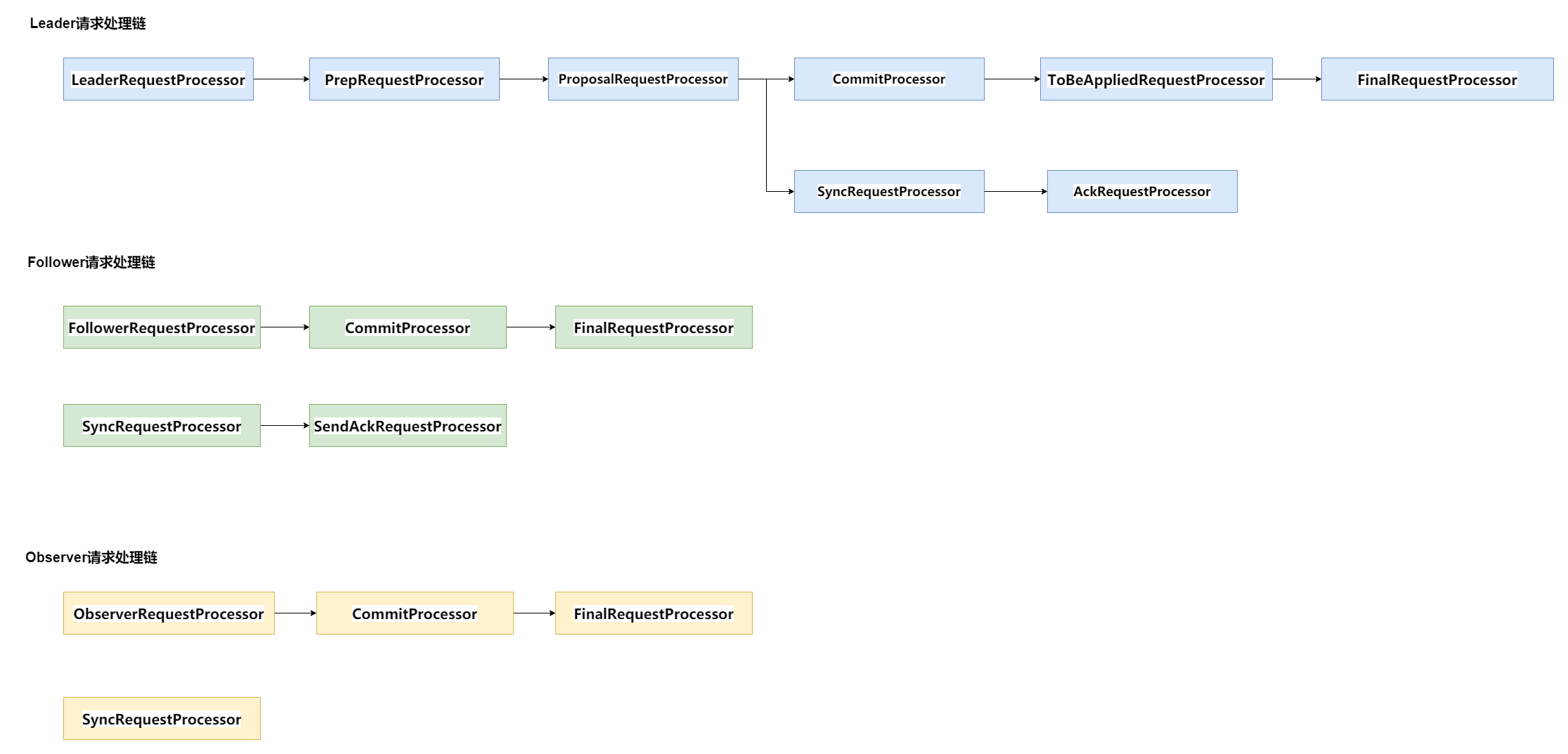
事務請求和非事務請求都會經過一個職責鏈處理,不同的是,事務請求需要經過兩階段提交,而非事務請求不需要,
兩階段提交只能由Leader發起提案和進行提交操作,所以Follower和Observer接收到事務請求必須先轉發給Leader,由Leader發起兩階段提交,
服務節點有三種型別Leader、Follower、Observer,所以有三條請求處理的職責鏈,其中個別處理器相同,
比如三條處理鏈最后都有一個FinalRequestProcessor來處理回應或者將請求應用到記憶體資料庫;Follower和Observer首個處理器都是將事務請求轉發給 Leader;Observer沒有投票權,不參與兩階段決策,所以沒有回應Leader的ACK處理器,
