我們在博文《聯邦學習:按病態獨立同分布劃分Non-IID樣本》中學習了聯邦學習開山論文[1]中按照病態獨立同分布(Pathological Non-IID)劃分樣本, 在上一篇博文《聯邦學習:按Dirichlet分布劃分Non-IID樣本》中我們也已經提到了按照Dirichlet分布劃分聯邦學習Non-IID資料集的一種演算法,下面讓我們來看按Dirichlet分布劃分資料集的另外一種變種,即按混合分布劃分Non-IID樣本,該方法為論文[2]中首次提出,
該論文提出了一個重要的假設,那就是雖然聯邦學習每個client的資料是Non-IID,但我們假設它們都來自一個混合分布(混合成分個數為超引數可調):
\[p(x|\theta) = \sum_{k=1}^K\alpha_k p(x|\theta_k) \]形象化的展示圖片如下:
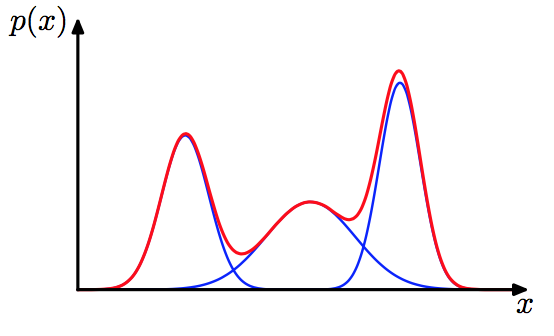 有了這個假設,那我們相當于假定了每個client資料間的一種相似性,這種相似性類似于從Non-IID中找出潛藏的IID成分,
有了這個假設,那我們相當于假定了每個client資料間的一種相似性,這種相似性類似于從Non-IID中找出潛藏的IID成分,
接下來我們來看這個劃分演算法的函式如何設計,除了常規Dirichlet劃分演算法所要求的n_clients、n_classes、\(\alpha\)等, 它還有一個專門的n_clusters引數,表示混合成分個數,我們來看函式原型:
def split_dataset_by_labels(dataset, n_classes, n_clients, n_clusters, alpha, frac, seed=1234):
我們解釋一下函式的引數,這里dataset是torch.utils.Dataset型別的資料集,n_classes表示資料集里樣本分類數,n_clusters是簇的個數(后面會解釋其含義,如果設定為-1,則就默認n_clusters=n_classes,相當于每個client各為一個簇,即放棄了混合分布假設),alpha 用于控制clients之間的資料diversity(多樣性),frac是使用資料集的比例(默認是1,即使用全部資料),seed是傳入的亂數種子,該函式回傳一個由n_client個client所需的樣本索引組成的串列組成的串列client_idcs,
接下來我們看這個函式的內容,這個函式的內容可以概括為:先將所有類別分組為n_clusters個簇;再對每個簇c,將樣本劃分給不同的clients(每個client的樣本數量按照dirichlet分布來確定),
首先,我們判斷n_clusters的數量,如果為-1,則默認每一個cluster對應一個資料class:
if n_clusters == -1:
n_clusters = n_classes
然后將打亂后的標簽集合\(\{0,1,...,n\_classes-1\}\)分為n_clusters個獨立同分布的簇,
all_labels = list(range(n_classes))
np.random.shuffle(all_labels)
def iid_divide(l, g):
"""
將串列`l`分為`g`個獨立同分布的group(其實就是直接劃分)
每個group都有 `int(len(l)/g)` 或者 `int(len(l)/g)+1` 個元素
回傳由不同的groups組成的串列
"""
num_elems = len(l)
group_size = int(len(l) / g)
num_big_groups = num_elems - g * group_size
num_small_groups = g - num_big_groups
glist = []
for i in range(num_small_groups):
glist.append(l[group_size * i: group_size * (i + 1)])
bi = group_size * num_small_groups
group_size += 1
for i in range(num_big_groups):
glist.append(l[bi + group_size * i:bi + group_size * (i + 1)])
return glist
clusters_labels = iid_divide(all_labels, n_clusters)
然后再建立根據上面劃分為簇的標簽(clusters_labels)建立key為label, value為簇id(group_idx)的字典,