(8)會話管理
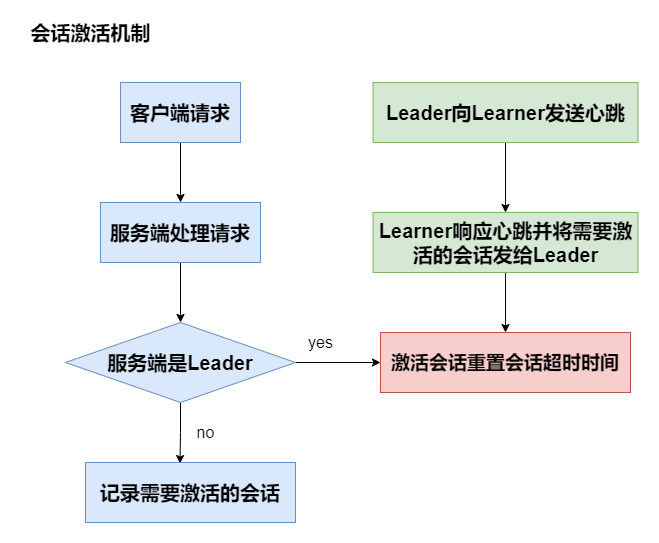
客戶端與服務端建立連接后,緊接著必須建立會話,之后所有通信都要在會話有效的基礎上進行,會話建立也是事務請求,sessionID的創建和會話超時時間協商由當前服務實體完成,但是會話管理包括會話超時檢查、清理、激活等都必須交由Leader負責,
客戶端發向服務端的請求,無論是正常請求還是心跳都會重新激活會話,即重置會話超時時間,而Learner沒有激活會話的權限,只有在Leader向Learner發送心跳,Learner回應心跳時,將需要激活的會話發給Leader,由Leader激活會話,
(9)watcher注冊與觸發
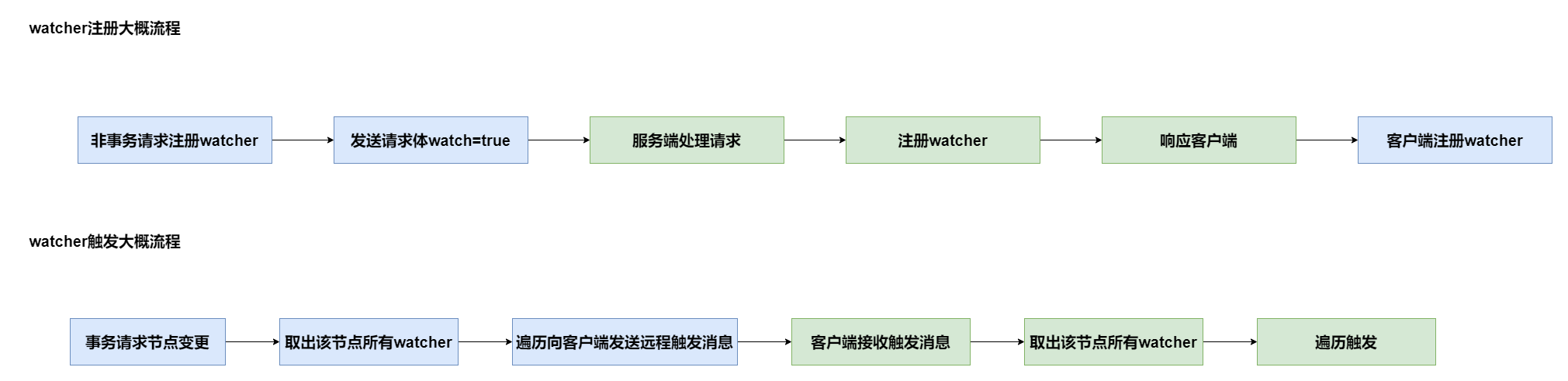