label2cluster = dict() # maps label to its cluster
for group_idx, labels in enumerate(clusters_labels):
for label in labels:
label2cluster[label] = group_idx
接著獲取資料集的索引
data_idcs = list(range(len(dataset)))
之后,我們
# 記錄每個cluster大小的向量
clusters_sizes = np.zeros(n_clusters, dtype=int)
# 存盤每個cluster對應的資料索引
clusters = {k: [] for k in range(n_clusters)}
for idx in data_idcs:
_, label = dataset[idx]
# 由樣本資料的label先找到其cluster的id
group_id = label2cluster[label]
# 再將對應cluster的大小+1
clusters_sizes[group_id] += 1
# 將樣本索引加入其cluster對應的串列中
clusters[group_id].append(idx)
# 將每個cluster對應的樣本索引串列打亂
for _, cluster in clusters.items():
rng.shuffle(cluster)
接著,我們按照Dirichlet分布設定每一個cluster的樣本個數,
# 記錄來自每個cluster的client的樣本數量
clients_counts = np.zeros((n_clusters, n_clients), dtype=np.int64)
# 遍歷每一個cluster
for cluster_id in range(n_clusters):
# 對每個cluster中的每個client賦予一個滿足dirichlet分布的權重
weights = np.random.dirichlet(alpha=alpha * np.ones(n_clients))
# np.random.multinomial 表示投擲骰子clusters_sizes[cluster_id]次,落在各client上的權重依次是weights
# 該函式回傳落在各client上各多少次,也就對應著各client應該分得的樣本數
clients_counts[cluster_id] = np.random.multinomial(clusters_sizes[cluster_id], weights)
# 對每一個cluster上的每一個client的計數次數進行前綴(累加)求和,
# 相當于最侄訓傳的是每一個cluster中按照client進行劃分的樣本分界點下標
clients_counts = np.cumsum(clients_counts, axis=1)
然后,我們根據每一個cluster中的每一個client分得的樣本情況(我們已經得到了每一個cluster中按照client進行劃分的樣本分界點下標),合并歸納得到每一個client中分得的樣本情況,
def split_list_by_idcs(l, idcs):
"""
將串列`l` 劃分為長度為 `len(idcs)` 的子串列
第`i`個子串列從下標 `idcs[i]` 到下標`idcs[i+1]`
(從下標0到下標`idcs[0]`的子串列另算)
回傳一個由多個子串列組成的串列
"""
res = []
current_index = 0
for index in idcs:
res.append(l[current_index: index])
current_index = index
return res
clients_idcs = [[] for _ in range(n_clients)]
for cluster_id in range(n_clusters):
# cluster_split為一個cluster中按照client劃分好的樣本
cluster_split = split_list_by_idcs(clusters[cluster_id], clients_counts[cluster_id])
# 將每一個client的樣本累加上去
for client_id, idcs in enumerate(cluster_split):
clients_idcs[client_id] += idcs