watcher 注冊是非事務請求特有的,客戶端并不會將 watcher 的詳細資訊發送給服務器,而是只發送一個是否注冊watcher 的布林值,
服務器在處理請求時檢測到請求體里的watch=true,就在記憶體資料庫里注冊一個watcher;資料發生變更,就取出該節點上注冊的所有watcher,進行觸發,觸發的動作由服務端傳遞給客戶端;客戶端也保存了節點和watcher的關系,客戶端從記憶體中取出該節點的所有watcher,一個個觸發,觸發的程序中判斷是發生了什么事件,如節點創建、節點內容變更、節點洗掉等,
(10)DataTree記憶體資料庫
DataTree是記憶體資料庫的具體實作,所謂樹形結構其實就是哈希表NodeHashMap,key為節點路徑,value為節點資訊DataNode,DataNode中保存節點內容、節點持久化版本狀態以及孩子節點相對路徑(去掉父節點路徑)串列,
NodeHashMap具體實作類為NodeHashMapImpl,實則就是對ConcurrentHashMap的簡單包裝,
三、原始碼環境搭建
1、IDEA匯入原始碼
從 github下拉ZooKeeper原始碼最新穩定版https://github.com/apache/zookeeper,為了和當時看原始碼時的版本一致,這里選擇 release-3.7.0:
git clone -b release-3.7.0 git@github.com:apache/zookeeper.git
原始碼匯入IDEA即可,org.apache.zookeeper.proto和org.apache.zookeeper.data等包下的類會出現例外:
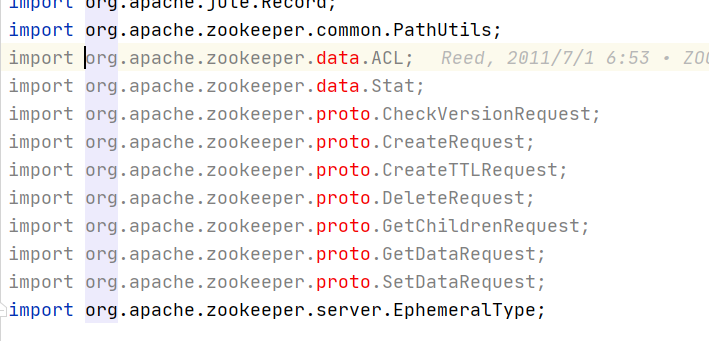
這是因為這些包的原始碼不是現成的,需要通過編譯Jute模塊自動生成,生成的代碼路徑如下:
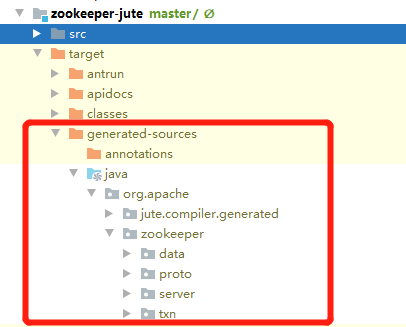
也可以一勞永逸,直接編譯root專案,這樣就會編譯所有模塊了,
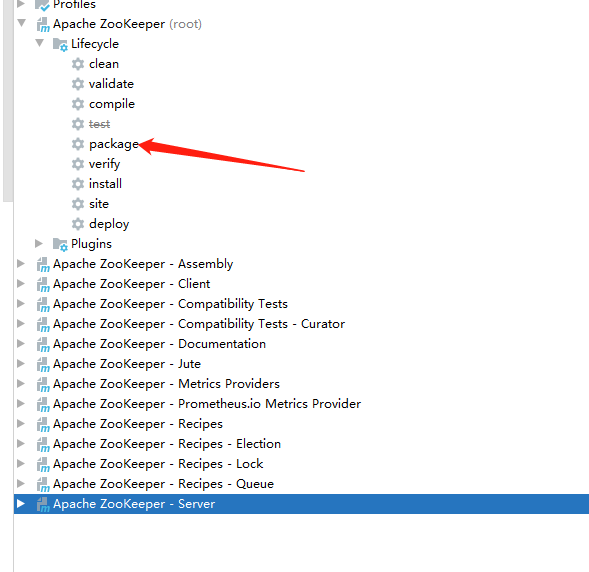
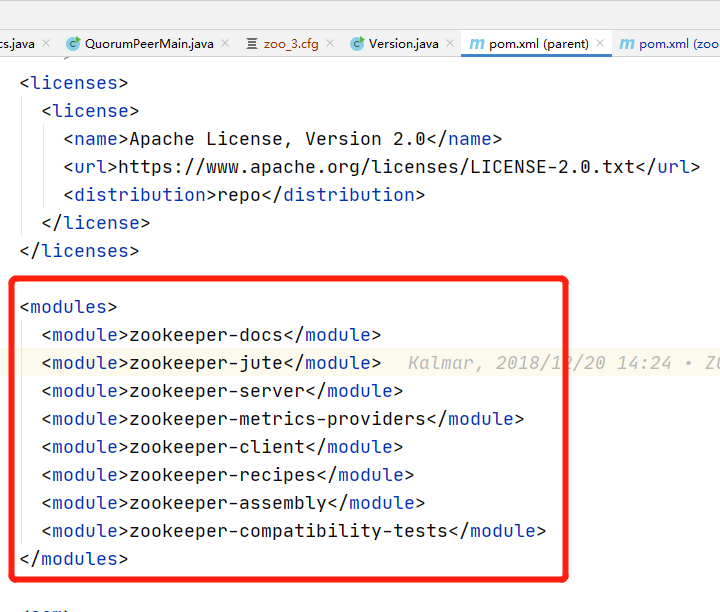
2、本地運行
root專案編譯成功后,就可以像搭建偽集群一樣本地運行原始碼了,
(1)偽集群搭建準備
如果不知道偽集群搭建需要準備哪些東西,請參考《分布式系統的基石之ZooKeeper——基本原理+場景應用+集群搭建(最強萬字入門指南)》,