最后,我們回傳每個client對應的樣本索引:
return clients_idcs
接下來我們在EMNIST資料集上呼叫該函式進行測驗,并進行可視化呈現,我們設client數量\(N=10\),Dirichlet概率分布的引數向量\(\bm{\alpha}\)滿足\(\alpha_i=0.4,\space i=1,2,...N\), 混合成分個數為3:
import torch
from torchvision import datasets
import numpy as np
import matplotlib.pyplot as plt
torch.manual_seed(42)
if __name__ == "__main__":
N_CLIENTS = 10
DIRICHLET_ALPHA = 1
N_COMPONENTS = 3
train_data = https://www.cnblogs.com/orion-orion/archive/2022/03/10/datasets.EMNIST(root=".", split="byclass", download=True, train=True)
test_data = https://www.cnblogs.com/orion-orion/archive/2022/03/10/datasets.EMNIST(root=".", split="byclass", download=True, train=False)
n_channels = 1
input_sz, num_cls = train_data.data[0].shape[0], len(train_data.classes)
train_labels = np.array(train_data.targets)
# 注意每個client不同label的樣本數量不同,以此做到Non-IID劃分
client_idcs = split_dataset_by_labels(train_data, num_cls, N_CLIENTS, N_COMPONENTS, DIRICHLET_ALPHA)
# 展示不同client的不同label的資料分布
plt.figure(figsize=(20,3))
plt.hist([train_labels[idc]for idc in client_idcs], stacked=True,
bins=np.arange(min(train_labels)-0.5, max(train_labels) + 1.5, 1),
label=["Client {}".format(i) for i in range(N_CLIENTS)], rwidth=0.5)
plt.xticks(np.arange(num_cls), train_data.classes)
plt.legend()
plt.show()
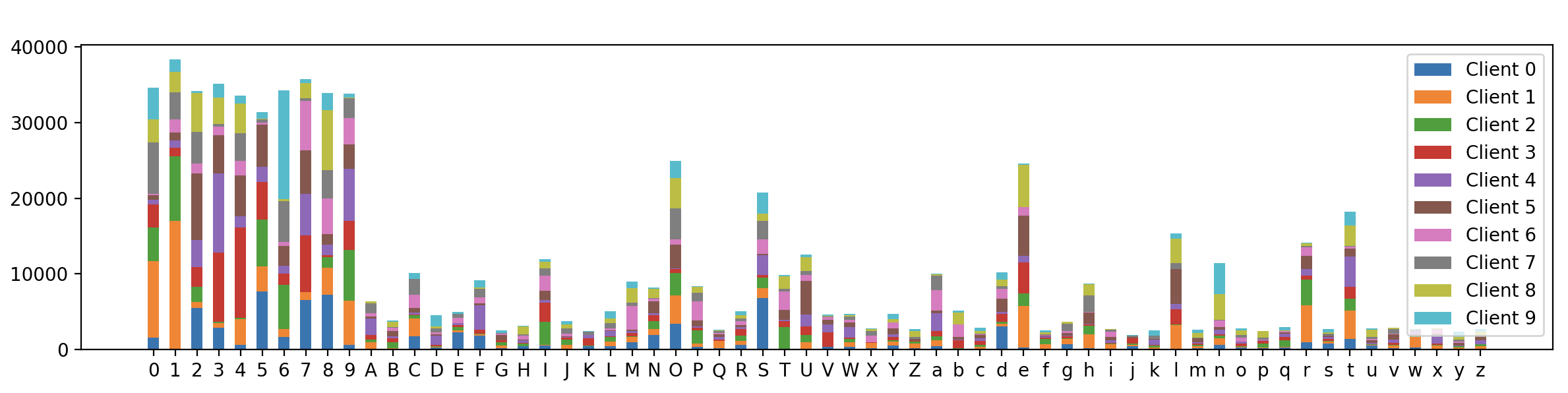
最終的可視化結果如下:
 可以看到,62個類別標簽在不同client上的分布雖然不同,但相對下面的完全基于Dirichlet的樣本劃分演算法,每個client之間的資料分布顯得更加相似,這證明我們的混合分布樣本劃分演算法是有效的,
可以看到,62個類別標簽在不同client上的分布雖然不同,但相對下面的完全基于Dirichlet的樣本劃分演算法,每個client之間的資料分布顯得更加相似,這證明我們的混合分布樣本劃分演算法是有效的,
參考
-
[1] McMahan B, Moore E, Ramage D, et al. Communication-efficient learning of deep networks from decentralized data[C]//Artificial intelligence and statistics. PMLR, 2017: 1273-1282.
-
[2] Marfoq O, Neglia G, Bellet A, et al. Federated multi-task learning under a mixture of distributions[J]. Advances in Neural Information Processing Systems, 2021, 34.
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/440529.html
標籤:其他
上一篇:百錢買百雞問題
下一篇:命令執行漏洞