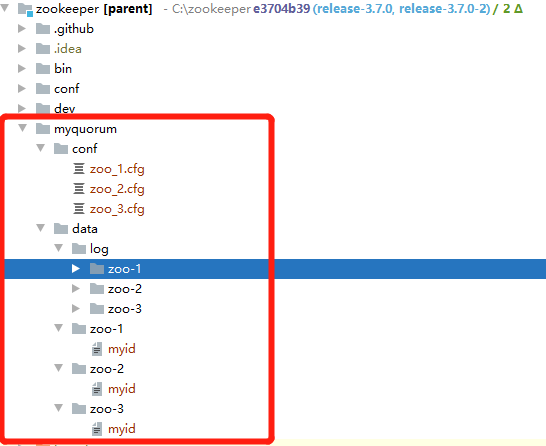
分別創建三個Application,Program arguments 指定組態檔路徑,Main class有兩種,一種是單體模式ZooKeeperServerMain,一種是集群模式QuorumPeerMain,這里選擇QuorumPeerMain,
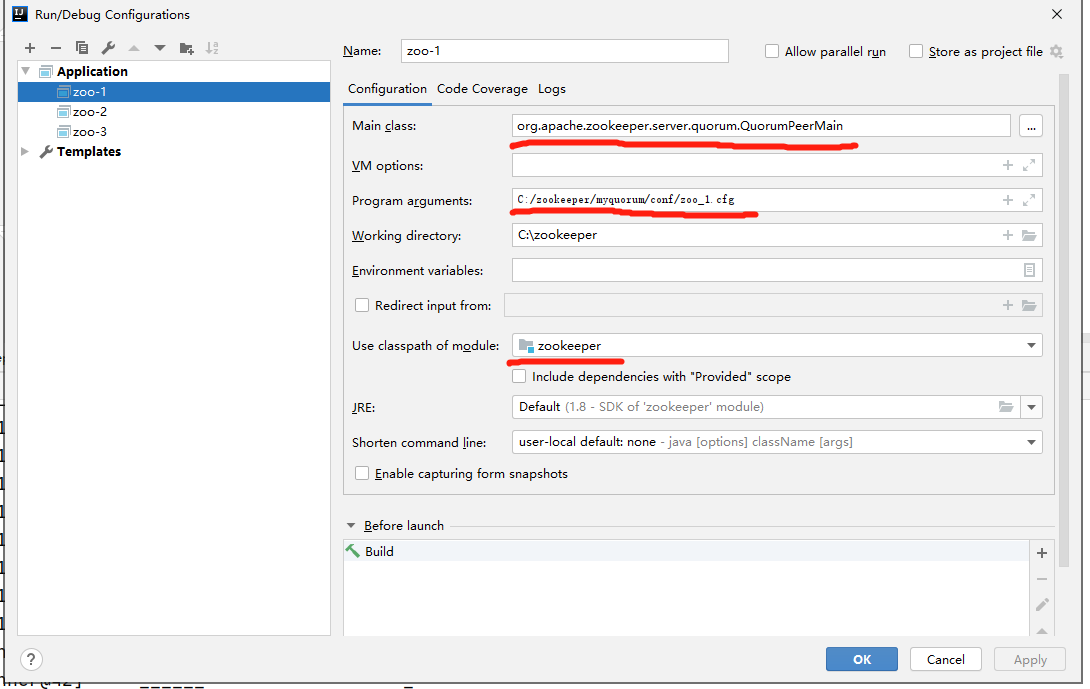
(2)運行
分別啟動zoo-1、zoo-2、zoo-3,可能會出現某些類找不到的情況:
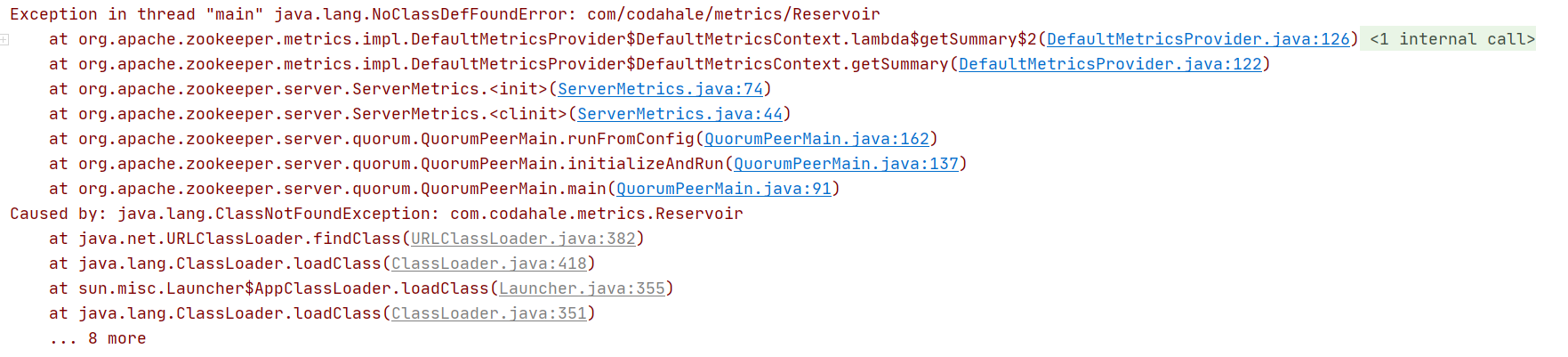
這是因為zookeeper-server模塊的pom.xml檔案部分依賴的scope是provided的,只有編譯和測驗環境中依賴才起作用,想在運行時也起作用,可以將provided改為compile,或者去掉scope,因為默認scope是compile,編譯,運行,測驗環境依賴都起作用,
修改完zookeeper-server模塊的pom.xml檔案后重新編譯就可以了,
如果運行的程序中控制臺沒有列印日志,首先查看zookeeper-server/src/main/resources路徑下是否有log4j.properties檔案,如果沒有,就把conf目錄下的log4j.properties復制過來,同時指定zookeeper-server/src/main/resources為Resources目錄才會生效,
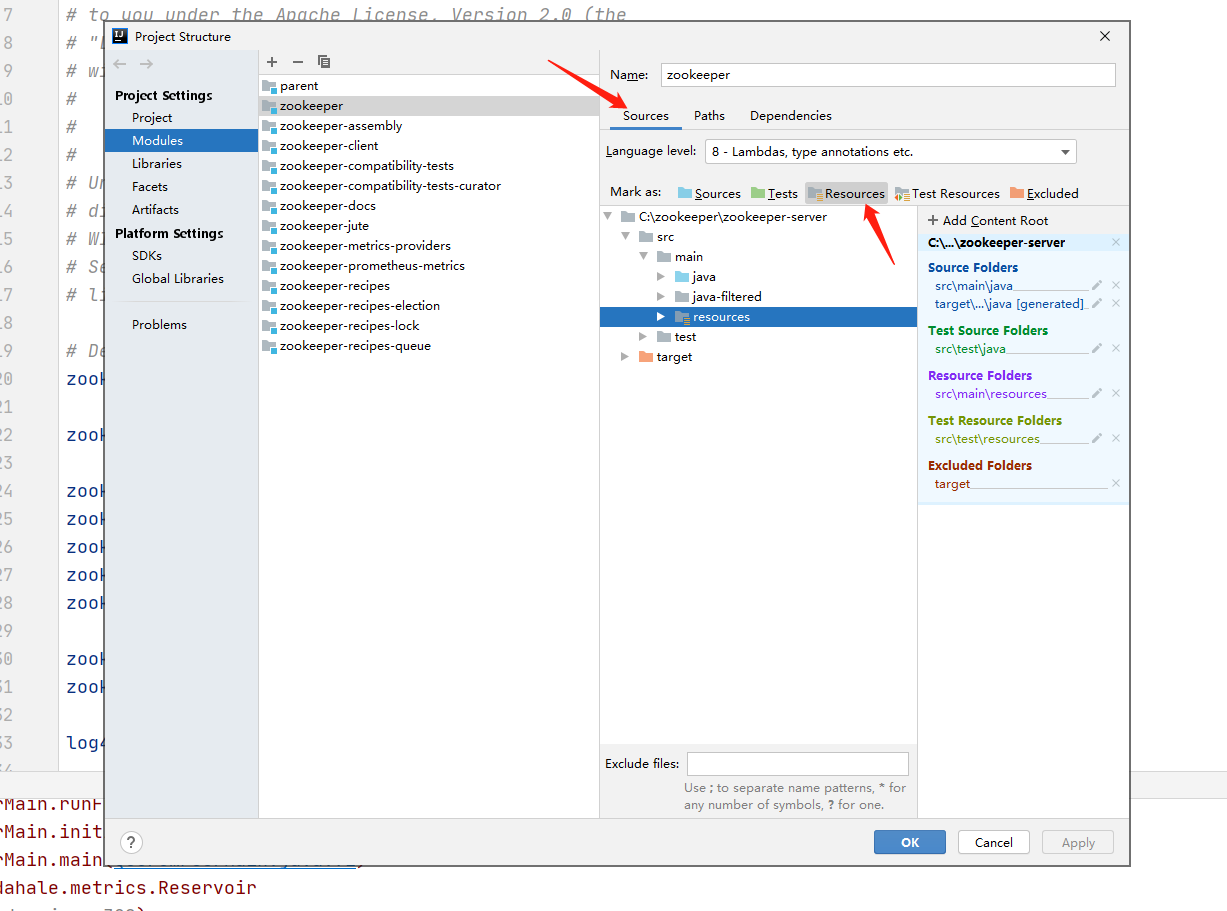
如此這般就可以運行了:
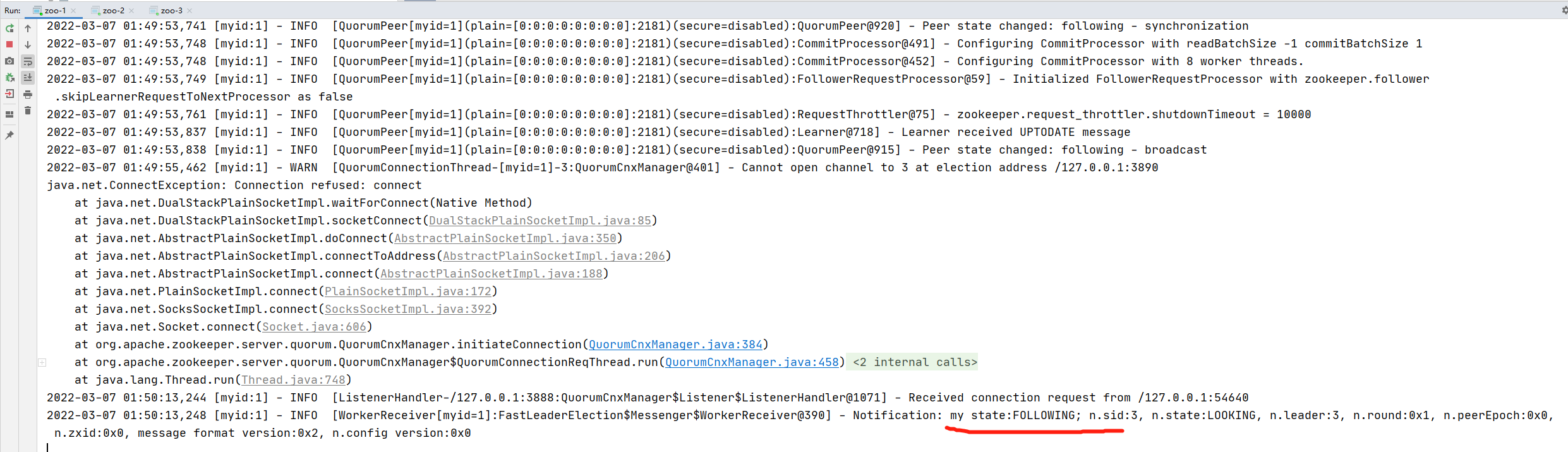
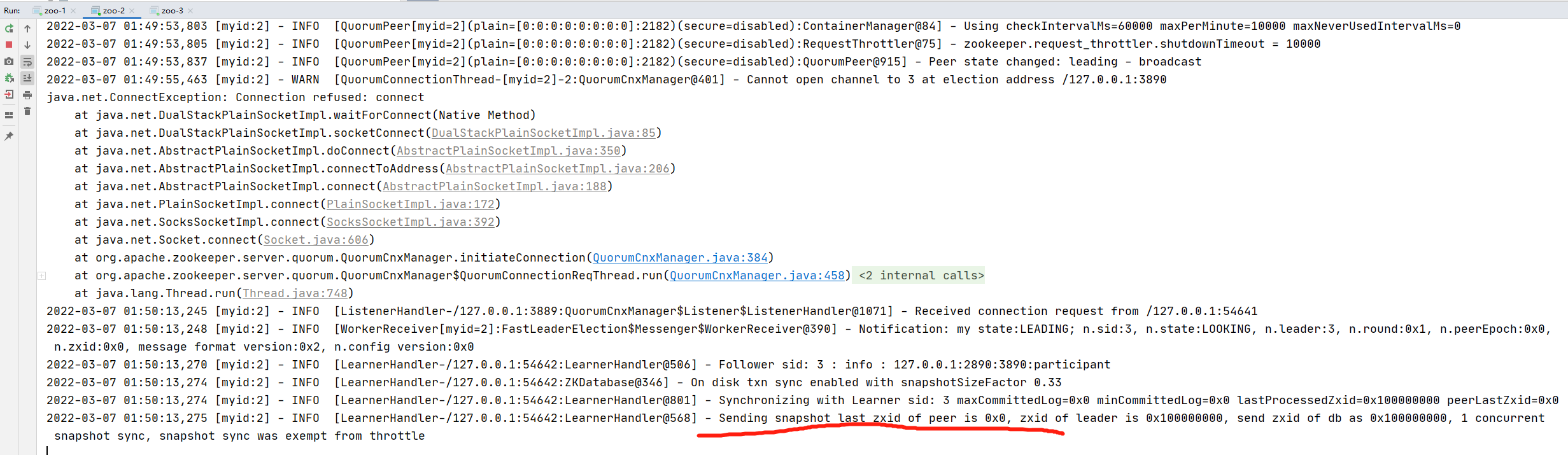
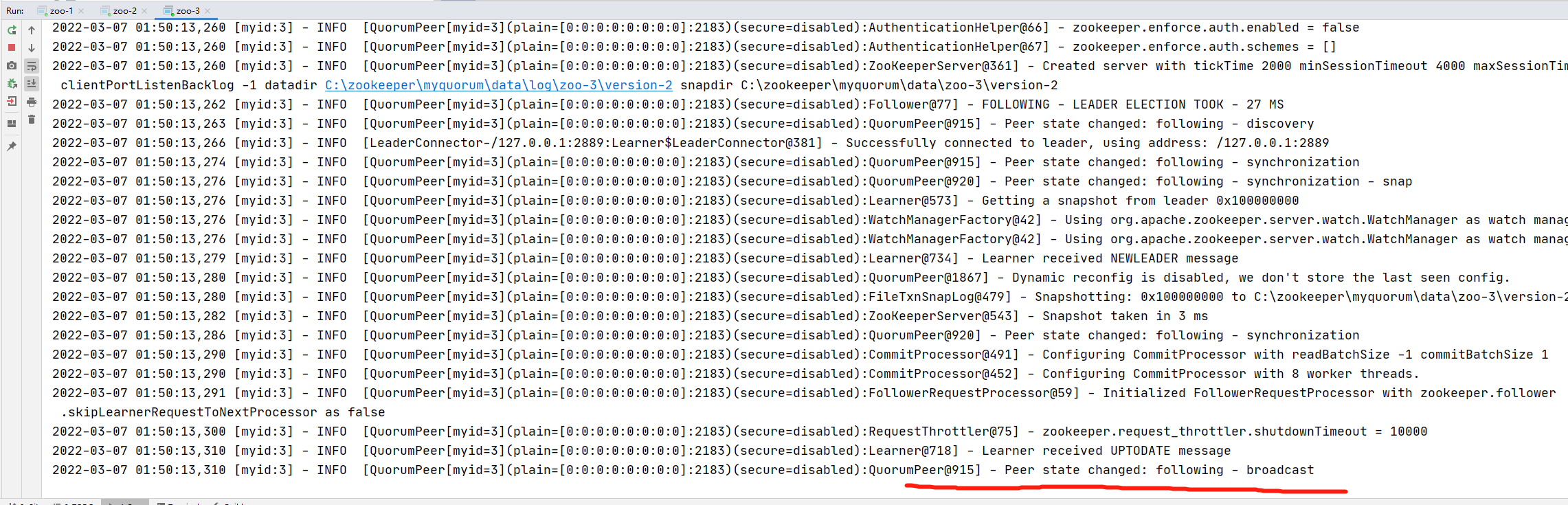
在本地運行原始碼的好處就是可以debug,debug對于閱讀原始碼,理解一些流程非常有幫助,
ZooKeeper原始碼注釋:https://github.com/stefanxfy/ZooKeeperLearning
如若文章有錯誤理解,歡迎批評指正,同時非常期待你的評論、點贊和收藏,
如果想了解更多優質文章,和我更密切的學習交流,請關注如下同名公眾號【徐同學呀】,期待你的加入,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/439244.html
標籤:其他